







引言:Open Source Week是DeepSeek公司2025年2月21日宣布的一个特别活动,该活动从2025年2月24日开始,持续一周时间。在这期间,DeepSeek每天会开源一个新的代码库,总计开放五个重要的底层技术项目代码库。这些代码库涵盖了从大模型推理加速、混合专家模型通信优化,到矩阵运算内核提升、并行计算效率改进,再到分布式文件系统等AI基础设施的关键层面。更为关键的是这些代码库已通过测试和部署,可投入生产环境。这个活动的目的是完全透明地分享他们的研究进展,促进AI领域的创新和发展。所有开源项目均使用MIT协议,把开源精神最大化。
一文搞懂软件开源协议的那些事【概念、分类、选择及商业应用】-CSDN博客
DeepSeek自从1月20号上线并开源了DeepSeek R1火爆出圈后,就一直吸引着国内、国外各界的目光,这次的开源周[2.24-3.1]更是把全民DeepSeek的热度推向了一个新的高度,每天解锁硬技能,都给大家带来了各种惊艳感。截止今天,开源周已全部结束,本文就和大家一起回顾开源周的那些硬核科技和狠活!一周开源内容概览:
周一:FlashMLA - 高效多头线性注意力解码内核
周二:DeepEP - 专为混合专家模型设计的高性能通信库
周三:DeepGEMM - 高效FP8通用矩阵乘法库
周四:DualPipe - 创新双向流水线并行算法
周五:3FS & Smallpond - 高性能分布式文件系统与数据处理框架
周六:DeepSeek-V3 / R1 推理系统概览
目录
四、【Day4:DualPipe + EPLB + Profiling Data】
六、【Day6:DeepSeek-V3 / R1 推理系统概览】

一、【Day1:FlashMLA】
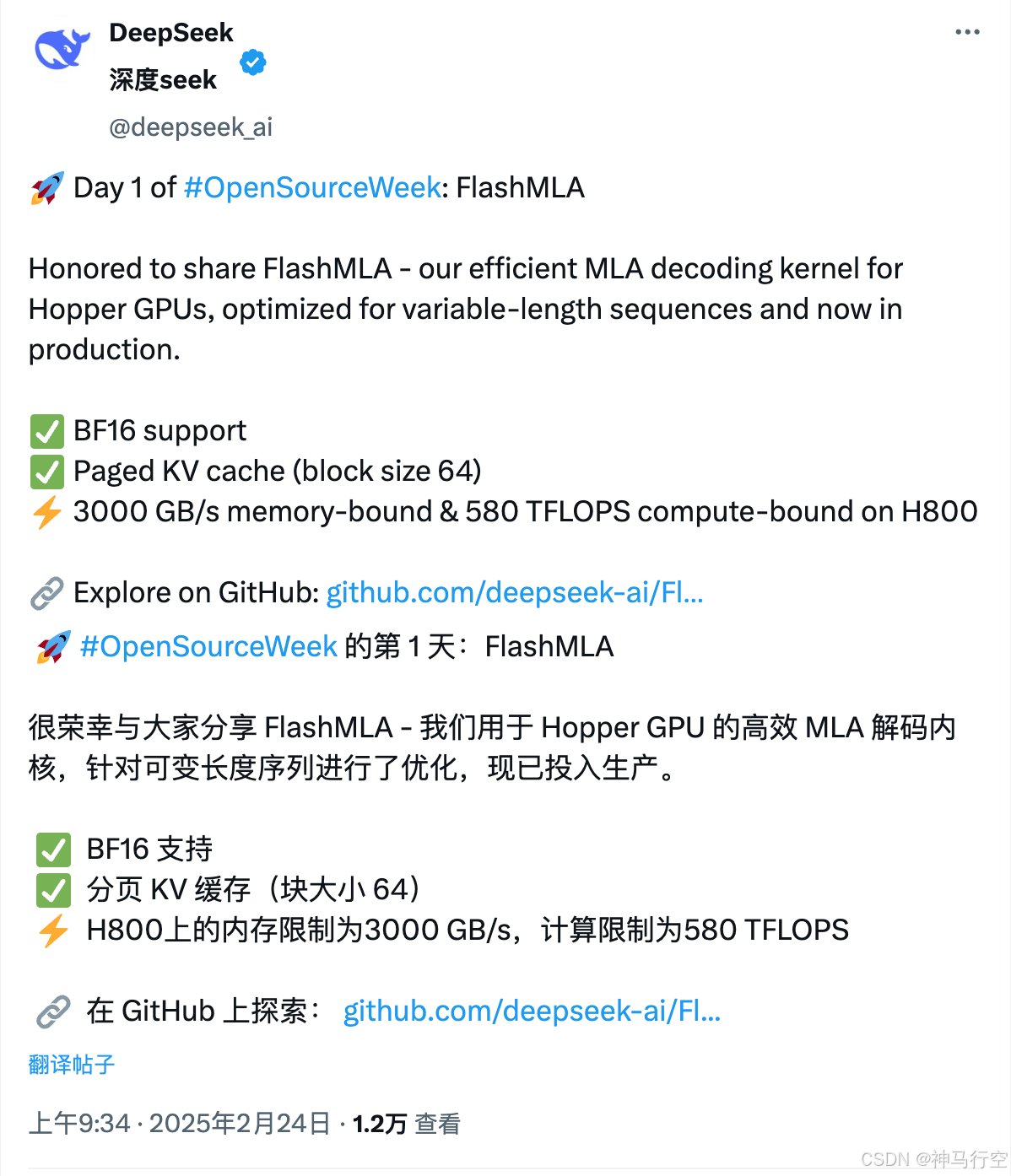
1、简介
FlashMLA是一个为NVIDIA Hopper GPU优化的高效多头线性注意力解码内核,它能够显著提升大语言模型的推理性能。
2、核心特点
-
✅支持BF16数据类型:提供高精度计算支持
-
✅采用分页KV缓存技术:块大小为64,优化内存访问
-
✅针对可变长度序列优化:适应不同长度的输入
-
✅惊人的性能表现:
-
内存受限场景:H800 GPU 上达成 3000 GB/秒内存带宽极限(约1分钟下载300部高清电影)
-
计算受限场景:高达580 万亿次浮点运算/秒(TFLOPS ,相当于1秒完成全人类手工计算几万年的量)
-
让H800的性能暴增,内存带宽和推理性能都提升了2-3倍!过去这类高效工具多被大公司独占,普通开发者用不起。开源后,所有人都能免费使用,降低AI开发门槛。企业用更少的GPU服务器就能完成任务,未来AI应用(比如智能客服、翻译软件)可能更便宜、更普及。
3、FlashMLA 的主要应用场景
- 长序列处理:适合处理数千个标记的文本,如文档分析或长对话。
- 实时应用:如聊天机器人、虚拟助手和实时翻译系统,降低延迟。
- 资源效率:减少内存和计算需求,便于在边缘设备上部署。
