







目录
2.1、AI算力芯片可应用于云端、边缘端、终端,当前以GPU为主流
2.2、英伟达主导全球GPU市场,GPU生态体系建立极高的行业壁垒
2.3、云厂商等大厂自研芯片趋势明显,推动定制ASIC芯片市场高速成长
2.4、美国不断加大对高端AI算力芯片出口管制,国产厂商迎来黄金发展期

一、AI 算力芯片发展概览
1.1、芯片分类
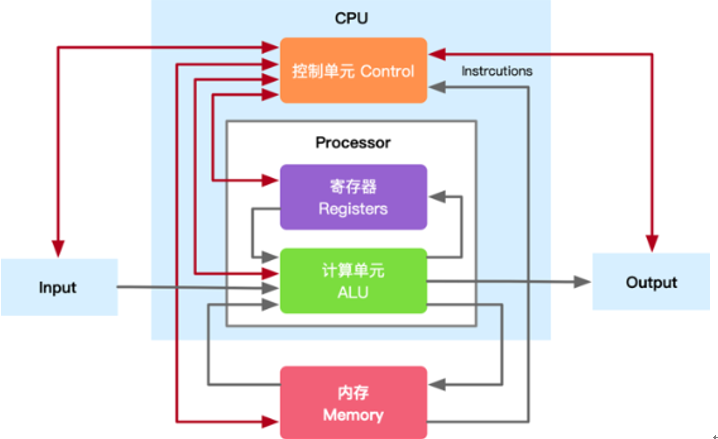
CPU
CPU 是Central Processing Unit(中央处理器)的简称,它负责执行指令和计算,控制着计算机的所有组件。它主要由算术单元(ALU,Arithmetic Logic Unit)、存储单元(MU,Memory Unit)也可以称为寄存器和控制单元(CU,Control Unit)。
GPU
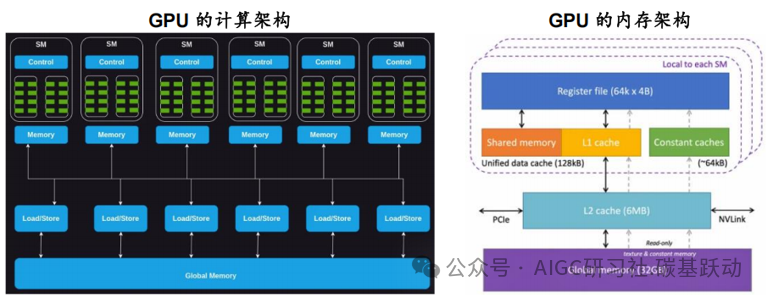
GPU 是Graphics Processing Unit(图形处理器)的简称,它是计算机系统中负责处理图形和图像相关任务的核心组件。GPU由流处理器(SM)、光栅操作单元、纹理单元、专用加速单元等多个关键组件组成,这些组件协同工作,以实现高效的通用计算和图形渲染。
AI 芯片
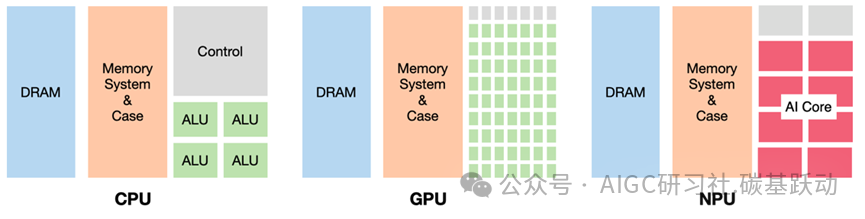
AI 芯片是专门为加速 AI 应用中的大量针对矩阵计算任务而设计的处理器或计算模块。与传统的通用芯片如中央处理器(CPU)不同,AI 芯片采用针对特定领域优化的体系结构(Domain-Specific Architecture,DSA),侧重于提升执行 AI 算法所需的专用计算性能。
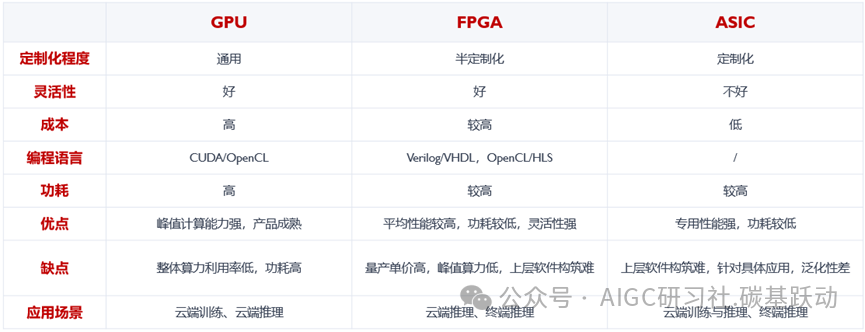
作为加速应用的AI芯片,主要的技术路线有三种:GPU、FPGA、ASIC
拓展一点:GPU与AI
