







######《Unsupervised Discovery of Object Landmarks as Structural Representations》
- CVPR2018,Yuting Zhang et al。
本文使用无监督的方式来发现结构表现的目标关键点。
网络结构:
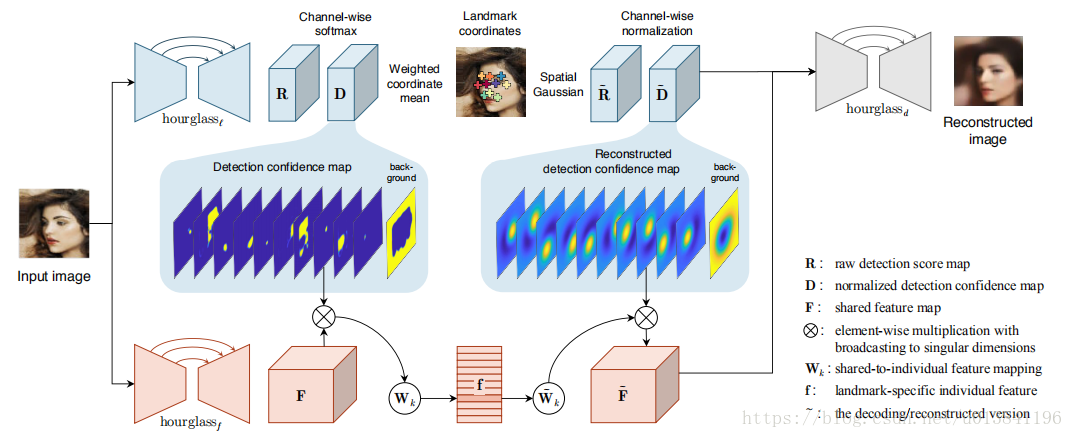
采用的是名为 hourglass 的网络构架,以图片作为输出,该网络输出 k+1 个 channel,含有 k 个 landmark 和背景。对不同 landmark 用 softmax 生成 confidence。
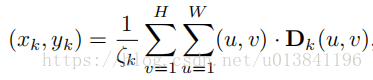
在如图公式中,Dk(u,v) 意思是第 k channel 中坐标为 (u,v) 的值,Dk 是 weight map,与对应坐标相乘,再除以总的权重和坐标乘积的和,从而生成该 channel 的 landmark 的 normalized 坐标。
soft constrain:
为了保证我们生成的诸landmark及其坐标是表达的我们想要的landmark而非其他latent representations,文章提出了几个soft constrain。
1,concentration constrain:

计算两个坐标轴上坐标的方差,设计如图示loss是为了使方差尽可能小

这里做了一个近似,使之转换成了Gau dis,更低的熵值意味着peak处更多的分布,换句话说,就是使landmark尽可能地突出出来。
2,separation constrain:
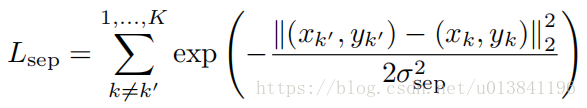
由于刚刚开始训练时候的输入是纯random distribution,故可能导致提取出的landmark聚集在中心,可能会导致separation效果不好,因此而落入local optima,故设计了该loss。
这个loss也不难理解,将不同channel间的坐标做差值,使得不同landmark尽可能不重叠。
3,Equivariance constraint:
这个比较好理解,就是某一个landmard在另一个image中变换坐标时应该仍能够很好地定位,在这里,作者介绍了他们实现landmark变换坐标的几个trick。
4,Cross-object correspondence:

本文模型认为不能保证同一object在不同情况检测时绝对的correspondence,文章认为这应该主要依赖于该特定pattern能够在网络生成的激活值展现一定的共性。
Local latent descriptors
这个des的目的是解决一个delimma:除了我们定义的landmark,可能还有一些latent representation,要复原一个image,仅仅landmarks是绝对不够的,所以需要一些其他的信息作为一个补充,但表达他们又有可能影响landmark的表达。

在这里,文章又用了另一个hourglass network,如图中左下角的F,就在我们之前提到的concentration costrain中,用一个高斯分布来将该channel对应的landmark突出出来,在这里,文章将他当做soft mask来用,用mask提取后再用一个linear operator来讲这些feature map映射到一个更低维的空间,至此,local latent descriptor就被生成了。
Landmark-based decoder

第一步,raw score map
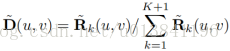
第二步,normalize
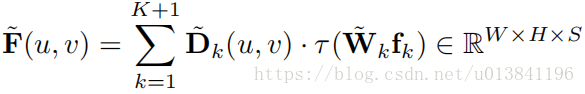
第三步,生成最终图像
在这里,wk是landmark-specific operator。
简言之,Dk是我们提出的landmark位置信息,fk是对应landmark的descriptor。
这里又提到了一个dilemma:在用mask的时候,越多的pixel被纳入是最理想的,但纳入太多又使得边缘的锐利不能体现,因为该文用了多个不同的超参数来尝试。
但是无监督的关键点学习是有用的,同人类的感知类似,潜在的发现对象的结构。
训练结果:

如同所示,自动的可以发现在语义上有意义的和固定位置的关键点,例如额头中心,眼,眼眉,鼻子和嘴角等。
参考:https://zhuanlan.zhihu.com/p/35693735
注:博众家之所长,集群英之荟萃。



















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











