







 本文介绍了classification_report在机器学习中的作用,通过示例展示了其在鸢尾花分类问题中的应用。分类报告包括精确率、召回率和F1值等关键指标,以及它们的计算方式。精确率表示预测正确的正例比例,召回率衡量发现正例的能力,F1值是精确率和召回率的调和平均数。同时,文章还回顾了预测结果的分类术语,如TP、FP、TN和FN,并提供了混淆矩阵的基础知识。
本文介绍了classification_report在机器学习中的作用,通过示例展示了其在鸢尾花分类问题中的应用。分类报告包括精确率、召回率和F1值等关键指标,以及它们的计算方式。精确率表示预测正确的正例比例,召回率衡量发现正例的能力,F1值是精确率和召回率的调和平均数。同时,文章还回顾了预测结果的分类术语,如TP、FP、TN和FN,并提供了混淆矩阵的基础知识。
一、classification_report是什么?
话不多说,直接上图,看看长啥样:
下图是使用sklearn.linear_model中对数几率回归模型求解鸢尾花分类问题的分类报告:
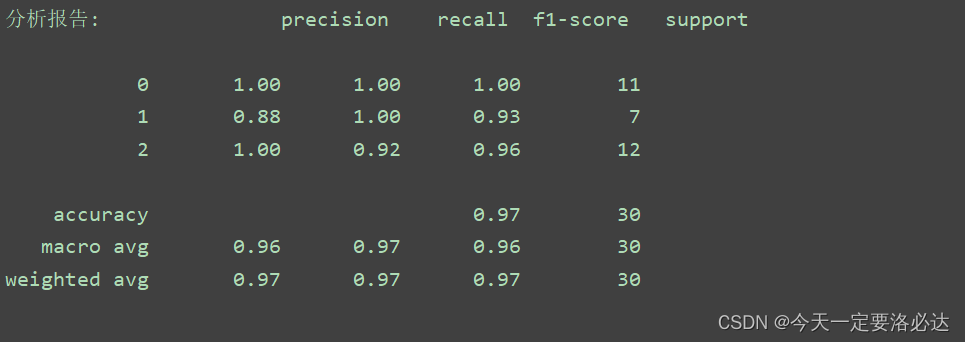
首先看列名,中文分别是“精确率”,“召回率”,“F1值”,样本数“”,我们接下来依次讲解这些内容。
行名分别是种类1,种类2…(这里的种类1是0,种类2是1,种类3是2),accuracy,macro avg(宏平均):算术平均
weighted avg(加权平均):除开本身的比例,还要算上该种类样本占所有样本的比例。
例如:本图macro avg=(1+0.93+0.96)/3=0.963
weighted avg=1×11/30+0.93×7/30+0.96×12/30=0.9676
二、预测结果分类(TP,FP,TN,FN)
我们回忆一下混淆矩阵的样子:
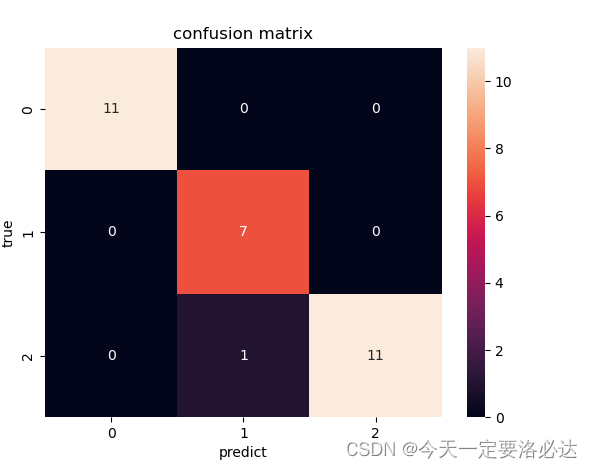
横坐标是预测的结果,纵坐标是真实的结果。如果一个真实数据类型为‘1’,但是它被预测为了‘0’,那么说明这个模型就预测错了。如果一个真实数据类型为‘1’,但是它被预测为了‘1’,那么说明这个模型就预测对了。
这个背景下,混淆矩阵里对角线上的元素就算预测对了
在这个概念下,我们引出TP,FP,TN,FN的概念:
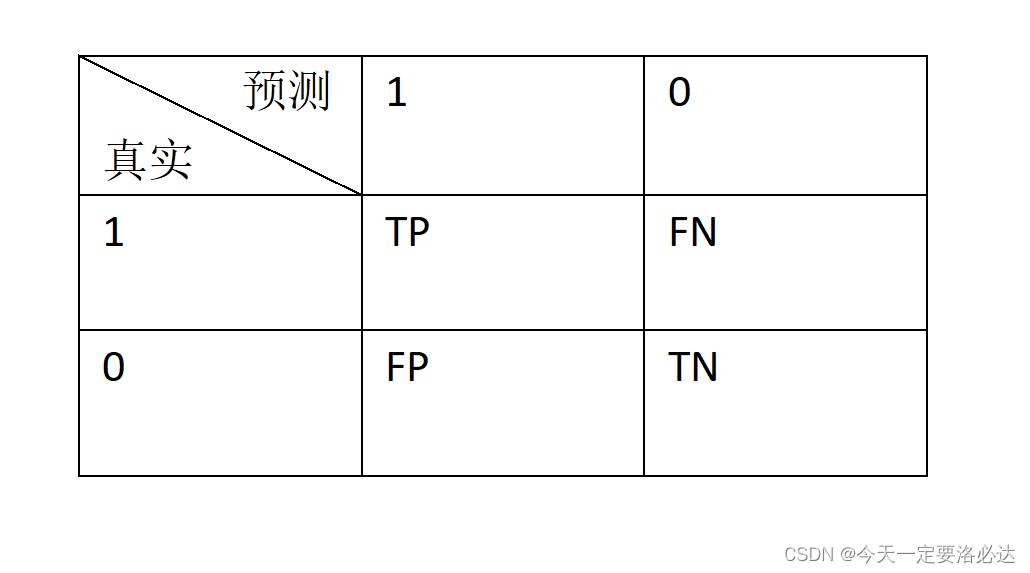
1)TP:实际为正,预测为正
2)FP:实际为正,预测为负
3)FN:实际为负,预测为正
4)TN:实际为负,预测为负
三.精确率,召回率,F1值
1)精确率
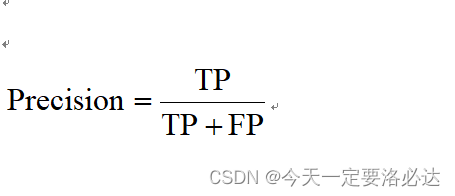
2)召回率

3)F1值

调用分析报告的代码(输入的是真实数据和预测数据):
classification_report(Y_test,Y_pre)

















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









