







浅析Gym中的env
近期在Gym上做有关强化学习的实验,用的是OpenAI Gym环境,但是我对于其中的state、observation、action存在疑问,到底这些量都包含什么呢?
然后我就去官网的Forum上去找,虽然有人存在相同的疑问,却没有人给出回答,所以只能自己去看Github上的环境代码了。现在将对Pendulum-v0进行简要分析,后面用到其他环境时将同样会分享出来。
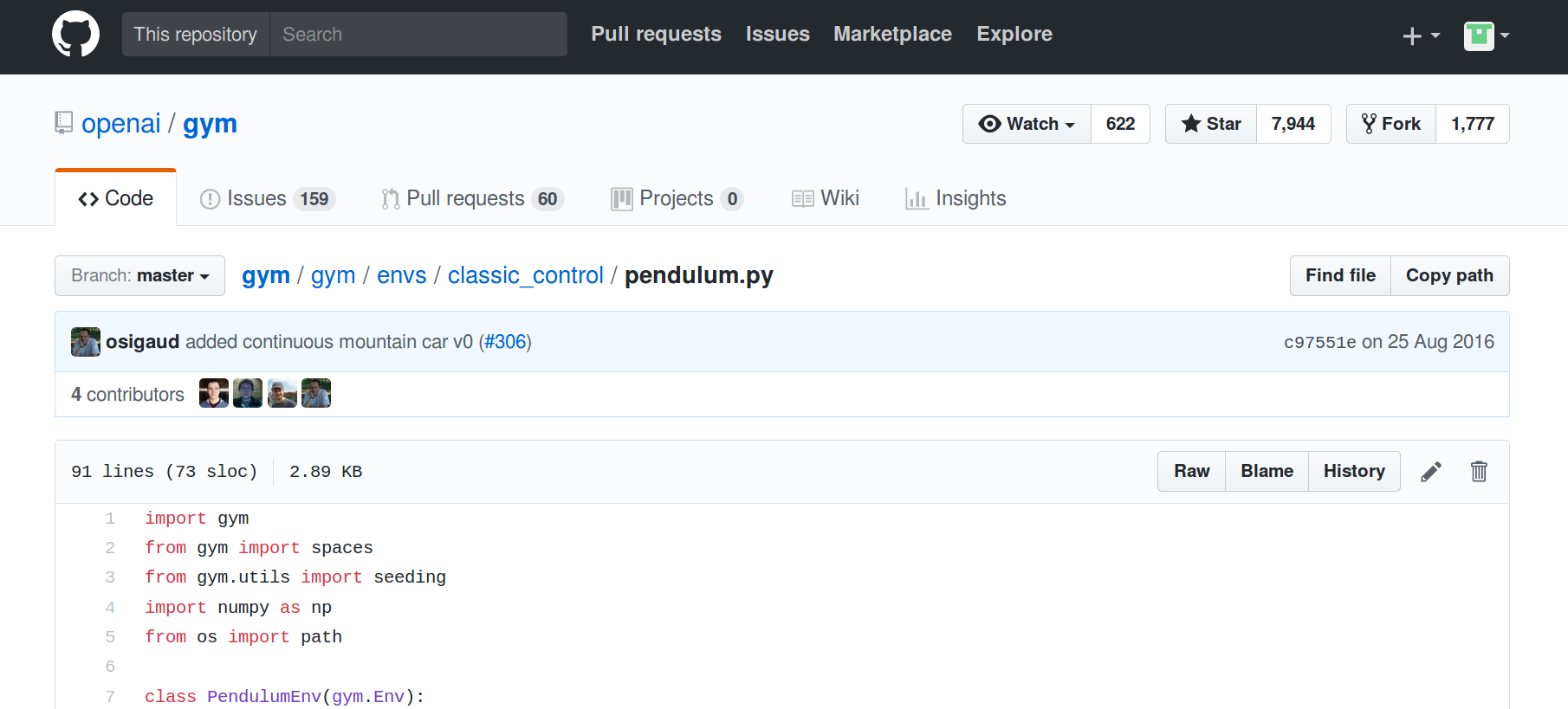
上面这就是Github上的Pendulum的实现代码。
首先,明确目标,我们想要知道Pendulum环境中的state、observation、action分别是什么。我们现在带着问题对代码进行分析,先来看看_get_obs()函数:
def _get_obs(self):
theta, thetadot = self.state
return np.array([np.cos(theta), np.sin(theta), thetadot])此外,同样可以看出observation包括了cos(th)、sin(th)、thdot三个量。
上面这二者的定义很符合我们在强化学习中学到的知识,state是最原始的环境内部的表示,observation则是state的函数。比如说,我们所看见的东西并不一定就是它们在世界中的真实状态,而是经过我们的大脑加工过的信息。
紧接着,我们找到了如下语句:
self.action_space = spaces.Box(low=-self.max_torque, high=self.max_torque, shape=(1,))到此为止,我们最初的三个疑问便解决了。那奖励呢?奖励是怎么计算的?
