







🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
1. 背景介绍
Wu X, Fu X, Liu Y, et al. A large-scale benchmark for food image segmentation[C]//Proceedings of the 29th ACM international conference on multimedia. 2021: 506-515.
食品图像分割是一项关键且不可或缺的任务,对开发与健康相关的应用(例如估算食品热量和营养成分)至关重要。然而,现有的食品图像分割模型存在以下两个原因导致的性能不足问题:
- 缺乏高质量、具有细粒度食材标签和像素级位置掩码的食品图像数据集——现有数据集要么仅具有粗略的食材标签,要么规模较小。
- 食品的复杂外观使得在食品图像中定位和识别食材变得困难。例如,图像中的食材可能相互重叠,同一种食材在不同食品图像中的外观可能完全不同。
在本研究中,我们构建了一个新的食品图像数据集 FoodSeg103(及其扩展 FoodSeg154),该数据集包含9,490张图像。我们为这些图像标注了154个食材类别,每张图像平均拥有6个食材标签和像素级掩码。此外,我们提出了一种名为 ReLeM 的多模态预训练方法,该方法显式地为分割模型提供丰富且语义化的食品知识。
在实验中,我们选择了三种流行的语义分割方法(即基于扩张卷积的方法【17】、基于特征金字塔的方法【22】以及基于视觉Transformer的方法【54】)作为基线,并在我们的新数据集上评估了这些方法以及 ReLeM。我们相信 FoodSeg103(及其扩展 FoodSeg154)以及使用 ReLeM 预训练的模型可以作为基准,推动未来在细粒度食品图像理解方面的研究。
我们将所有这些数据集和方法公开,网址为 https://xiongweiwu.github.io/foodseg103.html。

食品计算近年来受到越来越多的公众关注,因为它为与食品和健康相关的研究和应用提供了核心技术【2, 9, 31, 43】。食品计算的一个重要目标是自动识别不同类型的食品,并分析其营养成分和热量值。在计算机视觉领域,相关研究包括菜品分类【11, 50, 52】、菜谱生成【14, 39, 46】和食品图像检索【6, 42】。大多数研究聚焦于将食品图像整体表示和分析,而没有明确定位或分类其单独的食材——即烹饪食品中的可见组成部分。前者称为食品图像分类,后者则是食品图像分割。
食品图像分割更为复杂,因为它的目标是识别每种食材类别,并在食品图像中定位其像素级的位置。例如,给定“汉堡”的图像,好的分割模型需要识别并标注“牛肉”“番茄”“生菜”“洋葱”和“面包”这些食材。
