







参考书籍:《Python数据科学手册》
Pandas笔记精选

Pandas 是在 NumPy 基础上建立的新程序库(后者多是数组操作),提供了一种高效DataFrame数据结构。DataFrame 本质上是一种带行标签和列标签、支持相同类型数据和缺失值的多维数组。Pandas 不仅为带各种标签的数据提供了便利的存储界面,还实现了许多强大的操作。
Pandas 的三个基本数据结构:Series、DataFrame 和 Index。
pandas处理csv数据基本用法
1.Pandas对象简介
1.1 Pandas的Series对象
Pandas 的 Series 对象是一个带索引数据(out后可显示出)构成的一维数组。可以用一个数组创建 Series 对象。
Pandas 的 Series 对象比它模仿的一维 NumPy 数组更加通用、灵活:
-
两者间的本质差异其实是索引:NumPy 数组通过隐式定义的整数索引获取数值,而 Pandas 的Series 对象用一种显式定义的索引与数值关联。


-
Series是特殊的字典:
Pandas Series 的类型信息使得它在某些操作上比Python 的字典更高效。用字典创建 Series 对象时,其索引默认按照顺序排列。典型的字典数值获取方式仍然有效。
-
Series 对象还支持数组形式的操作,比如切片

-
创建:

需要注意的是,Series 对象只会保留显式定义的键值对。

1.2 Pandas的DataFrame对象
Pandas 的另一个基础数据结构是 DataFrame。和Series 对象一样,DataFrame既可以作为一个通用型 NumPy 数组,也可以看作特殊的 Python 字典。
-
DataFrame是通用的NumPy数组:
如果将 Series 类比为带灵活索引的一维数组,那么 DataFrame 就可以看作是一种既有灵活的行索引,又有灵活列名的二维数组。
可以把 DataFrame 看成是有序排列的若干 Series 对象(基本对象为Series)。这里的“排列”指的是它们拥有共同的索引。
DataFrame 还有一个 columns 属性,是存放列标签的 Index 对象。
-
DataFrame是特殊的字典(这样理解比前者更全面):
与 Series 类似,我们也可以把 DataFrame 看成一种特殊的字典。字典是一个键映射一个值,而 DataFrame 是一列映射一个 Series 的数据。
-
创建:
1.通过单个 Series 对象创建。
2.通过字典列表创建。即使字典中有些键不存在,Pandas 也会用缺失值 NaN(非数字)来表示。

3.通过 Series 对象字典创建。
4.通过 NumPy 二维数组创建。假如有一个二维数组,就可以创建一个可以指定行列索引值的 DataFrame。如果不指定行列索引值,那么行列默认都是整数索引值。
5.通过 NumPy 结构化数组创建。(Pandas 的 DataFrame与结构化数组十分相似)
1.3 Pandas的index对象
-
将Index看作不可变数组:
许多操作与列表及NumPy数组相似,但Index 对象与 NumPy 数组之间的不同在于,Index 对象的索引是不可变的。
Index 对象的不可变特征使得多个 DataFrame 和数组之间进行索引共享时更加安全,尤其是可以避免因修改索引时粗心大意而导致的副作用。
-
将Index看作有序集合:
可使用&, |, ^(异或)。
2.数据取值与选择
(可类比NumPy、标准Python)
2.1 Series数据选择方法
-
看作字典:键值对的映射、字典的表达式和方法。
-
看作一维数组:索引、切片、掩码、花哨的索引等操作。
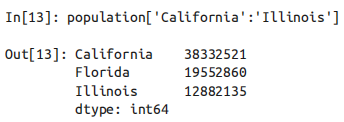
需要注意的是,当使用显式索引(如data[‘a’:‘c’])作切片时,结果包含最后一个索引;而当使用隐式索引(如 data[0:2])作切片时,结果不包含最后一个索引。
-
索引器:loc、iloc和ix。
上面提到的切片和取值的习惯用法经常会造成混乱。例如,如果你的 Series 是显式整数索引,那么 data[1] 这样的取值操作会使用显式索引,而 data[1:3] 这样的切片操作却会使用隐式索引。
In[11]: data = pd.Series(['a', 'b', 'c'], index=[1, 3, 5]) data Out[11]: 1 a 3 b 5 c dtype: object In[12]: # 取值操作是显式索引 data
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