2012 年的一系列重要事件标志着 GPU 在 AI 计算中的崭露头角。Hinton和 Alex Krizhevsky 设计的 AlexNet 是一个重要的突破,他们利用两块英伟达 GTX 580 GPU 训练了两周,将计算机图像识别的正确率提升了一个数量级,并赢得了2012 年 ImageNet 竞赛冠军。这一成就充分展示了GPU 在加速神经网络模型训练中的巨大潜力。同时,谷歌和吴恩达等团队的工作也进一步强调了 GPU 在 AI 计算中的重要性。谷歌利用 1000 台 CPU 服务器完成了猫狗识别任务,而吴恩达等则只用了 3 台 GTX680-GPU 服务器,取得了同样的成果。这一对比显示了 GPU 在深度学习任务中的显著加速效果,进一步激发了对 GPU 在 AI 领域的广泛应用。
从2005/2006 年开始,一些研究人员开始尝试使用 GPU 进行 AI 计算,但直到 2012/2013 年,GPU 才被更广泛地接受。随着神经网络层次越来越深、网络规模越来越大,GPU 的加速效果越来越显著。这得益于 GPU 相比 CPU 拥有更多的独立大吞吐量计算通道,以及较少的控制单元,使其在高度并行的计算任务中表现出色。
因此,GPU在 AI 发展中的作用愈发凸显,它为深度学习等复杂任务提供了强大的计算支持,并成为了 AI 计算的标配。从学术界到互联网头部厂商,都开始广泛采用 GPU,将其引入到各自的生产研发环境中,为 AI 技术的快速发展和应用提供了关键支持。
1.2、大模型持续迭代,推动全球算力需求高速成长
ChatGPT 热潮引发全球科技企业加速迭代 AI 大模型。
ChatGPT 是由美国公司 OpenAI 开发、在 2022 年11月发布上线的人工智能对话机器人,ChatGPT 标志着自然语言处理和对话 AI 领域的一大步。ChatGPT 热潮引发全球科技企业加速布局,谷歌、Meta、百度、阿里巴巴、华为、DeepSeek 等科技企业随后相继推出 AI 大模型产品,并持续迭代升级。

GPT-4.5带来更自然的交互体验。
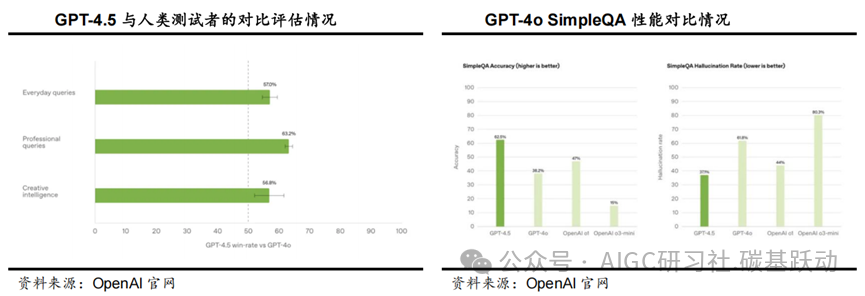
