









🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
1. 背景介绍
Han Y, Cheng Q, Wu W, et al. Dpf-nutrition: Food nutrition estimation via depth prediction and fusion[J]. Foods, 2023, 12(23): 4293.
🚀以上学术论文翻译由ChatGPT辅助。
合理而均衡的饮食对于维持良好的健康至关重要。随着深度学习技术的发展,一种基于食物图像的自动化营养估计方法为监测日常营养摄入和促进饮食健康提供了有前景的解决方案。
尽管基于单目图像的营养估计方法具有便捷、高效和经济的优势,但其准确性有限仍然是一个重要问题。为了解决这一问题,我们提出了一种基于单目图像的端到端营养估计方法——DPF-Nutrition。
在 DPF-Nutrition 中,我们引入了一个深度预测模块,用于生成深度图,从而提升食物分量估计的准确性。同时,我们设计了一个RGB-D 融合模块,将单目图像与预测得到的深度信息相结合,以提升营养估计的性能。
据我们所知,这是首次在食品营养估计中融合深度预测与 RGB-D 融合技术的研究尝试。
在 Nutrition5k 数据集上进行的大量实验证明了 DPF-Nutrition 在效果和效率上的优越性。
饮食健康已成为现代生活中的核心关注点。过量或不均衡的营养摄入可能导致各种饮食相关疾病,尤其是肥胖症,它将显著增加高血压、心血管疾病和糖尿病的风险【1】。
营养内容估计失误是造成摄入过量和不均衡的一个重要原因。国际食品信息委员会(IFIC)基金会曾报告称,大多数人倾向于高估自己的蔬菜摄入量,而低估脂肪摄入【2】。因此,迫切需要有效的营养估计方法,帮助人们监测日常饮食摄入,引导其迈向更健康的饮食方式。
以往的饮食评估方法主要依赖人工操作。最常用的“24 小时饮食回忆法”【3】要求参与者报告 24 小时内所食用的食物类型和分量,从而了解其饮食行为。许多流行的应用程序,如 MyFitnessPal、MyDietCoach、Yazio、FatSecret、MyFoodDiary 和 Foodnotes,都是基于此方法开发的。尽管该方法易于实现,但由于高度依赖参与者的主观判断,其过程繁琐且不够可靠。
幸运的是,近年来人工智能(AI)的发展,尤其是深度学习技术,使得自动化且可靠的饮食评估成为现实【4,5】。基于视觉的营养估计方法允许用户通过手机拍摄食物图片来监测食物摄入,极大减轻了用户的负担。
根据输入数据的类型,现有方法大致可分为三类【6】:基于单目图像的方法、多视角图像的方法和 RGB-D 方法。
早期工作【7,8】主要依赖多视角图像重建食物的三维结构并估计其体积,然后结合食物的营养信息计算总营养值。然而,多视角图像方法操作繁琐、效率低下,因为它要求用户从特定角度拍摄图像。
相比之下,基于单目图像的方法只需一张食物图像,操作简便,效果也不错。例如,Shao 等人【9】提出一种基于能量密度图的热量估计方法,将 RGB 图像逐像素映射到食物的能量密度图,并与人工 24 小时饮食回忆法对比,显示出明显优势。Thames 等人【10】则证明了基于视觉的方法在多个营养素的估计上优于专业营养师,所用模型是多任务卷积神经网络。Shao 等人【11】结合无损检测技术与深度学习分析食物营养成分,并通过改善小目标检测来提升估计准确性。
然而,从单目图像估计食物营养本质上是一个不适定问题【12】,因为单目图像在映射过程中会丢失重要的三维信息,而这对分量估计至关重要。
为解决此问题,研究者引入深度信息来弥补单目图像中缺失的三维特征。例如,Lu 等人【13】使用来自真实就餐场景的 RGB-D 图像作为输入,并集成食物分割、识别和三维重建技术以估计住院病人的营养摄入;Thames 等人【10】将单目图像与深度图合并成四通道输入,随后转换为三通道张量输入模型。然而,这些方法只是将食物图像与深度图视作配对图像,忽视了 RGB 图与深度图之间的内在差异,限制了估计性能。
最近,有研究尝试通过跨模态融合来提升营养估计效果。Vinod 等人【14】采用归一化技术来解决能量密度图与深度图之间的特征差异;Shao 等人【15】引入平衡特征金字塔【16】与卷积注意力模块【17】来增强融合特征,但融合方式仍是简单拼接,未能充分挖掘跨模态交互效应,限制了营养估计精度的进一步提升。
此外,深度图的获取严重依赖于专业深度传感器,这增加了成本,限制了 RGB-D 营养估计方法的应用场景。
