







引言
大语言模型LLM(如DeepSeek、ChatGPT、文心一言等)的“智慧”源于它们学习的海量数据集。简单来说,数据集就是模型的“知识库”,通常由互联网公开的文本、图片、视频等。这些数据需满足两个特点:规模大和多样性。规模大是指数据量可达千亿级词汇,让模型学习复杂规律;多样性则涵盖多领域(如科技、文学)、多语言、多形式(对话、新闻),帮助模型适应不同场景。例如,训练数据中既有百科知识,也有日常对话,模型才能既解答专业问题,又能闲聊。
大语言模型LLM的数据集Datasets从最初的预训练阶段到最终的评估阶段,一般可分为四大类别:预训练语料库、指令微调数据集、偏好数据集和评估数据集。每一类数据集的作用各不相同。
本文重点以DeepSeek为例,详细介绍预训练数据集相关内容。
目录
3.3、扩展:OpenR1-Math-220k(数学推理专项数据集)

一、开源通用预训练数据集
1.1、数据规模与内容
DeepSeek-V3模型在预训练阶段使用了148万亿个token,涵盖书籍、网页、代码、学术论文等多样化的高质量文本数据,确保模型具备广泛的通用知识。
1.2、作用
构建基础语言理解能力,覆盖自然语言处理、代码生成、逻辑推理等多领域任务。其数据多样性通过多源整合实现,涉及类似Common Crawl的网页数据、GitHub代码库及学术文献库。
1.3、扩展:通用数据集
通用数据集的数据类型可以分为八大类:网页、语言文本、书籍、学术材料、代码、平行语料库、社交媒体和百科全书。
1.3.1、网页数据
网页数据在预训练语料库比较普遍,它的数据量庞大,并且会着时间的推移不断更新和变化,并且可以涵盖不通的主题和语言。但是网页数据是以超文本标记语言(HTML)格式存在,同时包含大量的噪声、无关信息和敏感内容,需要在使用前对数据进行清洗。网页数据语料库一般通过两种方式构建:
- 方式一是基于 Common Crawl重新选择和清洗数据:比如RefinedWeb、C4、mC4、CC-Stories、RealNews、CLUECorpus2020等
- 方式二是独立抓取各种原始网页,然后采用一系列清洗流程,获得最终的语料库:像WuDaoCorpora-Text;
此外,一些多类别语料库中的网页数据也是通过这种方法构建的, 比如MNBVC、WanJuanText-1.0 和 TigerBot pretrain zh等。
示例:
RefinedWeb是通过严格的过滤和CommonCrawl的大规模重复数据删除构建的; 我们发现在RefinedWeb上训练的模型可以实现在线或优于在精选数据集上训练的模型的性能,同时仅依赖web数据。 RefinedWeb也是 “多模式友好的”: 它包含已处理样本中图像的链接和alt文本。
链接:OpenDataLab 引领AI大模型时代的开放数据平台
1.3.2、语言文本
语言文本数据主要由两部分组成。
1、第一部分是基于广泛来源的书面和口头语言构建的电子文本数据。
- 美国国家语料库(ANC),其内容主要包括各种美国英语的书面和口头材料。语料库的第二版有2200万字的规模,非常适合模型学习语言。
- BNC (英国国家语料库),包含了1亿字的电子文本资源,涵盖了英国英语的口语和书面语材料。