2025年2月27日,OpenAI正式发布AI大模型GPT-4.5。作为OpenAI 迄今为止规模最大、知识最丰富的模型,GPT-4.5 在GPT-4o 的基础上进一步扩展了预训练,与专注于科学、技术、工程和数学(STEM)领域的其他模型不同,GPT-4.5更全面、更通用。在与人类测试者的对比评估中,GPT-4.5 相较于GPT-4o的胜率(人类偏好测试)更高,包括但不限于创造性智能(56.8%)、专业问题(63.2%)以及日常问题(57.0%);GPT-4.5带来更自然、更温暖、更符合人类的交流习惯。GPT-4.5 的知识面更广,对用户意图的理解更精准,情绪智能也有所提升,因此特别适用于写作、编程和解决实际问题,同时减少了幻觉现象。
OpenAIo3进一步提升复杂推理能力。
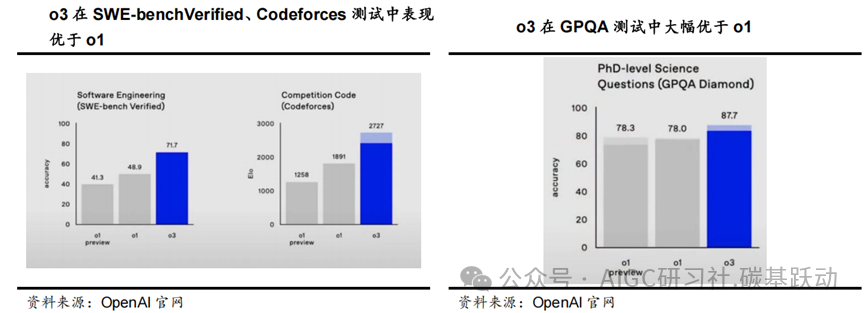
2024年12月20日,OpenAI发布全新推理大模型o3,o3模型在多个标准测试中的表现均优于o1,进一步提升复杂推理能力,在一些条件下接近通用人工智能(AGI)。在软件基准测试(SWE-benchVerified)中,o3的准确率达到了71.7%,相较o1提升超过20%;在编程竞赛(Codeforces)中,o3的评分达到2727,接近OpenAI顶尖程序员水平;而在数学竞赛(AIME)中,o3的准确率高达96.7%,远超o1的83.3%;在博士生级别问题测试集(GPQA)中,o3达到87.7分,远超人类选手的程度;在ARC-AGI测试中,o3首次突破了人类水平的门槛,达到87.5%。
大模型持续迭代,推动算力需求高速成长。
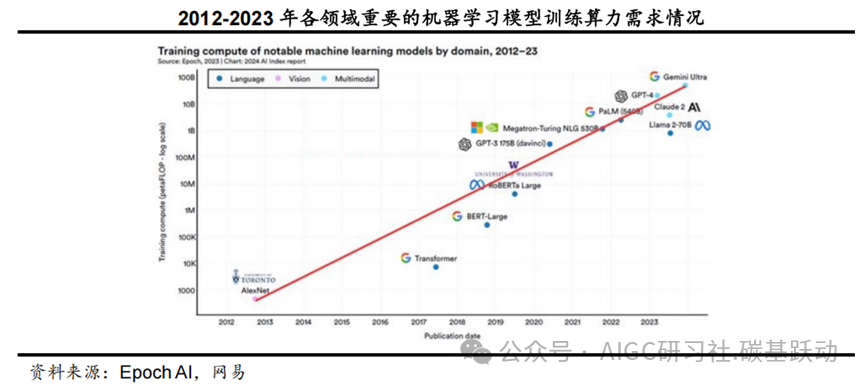
Scaling law推动大模型持续迭代,根据EpochAI的数据,2012-2023年大模型训练的算力需求增长近亿倍,目前仍然在大模型推动算力需求高速成长的趋势中。
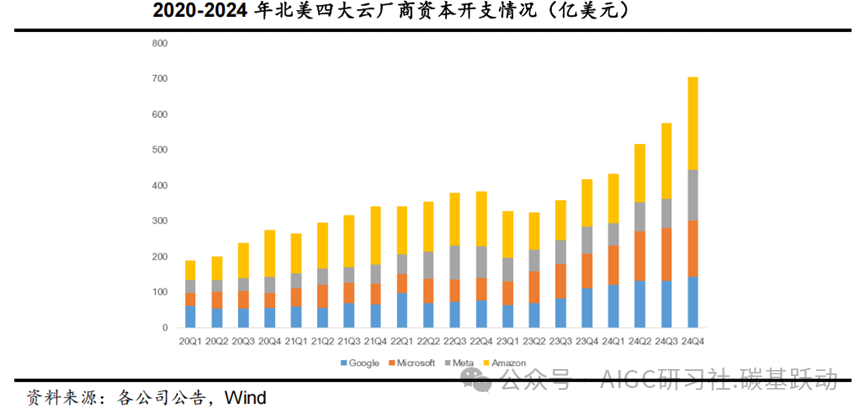
北美四大云厂商受益于AI对核心业务的推动,持续加大资本开支。