相比于通用物体图像的语义分割【3, 17, 22】,食品图像分割更具挑战性,原因包括:
-
食品外观的多样性:
- 同一食材因烹饪方式不同,外观可能差异巨大。例如,“菠萝”在肉类菜品中的外观与水果拼盘中的外观有很大不同。
- 不同食材可能外观非常相似。例如,“菠萝”和“土豆”在肉类菜品中的外观可能难以区分。
-
类别分布的不平衡:
- 食品数据集通常存在类别分布的不平衡现象,主要原因有:
- 大量食品图像集中于少数受欢迎的食品类别,而绝大多数食品类别并不常见。
- 数据集构建过程中存在选择偏差【44】。
- 食品数据集通常存在类别分布的不平衡现象,主要原因有:
为促进细粒度的食品图像分割研究,我们构建了一个名为FoodSeg103的大规模数据集,特点如下:
-
定义了103种食材类别,并使用这些标签标注了7,118张西式食品图像及对应的像素级分割掩码。
-
额外标注了2,372张亚洲食品图像,涵盖更为多样的食材,使其比FoodSeg103数据集更具挑战性。
- 该数据集定义了112种食材类别,其中55%的类别与FoodSeg103的数据集类别重叠。
-
综合两个数据集,共标注了154种食材类别,包含约60,000个分割掩码。
-
合并后的数据集命名为FoodSeg154。在数据标注过程中,我们进行了精心的数据选择、标签和掩码的多次迭代优化,以确保数据集的高质量。
-
在实验中,我们使用FoodSeg103进行域内训练和测试,使用FoodSeg154的额外部分进行跨域测试。
-
数据来源:
- FoodSeg103的数据源来自另一个食品数据集Recipe1M【41】,该数据集包含数百万张图像及烹饪菜谱,提供了关于“如何烹饪”和“需要哪些食材”的信息。
- 我们利用这些菜谱信息作为辅助信息,训练语义分割模型,这一方法被称为多模态知识迁移,并将我们的训练方法命名为ReLeM。
-
ReLeM方法:
- ReLeM通过将食品菜谱数据(以语言嵌入形式)与食品图像的视觉表示结合起来,实现了多模态信息的融合。
- 这种方法迫使视觉表示通过语言嵌入将同一食材在不同菜品中的外观在特征空间中“连接”起来(语言嵌入由食材标签及其烹饪说明提取)。
-
我们将提出的ReLeM模型应用到最先进的语义分割模型中,如CCNet【17】、Sem-FPN【22】和SeTR【54】。
-
在实验中,我们比较了使用ReLeM的变体模型与这些基线模型(包括卷积网络和Transformer骨干)的性能。
-
实验结果表明,ReLeM可以通用地应用于多种分割框架,并且在与SOTA CNN模型CCNet结合时能显著提高准确性。这验证了我们的知识迁移方法在性能更强的模型上效率更高,这一点非常符合多媒体社区的需求。
