







Hparams设置:
为了选择最佳的fft参数,我制作了一个griffin_lim_synthesis_tool笔记本, 您可以使用它来反转实际提取的梅尔/线性光谱图,并选择预处理的好坏程度。所有其他选项都在hparams.py中得到了很好的解释,并且具有有意义的名称,因此您可以尝试使用它们。
Preprocessing:
Preprocessing can then be started using:
python preprocess.py
dataset can be chosen using the --dataset argument. If using M-AILABS dataset, you need to provide the language, voice, reader, merge_books and book arguments for your custom need. Default is Ljspeech.
Example M-AILABS:
python preprocess.py --dataset='M-AILABS' --language='en_US' --voice='female' --reader='mary_ann' --merge_books=False --book='northandsouth'
or if you want to use all books for a single speaker:
python preprocess.py --dataset='M-AILABS' --language='en_US' --voice='female' --reader='mary_ann' --merge_books=True
This should take no longer than a few minutes.
https://www.caito.de/2019/01/the-m-ailabs-speech-dataset/
https://github.com/carpedm20/multi-speaker-tacotron-tensorflow
突然想到speaker id可以加到decoder之后, 很多位置都加, 不只是加载decoder的输入. 目前没有思考怎么去反驳他在clone中的问题.
分析:
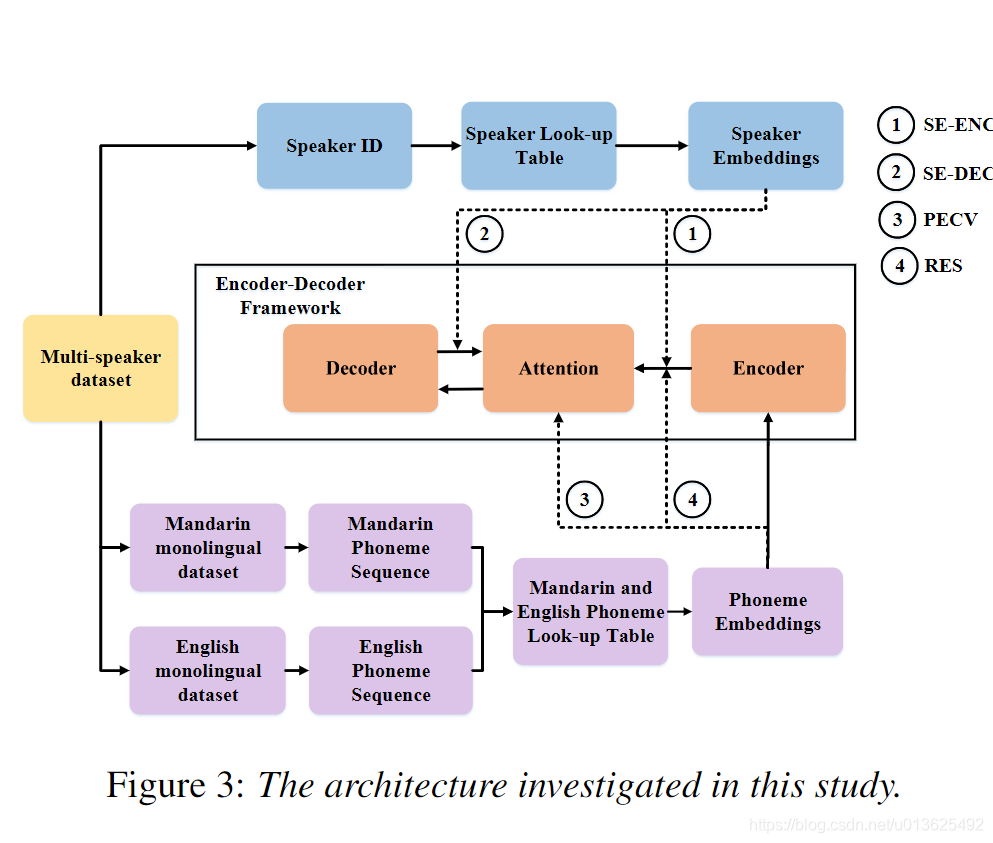

可能本质上一样, 但是因为text encoder output没有去相关性.

目前用最简单的加入到encoder output中, 不是拼接, 是加.
scp -r username@192.168.0.1:/home/test2 /home/test1
还是使用了拼接. (256dim)有点大.

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