受益于AI对于公司核心业务的推动,北美四大云厂商谷歌、微软、Meta、亚马逊2023年开始持续加大资本开支,2024年四季度四大云厂商的资本开支合计为706亿美元,同比增长69%,环比增长 23%。目前北美四大云厂商的资本开支增长主要用于AI基础设施的投资,并从AI投资中获得了积极回报,预计2025年仍有望继续大幅增加资本开支。
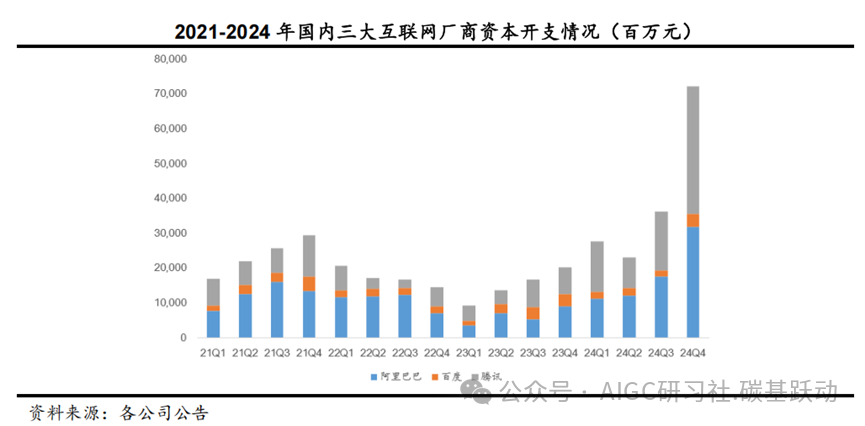
国内三大互联网厂商不断提升资本开支,国内智算中心加速建设。
国内三大互联网厂商阿里巴巴、百度、腾讯2023年也开始不断加大资本开支,2024年四季度三大互联网厂商的资本开支合计为720亿元,同比增长259%,环比增长99%,预计2025年国内三大互联网厂商将继续加大用于AI基础设施建设的资本开支。根据中国电信研究院发布的《智算产业发展研究报告(2024)》的数据,截至2024年6月,中国已建和正在建设的智算中心超250个;目前各级政府、运营商、互联网企业等积极建设智算中心,以满足国内日益增长的算力需求。
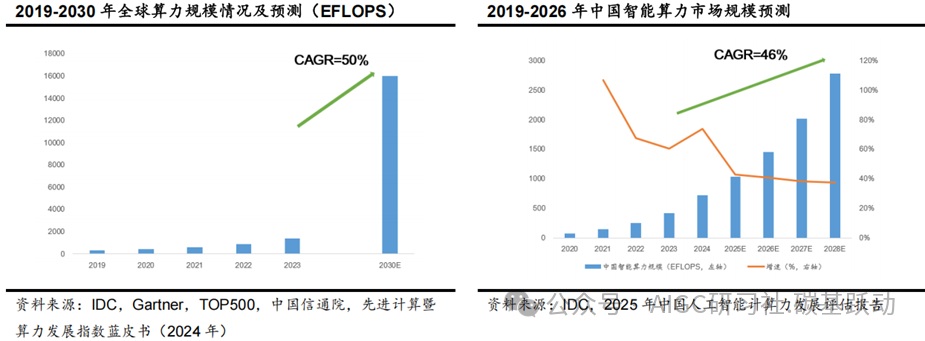
人工智能进入算力新时代,全球算力规模高速增长。
随着人工智能的快速发展以及AI大模型带来的算力需求爆发,算力已经成为推动数字经济飞速发展的新引擎,人工智能进入算力新时代,全球算力规模呈现高速增长态势。根据IDC、Gartner、TOP500、中国信通院的预测,预计全球算力规模将从2023年的1397 EFLOPS增长至2030年的16ZFLOPS,预计2023-2030年全球算力规模复合增速达50%。根据IDC的数据,2024年中国智能算力规模为725.3EFLOPS,预计2028年将达到2781.9 EFLOPS,预计2023-2028年中国智能算力规模的复合增速为46.2%。
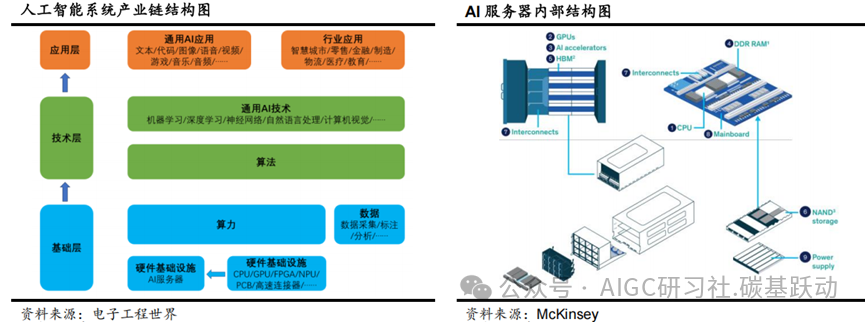
1.3、AI算力芯片是算力的基石
AI服务器是支撑生成式AI应用的核心基础设施。
