







声明:版权所有,转载请联系作者并注明出处 http://blog.csdn.net/u013719780?viewmode=contents
在ImageNet上的图像分类challenge上,Hinton和他的学生Alex Krizhevsky提出的AlexNet网络结构模型赢得了2012届的冠军,刷新了Image Classification的几率。因此,要研究CNN类型深度学习模型在图像分类上的应用,AlexNet就不得不谈,这是CNN在图像分类上的经典模型。
下面先看看AlexNet的结构图:
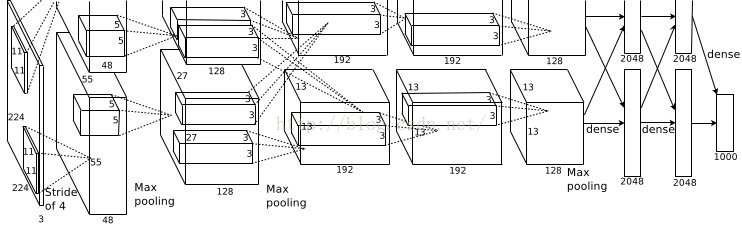
下面对其结构进行详细的分析,具体分析过程请看下面的流程图:
- conv1阶段DFD(data flow diagram):
In [13]:
Image(filename="/Users/youwei.tan/Documents/1.png")
Out[13]:
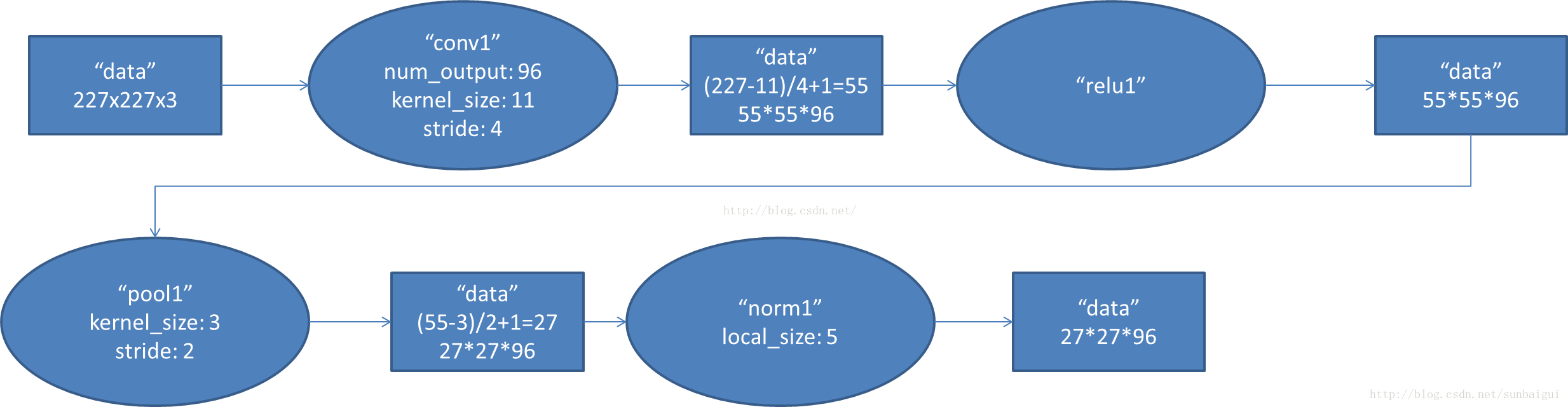
- conv2阶段DFD(data flow diagram):
In [6]:
Image(filename="/Users/youwei.tan/Documents/2.png")
Out[6]:
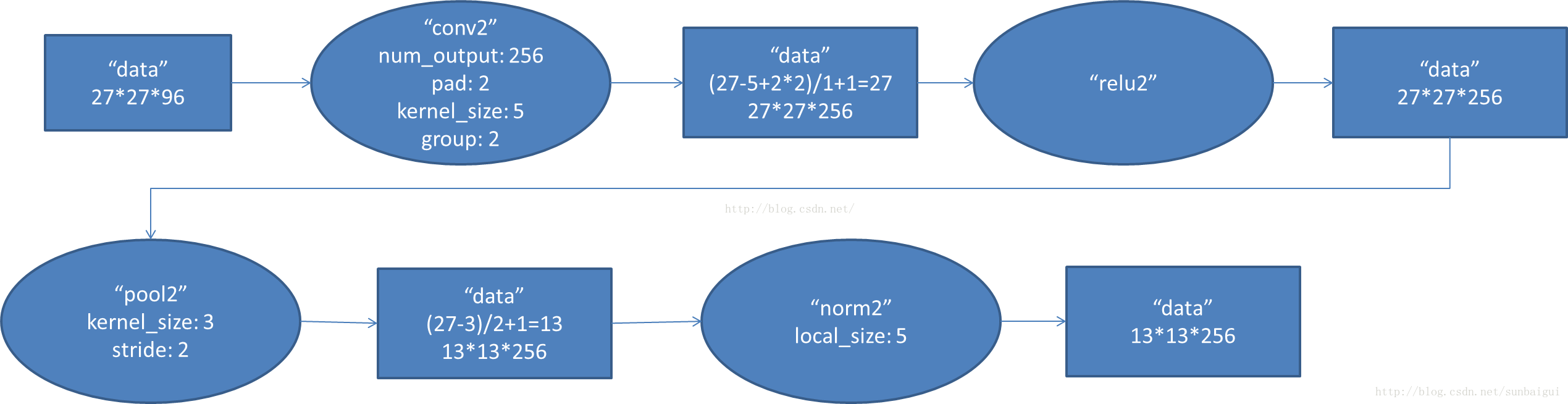
- conv3阶段DFD(data flow diagram):
In [7]:
Image(filename="/Users/youwei.tan/Documents/3.png")
Out[7]:

- conv4阶段DFD(data flow diagram):
In [8]:
Image(filename="/Users/youwei.tan/Documents/4.png")
Out[8]:

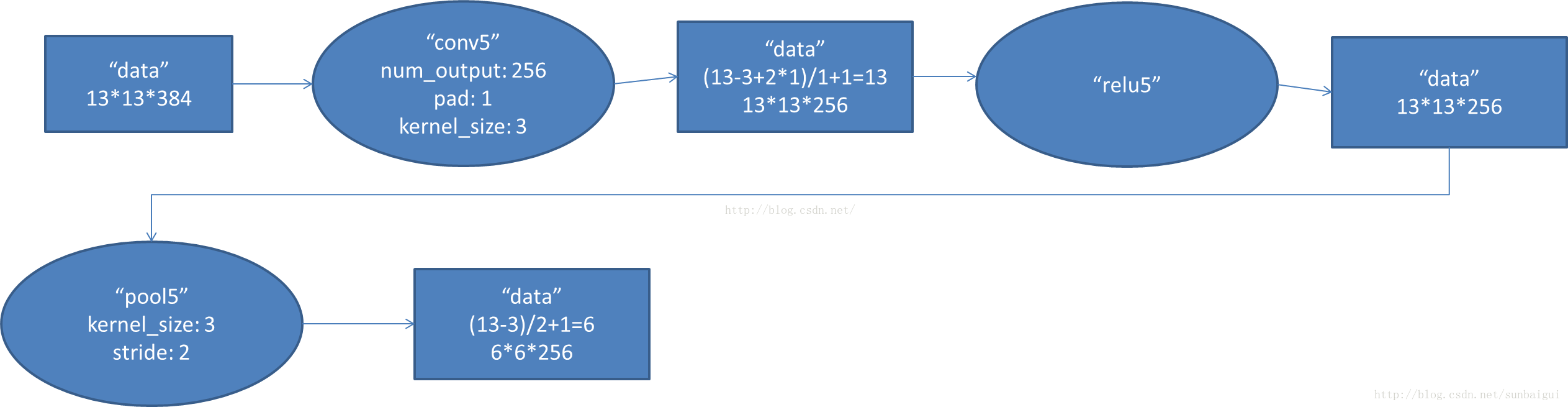
- conv5阶段DFD(data flow diagram):
In [9]:
Image(filename="/Users/youwei.tan/Documents/5.png")
Out[9]:
- fc6阶段DFD(data flow diagram):
In [10]:
Image(filename="/Users/youwei.tan/Documents/6.png")
Out[10]:
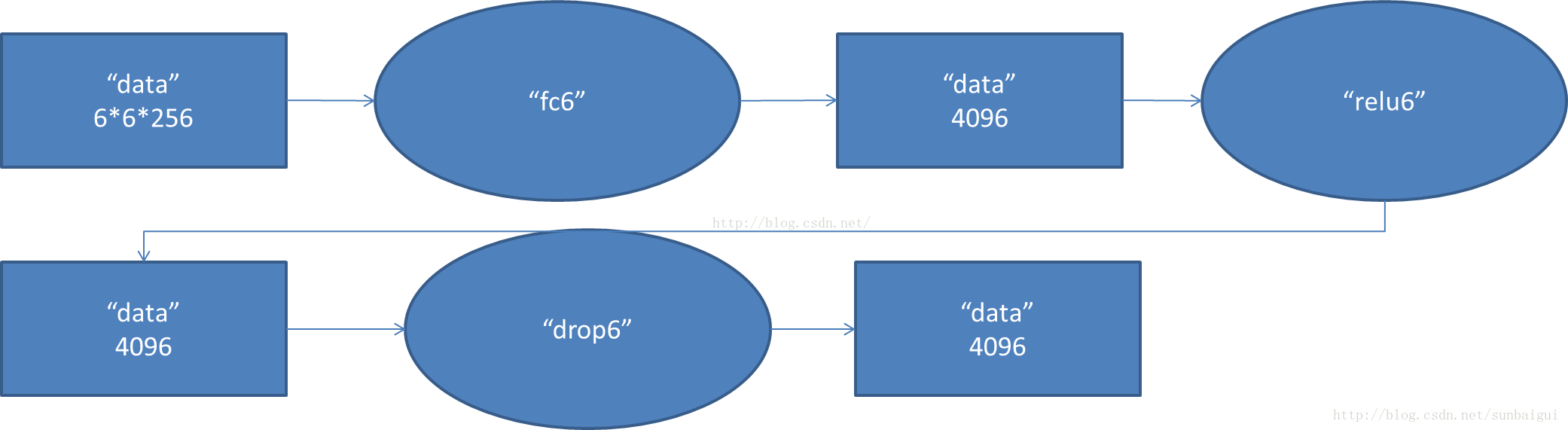
- fc7阶段DFD(data flow diagram):
In [11]:
Image(filename="/Users/youwei.tan/Documents/7.png")
Out[11]:
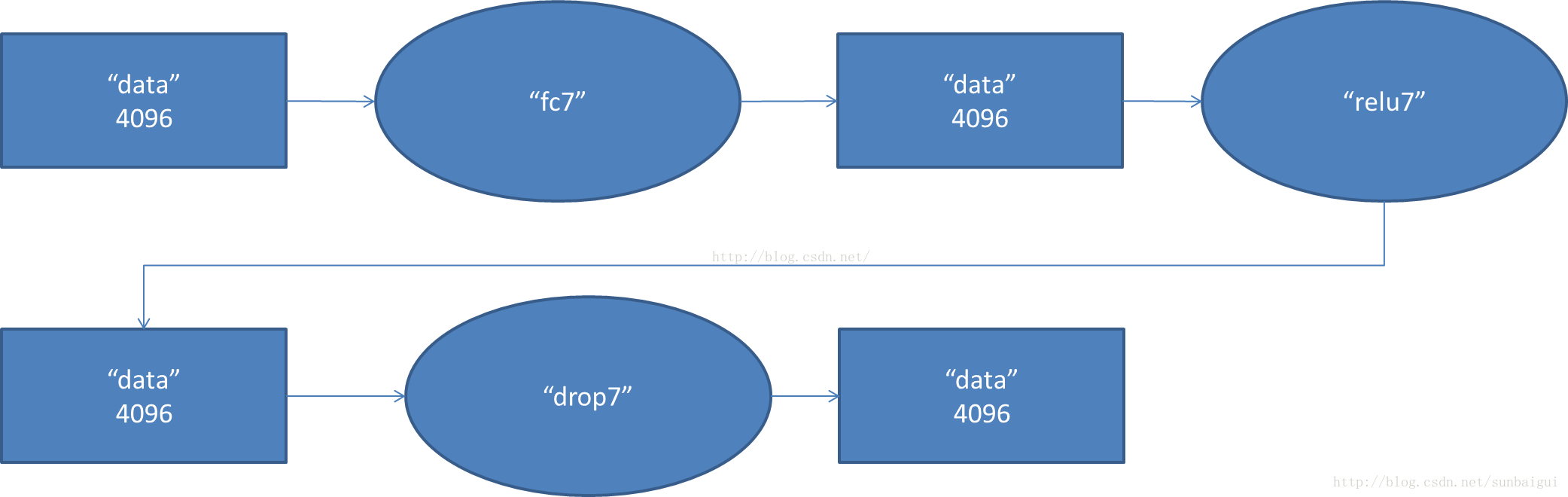
- fc8阶段DFD(data flow diagram):
In [12]:
Image(filename="/Users/youwei.tan/Documents/8.png")
Out[12]:

理解了AlexNet模型的结构,实现AlexNet的代码应该不难了,在网上看到了已经有大神用tensorflow实现了AlexNet(代码出处:http://blog.csdn.net/chenriwei2/article/details/50615753 ) 下面直接搬过来,具体代码如下:
In [6]:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# load数据
# import input_data
# mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 定义网络超参数
learning_rate = 0.001
training_iters = 200000
batch_size = 64
display_step = 20
# 定义网络参数
n_input = 784 # 输入的维度
n_classes = 10 # 标签的维度
dropout = 0.8 # Dropout 的概率
# 占位符输入
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
keep_prob = tf.placeholder(tf.float32)
# 卷积操作
def conv2d(name, l_input, w, b):
return tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(l_input, w, strides=[1, 1, 1, 1], padding='SAME'),b), name=name)
# 最大下采样操作
def max_pool(name, l_input, k):
return tf.nn.max_pool(l_input, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME', name=name)
# 归一化操作
def norm(name, l_input, lsize=4):
return tf.nn.lrn(l_input, lsize, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=name)
# 定义整个网络
def alex_net(_X, _weights, _biases, _dropout):
# 向量转为矩阵
_X = tf.reshape(_X, shape=[-1, 28, 28, 1])
# 卷积层
conv1 = conv2d('conv1', _X, _weights['wc1'], _biases['bc1'])
# 下采样层
pool1 = max_pool('pool1', conv1, k=2)
# 归一化层
norm1 = norm('norm1', pool1, lsize=4)
# Dropout
norm1 = tf.nn.dropout(norm1, _dropout)
# 卷积
conv2 = conv2d('conv2', norm1, _weights['wc2'], _biases['bc2'])
# 下采样
pool2 = max_pool('pool2', conv2, k=2)
# 归一化
norm2 = norm('norm2', pool2, lsize=4)
# Dropout
norm2 = tf.nn.dropout(norm2, _dropout)
# 卷积
conv3 = conv2d('conv3', norm2, _weights['wc3'], _biases['bc3'])
# 下采样
pool3 = max_pool('pool3', conv3, k=2)
# 归一化
norm3 = norm('norm3', pool3, lsize=4)
# Dropout
norm3 = tf.nn.dropout(norm3, _dropout)
# 全连接层,先把特征图转为向量
dense1 = tf.reshape(norm3, [-1, _weights['wd1'].get_shape().as_list()[0]])
dense1 = tf.nn.relu(tf.matmul(dense1, _weights['wd1']) + _biases['bd1'], name='fc1')
# 全连接层
dense2 = tf.nn.relu(tf.matmul(dense1, _weights['wd2']) + _biases['bd2'], name='fc2') # Relu activation
# 网络输出层
out = tf.matmul(dense2, _weights['out']) + _biases['out']
return out
# 存储所有的网络参数
weights = {
'wc1': tf.Variable(tf.random_normal([3, 3, 1, 64])),
'wc2': tf.Variable(tf.random_normal([3, 3, 64, 128])),
'wc3': tf.Variable(tf.random_normal([3, 3, 128, 256])),
'wd1': tf.Variable(tf.random_normal([4*4*256, 1024])),
'wd2': tf.Variable(tf.random_normal([1024, 1024])),
'out': tf.Variable(tf.random_normal([1024, 10]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([64])),
'bc2': tf.Variable(tf.random_normal([128])),
'bc3': tf.Variable(tf.random_normal([256])),
