







一、概念
数字孪生(Digital Twin)是一种基于数字技术的概念,它是指对于现实世界中的物理实体或系统,通过数字化的方式建立一个虚拟的、与之相对应的数字化模型,从而实现对物理实体或系统的监测、仿真、预测和优化等操作。
数字孪生通常包括两个部分:物理实体和数字化模型。物理实体可以是任何实际存在的事物,例如机器、设备、建筑、城市、生态系统等等。数字化模型则是基于物理实体的数据和信息进行建模,包括几何形状、结构、材料、运行状态、环境参数等等,可以对物理实体进行仿真、预测、优化等操作。
二、应用范围
数字孪生是一种基于数字技术的概念,可以应用于多个领域,其应用范围非常广泛,以下是数字孪生的一些应用范围:
制造业: 数字孪生可以帮助制造商对生产过程进行优化,提高生产效率和质量。
建筑业: 数字孪生可以帮助建筑师和工程师对建筑物进行设计、施工和运营的全生命周期管理。
城市规划: 数字孪生可以帮助城市规划者对城市进行智能化管理和优化,提高城市的可持续性。
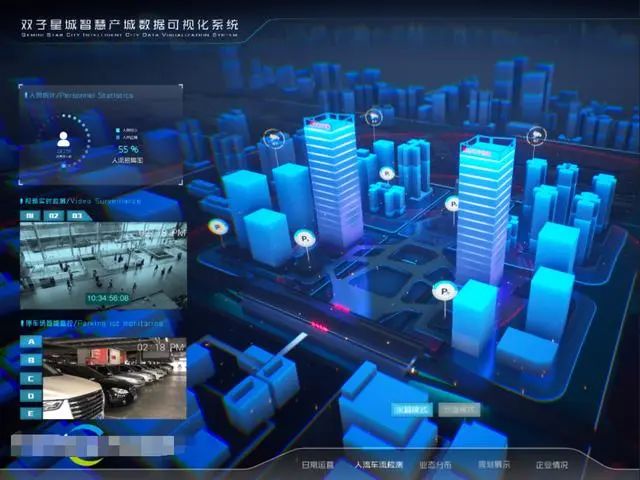
能源和环境: 数字孪生可以帮助能源和环境领域的专业人员对能源和环境系统进行监测、仿真和优化。