在本文中,我们提出了一种新颖的基于深度预测与融合的食物营养估计方法,称为 DPF-Nutrition。
我们引入了一个深度预测模块,用于生成预测深度图,而非依赖实际深度传感器获取深度图。这些预测深度图可恢复单目图像中缺失的三维信息,从而在不增加额外成本的情况下提升食物分量估计的准确性。
与现有 RGB-D 融合方法【14,15】只在单一模态上增强特征不同,我们提出了一种跨模态注意力块(CAB),专注于跨模态特征间的交互效应。CAB 利用跨模态注意力特征来增强单一模态特征,提高模态间的互补性,进而生成更具判别力的融合特征,使模型能更准确地聚焦于正确的营养区域。
此外,我们还设计了一种多尺度融合网络,通过结合不同分辨率的融合特征增强语义信息,使模型能够捕捉共现的食物特征。CAB 和多尺度融合网络共同组成了 DPF-Nutrition 中的 RGB-D 融合模块,该模块充分挖掘了 RGB 和深度图的特征,从而显著提升了食物营养估计性能。
值得一提的是,在推理阶段,DPF-Nutrition 仅依赖单张食物图像作为输入,因此本质上仍是一种基于单目图像的方法。
我们在公开数据集 Nutrition5k 上评估了 DPF-Nutrition 的有效性,并取得了令人满意的结果:对热量、质量、蛋白质、脂肪和碳水化合物的估计 PMAE 分别为 14.7%、10.6%、20.2%、22.6%、20.7%。
与 Thames 等人【10】提出的基于单目图像的前作相比,DPF-Nutrition 的平均 PMAE 降至 17.8%,提升了 11.3%。同时,与 Shao 等人【15】提出的最先进 RGB-D 方法相比,我们的模型也取得了 0.7% 的提升。
本文的贡献可总结为以下三点:
-
我们提出了一种新颖的基于单目图像的营养估计方法 DPF-Nutrition,这是首次在营养估计中结合深度预测与 RGB-D 融合技术。
-
我们设计了一个包含跨模态注意力块(CAB)和多尺度融合网络的 RGB-D 融合模块,有效挖掘图像中的信息特征以提升营养估计性能。
-
我们提出的 DPF-Nutrition 在 Nutrition5k 公共数据集上展示了对多种营养成分的准确估计能力,表现出了较强的有效性。
2. 材料与方法(Materials and Methods)
2.1 数据集(Dataset)
我们总结了现有营养数据集中关于多样性、数据规模、标注信息以及是否包含深度信息等方面的情况,结果如表 1 所示。总体来看,Nutrition5k 数据集【10】拥有最多的独立菜品和图像。此外,该数据集还包含丰富的营养标注信息,而其他数据集通常仅包括单一热量或分量标注。
本文使用 Nutrition5k 数据集对我们提出的 DPF-Nutrition 方法进行评估。该数据集包含由 Intel RealSense 相机采集的约 2 万段短视频与 3500 张 RGB-D 图像,涵盖约 5000 道不同的菜品。每道菜都包括详细信息,如食材名称、用量以及根据可靠的 USDA 食品营养数据库【18】计算的相关营养素信息。
图 1 展示了 Nutrition5k 数据集中的图像示例。在深度图中,靠近相机的物体显示为蓝色,远离相机的物体显示为红色,颜色条作为视觉指示器,反映了每个点到相机的距离,单位为厘米。

作为一种基于图像的营养估计方法,我们对 DPF-Nutrition 在 Nutrition5k 数据集中的 3500 张食品图像上进行了评估。Nutrition5k 提供了预定义的训练/测试划分,比例为 5:1。图 2 展示了一些存在明显标注错误的图像,这类图像可能干扰模型训练,导致性能下降。然而,为保证研究中方法对比的一致性,我们未对原始数据集进行清洗,保持其完整性。

2.2 方法(Methods)
我们提出的 DPF-Nutrition 的整体架构如图 3 所示,模型由两个主要模块组成:
-
模块 1:深度预测模块(Depth Prediction Module)
该模块旨在基于二维单目图像重建三维深度信息。我们采用 Vision Transformer 作为编码器,以降低细粒度信息和特征分辨率的损失,从而更准确地恢复三维信息。 -
模块 2:RGB-D 融合模块(RGB-D Fusion Module)
该模块旨在充分利用 RGB 图像和预测深度图的特征进行营养估计。融合模块集成了我们提出的多尺度融合网络(Multi-Scale Fusion Network)和跨模态注意力块(CAB)。多尺度融合网络丰富了细粒度食品图像的语义特征,而 CAB 则进一步提升了 RGB 和深度特征之间的互补性。