'bd1': tf.Variable(tf.random_normal([1024])),
'bd2': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# 构建模型
pred = alex_net(x, weights, biases, keep_prob)
# 定义损失函数和学习步骤
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# 测试网络
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# 初始化所有的共享变量
init = tf.initialize_all_variables()
# 开启一个训练
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 获取批数据
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys, keep_prob: dropout})
if step % display_step == 0:
# 计算精度
acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})
# 计算损失值
loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.})
print ("Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy= " + "{:.5f}".format(acc))
step += 1
print ("Optimization Finished!")
# 计算测试精度
print ("Testing Accuracy:", sess.run(accuracy, feed_dict={x: mnist.test.images[:256], y: mnist.test.labels[:256], keep_prob: 1.}))
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
Iter 1280, Minibatch Loss= 105135.500000, Training Accuracy= 0.20312
Iter 2560, Minibatch Loss= 53449.058594, Training Accuracy= 0.26562
Iter 3840, Minibatch Loss= 46481.890625, Training Accuracy= 0.45312
Iter 5120, Minibatch Loss= 27159.894531, Training Accuracy= 0.46875
Iter 6400, Minibatch Loss= 24144.722656, Training Accuracy= 0.59375
Iter 7680, Minibatch Loss= 34462.066406, Training Accuracy= 0.51562
Iter 8960, Minibatch Loss= 29766.037109, Training Accuracy= 0.54688
Iter 10240, Minibatch Loss= 18833.246094, Training Accuracy= 0.62500
Iter 11520, Minibatch Loss= 14885.839844, Training Accuracy= 0.67188
Iter 12800, Minibatch Loss= 29879.960938, Training Accuracy= 0.56250
Iter 14080, Minibatch Loss= 24039.386719, Training Accuracy= 0.50000
Iter 15360, Minibatch Loss= 6645.172852, Training Accuracy= 0.76562
Iter 16640, Minibatch Loss= 18668.121094, Training Accuracy= 0.64062
Iter 17920, Minibatch Loss= 12958.103516, Training Accuracy= 0.78125