交通运输: 数字孪生可以帮助交通运输领域的专业人员对交通系统进行优化,提高交通效率和安全性。

医疗保健: 数字孪生可以帮助医疗保健领域的专业人员对患者进行个性化诊断和治疗。
三、十个技术栈
数字孪生是一个综合性的概念,涉及到多个技术领域,以下是数字孪生中常用的技术术语:
三维建模: 用于生成数字孪生的三维模型,可以使用CAD软件、三维建模软件等。
数据采集: 用于采集物理世界中的数据,可以使用传感器、监控设备等。
数据处理: 用于处理采集到的数据,包括数据分析、数据挖掘等。
数据清洗: 指的是对原始数据进行处理和筛选,以确保数据的准确性、完整性和一致性。
数据建模: 指将现实世界中的物理系统或过程转化为数字形式的模型。这个过程包括收集、整理和分析相关的数据,然后使用数学、统计学和计算机科学等方法来构建模型。
物联网技术: 用于连接物理世界中的设备和系统,包括传感器、智能设备、云计算等。
数据传输: 数据传输是非常重要的一环,它扮演着连接实际系统和数字孪生模型的桥梁,起到了数据采集、传输和更新的作用。
空间数据融合:用于存储和处理数字孪生的数据和模型,包括云存储、云计算、云服务等。