示例:美国国家语料库(ANC)
Open American National Corpus | Open Data for Language Research and Education
2、第二部分是基于各个领域或主题的相关书面材料构建的电子文本数据。
- FinGLM涵盖了2019年至2021年一些上市公司的年度报告。数据类型属于金融领域的语言文本材料。
- TigerBot-law包括了包括中国宪法和中国刑法在内的11类法律法规,属于法律领域的语言文本材料。
- News-crawl从在线报纸和其他新闻来源提取单语种文本,涵盖了59种语言的新闻文本。
示例:中华古诗词数据库
1.3.3、书籍
书籍也是预训练语料库中常见的数据类型。与网页相比,书籍具有更长的文本内容和更优质的数据质量,这有助于提高LLMs的性能,使它们能够捕获人类语言特征,同时学习更深入的语言知识和上下文信息。书籍的一个好处是,所涵盖的领域极其多样化。因此,可以方便地对书籍进行细粒度的领域分类。常用的资源包括Smashwords 和Project Gutenberg。
- Smashwords 是一个大型的免费电子书库,包含超过50万本电子书。
- Project Gutenberg 作为最早的数字图书馆,致力于数字化和归档文化作品,也拥有丰富的书籍资源。
- Anna’s Archive:2023年,Anna’s Archive [23]成为世界上最大的开源和开放数据图书馆。创建者从Libgen、Sci-Hub等图书馆中抓取书籍。截至2024年2月,规模已达到641.2TB,并且还在不断增长。
示例:Smashwords
Smashwords - Products, Competitors, Financials, Employees, Headquarters Locations
1.3.4、学术材料
学术材料主要包括学术论文、期刊文章、会议论文、研究报告、专利等。这类数据的特点是具有高专业性和严谨性,质量高。将学术材料纳入语料库,可以帮助模型学习理解专业领域的知识。比如:
- arXiv是目前最常用的语料库,它收集了涵盖物理、数学、计算机科学、生物学和定量经济学的论文预印本。
- S2ORC 包含了各个学科的英文学术论文,包含摘要、参考文献列表和结构化的全文内容。
- PubMed Central在医学领域十分重要,它开放了近500万篇生物医学出版物。
- The Pile中,学术材料数据占38.1%,而网页数据只占18.1%。
- RedPajama-V1学术材料总计280亿个tokens,占比为2.31%。
示例:arXiv中DeepSeek-R1的技术论文
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
1.3.5、代码
现在大模型的一个常见应用场景是生成和理解代码,所以模型训练过程中使用的代码质量,会直接影响生成代码的有效性。同时需要注意的一点是,在网络抓取时,需要谨慎遵守项目作者设置的代码使用协议。代码数据的主要语料库包括The Stack、BIGQUERY和Github。
- The Stack:6TB开源代码,包含358种编程语言的。它适用于编程领域大型语言模型的开发。