我们的贡献如下:
- 构建了一个大规模食品图像分割数据集FoodSeg103(及其扩展FoodSeg154),为食品图像的语义分割任务提供了一个有前景且具有挑战性的基准。
- 提出了利用菜谱数据的知识迁移方法ReLeM,可整合到不同的语义分割方法中以提升模型性能。
- 进行了广泛的实验,揭示了在FoodSeg103数据集上进行食品分割的挑战,并验证了基于ReLeM的多种基线方法的效率。
2. 方法
2.1 食品图像分割数据集
FoodSeg103 是 FoodSeg154 的子集,后者还包含了一部分亚洲食品图像及其注释。图2展示了一些示例图像及其注释。在 FoodSeg103 中,我们定义了103种食材类别,并为7,118张图像分配了这些类别标签和分割掩码。这些图像来自现有的菜谱数据集 Recipe1M【41】。在 FoodSeg154 的额外子集中,我们特别收集了2,372张亚洲食品图像,其多样性高于 FoodSeg103 中的西式食品。我们利用这一子集评估食品图像分割模型的领域适应性性能。我们已公开发布 FoodSeg103 以促进公共研究,但由于图像的保密性,目前无法公开亚洲食品数据集。

2.2 收集食品图像
我们以 FoodSeg103 为例,说明数据集构建过程,包括图像来源、类别整理和图像选择。
-
来源:我们使用 Recipe1M【28, 41】 作为源数据集。该数据集包含90万张带有烹饪说明和食材标签的图像,主要用于食品图像检索和菜谱生成任务。
-
类别:
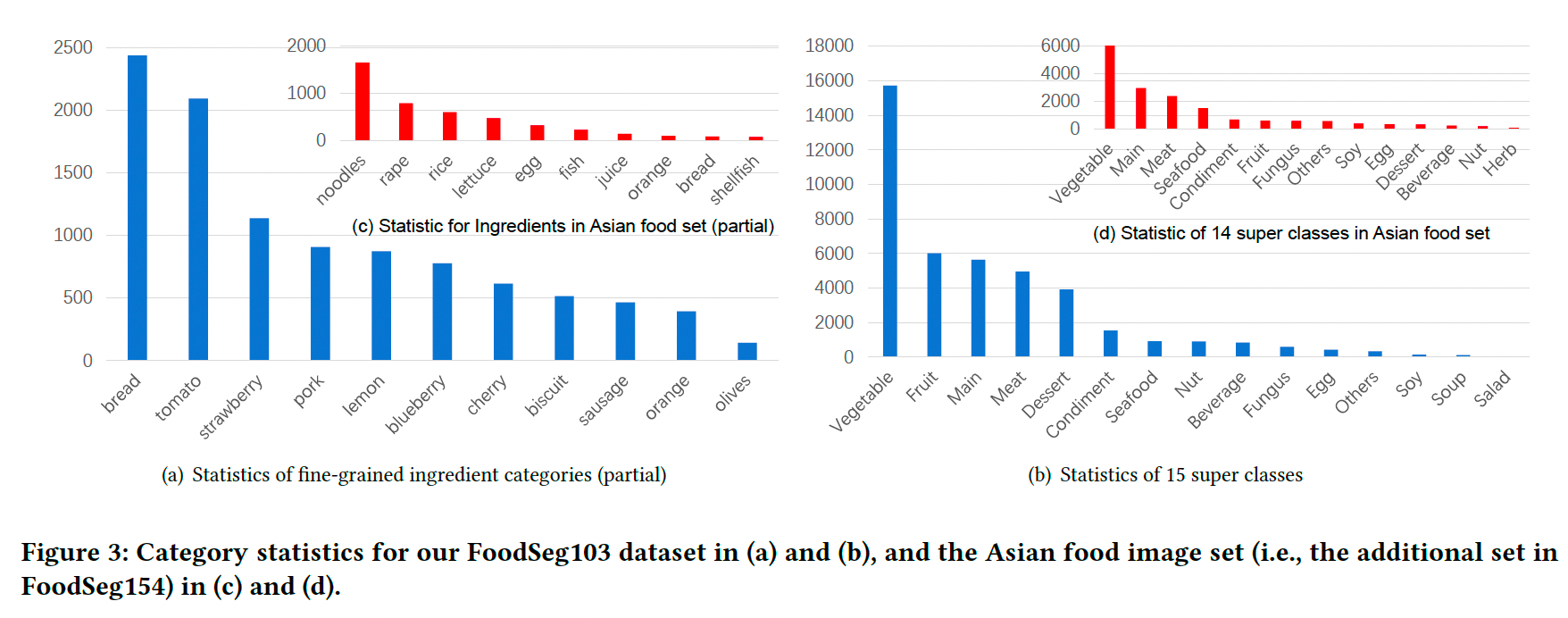
- 我们统计了 Recipe1M 中所有食材类别的频率。
- 虽然数据集中约有1,500种食材类别【40】,但大多数难以从图像中明确标注。因此,我们仅保留了前124种频率最高的食材类别(进一步精炼后减少为103种),并将不属于上述类别的食材分配到“其他”类别。
- 最终,我们将这些类别分为14个超类类别,例如“主食”(Main)类别包含“面条”和“米饭”等更细粒度的类别。
-
图像:
- 在每种细粒度食材类别中,我们基于以下两个标准从 Recipe1M 中采样图像:
- 图像中至少包含两种食材(可以是相同或不同类别),但不超过16种。
- 图像中的食材在视觉上清晰可见且易于标注。
- 最终,我们选择了7,118张图像进行分割掩码标注。
- 在每种细粒度食材类别中,我们基于以下两个标准从 Recipe1M 中采样图像:
2.3 标注食材标签和分割掩码
基于上述图像,下一步是标注分割掩码,即覆盖不同食材像素位置的多边形区域。这包括两个步骤:掩码标注和掩码优化。
-
标注:
- 我们委托了一家数据标注公司进行掩码标注,这是一项繁琐且耗时的工作。
- 每张图像由人工标注人员首先识别图像中的食材类别,为每种食材标记适当的类别标签,并绘制像素级掩码。
- 我们要求标注人员忽略覆盖面积小于图像总面积5%的微小区域,即使这些区域可能包含食材。
-
优化:
- 在接收到标注公司的所有掩码后,我们进行了整体优化。
- 优化的三个标准为:
- 修正错误标注的数据。
- 删除分配给少于5张图像的不常见类别标签。
- 合并视觉上相似的食材类别,例如“橙子”和“柑橘”。
- 经过优化后,食材类别从初始的125种减少到103种。
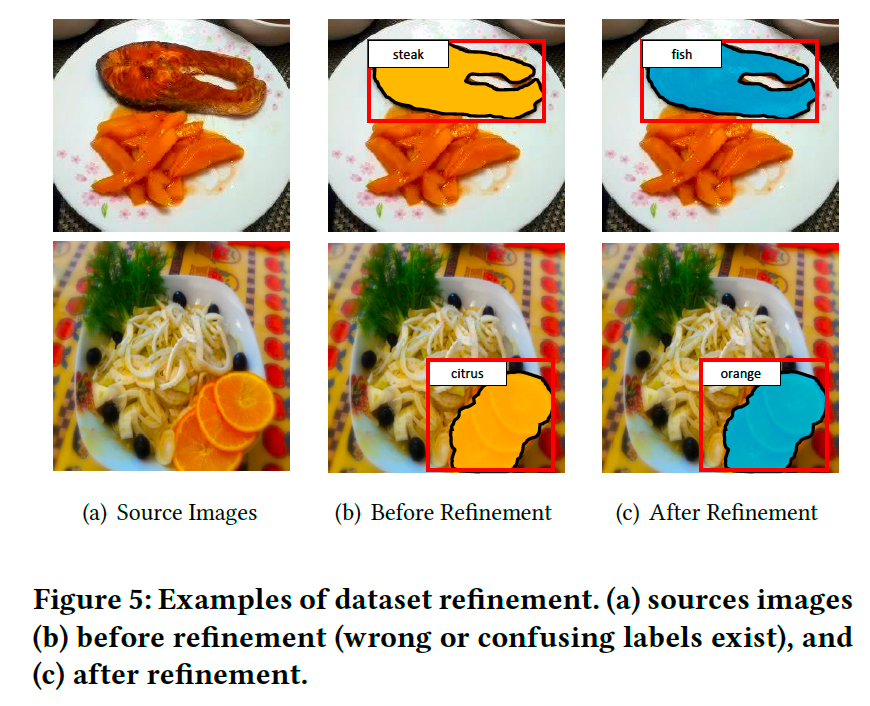
标注和优化工作耗时约一年。图2展示了一些数据示例,其中(a)为边界清晰、构图简单的案例,(b)和(c)为成分区域重叠、构图复杂的案例。
2.4 与食品图像数据集的对比
-
食品图像数据集:
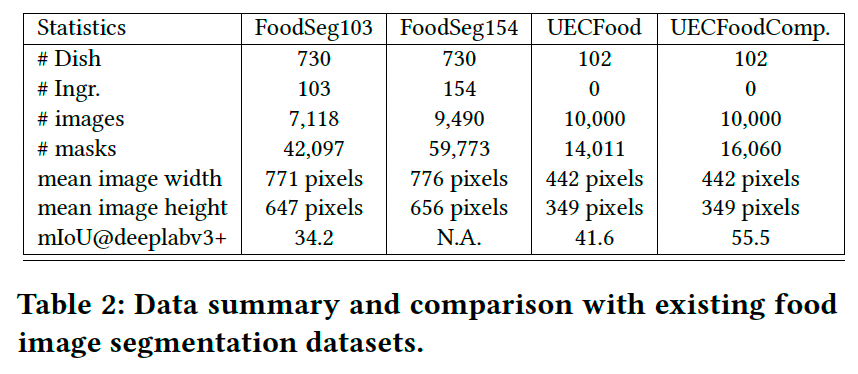
- 表1总结了对比结果,我们仅包含主要用于食品识别任务的数据集。
- 这些数据集包含图像和菜品级标签,但没有任何食材级注释。
- 虽然 Recipe1M 和 Recipe1M+ 包含每张图像的食材标签,但不提供分割掩码。
-
食品图像分割数据集:
- UECFoodPix【13】和 UECFoodPixComplete【35】 是仅有的两个食品图像分割的公共数据集,分别包含10k图像和102种菜品类别。
- 表2展示了详细对比结果,并突出了 FoodSeg103 和 FoodSeg154 的三个优势:
- FoodSeg 的像素级掩码数量(40k和60k)显著多于UEC数据集(仅10k)。
- FoodSeg 的注释掩码覆盖了食材级别,而UEC数据集仅覆盖整道菜品。
- FoodSeg 数据集在分析食品营养和估算热量方面更加实用。

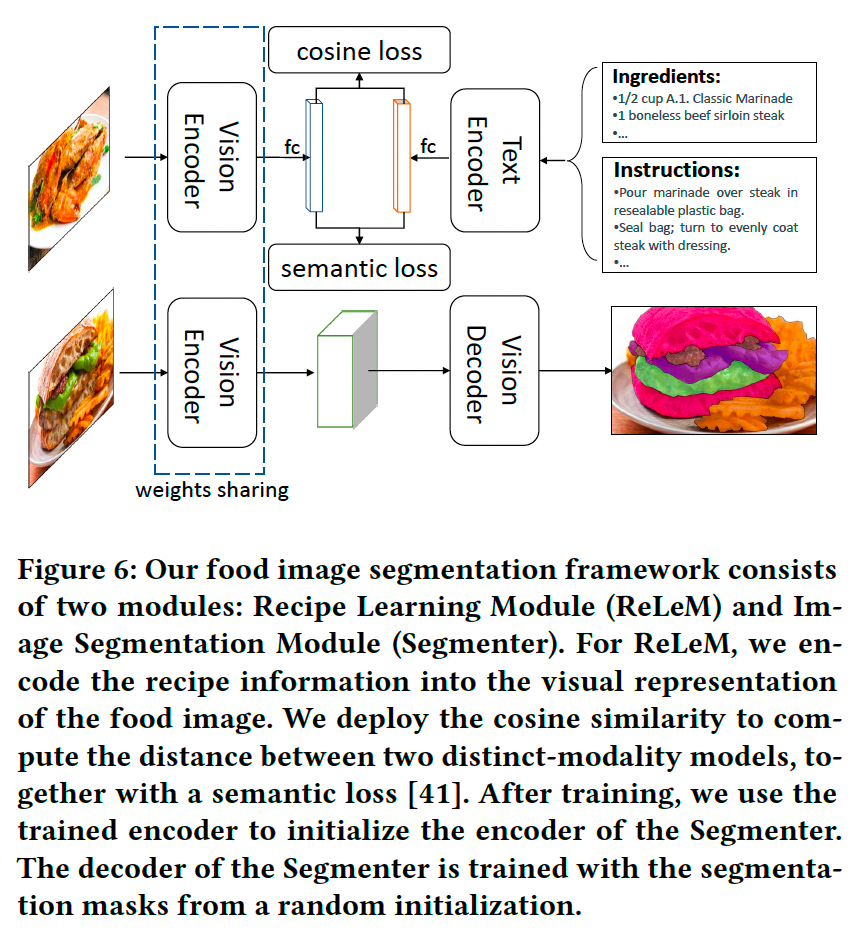
3. 食品图像分割框架
如图6所示,我们的食品图像分割框架包含两个模块:
-
菜谱学习模块(Recipe Learning Module, ReLeM):
- 将菜谱信息以语言嵌入形式融入食品图像的视觉表示。
- 这种方法称为多模态知识迁移。
- ReLeM通过提取食材标签及其烹饪说明的语言嵌入,将不同菜品中同一食材的视觉表示在特征空间中“连接”,以应对同一食材因不同烹饪方式而导致的外观差异。
-
图像分割模块(Image Segmentation Module, Segmenter):
- 采用基于编码器-解码器的图像分割方法。
- 编码器的权重由ReLeM预训练生成,解码器随机初始化,并利用分割掩码进行训练。