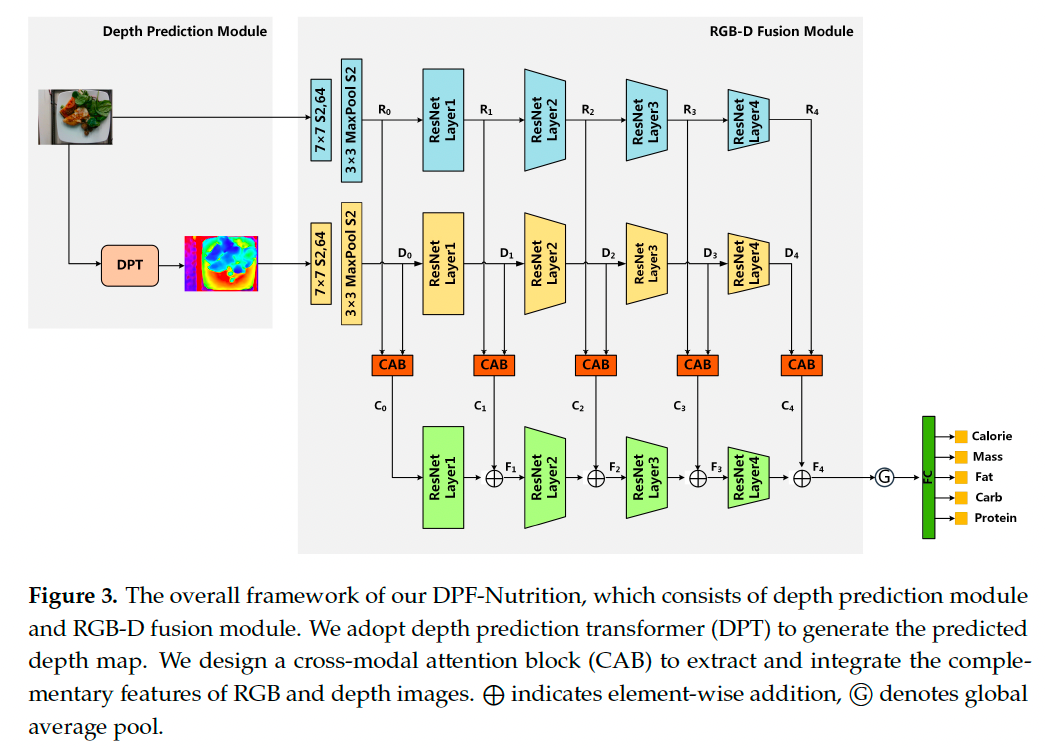
为实现准确的营养估计,模型需同时具备食物识别与分量估计能力。深度预测模块负责生成深度图,这是实现准确分量估计的关键。多尺度融合网络通过组合多层特征图生成高分辨率、语义性强的特征图,从而增强了对图像中共现食物的识别。
DPF-Nutrition 是一个端到端的食物营养估计模型,其中 CAB 能整合 RGB 图像与预测深度图之间的互补信息,促进跨模态协同估计。
模型整体架构如图 3 所示,具体包括:
- 主干网络采用 ResNet101【23】
- 深度预测模块采用 Dense Prediction Transformer(DPT)【24】生成深度图
- RGB-D 融合模块中,RGB 特征与深度特征由两个独立 ResNet 网络提取
- 同层特征输入 CAB 进行跨模态融合
- 多分辨率融合后的特征图通过第三个 ResNet 网络进一步自浅层到深层融合,最终特征图包含全局和局部详细信息
最终,特征图通过全局平均池化(Global Average Pooling)及多任务头(Multi-task Head)输出热量、质量、蛋白质、脂肪和碳水化合物的估计结果。
2.2.1 深度预测模块(Depth Prediction Module)
深度预测在计算机视觉中起着至关重要的作用,它增强了对真实三维场景的理解和感知。深度预测模型通常由编码器和解码器组成【25–27】。编码器从输入图像中提取特征,解码器将这些特征转换为最终的深度预测。
编码器的选择至关重要,因为编码过程中丢失的特征在解码器中难以恢复。与户外场景或大型物体的深度信息相比,食物的深度信息更加复杂,其几何形状多样、纹理丰富,因此在编码器中提取特征时容易失真。
传统卷积神经网络(CNN)【23,28】在加深网络层级时由于下采样操作会不可避免地损失分辨率和细节。而 Vision Transformer(ViT)【29】摒弃了下采样机制,能在所有阶段保持全局感受野,更适合用于处理细粒度的食物图像。
我们的深度预测模块由 Transformer 编码器和卷积解码器组成:
- Transformer 编码器提取图像的词袋特征表示
- 解码器将词袋表示重构为不同尺度的图像特征
- 最终将图像特征组合为深度估计图(见图 4a)
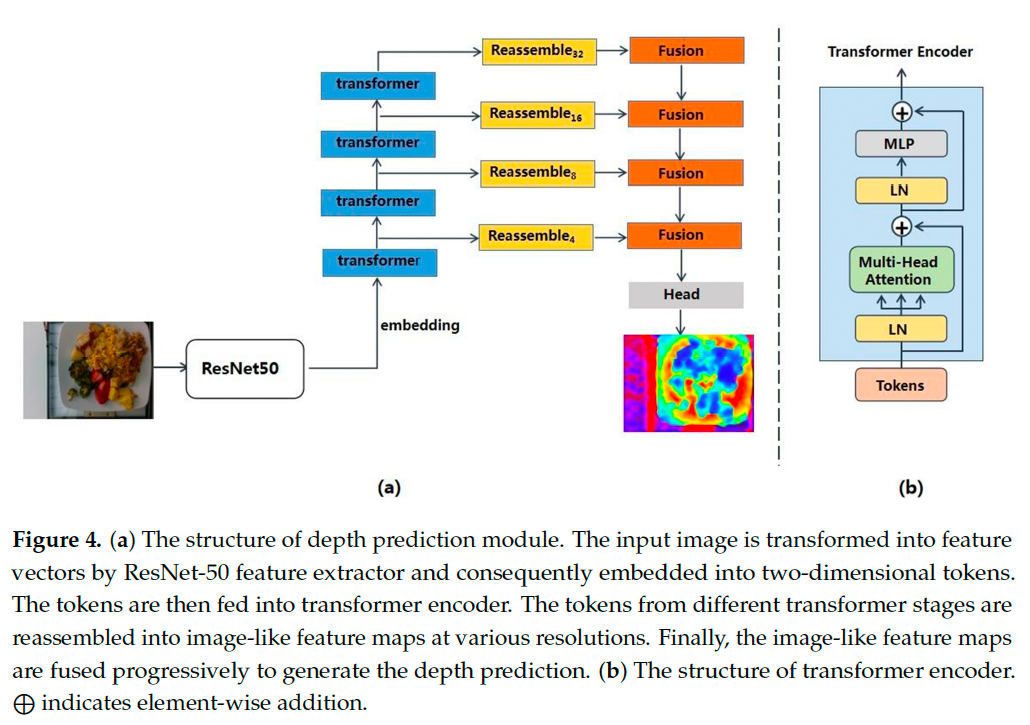
具体过程:
-
输入图像首先由 ResNet-50 编码为二维特征向量,以适配 Transformer 输入格式;
-
特征向量与可训练的位置编码(position embedding)结合,生成一系列嵌入向量 token;
-
输入 Transformer 编码器,提取图像的局部与全局特征(如图 4b 所示);
-
Transformer 块由多头注意力层、多层感知机(MLP)、LayerNorm 和残差连接组成;
-
给定图像分辨率为 H × W H \times W H×W,经过编码器后得到一组 token:
t = { t 0 , t 1 , … , t N p } , t n ∈ R D t = \{t_0, t_1, \dots, t_{N_p}\}, \quad t_n \in \mathbb{R}^D t={t0,t1,…,tNp},tn∈RD
其中 N p = H ⋅ W p 2 N_p = \frac{H \cdot W}{p^2} Np=p2H⋅W, D D D 表示 token 的维度, p p p 为 ResNet 的采样率。
-
这些 token 被拼接为图像特征图:
Concatnate : R N p × D → R H p × W p × D (1) \text{Concatnate} : \mathbb{R}^{N_p \times D} \rightarrow \mathbb{R}^{\frac{H}{p} \times \frac{W}{p} \times D} \tag{1} Concatnate:RNp×D→RpH×pW×D(1)
-
将特征图重新采样为固定尺寸 ( H s , W s ) (H_s, W_s) (Hs,Ws),并调整维度为 D ′ D' D′:
Resample : R H p × W p × D → R H s × W s × D ′ (2) \text{Resample} : \mathbb{R}^{\frac{H}{p} \times \frac{W}{p} \times D} \rightarrow \mathbb{R}^{H_s \times W_s \times D'} \tag{2} Resample:RpH×pW×D→RHs×Ws×D′(2)
