







第八课(上):学习与规划的结合
我们在《第一课:强化学习简介》中聊到过学习与规划的概念,它们的本质区别是:“学习”时,智能体并未对环境进行建模,因此只能与实际环境交互,从而在trial-and-error中学习;而“规划”时,智能体在自己的脑海中对环境构建了一个模型(虽然不一定准确),然后自己与这个模型进行交互,在该模型中进行推演,从而对策略进行改进。这两种方法各有利弊:“学习”方法是model-free的,因而免去了建模的麻烦,也就不用理会建模过程中可能存在的误差,缺点是必须要与实际环境进行大量交互,这在某些场景下是难以达成的,比如说在机器人控制中,我们难以在实际机器人上采集大量数据;“规划”方法则可以在模型中推演,从而极大地提升训练效率,但是却又引入了环境建模的误差(如果我们并不知道环境的真实模型的话),有时候这种误差将导致算法效果极其糟糕。
在本文中,我们将要介绍如何将“学习”与“规划”结合起来,利用二者的优点得到一个更好的算法。具体内容包括:Model-Based RL、Dyna Architectures、Simulation-Based Search、Bayesian Model-Based RL,其中Simulation-Based Search将在《第八课(下):基于Simulation的搜索方法》中进行介绍。
首先介绍基于模型的强化学习(Model-Based RL)。顾名思义,我们得先有一个模型,因此基于模型的强化学习是直接从经验中学习模型,这与我们前面讲到的Policy-Based RL是直接从经验中学习策略一样。学习到模型之后,就可以利用该模型进行规划了,如《第三课:动态规划》中说到的各种方法都可以用起来,不过这一课我们要介绍的可不是第三课中的内容,因为我们的目的是将“学习”与“规划”结合起来。
所谓的智能体对环境建模,其实是指我们要得到一个模型,该模型表达了智能体对于世界的理解,显然这不能一蹴而就(因为没有一个先知能够告诉智能体真实的世界模型是怎样的),而是得慢慢学习,当然我们可以通过引入一个较好的先验,使得我们的智能体站在巨人的肩膀上继续学习。David Silver说“The model is the agent's view of what the MDP is.”,我觉得这句话很有启发性,所以给出来以供大家思考。
聊到基于模型的强化学习,我们不得不聊一下它的优缺点。这种方法的优点是,我们能够通过监督学习高效率地习得模型,并且由于已知模型的形式,我们可以推断该模型的不确定程度。当然,万事万物都有其两面性,“模型”既然带来了好处,那必然也有其缺点:它将引入模型的误差,加上我们值函数估计的误差,这就有了两个误差源,令人不是很开心。
在《第二课:马尔科夫决策过程》里面,我们说对于环境建模实际上就是建立MDP模型。MDP模型通常包括状态集S,动作集A,转移概率矩阵P以及奖励函数R。一般我们默认智能体是知道状态集S、动作集A的全部信息的,所以我们所谓的对环境建模也就变成了求取P与R:
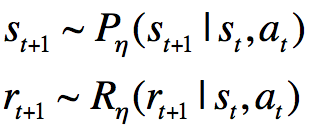
这里,我们假定状态转移分布与奖励分布是独立的:
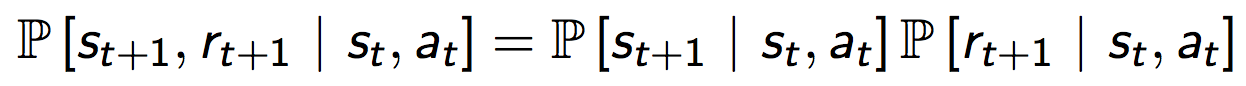
注意,R与值函数V是不一样的,R指的是简单的reward函数,比如下棋,开始一直为0,最后赢了为1,输了为0.而V则会将最后的奖励向前面的状态进行折算。
讲了这么多,关键问题是如何学习模型呢?通过监督学习:
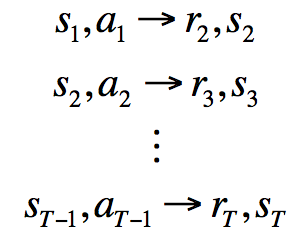
其中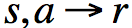
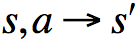
的概率分布。对于
因为是一个监督学习问题,所以我们需要指定假设空间(也即模型的学习范围),比如Table Lookup Model、Linear Expectation Model、Linear Gaussian Model、Gaussian Process Model、Deep Belief Network Model等。下面我们以Table Lookup Model为例来说说如何学习一个模型,并利用该模型进行规划。