我们找到如下代码:
costs = angle_normalize(th)**2 + .1*thdot**2 + .001*(u**2)return self._get_obs(), -costs, False, {}costs包含三项,一是angle_normalize(th)**2,二是.1*thdot**2,三是.001*(u**2)。第一项我们后面分析;第二项表示对于角速度的惩罚,毕竟如果我们在到达目标位置(竖直)之后,如果还有较大的速度的话,就越过去了;第三项是对于输入力矩的惩罚,我们所使用的力矩越大,惩罚越大,毕竟力矩×角速度=功率,还是小点的好。
最后,我们对angle_normalize(th)**2进行分析,显然,这是对于当前倒立摆与目标位置的角度差的惩罚,那到底th表示哪个角度呢?
对于angle_normalize()函数分析如下:
def angle_normalize(x):
return (((x+np.pi) % (2*np.pi)) - np.pi)
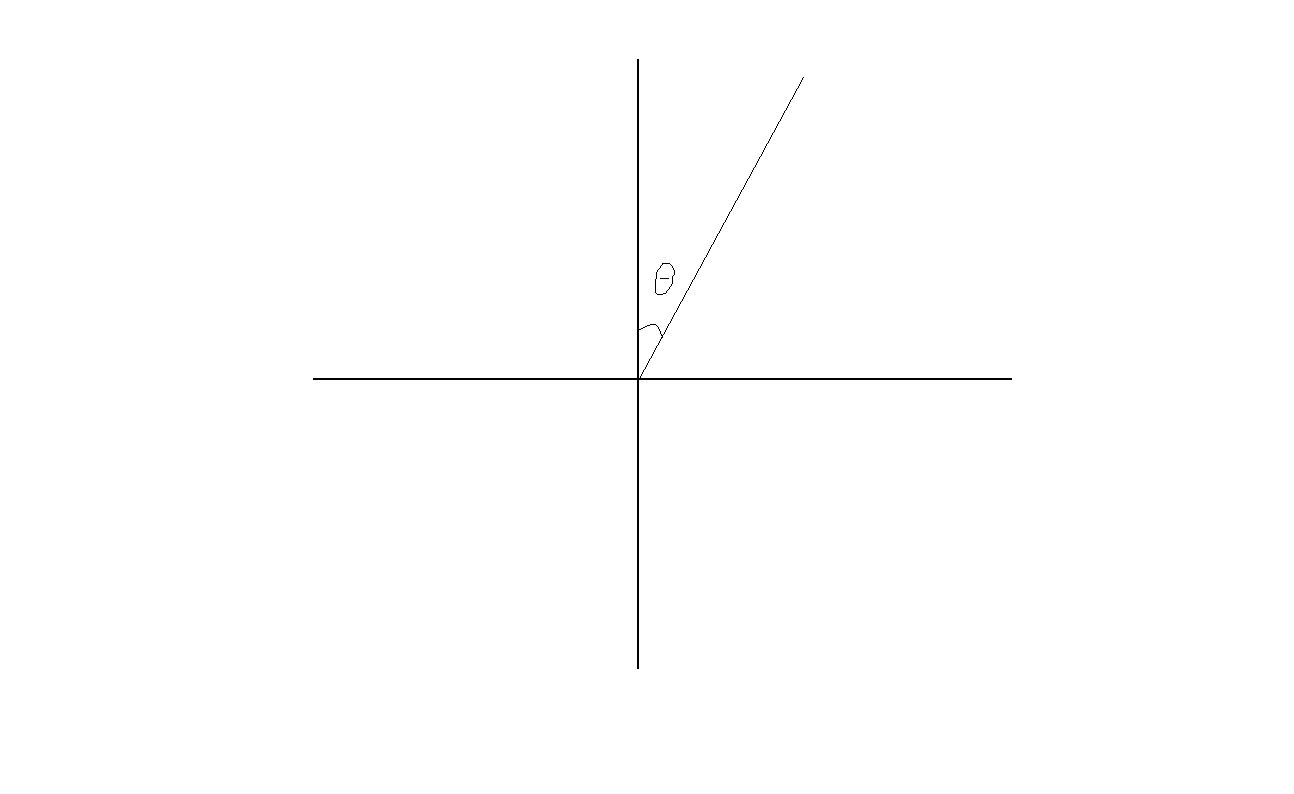
这就是我们的th,至此,我们的分析就告一段落啦~
对了,我们可以通过下面的代码对于observation、action的维度进行验证:
print env.observation_space
print env.action_space
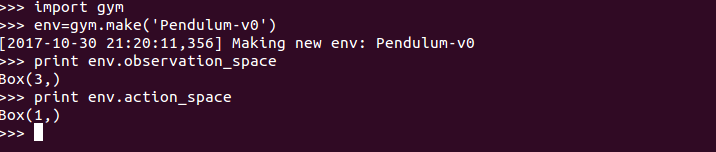
嗯,和我们上面的分析一致,OK。
再啰嗦一下,里面对于torque、th和thdot都是有限制的:
self.max_speed=8
self.max_torque=2.