人工智能产业链一般为三层结构,包括基础层、技术层和应用层,其中基础层是人工智能产业的基础,为人工智能提供数据及算力支撑。服务器一般可分为通用服务器、云计算服务器、边缘服务器、AI服务器等类型,AI服务器专为人工智能训练和推理应用而设计。大模型兴起和生成式AI应用显著提升了对高性能计算资源的需求,AI服务器是支撑这些复杂人工智能应用的核心基础设施,AI服务器的其核心器件包括CPU、GPU、FPGA、NPU、存储器等芯片,以及PCB、高速连接器等。
大模型有望推动AI服务器出货量高速成长。
大模型带来算力的巨量需求,有望进一步推动AI服务器市场的增长。根据IDC的数据,2024年全球AI服务器市场规模预计为1251亿美元,2025年将增至1587亿美元,2028年有望达到2227亿美元,2024-2028年复合增速达15.5%,其中生成式AI服务器占比将从2025年的29.6%提升至2028年的37.7%。IDC预计2024年中国AI服务器市场规模为190亿美元,2025年将达259亿美元,同比增长 36.2%,2028年将达到552亿美元,2024-2028年复合增速达30.6%。
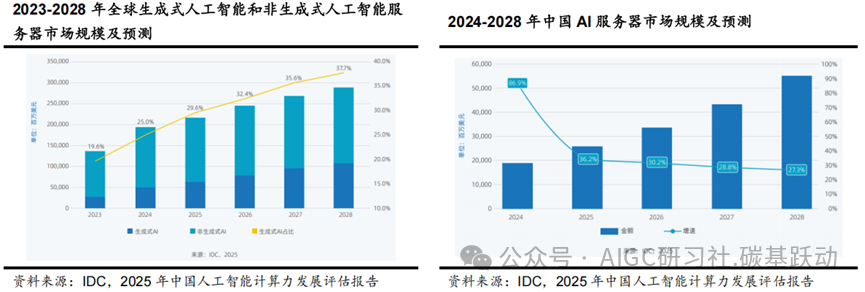
AI算力芯片是算力的基石。
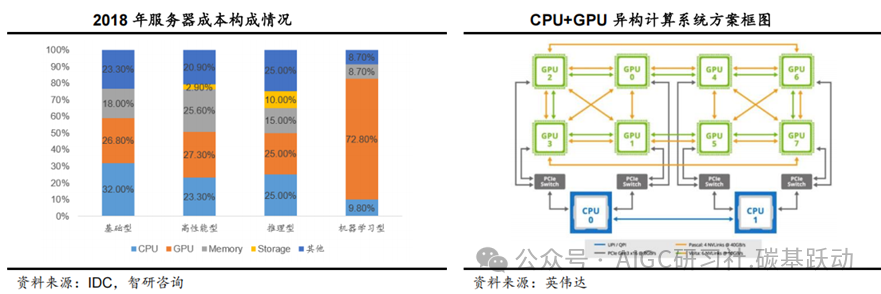
CPU+GPU是目前AI服务器主流的异构计算系统方案,根据IDC 2018年服务器成本构成的数据,推理型和机器学习型服务器中CPU+GPU成本占比达到50-82.6%,其中机器学习型服务器GPU成本占比达到72.8%。AI算力芯片具备强大的并行计算能力,能够快速处理大规模数据和复杂的神经网络模型,并实现人工智能训练与推理任务;AI算力芯片占AI服务器成本主要部分,为AI服务器提供算力的底层支撑,是算力的基石。AI算力芯片作为“AI时代的引擎”,有望畅享AI算力需求爆发浪潮,并推动AI技术的快速发展和广泛应用。
二、AI算力芯片生态
2.1、AI算力芯片可应用于云端、边缘端、终端,当前以GPU为主流
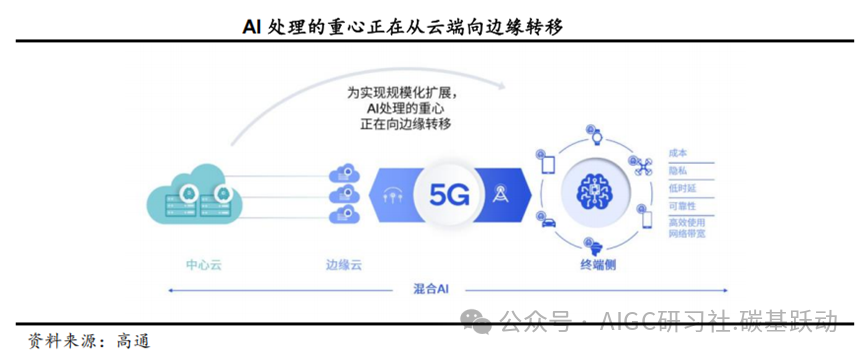
混合AI是AI的发展趋势。