这页PPT中介绍了两种Tabular方法,一种是参数化的方法,计算P、R,一种是非参数化方法,即直接记录经验(just remember things)。我们这里使用第一种方法对环境进行建模:

从左侧的经验中计算得到右侧转移概率分布以及奖励,现在我们可以开始进行规划了。当然这个问题可以用值迭代、策略迭代、树搜索等规划算法来解决,但是这里我们要讲另一种既简单又强大的规划方法:Sample-Based Planning。
动态规划中讲到的规划不是直接利用模型来对策略进行估计和改进么?是的,但是规划的定义是说利用模型进行计算,而不需要与环境进行交互,所以动态规划仅仅只是规划的一种方法而已,Sample-Based方法虽然不是直接利用模型进行计算,但是它却利用模型进行采样了,因而也叫规划。
在我们利用模型得到样本之后,就可以利用这些样本对值函数进行学习了,MC、Sarsa、Q-learning都可以用来解决这一问题。比如,将MC方法应用于上面的例子:

利用MC方法学习值函数,也即对于值函数的更新为:

以V(B)为例,我们依次将样本代入上面的式子,计算可得V(B)=0.75。当然,这是增量式的算法,为了计算简便,我们也可以直接通过MC方法的定义式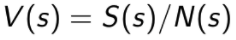
总结上面的Sample-Based RL:
real experience --> model --> simulated experience --> model-free RL
上面我们说过,Model-Based RL的缺点是会引入建模误差,这是无法避免的,此时我们的智能体最多学会一个次优策略,该策略与存在误差的模型相对应。那我们应该如何处理这一问题?两种解决方案:1)舍去模型,使用model-free方法;2)显式推断模型的不确定程度。
聊了这么多其实都是关于Model-Based RL的,现在我们来看一下本文的重点:Dyna Architectures。我们知道Model-Free方法是直接从real experience中学习值函数/策略,而Model-Based方法则是从real experience中学习模型,然后利用该模型产生simulated experience,并从该经验中规划值函数/策略。那我们将这两者结合将碰撞出什么样的火花?这就是Dyna的由来。Dyna如下所示:
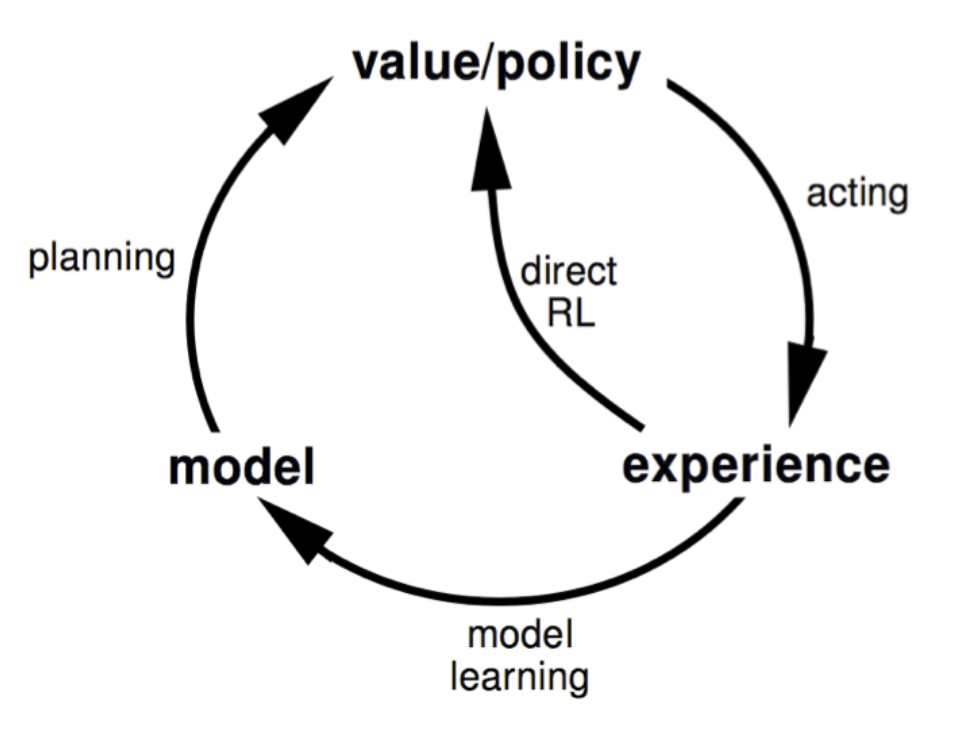
该结构中,我们首先从real experience中学习一个model,然后利用这个模型生成simulated experience,最后结合real/simulated experience来学习和规划值函数/策略。
值得注意的是,Dyna是一种结构,而不是一个确切的算法,我们可以将这种结构套在其他算法上面,比如Q-learning。原始的Q-learning算法如下:

该算法无非就是在每一个step时套用Q-learning的Q(s,a)更新公式,所以,我们可以很轻易地写出Dyna-Q:

先利用real experience对Q(s,a)进行一次更新,然后对模型进行更新,之后利用该模型模拟N个step,同时更新Q(s,a)。注意,这里的(s, a)是之前的经验中的。
对于一个简单的Maze问题,我们用Tabular Method对环境进行建模,训练结果如下:
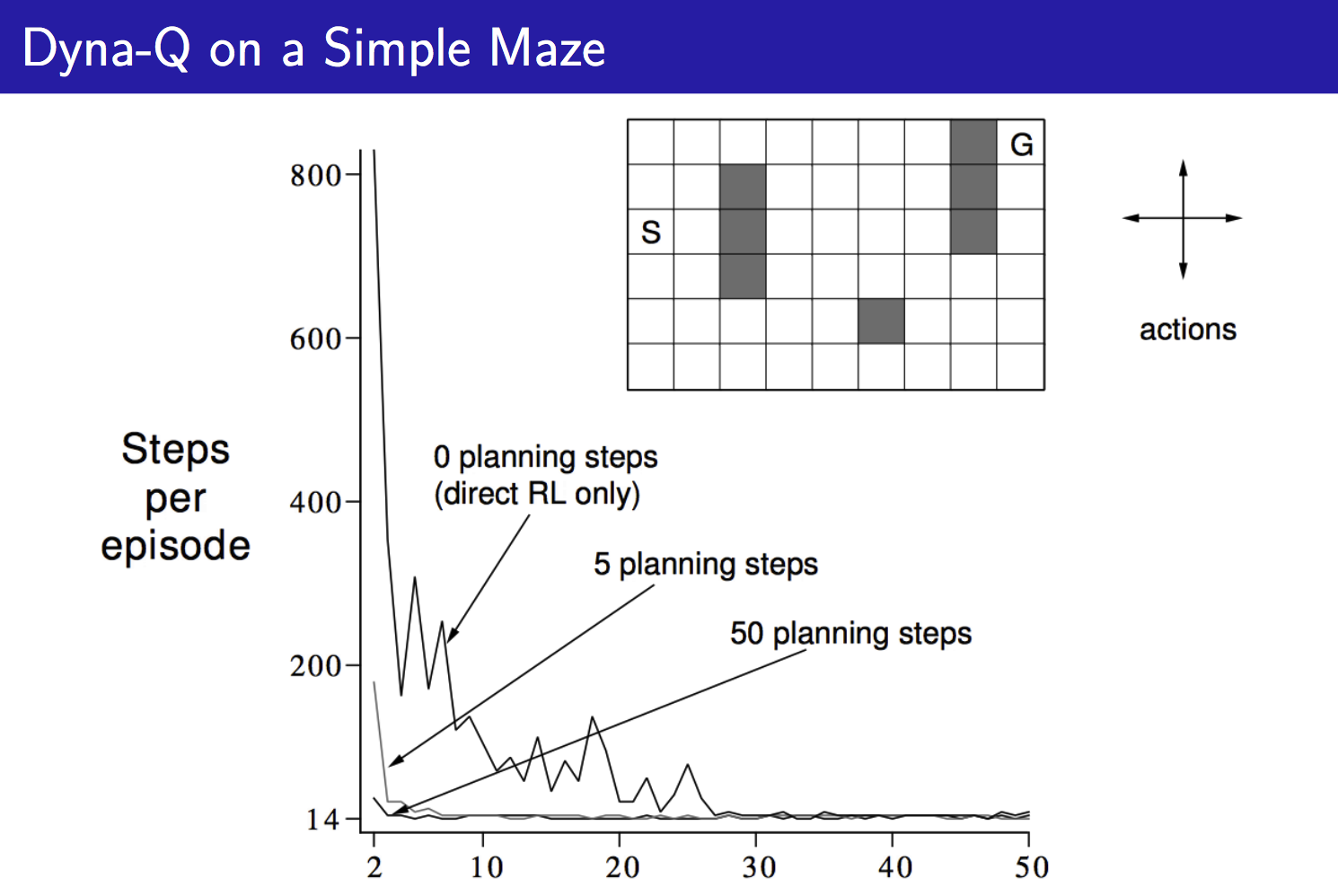
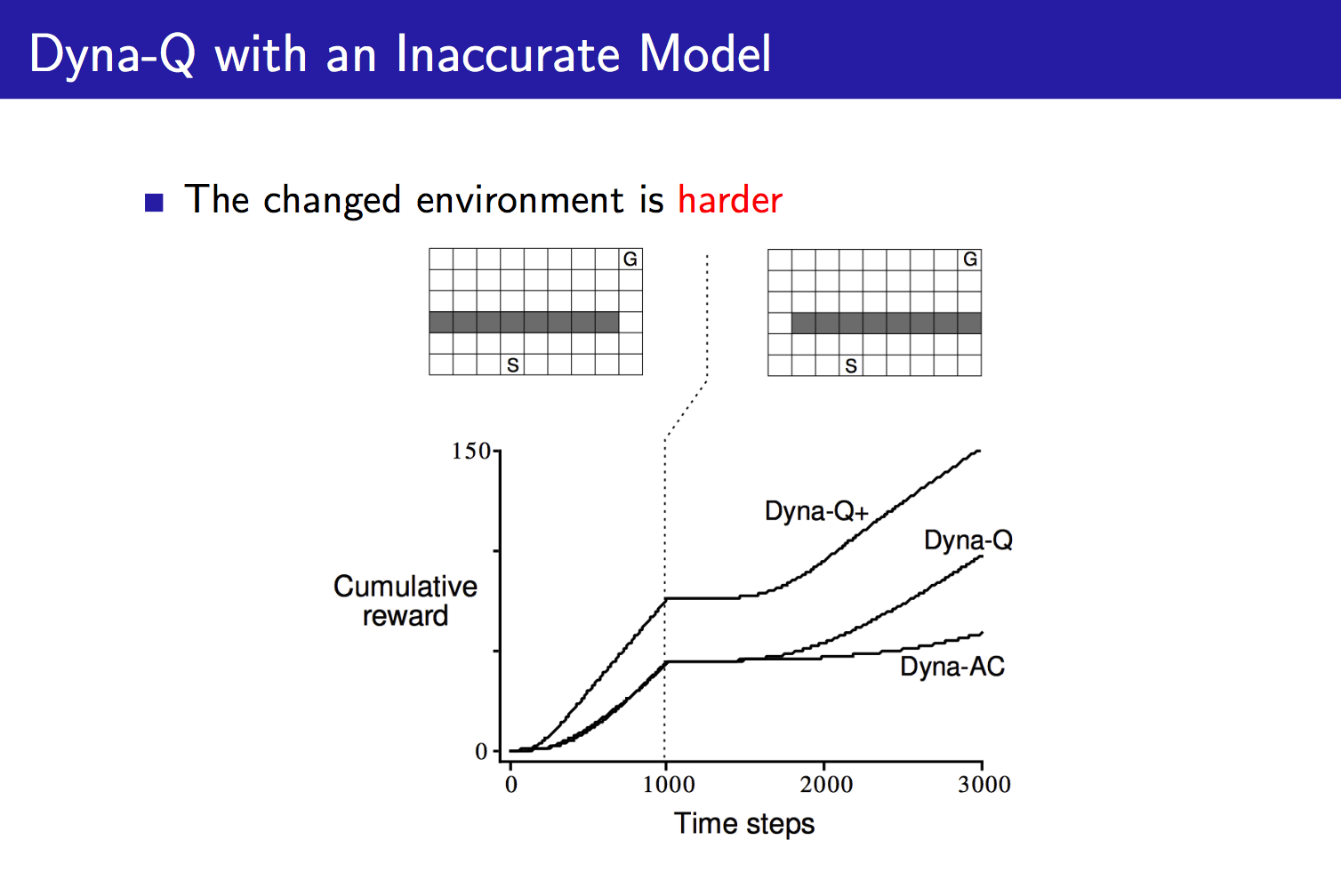
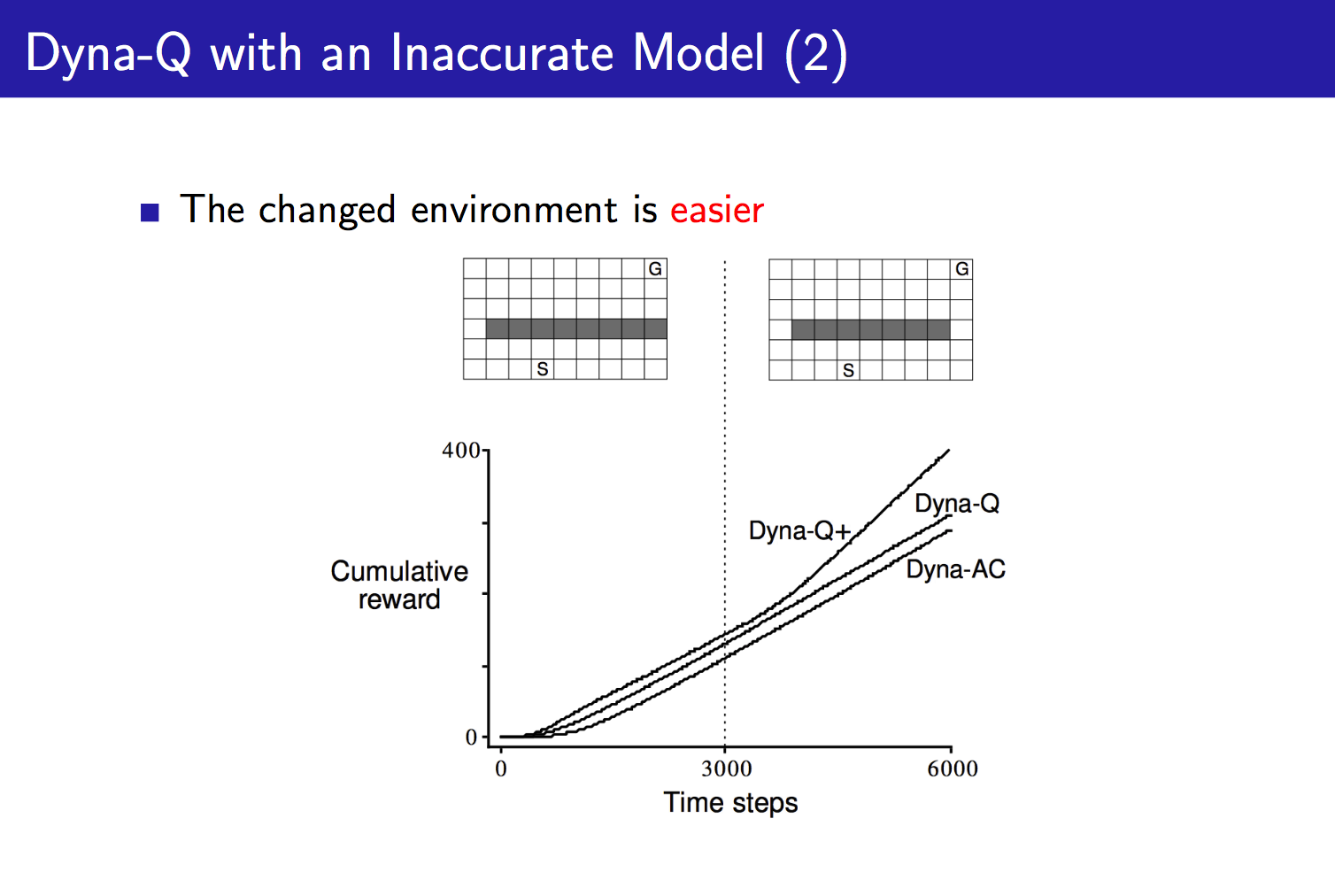
最后我们通过介绍Bayesian Model-Based RL来结束本文。