high = np.array([1., 1., self.max_speed])
self.action_space = spaces.Box(low=-self.max_torque, high=self.max_torque, shape=(1,))
self.observation_space = spaces.Box(low=-high, high=high)cos和sin都是大于-1小于1,thdot大于-8小于8,torque大于-2小于2,至于单位我们就不用考虑咯。
对了,我们通常使智能体进行学习时,通常会设置episode的数量以及每一个episode中step的数量,值得注意的是,在gym中,绝大多数环境默认的max_episode_steps=200,也就是说对于一些环境的step函数永远不会返回一个True的done而言,最多也就跑200个step:
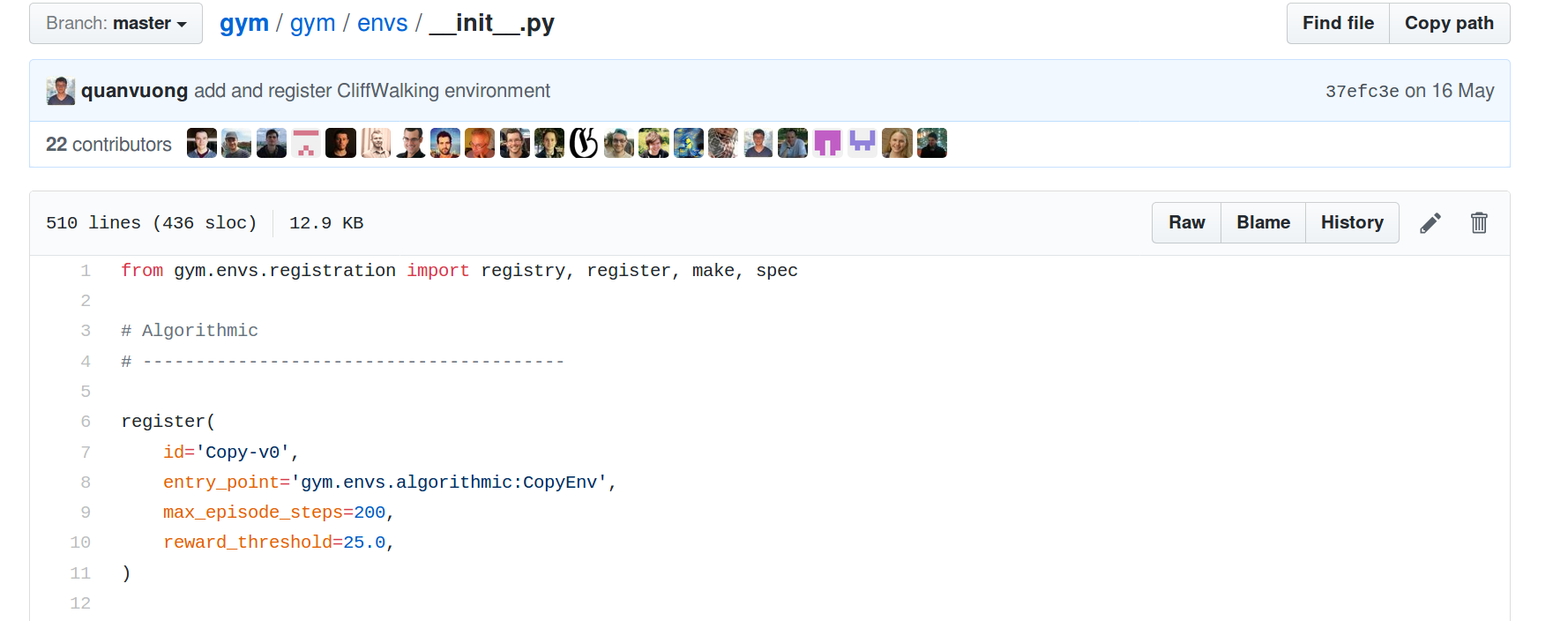
当然,对于这里的Pendulum也是一样,在200个step之后,就会将done设为True,虽然class PendulumEnv中没有将done设为True:

关于Pendulum我们就分析到这里了,下一个环境再见~

















 1359
1359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









