







目录
1.实际应用

关于分类的一些应用
2.How to do Classification

首先,要收集data。


1.假设现在的model是
y
=
b
+
w
1
x
1
+
w
2
x
2
y=b+w1x1+w2x2
y=b+w1x1+w2x2,如果用Regression来想,我们希望蓝色的接近1,红色的接近-1,用绿色的线分开。
但如果出现右图的情况,蓝色的点有的接近1,有的>>1,这是用Regression就出问题,会得到紫色的线,而不会得到绿色的线。因为要使>>1的蓝点压小,所以绿色的线一定向右侧倾斜。
所以,用Regression,Penalize to the examples that are"too correct",即去惩罚太正确的点,也就是>>1的蓝点,容易受噪声/边缘点的影响。
2.并且,如果Class1,2,3之间没有关系,当作Regression来处理,不会有好的结果。
3.Ideal Alternatives(理想模型)

f
(
x
n
)
≠
y
n
f(x_n)\neq y_n
f(xn)=yn,
δ
=
1
\delta=1
δ=1
f
(
x
n
)
=
y
n
f(x_n)= y_n
f(xn)=yn,
δ
=
0
\delta=0
δ=0
损失函数的意思即统计错误的次数
L(f)越小代表在Training data上的错误次数越小。
4.原理准备
Two Boxes

🔽

将盒子Box1,Box2换成Class1,Class2
给一个x,即要分类的对象,我们需要
P
(
c
1
)
、
P
(
c
2
)
、
P
(
x
∣
c
1
)
、
P
(
x
∣
c
2
)
P(c1)、P(c2)、P(x|c1)、P(x|c2)
P(c1)、P(c2)、P(x∣c1)、P(x∣c2)四个值

以水系和一般系的宝可梦为例


图中每个点代表一种宝可梦的属性。
Gaussian distribution(高斯分布)
一般的,我们假设x的分布为高斯分布(最为常见的概率分布模型),也称为正态分布,为什么会往往选择高斯分布呢,概率论中的中心极限定理告诉我们答案。

这是高维的分布,其中均值为
μ
\mu
μ,协方差为
∑
\sum
∑


只要知道
μ
\mu
μ,
∑
\sum
∑,就可以算Gaussian的Likelihood,即图中79个点的机率。
因为79个点是独立的,所以Likelihood的式子就等于79点依次相乘。

关于
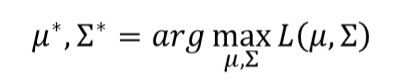
穷举所有的
μ
\mu
μ,
∑
\sum
∑,看哪一个能让上面Likelihood的式子最大。
μ ∗ \mu^* μ∗, ∑ ∗ \sum^* ∑∗的求法就按照上图的公式即可。
5.开始分类

开始二分类,根据高斯分布就可以计算
p
(
x
∣
C
1
)
p(x|C1)
p(x∣C1),
p
(
x
∣
C
2
)
p(x|C2)
p(x∣C2)


但是这样的正确率并不高,即使加到7维也没有太多的改善。
6.Modifying Model(改善模型)

我们可以看到,两组数据的
μ
\mu
μ,
∑
\sum
∑分别不同,参数过多导致很容易overfitting,所以要减少参数。
让Class1和Class2共享一个
∑
\sum
∑。

调整之后,唯一不同的就是
∑
\sum
∑的计算

最后的正确率可以达到73%,分界面变为线性。
但至于为什么会发生这种变化,因为是在高维空间发生的事情,所以很难人为地去做出解释。
7.总结三个步骤
• Function Set (Model)

• Goodness of a function
The mean 𝜇 and covariance Σ that maximizing the likelihood (the probability of generating data)
• Find the best function
8.最后高能!!!(Sigmoid function)

如上图,对式子进行变换,会得出Sigmoid function。
然后,又到了熟悉的Warning of Math😂

经过不断地变、变、变 🔽

可以观察到,第一项有系数
x
x
x,后面几项里其实都是参数。
我们就可以理解为x的系数其实就是
s
i
g
m
o
i
d
sigmoid
sigmoid中的参数
w
T
w^T
wT(这是个matrix),后面那些项可以看成是参数
b
b
b 。
那么在Generative model中我们的目标是寻找最佳的
N
1
,
N
2
,
μ
1
,
μ
2
,
∑
N1,N2,\mu1,\mu2,\sum
N1,N2,μ1,μ2,∑使
P
(
C
1
∣
x
)
P(C1|x)
P(C1∣x) maximise。
但我们能够化简呈线性的,那为什么还要舍近求远的求5个参数去将目标最优化呢?只有“两个参数”的方法我们叫做Discraminative model。
实际上,在大多数情况下,这两种方法各有利弊,但是实际上Discraminative model泛化能力比Generative model还是强不少的。什么时候Generative model更好呢?
• training data比较少的时候,需要靠几率模型脑补没有发生或的事情。
• training data中有noise。















 1094
1094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