- BIGQUERY:是Google BigQuery 语料库公开发布的一个子集,专注于六种选定的编程语言。
- Github:代码托管平台,提供开源和私有软件项目的代码库管理和代码片段共享功能。
- StackOverflow:作为一个致力于编程和开发的问答社区,它涵盖了编程语言、开发工具和算法等主题的问题和答案。所以也是代码数据的常见来源。
- phi-1是专门训练的代码模型。它不仅包括从The Stack和StackOverflow中选出的代码数据,还利用GPT-3.5生成了与Python相关的教科书和练习题。
示例:Github中DeepSeek的开源代码库
1.3.6、平行语料库
平行语料库是指:不同语言的文本或句子对的集合。平行语料库数据对于增强LLMs的机器翻译能力和跨语言任务性能至关重要。平行语料库的收集通常通过两个主要途径进行。
1、第一种是通过从互联网资源中提取文本。
- ParaCrawl 利用开源软件爬取网页,构建了一个公开可用的平行语料库。它包含了2.23亿个过滤后的句子对。
- MTP 收集和整理现有的中英文本数据,累计达到了3亿个文本对,这是目前最大的开源中英对照文本对数据集。
示例:TensorFlow中的para_crawl数据集
2、第二种方法是从联合国多语言文件中收集平行语料库。
- MultiUN 通过联合国官方文件系统收集平行文本对。这些文件涵盖了联合国的六种官方语言(阿拉伯语、中文、英语、法语、俄语和西班牙语)以及有限的德语版本。
- UNCorpus v1.0 由1990年至2014年的文本内容组成,这些内容包括公共领域的联合国官方记录和其他会议文件,总计799276个文件。这些文件大多数涵盖了六种官方语言。
示例:中英文NLP数据集
1.3.7、社交媒体数据
社交媒体数据指的是从各种媒体平台收集的文本内容,主要包括用户生成的帖子、评论和用户之间的对话数据。数据反映了社交媒体上个体之间的实时动态和互动性。尽管社交媒体数据中可能存在有害信息,如偏见、歧视和暴力,但对于LLMs的预训练仍然至关重要。这是因为社交媒体数据有利于模型学习会话交流中的表达能力,并捕捉社会趋势、用户行为模式等。
1、在英文社交媒体平台上,数据通常在StackExchange和Reddit等平台上进行爬取。
- StackExchange是一个包含各种主题的问答对集合,是最大的公开可用问答对资源之一。
- Reddit包括大量的用户生成帖子以及每个帖子对应的赞成和反对票数。除了作为社交媒体数据,Reddit还可以用于基于投票计数构建人类偏好数据集。
- WebText从Reddit的4500万个网页链接中抓取社交媒体文本,确保每个链接至少有3个赞成票以保证数据质量。然而,只有WebText的一小部分是公开可用的。
示例:StackExchange
2、中文社交媒体数据通常从知乎、网易等平台收集。
示例:网易页面
1.3.8、百科全书
百科全书数据指的是从百科全书、在线百科全书网站或其他知识数据库中提取的文本信息。在线百科全书网站上的数据由专家、志愿者或社区贡献者编写和编辑,提供了一定的权威性和可靠性。由于其易于获取,它在预训练语料库中被更频繁地包含,用来增强LLMs的能力。