3.1 食品图像分割的挑战
食品图像分割可以视为语义分割的一种特殊类型【25, 54】,但其难度更大,主要由于:
- 食材因烹饪方式不同导致的外观差异:
- 例如,“煮鸡蛋”和“炒鸡蛋”的视觉特征可能截然不同。
- 类别分布的不平衡:
- 食材类别通常呈长尾分布,数据在尾部类别中非常稀疏。
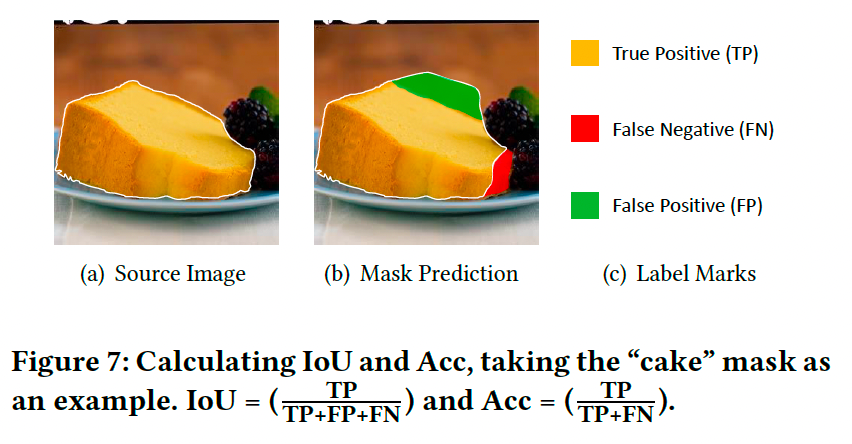
给定一张食品图像,分割器需要识别食材类别,并为每种类别生成相应的像素掩码。常用的评估指标包括:
- mIoU:每类的平均交并比。
- mACC:所有类别的平均准确率。
- aAcc:所有像素的总体准确率。
图7展示了IoU和准确率(Acc)的详细计算方法。
3.2 菜谱学习模块(ReLeM)
我们提出ReLeM以减少因不同烹饪方式引起的食材外观差异。具体而言:
- 训练方法将菜谱信息整合到相应图像的视觉表示中。
- 假设同一种食材在两张图像中因不同烹饪方式导致视觉表示差异较大,ReLeM通过菜谱文本嵌入(例如烹饪说明)减少这种差异:
∣ ϕ ( v 1 ∣ r 1 ) − ϕ ( v 2 ∣ r 2 ) ∣ < ∣ ϕ ( v 1 ) − ϕ ( v 2 ) ∣ |\phi(v_1 | r_1) - \phi(v_2 | r_2)| < |\phi(v_1) - \phi(v_2)| ∣ϕ(v1∣r1)−ϕ(v2∣r2)∣<∣ϕ(v1)−ϕ(v2)∣
其中, ϕ \phi ϕ 为分割器中的视觉解码器(详见第4.2节)。
3.3 优化方法
ReLeM通过两个损失项优化:
-
余弦相似性损失:
L cosine ( v , t , y ) = { 1 − cosine ( v , t ) , y = 1 max ( 0 , cosine ( v , t ) − α ) , y = − 1 L_{\text{cosine}}(v, t, y) = \begin{cases} 1 - \text{cosine}(v, t), & y = 1 \\ \max(0, \text{cosine}(v, t) - \alpha), & y = -1 \end{cases} Lcosine(v,t,y)={1−cosine(v,t),max(0,cosine(v,t)−α),y=1y=−1
其中, y y y 表示 t t t 和 v v v 是否来自相同菜谱, α \alpha α 是边距参数,设为0.1。 -
语义损失:
L semantic ( v , t , u v , u t ) = CE ( v , u v ) + CE ( t , u t ) L_{\text{semantic}}(v, t, u_v, u_t) = \text{CE}(v, u_v) + \text{CE}(t, u_t) Lsemantic(v,t,uv,ut)=CE(v,uv)+CE(t,ut)