Iter 19200, Minibatch Loss= 11467.254883, Training Accuracy= 0.75000
Iter 20480, Minibatch Loss= 11780.928711, Training Accuracy= 0.78125
Iter 21760, Minibatch Loss= 17288.359375, Training Accuracy= 0.68750
Iter 23040, Minibatch Loss= 10288.304688, Training Accuracy= 0.79688
Iter 24320, Minibatch Loss= 10797.081055, Training Accuracy= 0.73438
Iter 25600, Minibatch Loss= 15526.394531, Training Accuracy= 0.68750
Iter 26880, Minibatch Loss= 5896.966309, Training Accuracy= 0.78125
Iter 28160, Minibatch Loss= 5986.314941, Training Accuracy= 0.78125
Iter 29440, Minibatch Loss= 14352.033203, Training Accuracy= 0.70312
Iter 30720, Minibatch Loss= 9299.230469, Training Accuracy= 0.79688
Iter 32000, Minibatch Loss= 12997.154297, Training Accuracy= 0.73438
Iter 33280, Minibatch Loss= 8444.686523, Training Accuracy= 0.78125
Iter 34560, Minibatch Loss= 8713.619141, Training Accuracy= 0.79688
Iter 35840, Minibatch Loss= 11031.250000, Training Accuracy= 0.76562
Iter 37120, Minibatch Loss= 14087.941406, Training Accuracy= 0.78125
Iter 38400, Minibatch Loss= 6499.219727, Training Accuracy= 0.78125
Iter 39680, Minibatch Loss= 7266.004883, Training Accuracy= 0.79688
Iter 40960, Minibatch Loss= 13199.544922, Training Accuracy= 0.65625
Iter 42240, Minibatch Loss= 7316.147949, Training Accuracy= 0.82812
Iter 43520, Minibatch Loss= 5919.269531, Training Accuracy= 0.84375
Iter 44800, Minibatch Loss= 4456.823242, Training Accuracy= 0.81250
Iter 46080, Minibatch Loss= 2113.104492, Training Accuracy= 0.93750
Iter 47360, Minibatch Loss= 4923.742188, Training Accuracy= 0.85938
Iter 48640, Minibatch Loss= 7970.073730, Training Accuracy= 0.75000
Iter 49920, Minibatch Loss= 5625.089844, Training Accuracy= 0.79688
Iter 51200, Minibatch Loss= 8557.619141, Training Accuracy= 0.82812
Iter 52480, Minibatch Loss= 4743.790039, Training Accuracy= 0.78125
Iter 53760, Minibatch Loss= 972.031982, Training Accuracy= 0.90625
Iter 55040, Minibatch Loss= 6338.499023, Training Accuracy= 0.81250