最常见的百科全书语料库是Wikipedia。它具有免费、开源、多语言和高文本价值的特点。语料库会从Wikipedia中选择特定语言的数据,进行爬取和过滤,作为预训练语料库的一部分。
在中文语言百科全书语料库方面,除了Wikipedia的中文版外,还有百度百科语料库。它涵盖了几乎所有的知识领域。
示例:TigerBot-wiki 专门致力于收集与中国百科全书相关的数据。这构成了TigerBot模型反思过程中使用的原始外部大脑数据,规模为205MB。
GitHub - TigerResearch/TigerBot: TigerBot: A multi-language multi-task LLM
1.3.9、多类别数据
多类别语料库是指包含两种或更多类型的数据,使用多类别数据,有助于增强LLMs的泛化能力。在预训练期间,可以选择现有的开源多类别语料库直接进行预训练,或者选择多个单一类别语料库进行一定比例的混合。
1、英文中常见的多类别语料库,包括RedPajama-V1、The Pile、TigerBot pretrain en和Dolma。
- RedPajama-V1是LLaMA模型使用的预训练语料库的部分复制。它包含六种数据类型,其中网页数据占大多数,达到87.0%。整体展示呈现出数据分布的偏斜。
- The Pile 拥有更丰富的数据类型,并且分布更加均匀。它是各种子集的组合,旨在尽可能多地捕获文本的形式。
- TigerBot pretrain en 从开源语料库中选择五种类型的数据,力求平衡分布。
- Dolma 英语语料库已经公开发布,包含3T个token。可以更好的用于推进预训练模型领域的开放研究。
2、中文多类别语料库包括MNBVC 和TigerBot pretrain zh。
- MNBVC 没有提供数据类型的分布,但包括各种形式的纯文本中文数据,如新闻、小说、杂志、古典诗词、聊天记录等。其目标是达到40TB的数据量,以匹配ChatGPT。数据收集仍在进行中。
- TigerBot pretrain zh专注于网页内容、百科全书、书籍和语言文本。
除了常见的中英文语料库,北京人工智能研究院与其他机构合作,构建了世界上最大的开源阿拉伯语预训练语料库,称为ArabicText 2022。它可以用于训练阿拉伯语LLMs。还有两个多语言和多类别的语料库,即WanJuanText-1.0和ROOTS。
示例:ArabicText 2022 语料库
二、数学与代码专项数据集
2.1、数据来源
包括数学竞赛题目(如AIME、MATH-500)、LeetCode编程题及编译器生成的测试用例反馈,强化模型在数学推理和代码生成中的表现。
2.2、作用
提升模型在STEM领域的专项能力。例如,DeepSeek-R1通过规则奖励系统(如答案格式验证)优化数学问题解决能力,而代码数据则用于训练模型生成可执行代码。
示例:MATH-500
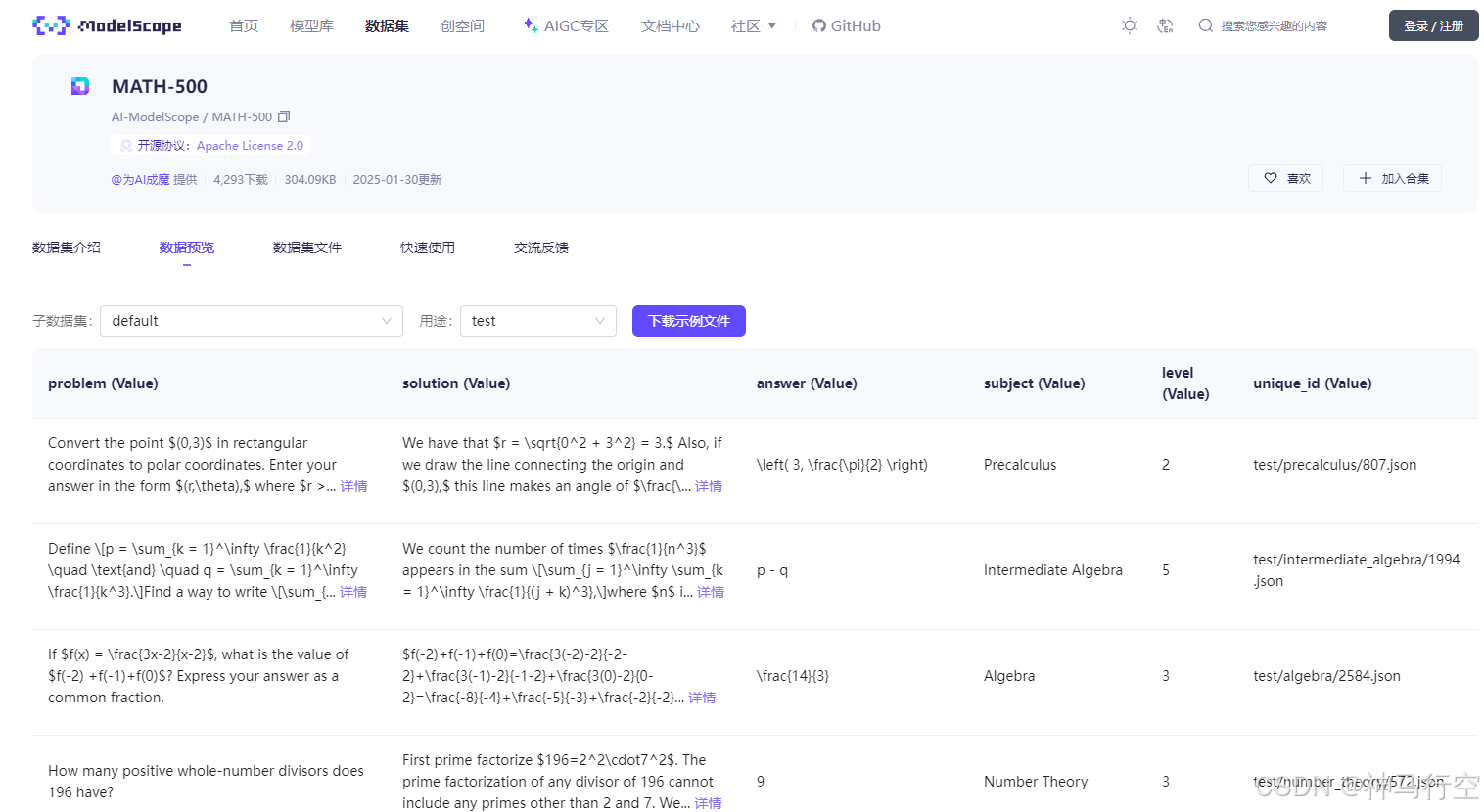
三、强化学习与后训练数据集
3.1、数据生成方式