目前 AI 训练或推理主要依赖英伟达 H100 / H800,但软件生态还在完善。
由于 FlashMLA 的开源,未来它可以被集成到 vLLM(高效 LLM 推理框架)、Hugging Face Transformers 或 Llama.cpp(轻量级 LLM 推理) 生态中,从而有望让开源大语言模型(如 LLaMA、Mistral、Falcon)运行得更高效。
同样的资源,能干更多的活,还省钱。因为 FlashMLA 拥有更高的计算效率(580 TFLOPS)和更好的内存带宽优化(3000 GB/s),同样的 GPU 资源就可以处理更多请求,从而降低单位推理成本。对于 AI 公司或者云计算服务商来说,使用 FlashMLA 也就意味着更低的成本、更快的推理,让更多 AI 公司、学术机构、企业用户直接受益,提高 GPU 资源的利用率。
4、GitHub 项目地址
GitHub - deepseek-ai/FlashMLA: FlashMLA: Efficient MLA Decoding Kernel for Hopper GPUs
技术栈: C++、Python、Cuda
5、小结
FlashMLA就像给AI引擎换上了“涡轮增压”,让它在处理复杂任务时既快又省电。通过开源,DeepSeek希望让更多人参与AI技术的创新,共同推动科技进步。
二、【Day2:DeepEP】

1、简介
DeepEP 是一个MoE模型和专家并行(Expert Parallelism, EP)设计的通信库。它提供了高吞吐量和低延迟的全互联 GPU 内核,这些内核也被称为 MoE 数据分发(dispatch)和合并(combine)。此外,该库还支持低精度操作,包括 FP8。
为了与 DeepSeek-V3 论文中提出的分组限制门控算法(group-limited gating algorithm)相匹配,DeepEP 提供了一组针对非对称域带宽转发优化的内核,例如从 NVLink 域向 RDMA 域转发数据。这些内核具有高吞吐量,非常适合用于训练和推理预填充任务。此外,它们还支持流式多处理器(Streaming Multiprocessors, SM)数量控制。
针对对延迟敏感的推理解码任务,DeepEP 包含了一组使用纯 RDMA 的低延迟内核,以最大限度地减少延迟。该库还引入了一种基于钩子(hook)的通信与计算重叠方法,不占用任何 SM 资源。
2、核心特点
-
✅ 高效且优化的全互联(all-to-all)通信
-
✅ 支持节点内和节点间通信,兼容 NVLink 和 RDMA
-
✅ 面向训练和推理预填充的高吞吐量内核
-
✅ 面向推理解码的低延迟内核
-
✅ 原生支持 FP8 数据类型分发
-
✅ 灵活的 GPU 资源控制,实现计算与通信的重叠
DeepEP的灵感来源于自然界中的生物进化。在自然界中,生物通过遗传、变异和自然选择逐渐适应环境,变得更强大。可以把它想象成一个“超级智能助手”,DeepEP可以自动设计出高效的程序,而不需要人类程序员一步步地去写代码,它能帮助计算机程序自己变得更好、更聪明!