Iter 56320, Minibatch Loss= 9248.547852, Training Accuracy= 0.76562
Iter 57600, Minibatch Loss= 5703.125000, Training Accuracy= 0.85938
Iter 58880, Minibatch Loss= 10426.742188, Training Accuracy= 0.78125
Iter 60160, Minibatch Loss= 4342.888672, Training Accuracy= 0.84375
Iter 61440, Minibatch Loss= 7261.451660, Training Accuracy= 0.84375
Iter 62720, Minibatch Loss= 3899.342285, Training Accuracy= 0.89062
Iter 64000, Minibatch Loss= 3670.834229, Training Accuracy= 0.85938
Iter 65280, Minibatch Loss= 5787.583008, Training Accuracy= 0.82812
Iter 66560, Minibatch Loss= 6649.801758, Training Accuracy= 0.78125
Iter 67840, Minibatch Loss= 2080.366455, Training Accuracy= 0.92188
Iter 69120, Minibatch Loss= 7153.665039, Training Accuracy= 0.84375
Iter 70400, Minibatch Loss= 5228.269043, Training Accuracy= 0.82812
Iter 71680, Minibatch Loss= 9432.683594, Training Accuracy= 0.78125
Iter 72960, Minibatch Loss= 1656.271851, Training Accuracy= 0.92188
Iter 74240, Minibatch Loss= 2362.667236, Training Accuracy= 0.89062
Iter 75520, Minibatch Loss= 4994.963867, Training Accuracy= 0.85938
Iter 76800, Minibatch Loss= 691.407837, Training Accuracy= 0.92188
Iter 78080, Minibatch Loss= 3261.704102, Training Accuracy= 0.89062
Iter 79360, Minibatch Loss= 4440.437500, Training Accuracy= 0.84375
Iter 80640, Minibatch Loss= 5165.506348, Training Accuracy= 0.85938
Iter 81920, Minibatch Loss= 2232.877441, Training Accuracy= 0.92188
Iter 83200, Minibatch Loss= 2232.522949, Training Accuracy= 0.85938
Iter 84480, Minibatch Loss= 1921.781006, Training Accuracy= 0.93750
Iter 85760, Minibatch Loss= 5770.326172, Training Accuracy= 0.79688
Iter 87040, Minibatch Loss= 2022.952881, Training Accuracy= 0.92188
Iter 88320, Minibatch Loss= 1921.537109, Training Accuracy= 0.90625
Iter 89600, Minibatch Loss= 8427.068359, Training Accuracy= 0.75000
Iter 90880, Minibatch Loss= 3777.687012, Training Accuracy= 0.85938
Iter 92160, Minibatch Loss= 1407.593140, Training Accuracy= 0.90625