其中, CE \text{CE} CE 为交叉熵损失, u v u_v uv 和 u t u_t ut 分别为 v v v 和 t t t 的语义类别。
3.4 预处理
每个菜谱包含食材和烹饪说明。预处理步骤包括:
- 从原始文本中提取有用的食材和烹饪说明,去除冗余词语。
- 对食材文本使用双向LSTM学习word2vec表示。
- 对长序列的烹饪说明,采用skip-instructions编码生成固定长度的特征向量【23, 41】。
3.5 文本编码器
文本编码器用于从食材标签和烹饪说明中提取文本知识:
- LSTM编码器:
- 使用双向LSTM编码食材特征。
- 使用单向LSTM编码说明特征。
- Transformer编码器:
- 使用两层轻量级Transformer,每层包含4个自注意力模块。
3.6 视觉编码器
视觉编码器从输入图像中提取视觉知识,其权重将初始化分割器中的视觉编码器。本文中使用了两种视觉编码器:
- 基于卷积神经网络的 ResNet-50【15】。
- 基于视觉Transformer的 ViT-16/B【12】。
3.7 图像分割模块(Segmenter)
分割模块采用语义分割的标准范式:
- 输入图像首先由视觉编码器编码。
- 然后通过视觉解码器进行掩码预测。
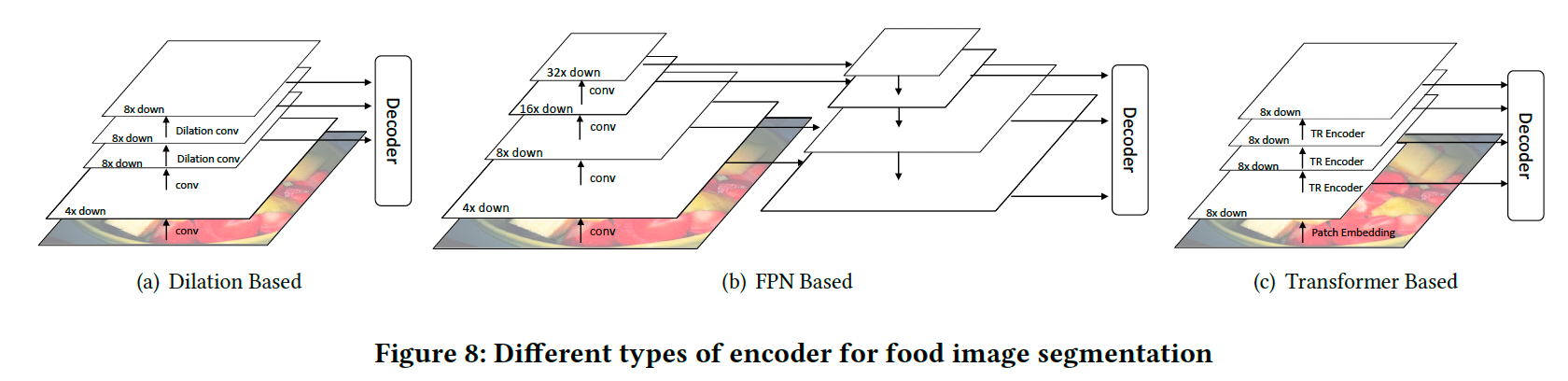
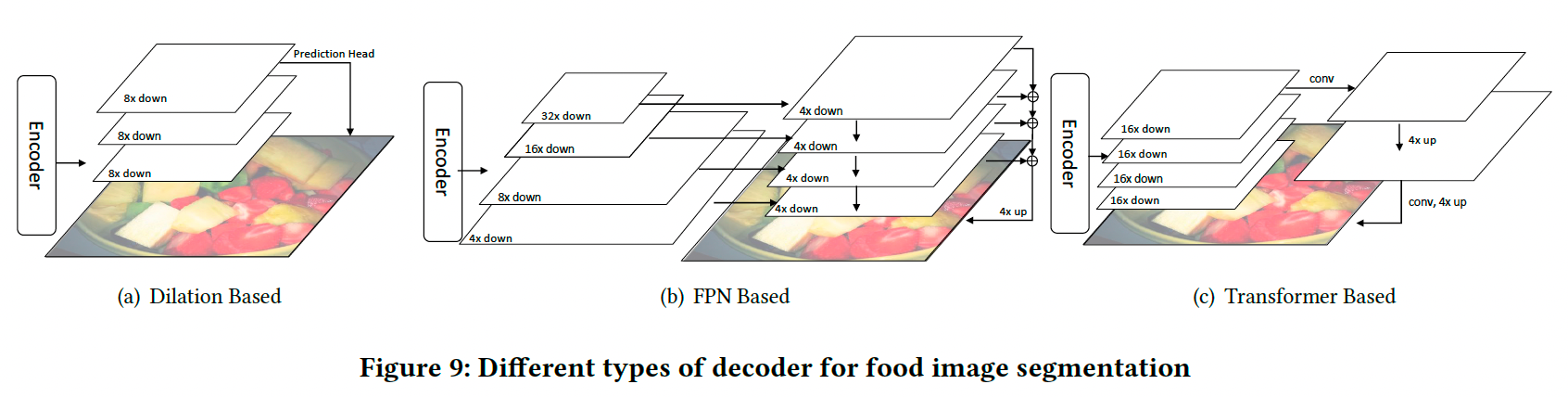
现有分割模型可分为三类:
-
基于膨胀卷积(Dilation-based):
- 膨胀卷积层扩大感受野,同时保持分辨率(图8 (a))。
- 解码器仅使用最后一层特征图进行预测(图9 (a))。
-
基于特征金字塔(FPN-based):
- 特征金字塔通过横向连接整合不同层的特征图。
- 浅层图像表示通过深层特征图增强(图8 (b))。
- 解码器融合一组特征金字塔后生成掩码(图9 (b))。
-
基于Transformer(Transformer-based):
- Transformer通过注意力机制适合语义分割任务,因为上下文信息在分割物体时非常重要。
- 注意力机制扩大了感受野【45, 54】。
- 模型将图像重塑为区域序列,并通过注意力模块对这些序列进行编码(图8 ©)。
- 解码器在最后一层特征图上预测分割掩码(图9 ©)。
本文实验分别使用这三类模型的代表性框架:
- CCNet(膨胀卷积)【17】。
- FPN(特征金字塔)【22】。
- SeTR(Transformer)【54】。