DeepEP的核心思想就是“让程序自己进化”。假设你想教一个机器人学会走路。传统方法可能需要工程师手动编写大量的代码,告诉机器人每一步该怎么动。但用DeepEP,你可以直接给机器人设定一个目标:“学会走路”。然后,DeepEP会让机器人尝试各种动作,比如抬腿、迈步、保持平衡等。它会不断测试哪种动作效果最好,并逐步改进,最终让机器人学会走路!它模仿了自然界中生物进化的规律,通过不断尝试、筛选和改进,最终生成高效、智能的解决方案。这种方法不仅节省了人类的时间,还能发现一些人类想不到的好办法。
3、主要应用场景
-
大规模MoE模型训练(如千亿参数级别)
-
高并发低延迟的实时推理服务
-
多模态、科学计算等异构计算任务
特别的,在repo最后,deepseek还说明,用了一个没有在英伟达文档里面的指令用来做优化,真是拥有探索精神的黑客,值得学习!估计是英伟达留的后门接口(为了商业上多卖卡,故意压低卡的利用率),可惜被DeepSeek团队“无情撕碎”😊,捅破了英伟达在技术上的那层窗户纸!
一文深度解析DeepSeek:【技术原理+开发实践+行业应用】【为啥DeepSeek能火爆出圈】【9000+字】_deepseek开发经过-CSDN博客
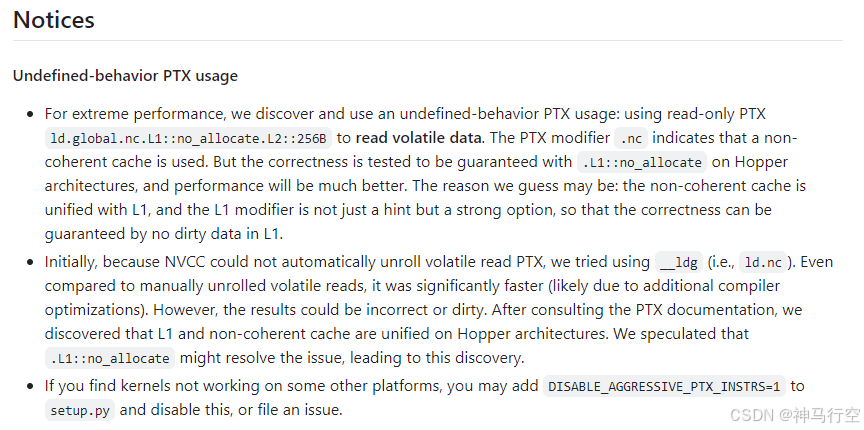
4、GitHub项目地址
https://github.com/deepseek-ai/DeepEP
技术栈:C++、Python、Cuda、CMake
5、小结
DeepEP 通过全栈式通信优化,重新定义了 MoE 模型的并行训练与推理效率,其开源标志着 AI 基础设施领域从封闭优化向开放协作的转变。这一技术突破不仅为开发者提供了高性能工具,也为未来 AI 模型的规模化扩展提供了关键支持。开发者可以直接使用,就像用现成的乐高积木搭房子,降低AI开发门槛,可以使训练速度提升3倍,延迟降低5倍,让AI应用(比如智能助手、自动生成图片)更快落地。
三、【Day3:DeepGEMM】
1、简介
DeepGEMM,全名是“Deep General Matrix Multiplication”(深度通用矩阵乘法),是一个为 DeepSeek-V3 专门设计的,用于 FP8 的,通用矩阵乘法(GEMM)库。FP8 是一种用更少位数(8位)存储数字的方法,就像用更小的便利贴记笔记,虽然每张纸能写的内容少,但搬运和传递更快,节省内存和计算时间。你可以把它看作是一个“超级快的数学助手”,专门用来加速一种叫做矩阵乘法的计算任务。
2、核心特点
-
✅ 支持FP8:DeepGEMM采用了 CUDA 核心两级累加(解决不精确的问题)
-
✅ 支持分组GEMM:主要是改进了CUTLASS的分组GEMM,对MoE模型针对性优化
-
✅ 即时编译: 通过 JIT 技术,代码可以在运行时动态生成和优化,进一步提升性能和灵活性
-
✅ FFMA SASS 交错:deepseek深入分析了SASS编译结果,在FFMA/FADD中调整SASS指令,提高了细粒度 FP8 GEMM效率