-
最后使用 RefineNet 解码器【30】结合不同分辨率的特征图生成最终深度预测结果。
2.2.2 RGB-D 融合模块(RGB-D Fusion Module)
RGB-D 融合被广泛应用于图像分类【31】、食物摄入检测【32】和营养评估【15】等任务中。其核心是结合 RGB 图像与深度图的互补信息,获得更丰富、增强的特征表示。
由于 RGB 与深度图属于不同模态,信息特性完全不同,因此简单拼接或相加不能充分利用跨模态特征。
我们总结现有 RGB-D 融合方法为两类范式【见图 5】:
- 增强–融合(Enhancement–Fusion):如 Vinod 等人【14】,通过归一化技术对特征空间差异进行修正;
- 融合–增强(Fusion–Enhancement):如 Shao 等人【15】,使用平衡特征金字塔与卷积注意模块增强融合特征。
但这两种范式各有不足:
- 融合–增强方法未充分考虑模态互补性,容易丢失有用信息;
- 增强–融合方法可能引入冗余信息。
因此我们提出一种新的 “融合–增强–融合” 范式:
- 首先直接融合 RGB 与深度特征,获取跨模态交互信息;
- 利用该交互信息分别增强单模态特征;
- 最后将增强后的单模态特征融合,生成最终 RGB-D 特征。
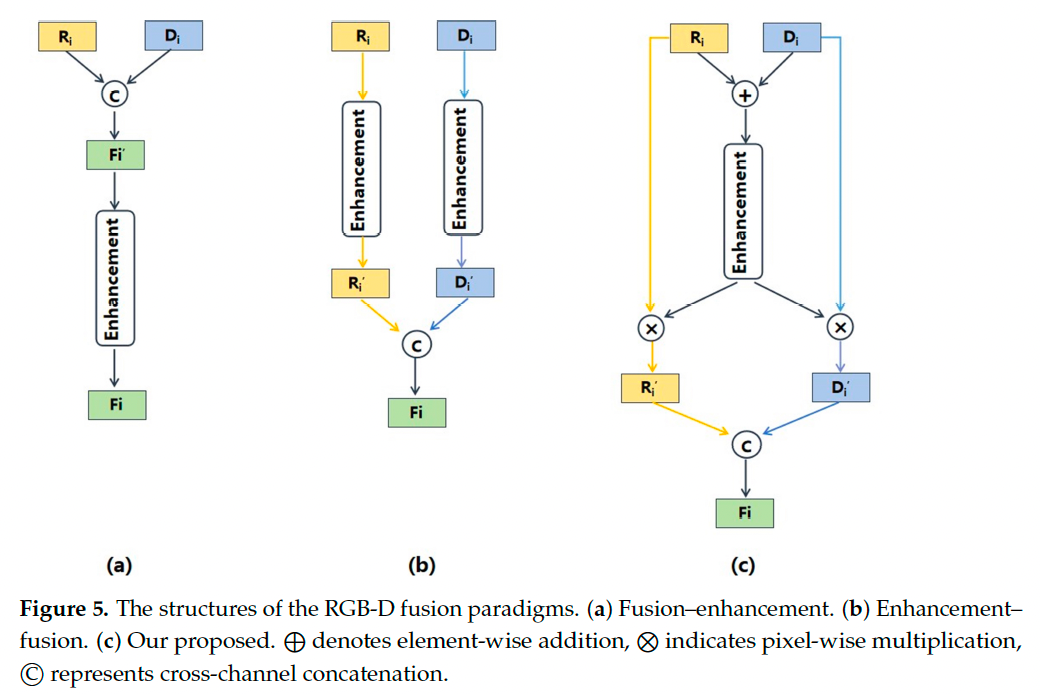
我们为此设计了 跨模态注意力块(CAB)(见图 6),可增强有用特征并过滤冗余信息,使模型更准确地关注高营养区域,而非仅关注食物或大体积区域。
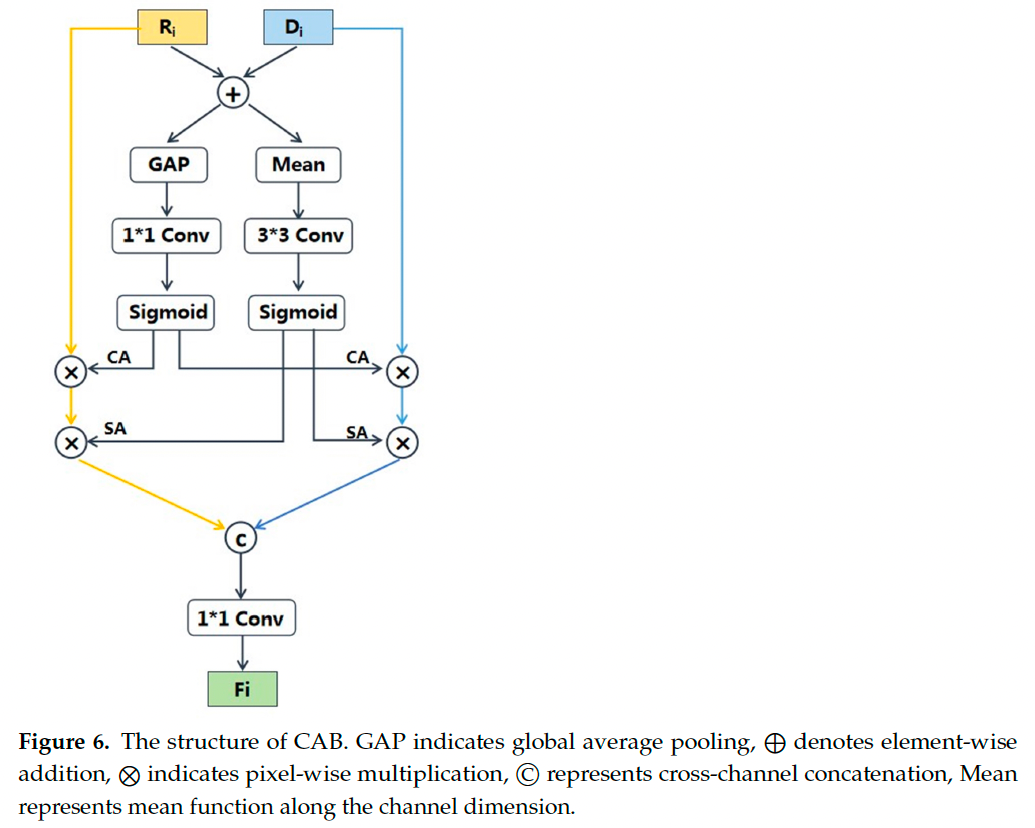
具体实现如下:
-
深度预测模块生成深度图后,与 RGB 图像共同输入特征提取网络;
-
生成的 RGB 特征记为 { R i } i = 0 4 \{R_i\}_{i=0}^4 {Ri}i=04,深度特征为 { D i } i = 0 4 \{D_i\}_{i=0}^4 {Di}i=04;
-
相同分辨率的特征图输入 CAB 生成互补融合特征;
-
CAB 利用通道注意力与空间注意力机制建构不同模态的特征对应关系;
-
对两个输入特征 R i R_i Ri 与 D i D_i Di,首先沿通道维度逐像素相加,再分支处理:
- 通道注意力分支:
C A = Sig ( Conv 1 × 1 ( GAP ( R i + D i ) ) ) (3) CA = \text{Sig}(\text{Conv}_{1\times1}(\text{GAP}(R_i + D_i))) \tag{3} CA=Sig(Conv1×1(GAP(Ri+Di)))(3)
其中 GAP ( ⋅ ) \text{GAP}( \cdot ) GAP(⋅) 表示全局平均池化, Conv 1 × 1 \text{Conv}_{1\times1} Conv1×1 为 1 × 1 1 \times 1 1×1 卷积(后接 BN 和 ReLU), Sig ( ⋅ ) \text{Sig}( \cdot ) Sig(⋅) 为 Sigmoid 激活函数。
- 通道注意力分支:
在空间注意力分支中,我们首先在通道维度上对加性特征图的所有像素取平均,获得空间描述符。随后,对该空间描述符应用 3 × 3 3 \times 3 3×3 卷积(带有 BN 和 ReLU)进行平滑处理。最终,通过 Sigmoid 激活函数得到空间注意力向量。该过程可表示为:
S A = Sig ( Conv 3 × 3 ( Mean ( R i ⊕ D i ) ) ) (4) SA = \text{Sig}(\text{Conv}_{3\times3}(\text{Mean}(R_i \oplus D_i))) \tag{4} SA=Sig(Conv3×3(Mean(Ri⊕Di)))(4)
其中 Mean ( ⋅ ) \text{Mean}(\cdot) Mean(⋅) 表示在通道维度上的均值操作, ⊕ \oplus ⊕ 表示逐元素加法。
通道注意力与空间注意力的权重增强了 RGB 与深度特征之间的相关性与互补性。基于跨模态注意力机制,得到增强的 RGB 特征图与深度特征图。接着,我们将这些增强后的特征拼接,并输入一个 1 × 1 1 \times 1 1×1 卷积层以获得互补的 RGB-D 特征 C i C_i Ci,过程如下:
C i = Conv 1 × 1 ( Concat ( R i ⊗ C A ⊗ S A , D i ⊗ C A ⊗ S A ) ) (5) C_i = \text{Conv}_{1\times1}(\text{Concat}(R_i \otimes CA \otimes SA,\ D_i \otimes CA \otimes SA)) \tag{5} Ci=Conv1×1(Concat(Ri⊗CA⊗SA, Di⊗CA⊗SA))(5)
其中 Concat ( ⋅ ) \text{Concat}(\cdot) Concat(⋅) 表示跨通道拼接, ⊗ \otimes ⊗ 表示逐元素乘法。
通过上述提出的 CAB 结构,我们获得了一组跨模态特征 { C i } i = 0 4 \{C_i\}_{i=0}^4 {Ci}i=04。为进一步增强语义特征,我们引入多尺度融合网络,逐步整合低层特征的局部细节信息与高层特征的全局上下文信息。这使得模型能够更全面地捕捉图像中共现的食物项,尤其是图中较小的物体,从而提高营养估计的准确性。
我们将第一层跨模态特征图 F 0 F_0 F0 作为融合网络的输入,该特征图首先通过一个 ResNet 卷积模块进行精炼,并与下一层的跨模态特征图 C 1 C_1 C1 进行融合生成 F 1 F_1 F1。该操作在接下来的阶段继续重复,最终将所有不同尺度的跨模态特征整合,过程可表示为:
F i = C i ⊕ Res i ( C i − 1 ) (6) F_i = C_i \oplus \text{Res}_i(C_{i-1}) \tag{6} Fi=Ci⊕Resi(Ci−1)(6)
其中 Res i \text{Res}_i Resi 表示第 i i i 个 ResNet 卷积块。
通过多尺度融合网络和 CAB,我们充分利用了 RGB 与深度图的互补信息,最终生成最终特征表示 F 4 F_4 F4。然后该特征图被输入至全连接层(FC)以及五个多任务头(每个头的维度为 2048 和 1),输出相应的营养素估计值。
2.2.3 损失函数(Loss Function)
作为一个多任务学习模型,DPF-Nutrition 预测了食物中的热量(calories)、质量(mass)以及三种宏量营养素(脂肪 fat、碳水化合物 carbohydrate 和蛋白质 protein)。对于每一个子任务,我们使用 L 1 L_1 L1 损失来衡量预测值与真实值之间的偏差,定义如下:
L c a l = 1 N ∑ i = 1 N ∣ y c a l i − y ^ c a l i ∣ (7) L_{cal} = \frac{1}{N} \sum_{i=1}^N |y_{cal}^i - \hat{y}_{cal}^i| \tag{7} Lcal=N1i=1∑N∣ycali−y^cali∣(7)
其中 L c a l L_{cal} Lcal 表示热量子任务的损失, y c a l i y_{cal}^i ycali 为第 i i i 个样本的预测热量值, y ^ c a l i \hat{y}_{cal}^i y^cali 为对应的真实值。其他子任务的损失定义与此相同。
由于每个子任务的损失尺度可能不同,某些任务的损失可能主导整体训练过程。我们引入了几何损失组合策略【33】,该方法对不同尺度的子任务损失具有不变性,从而实现子任务之间的平衡。总损失函数定义如下:
L t o t a l = L c a l ⋅ L m a s s ⋅ L f a t ⋅ L c a r b ⋅ L p r o t e i n 5 (8) L_{total} = \sqrt[5]{L_{cal} \cdot L_{mass} \cdot L_{fat} \cdot L_{carb} \cdot L_{protein}} \tag{8} Ltotal=5Lcal⋅Lmass⋅Lfat⋅Lcarb⋅Lprotein(8)
其中 L t o t a l L_{total} Ltotal 表示整体损失。
2.3 评估指标(Evaluation Metrics)
本文使用两个评估指标来衡量营养估计的准确性:平均绝对误差(MAE)与百分比平均绝对误差(PMAE),定义如下:
M A E = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ (9) MAE = \frac{1}{N} \sum_{i=1}^N |y_i - \hat{y}_i| \tag{9} MAE=N1i=1∑N∣yi−y^i∣(9)