在概率论中,存在着两个互相争论的学派,一个是频率学派,一个是贝叶斯学派。我们知道,频率学派试图直接为事件建模,而贝叶斯学派则并不刻画事件本身,而是从观察者角度出发,建立观察者对于事件的认知。关于这两派的具体介绍可以参考知乎:频率学派和贝叶斯学派有何不同?言归正传,既然是Bayesian Model-Based RL,自然是从贝叶斯学派的角度出发,给出先验,然后通过观察,得到后验:

与一般的Model-Based方法不同的是,Bayesian Model-Based方法有很多模型假设(进行参数的分布估计,而不是点估计),而不是仅仅只有一个模型假设(并不估计参数的分布),换句话说,我们可以用模型参数的分布概率来表示模型的不确定程度,如果我们对于该分布求取期望,就可以得到Bayesian值函数:
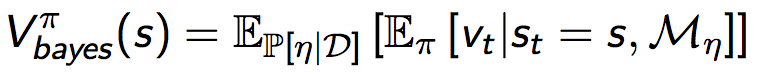
最优Bayesian值函数为:
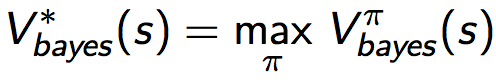
PPT中关于它的介绍:

这里有提到这种方法中所构造的规划问题比之前要更难,因为值函数在以前的基础上多了一个对参数分布求期望,所以我们并不能像以前一样那么轻松地将V表示为贝尔曼方程形式。
以一个例子结束本文:

关于高斯过程回归(GP)可以参考浅谈高斯过程回归,祝大家工作愉快~















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