3、主要应用场景
矩阵乘法在很多地方都很重要,比如人工智能训练、科学研究、游戏和漫画、大数据分析等,但是矩阵乘法的计算量非常大,尤其是当矩阵很大时,普通的计算机可能需要很长时间才能完成。DeepGEMM使用了一种全新的算法,能够比传统方法更快地完成矩阵乘法。就像你在跑步比赛中找到了一条捷径,能比别人更快到达终点。
4、GitHub项目地址
技术栈:Cuda、Python
5、小结
普通AI库可能有几千行代码,而DeepGEMM的核心逻辑只有300行,就像一篇精炼的作文,既高效又容易理解。还支持普通的和专家混合(Mix-of-Experts,MoE)分组 GEMM。MoE模型像多个“小专家”合作解决问题,DeepGEMM专门优化了这种结构的计算,支持两种特殊排列方式,让“专家们”协作更顺畅。
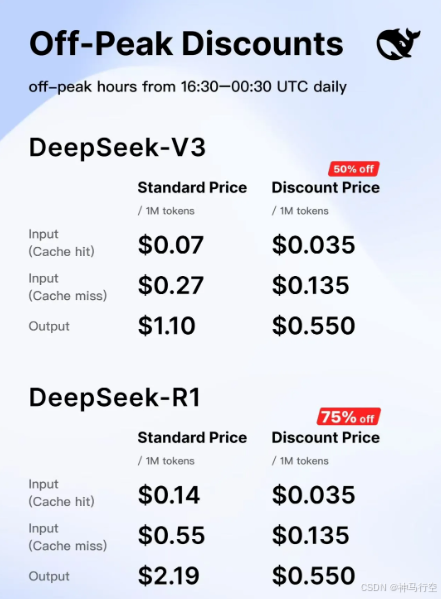
6、降价
开源了这么多的硬核科技还不算,就连价格也要半价!DeepSeek官方表示,DeepSeek-v3 API调用分时段半价!DeepSeek
四、【Day4:DualPipe + EPLB + Profiling Data】
开源周第四天,deepseek带来了三个项目,全部都是关于V3/R1训练和推理相关的并行策略优化。
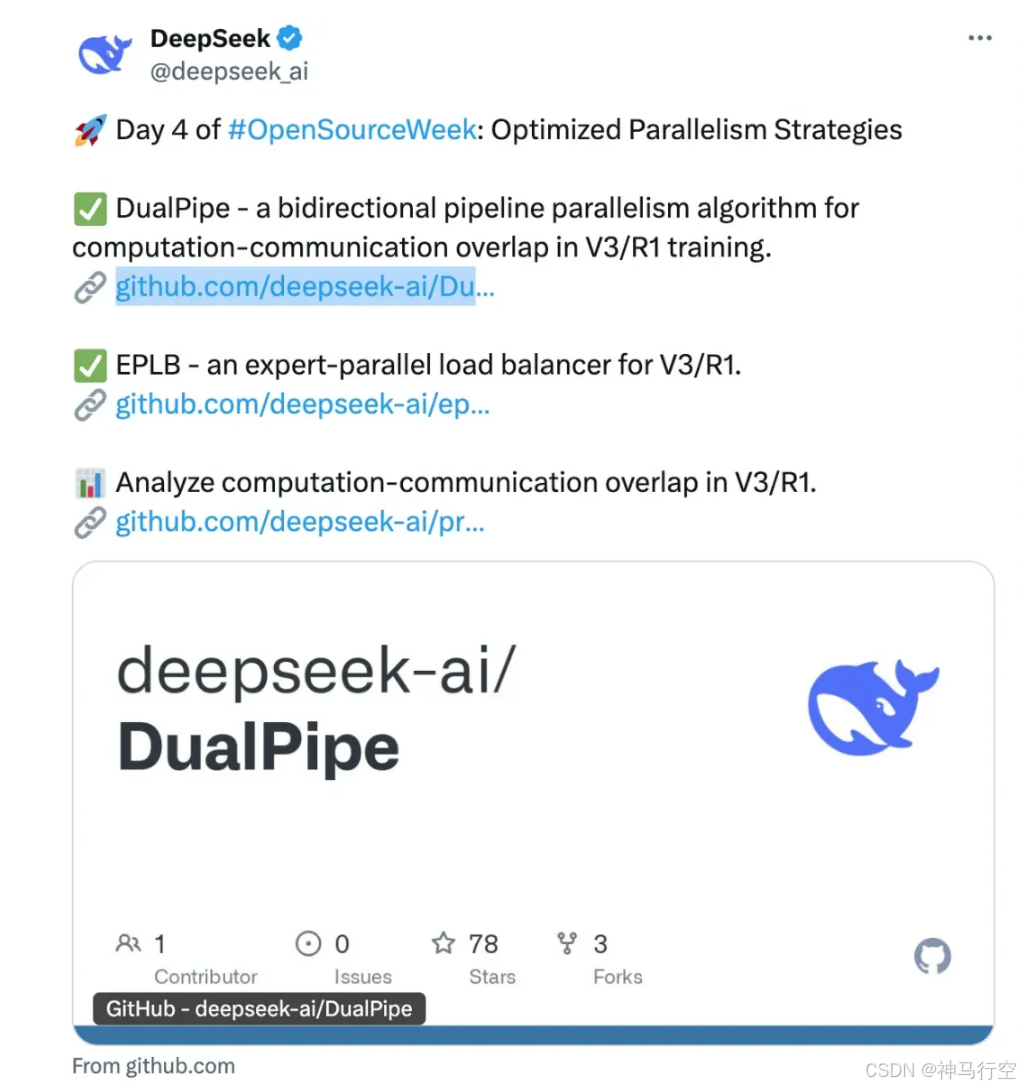
1、简介
DualPipe
DualPipe 是 DeepSeek-V3 技术报告中介绍的创新双向流水线并行算法。此算法实现了前向计算过程(Forward Pass)(模型处理输入数据)和后向计算过程(Backward Pass)(模型更新权重)的计算 - 通信阶段完全重叠,同时减少了 "流水线气泡" (Pipeline Bubbles)—— 即计算设备的空闲等待时间。传统方法是一条传送带来回用,DualPipe 则是两条传送带同时开动。
EPLB
EPLB (Expert Parallelism Load Balancer,专家并行负载均衡器)是 DeepSeek 开发的专门解决 MoE模型(混合专家模型) 在训练或推理时,通过动态调整专家模型的复制和分配策略,确保不同 GPU 之间的负载差异最小化。它就像一个学校的课程安排系统,通过智能调度,确保每个老师的工作量大致相同,提高了整体的教学效率。主要用于优化MoE的分布式部署。
Profiling Data
Profiling Data 是一种性能分析工具,用于记录程序运行过程中的详细信息,帮助开发者了解程序的性能瓶颈、资源利用情况和通信模式。可以把它想象成一个学校的考试成绩分析系统,记录每个学生的考试时间、答题速度、错误率等信息,帮助老师了解学生的学习情况。
2、工作原理



3、核心特性
DualPipe核心特点
-
计算与通信重叠:DualPipe的设计目标是最大化集群的计算性能,在前向传播和后向传播中实现计算与通信的完全重叠,减少传统流水线并行中的空闲等待时间。 在MoE模型的跨节点写作的专家并行(Expert Parallelism)尤其重要。