P M A E = M A E 1 N ∑ i = 1 N y ^ i (10) PMAE = \frac{MAE}{\frac{1}{N} \sum_{i=1}^N \hat{y}_i} \tag{10} PMAE=N1∑i=1Ny^iMAE(10)
其中 y i y_i yi 表示第 i i i 个样本的预测营养值, y ^ i \hat{y}_i y^i 表示真实值。热量值以千卡(kcal)计,其他营养素(脂肪、碳水、蛋白)以克(g)计。MAE 和 PMAE 越低,代表估计准确度越高。
此外,为评估深度图的预测效果,我们引入了以下三个指标:
-
绝对相对误差(AbsRel):
A b s R e l = 1 N ∑ i = 1 N ∣ d i − d ^ i ∣ d ^ i (11) AbsRel = \frac{1}{N} \sum_{i=1}^N \frac{|d_i - \hat{d}_i|}{\hat{d}_i} \tag{11} AbsRel=N1i=1∑Nd^i∣di−d^i∣(11) -
均方根误差(RMSE):
R M S E = 1 N ∑ i = 1 N ( d i − d ^ i ) 2 (12) RMSE = \sqrt{ \frac{1}{N} \sum_{i=1}^N (d_i - \hat{d}_i)^2 } \tag{12} RMSE=N1i=1∑N(di−d^i)2(12) -
误差阈值内的准确率(Accuracy@thr):
Accuracy = % of i s.t. max ( d i d ^ i , d ^ i d i ) < δ (13) \text{Accuracy} = \% \text{ of } i \text{ s.t. } \max\left( \frac{d_i}{\hat{d}_i}, \frac{\hat{d}_i}{d_i} \right) < \delta \tag{13} Accuracy=% of i s.t. max(d^idi,did^i)<δ(13)
其中 d i d_i di 表示预测深度值, d ^ i \hat{d}_i d^i 为真实深度值。较低的 AbsRel 和 RMSE,及更高的 Accuracy,表明模型的深度预测性能越好。
3. 结果
3.1 实验细节
所有实验均在 24GB 显存的 NVIDIA GTX 3090 GPU 上完成。为确保实验公平,所有实验均采用相同的设置。
在训练深度预测模块时,我们将输入图像的长边缩放至 384 像素,并在其中随机裁剪 384 × 384 384 \times 384 384×384 的正方形区域进行训练。这一操作不仅满足视觉 Transformer 的输入尺寸需求,也作为一种增强策略,有助于提升模型的泛化能力。编码器网络使用 ImageNet1K 预训练权重初始化,解码器则随机初始化。我们使用 Adam 优化器 [34],初始学习率设为 1 × 10 − 5 1 \times 10^{-5} 1×10−5,并采用余弦退火策略衰减学习率,最终降至 1 × 10 − 6 1 \times 10^{-6} 1×10−6。模型训练 60 个 epoch,batch size 设为 8。
训练 RGB-D 融合模块时,将图像尺寸调整为 336 × 448 336 \times 448 336×448,以减少显存消耗同时保持原始长宽比。图像增强方法包括中心裁剪和随机水平翻转,以提升模型泛化能力。主干网络采用在 Food2K [35] 数据集上预训练的权重进行初始化。Food2K 是一个用于细粒度食物识别的大型数据集,特别适用于食物相关视觉任务的迁移学习。我们选择 Adam 优化器,初始学习率设为 5 × 10 − 5 5 \times 10^{-5} 5×10−5,并使用指数衰减策略更新学习率,衰减率设为 0.98。模型训练共进行 150 个 epoch,batch size 依旧为 8。优化器选择、学习率策略和 batch size 的设定均基于经验精心设计,以获得最佳效果。
3.2 主干网络对比
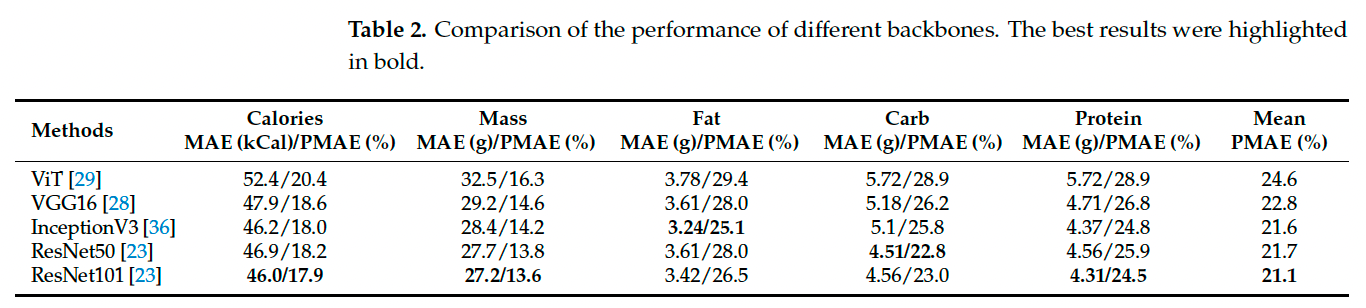
主干网络的选择对模型性能至关重要。本节中,我们比较了多个常用的卷积神经网络(CNN)和近年来流行的 Vision Transformer [29]。如表 2 所示,ResNet101 实现了最佳平均 PMAE(20.9%),因此除非特别说明,我们在 DPF-Nutrition 中采用 ResNet101 [23] 作为主干网络。
