







在BN出现之前,权值初始化决定了神经网络的初始优化位置,如图6。
正向传播时,神经元的输出会被作为激活函数的输入来进行激活判断。如果神经元的输出不合适,则难以优化(恒为0或1),神经元的输出应当控制在均值为0,方差为1的范围内比较合适。
为了使神经元输出控制在这个范围内,如此处神经元输出范围为N~(0,1)正态分布,该神经元的输入有n个神经元,则权重矩阵元素初始化就应当为N~(0,1/n),如式5。在反向传播时,由于梯度的连乘效应(梯度=激活层1斜率*权重1*激活层2斜率*权重。。),权值的过大或过小会造成梯度爆炸或消失。所以梯度应当尽量保持在1左右。
对求梯度产生影响的有几个因素:激活函数求导(如sigmoid函数的梯度最高为0.25,易梯度消失,而tanh函数梯度最高为1,较为合适);权重(权重的取用考虑当前层的输入)。
2010年之前,权值初始化偏向单纯的数学随机选取。常值初始化仅用于偏差b的初始化,因为权值的常数初始化会导致神经网络的失效。
权值的初始化一般用均匀分布初始化、高斯分布初始化、截断高斯分布初始化随机选取。在此基础上的改进版本为自适应初始化(0均值,标准差自适应张量size的截断高斯分布)。
之后,Lecun提出了lecun初始化(期望为0,标准差自适应前向传播的均匀分布)[48],如式6。
2010年,Glorot和Bengio提出的Xavier初始化(均值为0,标准差同时考虑前向和反向传播的正态分布/均匀分布)[49]。他们的背景假设是激活函数在0附近近似为恒等映射(线性函数),如tan函数(tanh(x)=x)。
2012年alexnet中使用非0对称relu函数后,权值初始化也做出了相应改进,也就是何恺明提出的he初始化(均值0,标准差自适应的高斯分布)[47],基于PRelu激活函数的初始化,如式6,考虑前向传播和反向传播对方差的放缩系数为常数,故二者等价。PRelu激活函数下模型收敛较Xavier更好。
2015年Sergey Ioffe和 Christian Szegedy提出了批量标准化BN。BN考虑,神经网络是由于每层的权值参数不同,导致的每层输入数据分布也会不同,这对学习率和参数初始化的要求就会很高。
BN的原理是,将每层的数据进行以单样本单通道为单位进行小批量规范化,并且为了同时兼顾非线性函数的表示能力,在标准化后使用可单层学习的参数scale和shift来进行恢复[41]。
在正向传播时,数学表达式如式7,在反向传播时,对输入x梯度计算链式法则,对两参数梯度计算更新参数。BN减少了数据分布变化引起的内部协变量,又避免了单层规范化可能带来的偏差值爆炸和非线性表达失效的问题。如此,由于数据分布被规范化,正向传播时数据分布移动到激活函数中心非饱和区域加速优化,反向传播时激活函数斜率接近1加速收敛。随着BN的出现,收敛函数更加平滑,权值初始化设计的问题已经基本被解决。

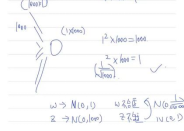
式5 权值初始化的取值推导

![]()
![]()
![]()
![]()
式6 依次为Lecun初始化、Xavier初始化(高斯/均匀分布)、he初始化(高斯)(fan_in指当前网络层的输入神经元个数,fan_out指当前网络层的输出神经元个数)


图6 BN出现前后的优化观景loss landscape















 8023
8023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