-
双向调度:DualPipe 是双向调度策略,主要是从流水线的两端同时输入,重复利用硬件资源。还设计了一个复杂但很高效的8步调度策略。
-
显存优化:DualPipe 将模型的最浅层(包括嵌入层)和最深层(包括输出层)部署在同一流水线级别(PP Rank),实现参数和梯度的物理共享,进一步提升内存效率

EPLB 核心特点
-
负载均衡优化:主要是复制高负载的专家(可以称为:冗余专家策略)并对专家分配进行启发式的调整,确保不同GPU之间的负载均衡。
-
分层负载均衡:采用三层结构:节点级→节点内专家复制→GPU分配,优先保证同一组的专家尽量分配到同一个节点,减少跨节点的数据传输,然后在每一层都保证负载均衡。这种应用在deepseek V3中的分组限制路由(Group-Limited Expert Routing)策略显著提升了分布式训练的效率。
-
动态调度策略:根据实际情况动态选择负载均衡策,预填充阶段使用分层策略和解码阶段使用全局策略
4、GitHub项目地址
DualPipe
技术栈:Python
EPLB
GitHub - deepseek-ai/EPLB: Expert Parallelism Load Balancer
技术栈:Python
Profiling Data
GitHub - deepseek-ai/profile-data: Analyze computation-communication overlap in V3/R1.
五、【Day5:3FS + Smallpond】

1、简介
3FS
3FS(Fire-Flyer File System)是 DeepSeek 开源的一种高性能并行文件系统,通过分布式存储架构和并行读写技术,提高了数据处理的效率,用于存储和管理数据,专为应对 AI 训练和推理工作负载的挑战而设计。3FS是deepseek开发的Fire-Flyer AI-HPC的一部分,在论文Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning有详细的介绍。
Fire-Flyer AI-HPC有三个部分,HAI Platform 两年前就开源了,3FS今天也开源了,只剩下HaiScale还没开源。
Smallpond
Smallpond是一个专门处理海量数据的工具(基于 3FS 的数据处理框架),构建于 DuckDB 和 3FS 之上,支持轻量级、高性能的数据处理,可扩展至 PB 级数据集。可以把它想象成一个超级智能的分拣机器人。它利用 3FS 的高性能存储和 DuckDB 的高效查询能力,提供了一个简单易用的接口来处理数据。
安装和使用都比较简单,API不多,提供两种不同的API,分别支持动态和静态构建数据流图。安装:
pip install smallpond
2、核心特点
-
高性能设计:3FS专为充分利用NVMe SSD的高输入输出操作每秒(IOPS)和高吞吐量以及RDMA网络而设计。通过这样的设计,3FS能够高效地处理大量数据请求,满足深度学习和大规模计算的需求。