基于规则生成结构化数据,例如要求模型输出包含<think>标签的推理过程,并结合准确度奖励(如答案正确性验证)优化模型行为。DeepSeek官方生成的60万条数学与代码推理数据,通过规则奖励系统和强化学习优化模型能力。数据包含多轮交互轨迹,支持知识蒸馏至小模型(如32B参数模型)。
3.2、作用
通过强化学习(RL)提升模型在复杂数学问题、代码生成(如LeetCode题目)中的推理能力,支持拒绝采样和奖励模型筛选。如DeepSeek-R1-Zero完全依赖RL训练,无需监督微调(SFT),实现自主推理模式进化。
3.3、扩展:OpenR1-Math-220k(数学推理专项数据集)
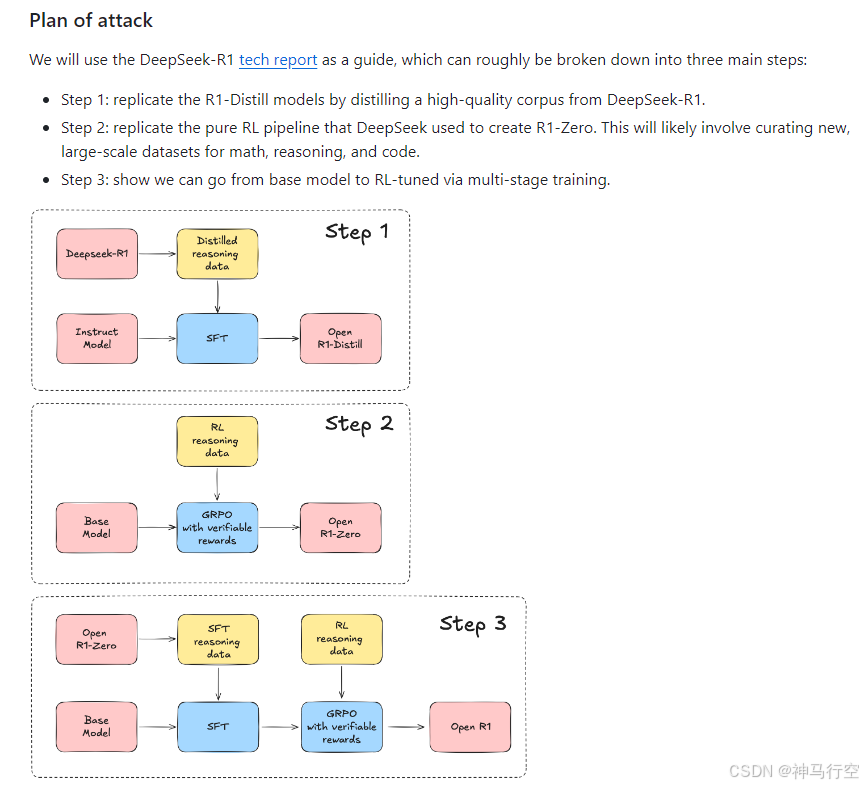
1、概述
OpenR1-Math-220k(数学推理专项数据集)是由Hugging Face的Open R1项目开源的高质量数学推理数据集,包含22万条经过严格筛选的数学问题及其推理轨迹。数据基于DeepSeek R1生成,覆盖NuminaMath-CoT 1.5改进版中的问题,并经过数学验证工具和Llama3.3-70B-Instruct模型的二次审核,确保答案正确性。
2、作用
用于训练小模型(如Qwen-7B)实现与DeepSeek-R1相当的数学推理能力,支持监督微调(SFT)和偏好优化(DPO)方法。
-
生成脚本与代码:GitHub Open R1项目
3、数据生成
下面是open-r1 伪代码的形式展示数据集生成方式。
(1)、准备环境(依赖实际的CUDA版本)
conda create -n sglang124 python=3.11
conda activate sglang124
pip install torch=2.5.1 --index-url https://download.pytorch.org/whl/cu124
pip install sgl-kernel --force-reinstall --no-deps
pip install "sglang[all]>=0.4.2.post4" --find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer/(2)、加载模型
sbatch slurm/serve_r1.slurm -m "/fsx/deepseek-r1-checkpoint" -e "sglang124"(3)、运行脚本生成数据集
python scripts/generate_reasoning.py \
--dataset-name "AI-MO/NuminaMath-1.5" \
--output-file "numinamath_r1_generations.jsonl" \
--prompt-column "problem" \
--uuid-column "problem" \
--api-addr "<SGLANG_SERVER_ADDRESS>:39877" \
--num-generations 2 \
--max-tokens 16384 \
--max-concurrent 200四、垂直领域预训练数据集
垂直领域预训练数据集通常用于LLMs的增量预训练阶段。在通用预训练语料库上训练基础模型后,如果需要将模型应用于特定领域的下游任务,可以进一步使用特定领域预训练语料库进行增量预训练,即常说的微调。