Iter 93440, Minibatch Loss= 3493.047363, Training Accuracy= 0.82812
Iter 94720, Minibatch Loss= 3549.630371, Training Accuracy= 0.90625
Iter 96000, Minibatch Loss= 4050.996338, Training Accuracy= 0.89062
Iter 97280, Minibatch Loss= 2689.620605, Training Accuracy= 0.87500
Iter 98560, Minibatch Loss= 775.571289, Training Accuracy= 0.92188
Iter 99840, Minibatch Loss= 4966.501465, Training Accuracy= 0.81250
Iter 101120, Minibatch Loss= 468.303955, Training Accuracy= 0.96875
Iter 102400, Minibatch Loss= 4239.565430, Training Accuracy= 0.87500
Iter 103680, Minibatch Loss= 2601.228760, Training Accuracy= 0.90625
Iter 104960, Minibatch Loss= 2539.465820, Training Accuracy= 0.84375
Iter 106240, Minibatch Loss= 3445.990234, Training Accuracy= 0.92188
Iter 107520, Minibatch Loss= 2020.942261, Training Accuracy= 0.89062
Iter 108800, Minibatch Loss= 2290.115479, Training Accuracy= 0.84375
Iter 110080, Minibatch Loss= 5105.082520, Training Accuracy= 0.84375
Iter 111360, Minibatch Loss= 2792.384521, Training Accuracy= 0.90625
Iter 112640, Minibatch Loss= 3714.771973, Training Accuracy= 0.84375
Iter 113920, Minibatch Loss= 2331.506348, Training Accuracy= 0.82812
Iter 115200, Minibatch Loss= 5542.223633, Training Accuracy= 0.87500
Iter 116480, Minibatch Loss= 2068.789795, Training Accuracy= 0.87500
Iter 117760, Minibatch Loss= 3032.279541, Training Accuracy= 0.85938
Iter 119040, Minibatch Loss= 2303.545166, Training Accuracy= 0.89062
Iter 120320, Minibatch Loss= 1151.952393, Training Accuracy= 0.93750
Iter 121600, Minibatch Loss= 2172.850342, Training Accuracy= 0.92188
Iter 122880, Minibatch Loss= 1365.023438, Training Accuracy= 0.96875
Iter 124160, Minibatch Loss= 2074.203613, Training Accuracy= 0.90625
Iter 125440, Minibatch Loss= 3134.413330, Training Accuracy= 0.90625
Iter 126720, Minibatch Loss= 1457.720703, Training Accuracy= 0.92188
Iter 128000, Minibatch Loss= 7626.540039, Training Accuracy= 0.87500
Iter 129280, Minibatch Loss= 332.535400, Training Accuracy= 0.95312