分割器的编码器由ReLeM预训练初始化。通过LSTM和Transformer编码文本,我们构建了6种不同的ReLeM模型,即:
ReLeM-CCNet, FPN, SeTR × (LSTM, Transformer)
\text{ReLeM-{CCNet, FPN, SeTR} × ({LSTM, Transformer})}
ReLeM-CCNet, FPN, SeTR × (LSTM, Transformer)
训练过程中,我们使用标准的像素级交叉熵损失优化分割模型。
4. 实验
我们在数据集 FoodSeg103 上进行了广泛的实验,并将提出的 ReLeM 方法与三种语义分割基线方法结合。以下内容包括实验设置、消融研究结果,以及语义分割和食品图像分割任务的性能对比。此外,我们还评估了模型在 FoodSeg154 中亚洲食品数据集上的跨域适应能力,并提供了最佳分割模型的定性结果。
4.1 实验细节
数据集设置:
- 在实验中,我们使用 FoodSeg103 进行域内训练和测试,使用亚洲食品子集进行跨域测试。
- 我们将 FoodSeg103 数据集随机分为训练集(70%)和测试集(30%),其中训练集包含4,983张图像和29,530个食材掩码,测试集包含2,135张图像和12,567个食材掩码。
- ReLeM 的训练使用 Recipe1M+ 的训练集来学习菜谱表示,测试图像隐藏于训练过程。
分割器设置:
- 使用两种视觉编码器:
- ResNet-50(基于卷积神经网络),初始化于 ImageNet-1k【10】。
- ViT-16/B(基于视觉Transformer),初始化于 ImageNet-21k,包含12层Transformer编码器,每层具有12头自注意力模块。
- 三种分割器:
- CCNet【17】和 FPN【22】(基于ResNet-50)。
- SeTR【54】(基于ViT-16/B)。
- ReLeM 的视觉编码器与分割器相同。
学习参数:
- 图像大小调整为 2049 × 1024 2049 \times 1024 2049×1024 像素,从中裁剪 768 × 768 768 \times 768 768×768 的补丁,并应用随机水平翻转和颜色抖动。
- 模型通过SGD优化,训练80k次迭代,每批8张图像,初始学习率为 1 × 1 0 − 3 1 \times 10^{-3} 1×10−3,学习率以多项式衰减( 0.9 0.9 0.9)。
- ReLeM 的输入图像调整为 256 × 256 256 \times 256 256×256 像素,并裁剪为 224 × 224 224 \times 224 224×224。
4.2 实验结果与观察