4.1、金融领域
金融领域的预训练语料库有助于大型语言模型(LLMs)学习与金融市场、经济学、投资和金融相关的主题。数据通常来源于金融新闻、财务报表、公司年报、金融研究报告、金融文献、市场数据等。金融领域的数据类型通常是相似的,差异主要在于数据时间范围、来源网站等因素。
- BBT-FinCorpus 是一个大规模的中文金融领域语料库,包含四个部分:公司公告、研究报告、金融新闻和社交媒体。它用于预训练BBT-FinT5基础模型。
- 轩辕大模型使用的预训练语料库是FinCorpus ,它是由公司公告、金融信息和新闻、金融考试问题组成。
- FinGLM 涵盖了2019年至2021年上市公司的年度报告。
- 在TigerBot 中,TigerBot-research 和TigerBot-earning分别侧重于研究报告和财务报告。
- 上海证券交易所、深圳证券交易所等有各上市公司的公开信息。
示例:巨潮资讯网
4.2、教育领域
整合多学科教材及试题库,如中公教育的“云信”模型通过解析岗位文档优化AI就业规划系统。
- Proof-Pile-2 收集了与数学相关的代码(17种编程语言)、数学网络数据和数学论文。它已被用于训练数学模型 Llemma。。
4.3、医疗领域
医疗领域的预训练语料库可以为大型语言模型(LLMs)提供学习材料,涵盖疾病、医疗技术、药物和医学研究等主题。数据通常来源于医学文献、医疗诊断记录、病例报告、医疗新闻、医学教科书等相关内容。
- Medical-pt 已通过开放获取的医学百科全书和医学教科书数据集进行了增强;
- PubMed Central 则开放获取了与生物医学研究相关的出版物。
示例:柳叶刀(The Lancet)
4.4、交通领域
TransGPT,作为中国首个开源的大规模交通模型,已向学术界提供了TransGPT-pt语料库 。该语料库包括丰富的与交通相关的数据,如交通文献、交通技术项目、交通统计数据、工程建设信息、管理决策信息、交通术语等。
TransGPT
4.5、法律领域
法律文本数据通常来源于法律文件、法律书籍、法律条款、法院判决和案例、法律新闻等法律来源。例如,TigerBot-law 已编译了11个类别的中国法律法规供模型学习。另外,部分多类别语料库也纳入了从法律相关网站抓取的数据,如The Pile。
示例:TigerBot-law-plugin
五、总结
DeepSeek的数据集构建策略以大规模通用预训练+垂直领域增强为核心,结合强化学习与知识蒸馏技术,实现从通用能力到专项任务的平衡。其开源模型(如DeepSeek-V3、R1)及技术报告为学术界提供了可复现的数据处理与训练框架,而企业级应用则通过私有化数据微调推动行业智能化转型。未来,低算力迁移与多模态数据整合将是其技术迭代的关键方向。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗

















 2557
2557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