-
系统架构:3FS系统由四个角色组成:集群管理器、元服务、存储服务和客户端。元服务和存储服务定期向集群管理器发送心跳信号,确保系统稳定和高效运行。多个集群管理器的设置保证了系统的高可用性。
-
请求控制机制:3FS实现了一种请求发送控制机制,以减轻网络拥塞。在客户端接收到读取请求后,存储服务会请求客户端允许传输数据。这种机制限制了并发发送者的数量,有助于在高负载情况下保持良好的性能。
-
强一致性与链复制:3FS采用链复制和分配查询(CRAQ)方法,以提供强一致性。文件内容被切分为多个块,并在一系列存储目标上进行复制,这样可以充分释放所有SSD的吞吐量和IOPS。
-
高吞吐量:通过优化批量写入和读取操作,3FS能够实现每个节点超过10 GiB/s的写入速度,从而加快了检查点保存和加载的过程,降低了训练过程中的延迟。
-
3FS-KV系统:3FS还支持3FS-KV,这是一个基于3FS构建的共享存储分布式数据处理系统,支持键值存储、消息队列和对象存储模型,进一步提升了系统的灵活性和性能。
3FS这个高性能文件系统的实现中,有一点必须提一下,就是deepseek使用Rust来实现了chunk_engine。chunk_engine是块引擎,是3FS存储服务底层的核心模块之一,负责磁盘物理块的管理、分配和回收,上层可以通过块引擎对块数据进行读写。chunk_engine主要使用了cxx自动生成C++绑定,让C++代码直接调用Rust代码。最近几年,Rust在mlsys领域使用频率越来越多,包括huggingface开发的tokenizers也是Rust实现的。deepseek团队选择Rust来实现chunk_engine可能也是觉得Rust的代码好维护,内存安全,性能也很好的优点。
3、工作原理

Smallpond

4、GitHub项目地址
3FS
技术栈:C++、Rust、OpenEdge ABL、Python、C、CMake、Other
Smallpond
GitHub - deepseek-ai/smallpond: A lightweight data processing framework built on DuckDB and 3FS.
技术栈:Python
5、相关链接
https://arxiv.org/pdf/2408.14158
GitHub - HFAiLab/hai-platform: 一种任务级GPU算力分时调度的高性能深度学习训练平台
https://github.com/huggingface/tokenizers
六、【Day6:DeepSeek-V3 / R1 推理系统概览】

1、简介
Deepseek先介绍了推理系统的设计原则,推理系统的优化目标:更大的吞吐,更低的延迟。
推理系统架构图
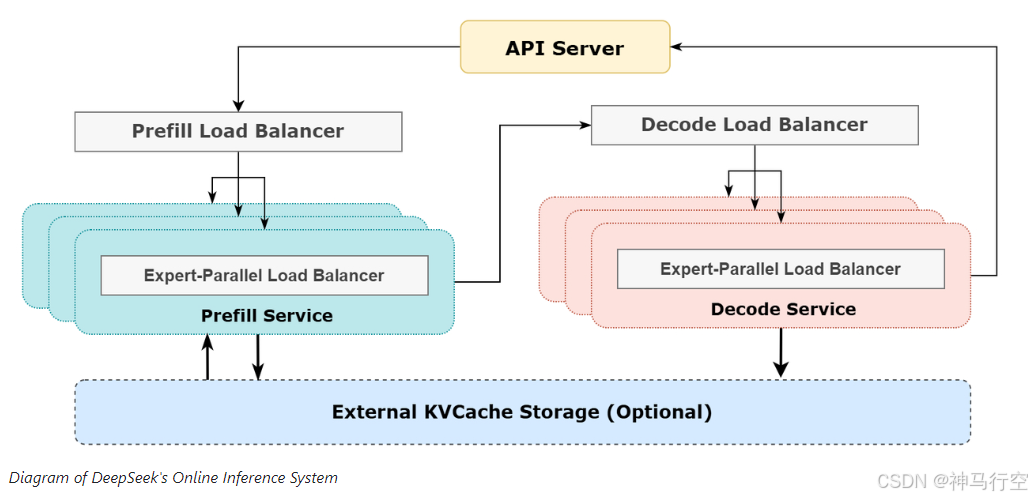
2、大规模跨节点专家并行
Deepseek采用的是多机多卡的专家并行策略:
- Prefill:路由专家 EP32、MLA 和共享专家 DP32,一个部署单元是 4 节点,32 个冗余路由专家,每张卡 9 个路由专家和 1 个共享专家
- Decode:路由专家 EP144、MLA 和共享专家 DP144,一个部署单元是 18 节点,32 个冗余路由专家,每张卡 2 个路由专家和 1 个共享专家
多机多卡的专家并行引入比较大的通信开销,所以使用了双 batch 重叠来掩盖通信开销,提高整体吞吐。
prefill 阶段,两个 batch 的计算和通信交错进行,一个 batch 在进行计算的时候可以去掩盖另一个 batch 的通信开销;
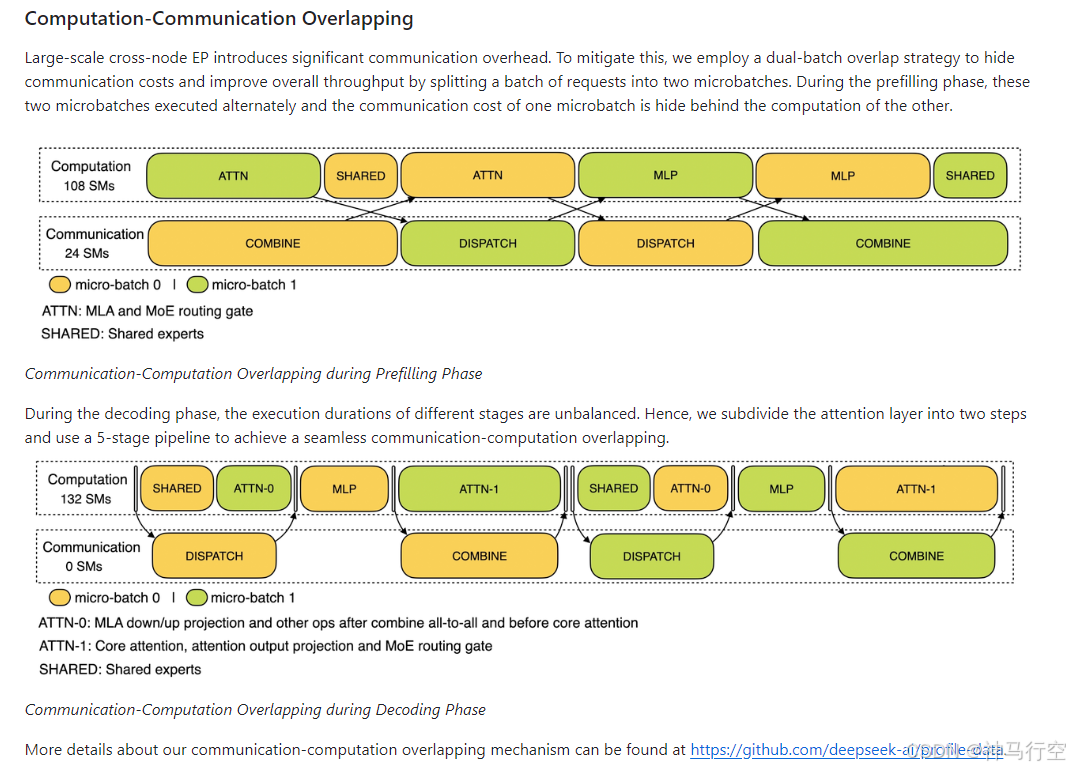
decode 阶段,不同阶段的执行时间有所差别,所以我们把 attention 部分拆成了两个 stage,共计 5 个 stage 的流水线来实现计算和通信的重叠。
因为使用了大规模并行(包括专家并行/数据并行)时,就存在某些GPU过载的情况,需要做计算负载均衡和通信负载均衡。
1、Prefill Load Balancer
- 核心问题:不同数据并行(DP)实例上的请求个数、长度不同,导致 core-attention 计算量、dispatch 发送量也不同
-
优化目标:各 GPU 的计算量尽量相同(core-attention 计算负载均衡)、输入的 token 数量也尽量相同(dispatch 发送量负载均衡),避免部分 GPU 处理时间过长
2、Decode Load Balancer
-
核心问题:不同数据并行(DP)实例上的请求数量、长度不同,导致 core-attention 计算量(与 KVCache 占用量相关)、dispatch 发送量不同
-
优化目标:各 GPU 的 KVCache 占用量尽量相同(core-attention 计算负载均衡)、请求数量尽量相同(dispatch 发送量负载均衡)
3、Expert-Parallel Load Balancer
-
核心问题:对于给定 MoE 模型,存在一些天然的高负载专家(expert),导致不同 GPU 的专家计算负载不均衡
-
优化目标:每个 GPU 上的专家计算量均衡(即最小化所有 GPU 的 dispatch 接收量的最大值)
3、线上推理系统的实际统计数据
DeepSeek R1/V3所有服务都使用H800,矩阵计算和 dispatch 传输采用和训练一致的 FP8 格式,core-attention 计算和 combine 传输采用和训练一致的 BF16,最大程度保证了服务效果。
因为服务白天负载高,晚上负载低,所以负载高的时候全服务器做推理,负载低的时候腾一些机器出来做研究和训练。
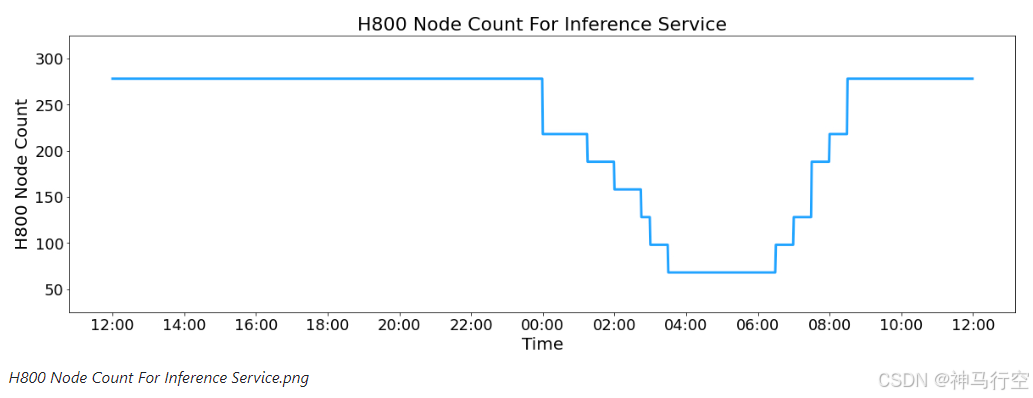