原型设计: 是指在设计过程中创建一个低保真或高保真的可视化模型,以展示和演示最终产品的外观、布局和交互。
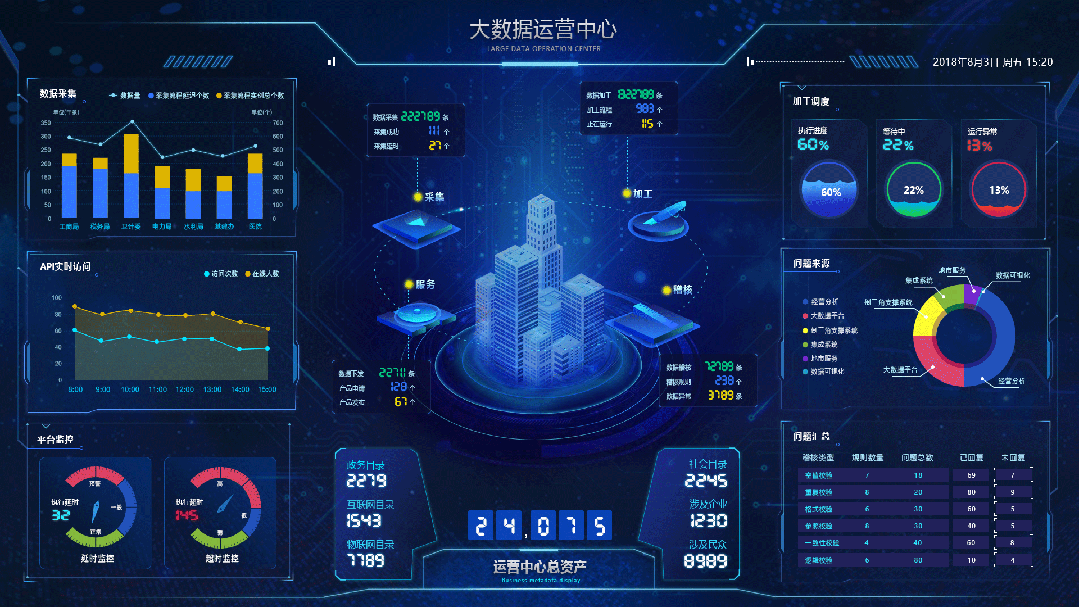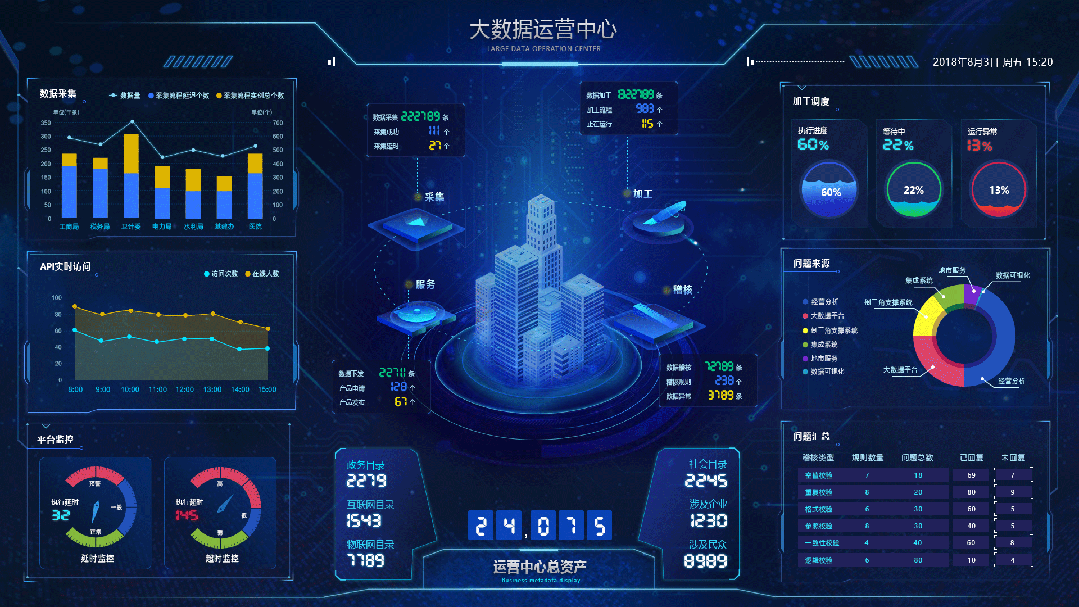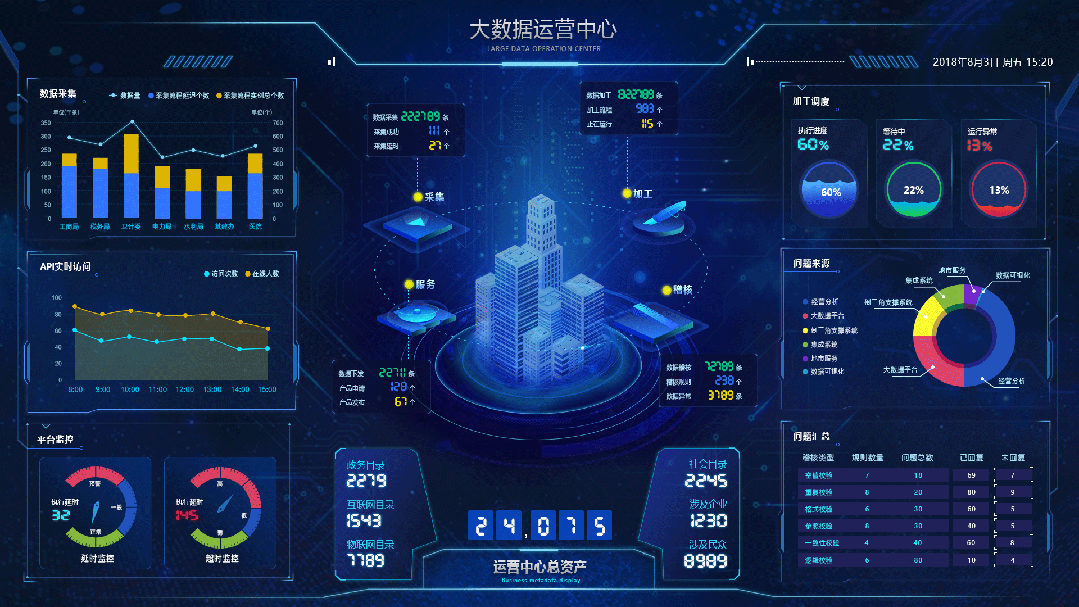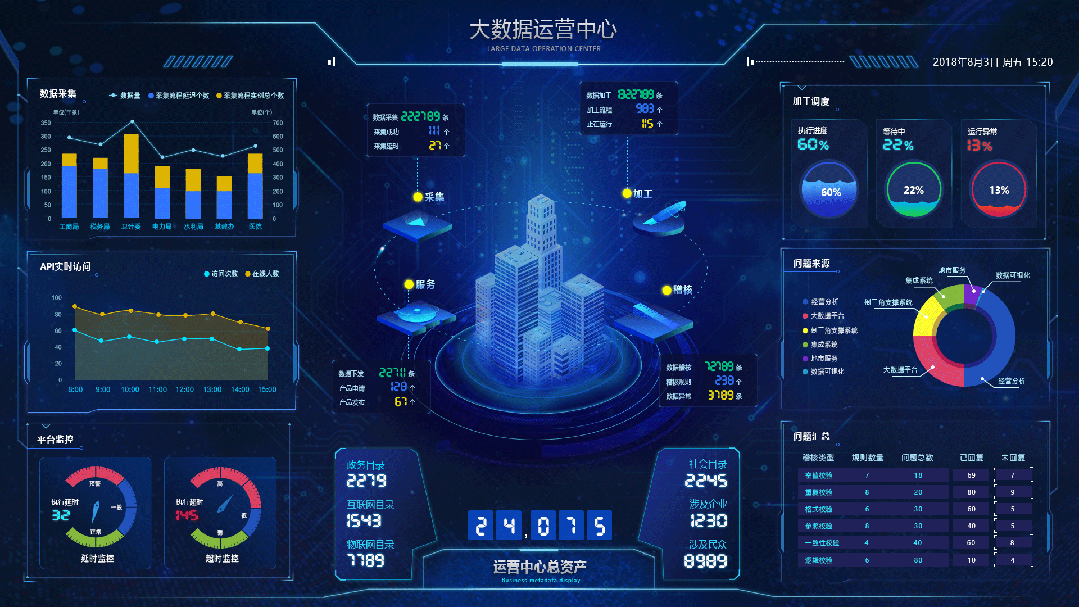
数据可视化与模拟仿真: 用于展示数字孪生的数据和模型,包括图表、地图、动画等。通过建立物理系统的数学模型,数字孪生平台可以进行虚拟仿真,模拟物理系统在不同条件下的运行情况。
数字孪生涉及到多个技术领域,需要综合运用多种技术手段来实现数字孪生的构建和应用。
via:
-
数字孪生10个技术栈:总体介绍 数字孪生研习社 系统仿真学报公众号 2024年07月26日 16:06 北京

















 854
854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