3.3 深度预测分析
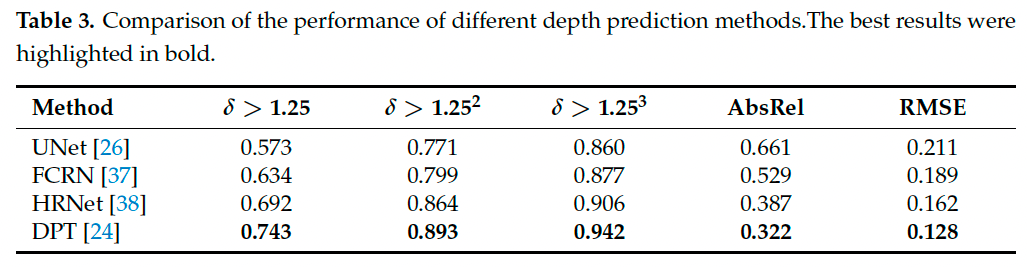
为评估 Dense Prediction Transformer (DPT) 在食物图像上的性能,我们将其与三种基于全卷积网络的深度预测方法进行了比较。为确保公平性,所有方法在相同的实验设置和数据划分下进行评估。比较的方法包括:DPT [24]、FCRN [37]、UNet [26] 和 HRNet [38]。实验结果如表 3 所示。得益于 Vision Transformer 能在编码过程中保持图像分辨率与细节信息,DPT 在深度估计中取得了最佳表现。
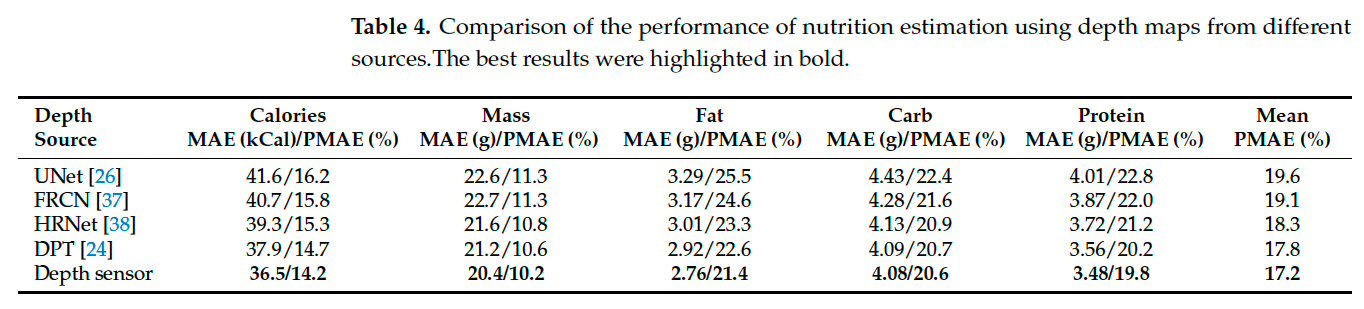
此外,为评估深度图质量对营养估计的影响,我们分别使用真实深度图和由 DPT、FCRN、UNet 与 HRNet 生成的深度图,与 RGB 图像结合进行营养估计。所有实验均使用相同的 RGB-D 融合模块与实验设置。结果如表 4 所示,使用真实深度图时的平均 PMAE 最优,为 17.2%。而当预测深度图的质量越高时,营养估计的性能也越好。
3.4 跨模态融合分析
为验证所提出的 CAB 的有效性,我们与两种 RGB-D 融合方法进行了比较。结果如表 5 所示。这两种方法分别对应图 5 中展示的“fusion–enhancement”和“enhancement–fusion”融合范式。为确保公平,三种方法在增强方式上均使用了空间注意力与通道注意力机制,实验设置与数据划分保持一致。CAB 通过跨模态交互信息来增强单模态特征,生成互补的融合特征。在三种方法中,CAB 采用“fusion–enhancement–fusion”范式,获得最佳性能,平均 PMAE 为 17.8%。

3.5 方法对比
为评估 DPF-Nutrition 的性能,我们将其与三种代表性的营养估计方法进行了比较。所有方法在相同的实验设置与数据划分下进行,实验结果如表 6 所示。参考方法包括 Thames 等人提出的 Google-Nutrition [10] 与 Shao 等人的 RGB-D Nutrition [15],我们还比较了 Swin-Nutrition [11] 和本文提出的 DPF-Nutrition。
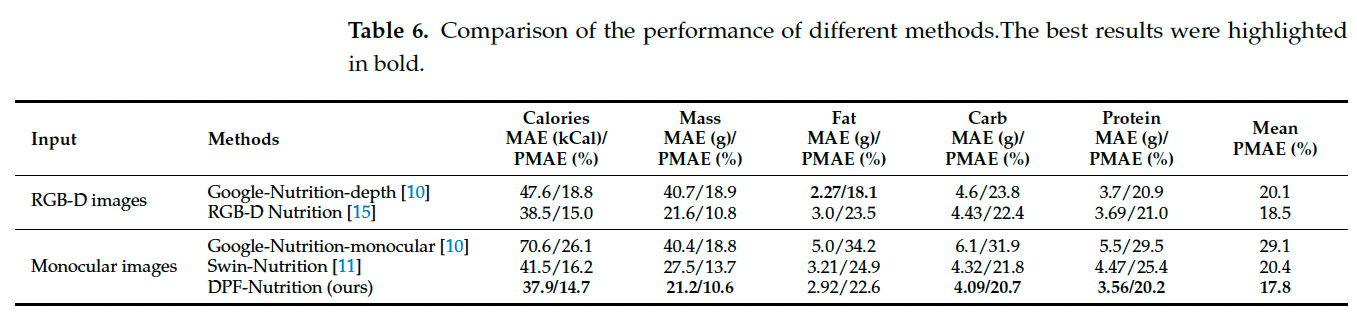
Google-Nutrition 是 Nutrition5k 数据集发布时提出的基准方法,包含 Google-Nutrition-monocular(使用单目图像)与 Google-Nutrition-depth(使用图像与深度图)两个版本。Swin-Nutrition 基于 Swin-Transformer [39] 和特征融合模块,在单目图像营养估计中实现了当前最优性能。需注意,本论文中 Swin-Nutrition 的实验结果不同于其原文 [11],因为我们复现了该方法以避免原实验中因数据清洗带来的差异。
实验结果显示,DPF-Nutrition 在单目图像营养估计中表现出显著优势。相较于 Google-Nutrition-monocular 和 Swin-Nutrition,平均 PMAE 分别提升了 11.3% 和 2.6%。进一步与当前 RGB-D 最优方法 RGB-D Nutrition 相比,DPF-Nutrition 在平均 PMAE 上提升了 0.7%,尽管存在预测深度图与真实深度图之间的偏差,这一提升仍证明了我们对 RGB-D 融合策略的有效探索。
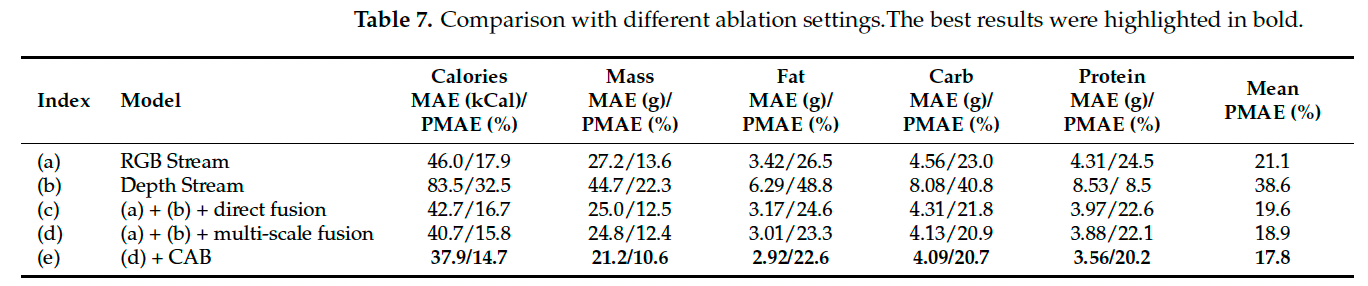
3.6 消融实验
为验证各个模块的有效性,我们对 DPF-Nutrition 的不同组成部分进行了系统的消融实验,实验结果如表 7 所示。
其中,基线模型 (a) 使用单一 ResNet101 网络从 RGB 图像中估计营养值。模型 (b) 使用深度预测模块生成的深度图进行估计。模型 © 采用简单的特征向量拼接方式融合 RGB 与深度流。模型 (d) 引入了多尺度融合网络,而模型 (e) 为完整的 DPF-Nutrition,基于 (d) 进一步加入 CAB 模块。
实验结果显示,模型 (a) 的平均 PMAE 为 20.9%,模型 (b) 为 38.6%,说明仅依赖深度信息难以准确估计营养值。模型 © 相比模型 (a) 提升了 1.5%,表明深度图作为补充信息是有效的。模型 (d) 与模型 (e) 分别验证了多尺度融合网络和 CAB 模块的效果,最终完整模型 (e) 的 PMAE 相比模型 © 降低了 1.8%,热量 MAE 减少了 4.8 kcal,质量 MAE 减少了 3.8 g,证明了各模块在提升营养估计准确性方面的有效性。