在最近的 24 小时里(北京时间 2025/02/27 12:00 至 2025/02/28 12:00),DeepSeek V3 和 R1 推理服务占用节点总和,峰值占用为 278 个节点,平均占用 226.75 个节点(每个节点为 8 个 H800 GPU)。假定 GPU 租赁成本为 2 美金/小时,总成本为 $87,072/天。
在 24 小时统计时段内,DeepSeek V3 和 R1:
-
输入 token 总数为 608B,其中 342B tokens(56.3%)命中 KVCache 硬盘缓存。
-
输出 token 总数为 168B。平均输出速率为 20~22 tps,平均每输出一个 token 的 KVCache 长度是 4989。
-
平均每台 H800 的吞吐量为:对于 prefill 任务,输入吞吐约 73.7k tokens/s(含缓存命中);对于 decode 任务,输出吞吐约 14.8k tokens/s。
以上统计包括了网页、APP 和 API 的所有负载。如果所有 tokens 全部按照 DeepSeek R1 的定价计算,理论上一天的总收入为 $562,027,成本利润率 545%。
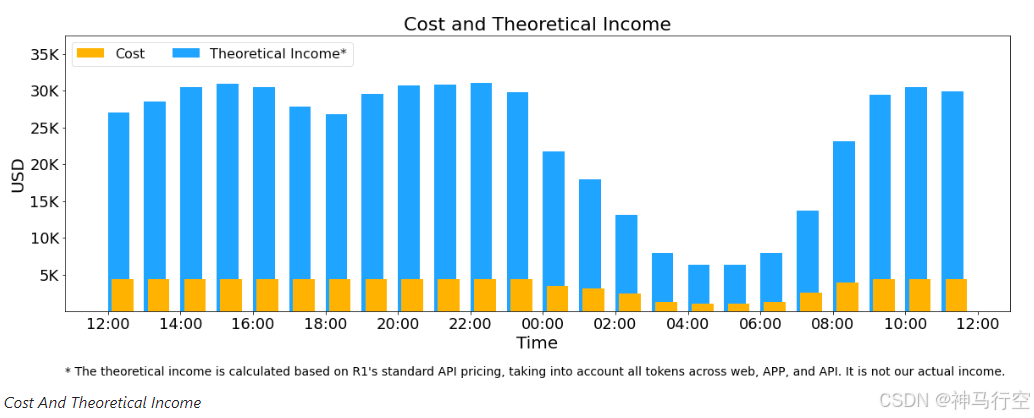
实际上deepseek 是没有这么多收入,因为 V3 的定价更低,同时收费服务只占了一部分,另外夜间还会有折扣。
4、相关链接
https://zhuanlan.zhihu.com/p/27181462601
七、总结
DeepSeek本周开源内容覆盖了从底层算力优化(如Flash MLA、DeepGEMM)到分布式通信(DeepEP)、并行计算工具(DualPipe、EPLB),再到存储系统(3FS)的全栈技术,旨在提升AI训练和推理效率,降低开发门槛。这些成果充分体现了DeepSeek团队第一性原理的思考方式和强悍的意志,这些开源项目不仅推动了行业技术进步,也对AI生态中的芯片、应用开发等环节产生深远影响。有了DeepSeek,像燧原、沐曦、天数、智芯、摩尔线程、壁仞,这些国产芯片也可以更多介入训练和推理生意了。所以,国产芯片肯定是受益的一方,第二就是基础层做硬件的。除了AGI,Deepseek也许还有更大的野心。如果把大模型比作更底层的操作系统,那OpenAI可能是‘IOS’,而DeepSeek就是‘安卓’。因为比技术更重要的是,开源的生态和协同。
1、一周开源内容汇总
https://github.com/deepseek-ai/open-infra-index
2、深度解读
DeepSeek开源周 Day05:从3FS盘点分布式文件存储系统
DeepSeek开源周 Day04:从DualPipe聊聊大模型分布式训练的并行策略
DeepSeek开源周 Day03:从DeepGEMM看大模型算力提速的矩阵乘法
DeepSeek开源周 Day02:从DeepEP开源趋势重新审视大模型Infra
DeepSeek开源周 Day01:从FlashMLA背后原理回顾KV Cache
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