Iter 130560, Minibatch Loss= 3173.010010, Training Accuracy= 0.81250
Iter 131840, Minibatch Loss= 2052.775879, Training Accuracy= 0.89062
Iter 133120, Minibatch Loss= 915.511108, Training Accuracy= 0.93750
Iter 134400, Minibatch Loss= 2391.861572, Training Accuracy= 0.89062
Iter 135680, Minibatch Loss= 1909.811890, Training Accuracy= 0.87500
Iter 136960, Minibatch Loss= 1870.513428, Training Accuracy= 0.87500
Iter 138240, Minibatch Loss= 3669.521973, Training Accuracy= 0.87500
Iter 139520, Minibatch Loss= 3938.454834, Training Accuracy= 0.87500
Iter 140800, Minibatch Loss= 3682.827393, Training Accuracy= 0.85938
Iter 142080, Minibatch Loss= 773.881226, Training Accuracy= 0.89062
Iter 143360, Minibatch Loss= 2542.113770, Training Accuracy= 0.82812
Iter 144640, Minibatch Loss= 1390.634399, Training Accuracy= 0.95312
Iter 145920, Minibatch Loss= 1816.718994, Training Accuracy= 0.92188
Iter 147200, Minibatch Loss= 2383.392822, Training Accuracy= 0.84375
Iter 148480, Minibatch Loss= 2805.485352, Training Accuracy= 0.90625
Iter 149760, Minibatch Loss= 4273.811035, Training Accuracy= 0.85938
Iter 151040, Minibatch Loss= 2829.233154, Training Accuracy= 0.90625
Iter 152320, Minibatch Loss= 2350.943848, Training Accuracy= 0.87500
Iter 153600, Minibatch Loss= 1390.092407, Training Accuracy= 0.92188
Iter 154880, Minibatch Loss= 1447.536255, Training Accuracy= 0.85938
Iter 156160, Minibatch Loss= 2814.929688, Training Accuracy= 0.92188
Iter 157440, Minibatch Loss= 1454.184570, Training Accuracy= 0.92188
Iter 158720, Minibatch Loss= 1053.621826, Training Accuracy= 0.90625
Iter 160000, Minibatch Loss= 268.273071, Training Accuracy= 0.96875
Iter 161280, Minibatch Loss= 421.640625, Training Accuracy= 0.93750
Iter 162560, Minibatch Loss= 554.997803, Training Accuracy= 0.95312
Iter 163840, Minibatch Loss= 756.904907, Training Accuracy= 0.92188
Iter 165120, Minibatch Loss= 2533.083496, Training Accuracy= 0.90625