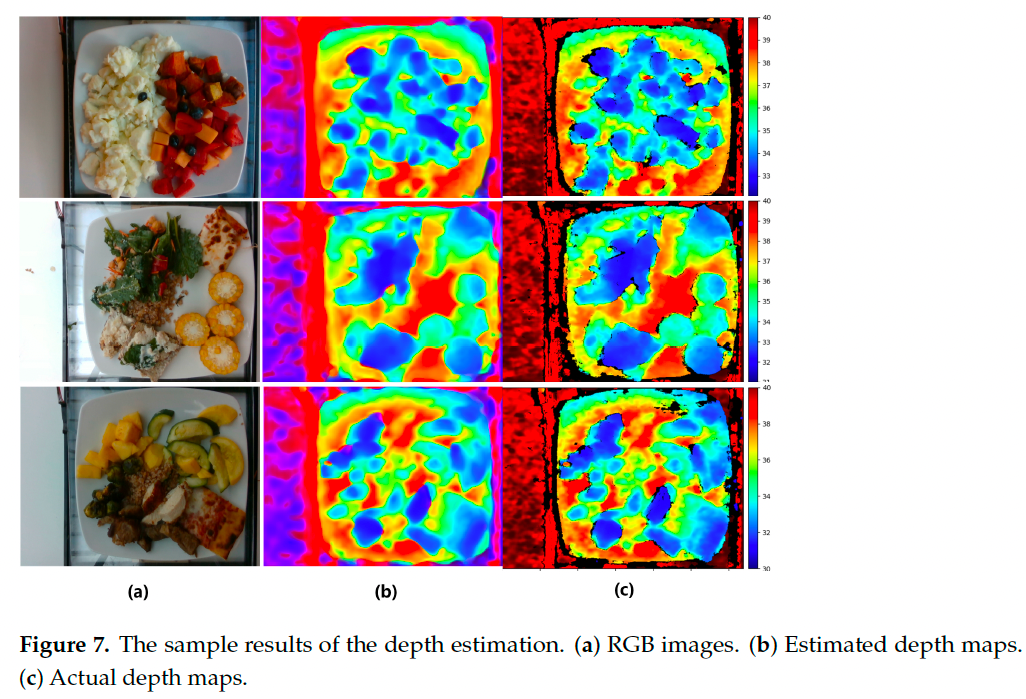
3.7 可视化分析
为了更直观地展示我们方法的效果,我们首先对深度预测模块进行了可视化,如图 7 所示。结果表明我们的方法能够有效还原深度信息,并消除原始深度中的噪声。
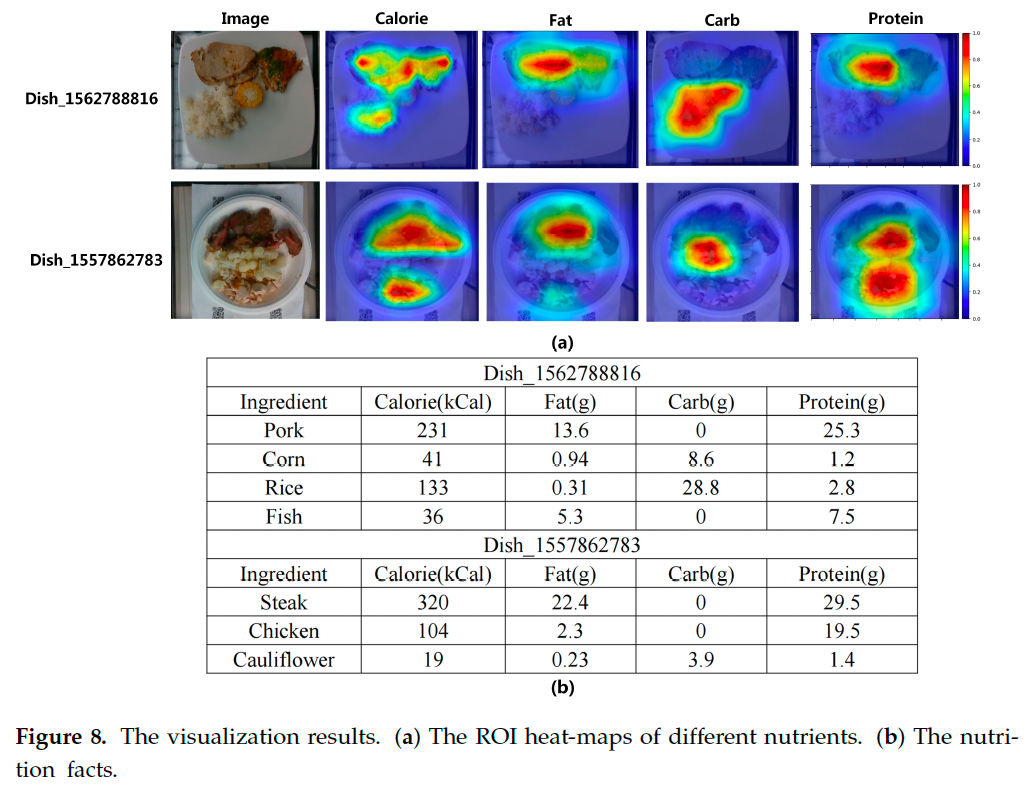
随后我们使用 Grad-CAM [40] 对 RGB-D 融合模块进行可视化,生成热力图以突出模型关注的区域。部分菜品的可视化结果与营养标注如图 8 所示,红色区域表示模型重点关注,蓝色区域表示关注较少。
例如,在 dish_156278816 中,模型在估计脂肪和蛋白质时关注猪肉与鱼类部分,而在估计碳水时则关注米饭与玉米。这表明模型能准确地提取与各营养素相关的视觉信息,并按需分配关注区域。
4. 讨论
每日营养摄入对人类健康至关重要。已有研究表明,适度的热量限制(18%-30%)可带来多种健康益处,如减少内脏脂肪、提升胰岛素敏感性、降低代谢疾病风险 [41,42]。长期实验发现,经过治疗后,Ⅱ度肥胖患者体重平均下降 22.4%,热量与碳水摄入分别减少 18.3% 与 15.6% [43]。
尽管 DPF-Nutrition 在营养估计方面取得了提升,其在热量、质量、蛋白质、脂肪、碳水化合物方面的 PMAE 仍分别为 14.7%、10.6%、20.2%、22.6%、20.7%。对于医疗等高要求场景,这些误差仍可能带来不利影响。
我们对误差较大的测试样本进行了分析,发现主要存在三类问题:
- 食物遮挡与堆叠:例如 dish_1560367980 中,低热量菠菜遮盖高热量披萨,导致热量预测低估 31.6%。
- 不可见成分:如 dish_1562617939 中大量橄榄油不可见,热量 PMAE 达 52.5%,脂肪 PMAE 高达 68.3%。
- 训练集中缺失的食材:如 dish_1562617703 中出现罕见的冰淇淋,热量 PMAE 达 39.5%,碳水 PMAE 达 57.4%。
若将上述样本移除,模型在热量、质量、蛋白质、脂肪、碳水方面的 PMAE 分别下降至 13.4%、10.2%、21.2%、19.2%、18.9%,平均 PMAE 提升 1.2%。然而这类真实场景不可忽视。
此外,营养数据集数量和多样性仍严重不足。尤其是由于食物具有地域性与文化性,不同菜系之间的可迁移性较弱。例如,基于西餐训练的模型难以直接用于中餐估计。中餐菜式多样,食材复杂、烹饪手法丰富,给视觉估计带来了更大挑战。
未来,我们将重点解决食物遮挡和不可见成分的问题。针对食物遮挡,可尝试检测图像中堆叠区域,进行结构化分析并修正营养估计。同时我们也致力于构建更大规模、更具代表性的公开食物数据集。考虑到数据迁移的困难,我们计划先构建一个中式早餐数据集,体量虽小但质量高,具有现实应用价值。
此外,我们还希望将 DPF-Nutrition 应用于实际系统。目前多数饮食打卡 App,如 MyFitnessPal、MyDietCoach 等仍需手动输入,而 DPF-Nutrition 实现了从图像采集到营养估计的全自动流程,具备减轻用户负担、降低成本、提升准确性的潜力。
当然,实用化过程中还需考虑模型的计算复杂度与图像质量问题。我们的设计侧重于精度,但实际应用中计算开销也直接影响用户体验,未来需进一步优化模型以实现轻量化。同时,图像采集中的拍摄角度、距离、光照等也会影响估计结果,需设计方案缓解这些影响。
我们坚信自动化营养评估研究前景广阔。它可以帮助大众实时掌握饮食营养,提升健康意识与饮食管理能力。我们希望本研究能促进营养教育与公共健康的发展。
5. 结论
本文提出了一种面向饮食评估的自动化营养估计方法 —— DPF-Nutrition,旨在开发一种成本低、精度高的营养非接触估计方法。我们的方法通过预测单目图像的深度图,结合恢复出的三维信息与 RGB 图像进行营养估计。
在 Nutrition5k 数据集上的实验结果表明,本文方法在与现有图像估计方法对比中具备显著竞争力,验证了 DPF-Nutrition 的有效性。未来,我们期待自动化视觉营养估计技术能够广泛应用于日常生活,促进饮食教育,提升公众健康水平。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