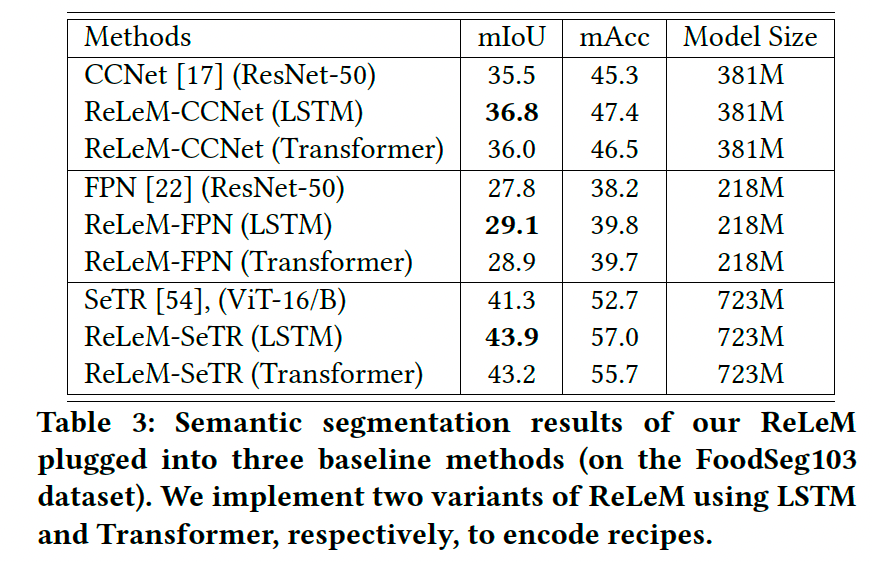
表3展示了CCNet、FPN和SeTR在 FoodSeg103 上的实验结果:
- 所有分割器在结合 LSTM 或 Transformer 的 ReLeM 时均取得显著提升(分别为1.3%、1.3%和2.6%)。
- 使用 LSTM 的 ReLeM 的性能始终优于 Transformer。
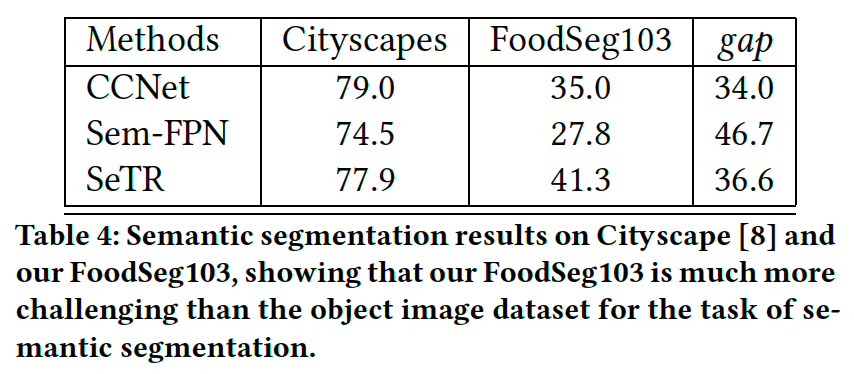
4.3 FoodSeg103 与 Cityscapes 的对比
我们将食品图像分割任务与传统语义分割任务进行了对比,评估了CCNet、SeTR和FPN在 FoodSeg103 和 Cityscapes【8】 数据集上的表现:
- Cityscapes 数据集包含约5,000张德国城市街景图像,分割目标为20种物体。
- 如表4所示,所有基线方法在 Cityscapes 上表现良好,但在 FoodSeg103 上表现显著下降。这表明食品图像分割任务的难度更高。
4.4 定性结果
图10展示了 CCNet 和 ReLeM-CCNet 在 FoodSeg103 测试集上的定性结果:
- 前两行表明 ReLeM-CCNet 生成了更准确且细致的分割结果,验证了 ReLeM 的有效性。
- 最后一行展示了一个失败案例,其中不同食材之间没有清晰的边界。

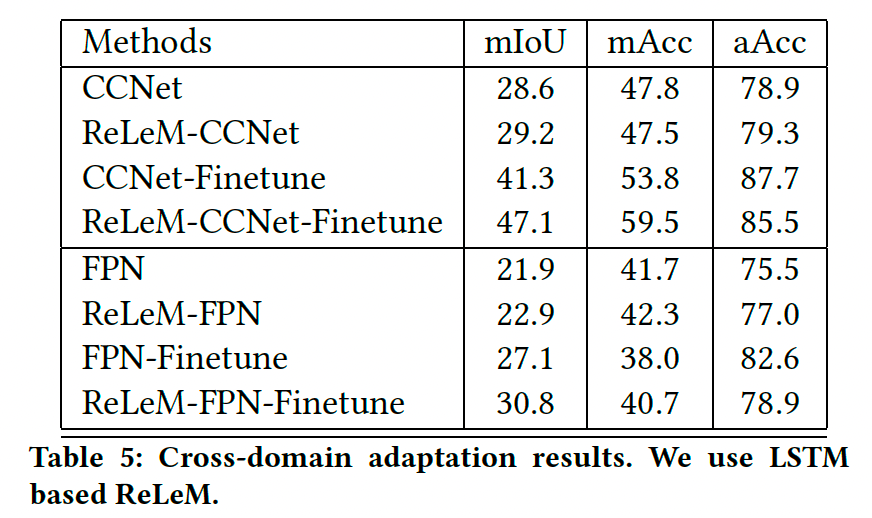
4.5 跨域评估
我们使用 FoodSeg154 的亚洲食品数据集进行了跨域模型评估:
- 使用 FoodSeg103 训练的模型在亚洲食品子集上进行适配。
- 亚洲食品数据集均分为训练集和测试集,分别包含62个与 FoodSeg103 重叠的类别和112个总类别。
- 表5显示:
- 使用 ReLeM 的模型在所有情况下均优于基线模型。
- 结合亚洲食品数据集的微调进一步提高了性能。
5. 结论
我们构建了一个大规模食品图像分割数据集 FoodSeg103(及其扩展 FoodSeg154),包括约10k图像和60k分割掩码,覆盖154种食材的高度多样化外观。此外,我们提出了基于多模态的预训练方法 ReLeM,通过结合三种语义分割基线方法并在 FoodSeg103 和 FoodSeg154 上进行广泛实验,验证了其有效性。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!




















 7436
7436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