Iter 166400, Minibatch Loss= 1262.960327, Training Accuracy= 0.90625
Iter 167680, Minibatch Loss= 987.682190, Training Accuracy= 0.93750
Iter 168960, Minibatch Loss= 2693.651367, Training Accuracy= 0.87500
Iter 170240, Minibatch Loss= 2195.717285, Training Accuracy= 0.92188
Iter 171520, Minibatch Loss= 2571.887451, Training Accuracy= 0.87500
Iter 172800, Minibatch Loss= 632.802551, Training Accuracy= 0.96875
Iter 174080, Minibatch Loss= 1144.768799, Training Accuracy= 0.90625
Iter 175360, Minibatch Loss= 1107.609863, Training Accuracy= 0.89062
Iter 176640, Minibatch Loss= 962.998108, Training Accuracy= 0.93750
Iter 177920, Minibatch Loss= 475.736450, Training Accuracy= 0.95312
Iter 179200, Minibatch Loss= 454.031738, Training Accuracy= 0.96875
Iter 180480, Minibatch Loss= 1643.504272, Training Accuracy= 0.93750
Iter 181760, Minibatch Loss= 520.336853, Training Accuracy= 0.96875
Iter 183040, Minibatch Loss= 5099.615723, Training Accuracy= 0.82812
Iter 184320, Minibatch Loss= 1832.333374, Training Accuracy= 0.92188
Iter 185600, Minibatch Loss= 5085.391602, Training Accuracy= 0.87500
Iter 186880, Minibatch Loss= 1165.275635, Training Accuracy= 0.90625
Iter 188160, Minibatch Loss= 436.611694, Training Accuracy= 0.95312
Iter 189440, Minibatch Loss= 729.550781, Training Accuracy= 0.92188
Iter 190720, Minibatch Loss= 631.992798, Training Accuracy= 0.92188
Iter 192000, Minibatch Loss= 254.609497, Training Accuracy= 0.95312
Iter 193280, Minibatch Loss= 1927.740479, Training Accuracy= 0.90625
Iter 194560, Minibatch Loss= 0.000000, Training Accuracy= 1.00000
Iter 195840, Minibatch Loss= 735.920166, Training Accuracy= 0.95312
Iter 197120, Minibatch Loss= 93.257446, Training Accuracy= 0.98438
Iter 198400, Minibatch Loss= 328.502441, Training Accuracy= 0.93750
Iter 199680, Minibatch Loss= 1295.930298, Training Accuracy= 0.92188
Optimization Finished!
('Testing Accuracy:', 0.96875)















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