AI训练和推理受限于大型复杂模型而在云端部署,而AI推理的规模远高于AI训练,在云端进行推理的成本极高,将影响规模化扩展。随着生成式AI的快速发展以及计算需求的日益增长,AI处理必须分布在云端和终端进行,才能实现AI的规模化扩展并发挥其最大潜能。混合AI指终端和云端协同工作,在适当的场景和时间下分配AI计算的工作负载,以提供更好的体验,并高效利用资源;在一些场景下,计算将主要以终端为中心,在必要时向云端分流任务;而在以云为中心的场景下,终端将根据自身能力,在可能的情况下从云端分担一些AI工作负载。与仅在云端进行处理不同,混合AI架构在云端和边缘终端之间分配并协调AI工作负载;云端和边缘终端如智能手机、汽车、个人电脑和物联网终端协同工作,能够实现更强大、更高效且高度优化的AI。
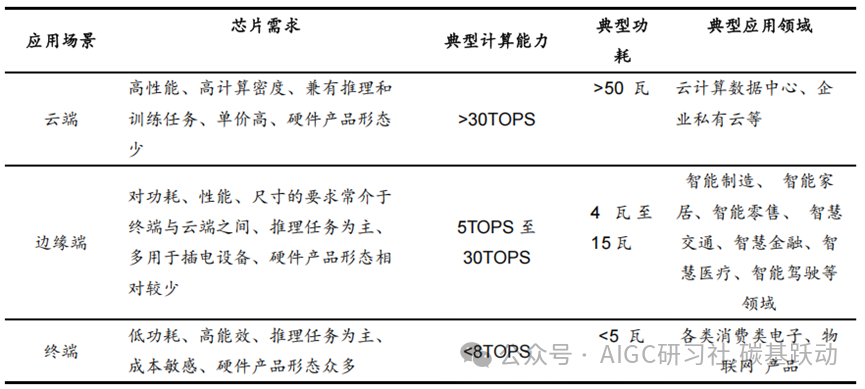
AI算力芯片按应用场景可分为云端、边缘端、终端AI算力芯片。
人工智能的各类应用场景,从云端溢出到边缘端,或下沉到终端,都需要由AI算力芯片提供计算能力支撑。云端、边缘端、终端三种场景对于AI算力芯片的运算能力和功耗等特性有着不同要求,云端AI算力芯片承载处理海量数据和计算任务,需要高性能、高计算密度,对于算力要求最高;终端对低功耗、高能效有更高要求,通常对算力要求相对偏低;边缘端对功耗、性能的要求通常介于终端与云端之间;本文主要针对于云端AI算力芯片。
云端、边缘端、终端应用场景对AI算力芯片的算力需求情况
根据芯片的设计方法及应用,AI算力芯片可分为通用型AI芯片和专用型AI芯片。
通用型AI芯片为实现通用任务设计的芯片,主要包括CPU、GPU、FPGA等;专用型AI芯片是专门针对人工智能领域设计的芯片,主要包括TPU(Tensor Processing Unit)、NPU(Neural Network Processing Unit)、ASIC等。在通用型AI芯片中,由于在计算架构和性能特点上的不同,CPU适合处理逻辑复杂、顺序性强的串行任务;GPU是为图形渲染和并行计算设计的处理器,具有大量的计算核心,适合处理大规模并行任务;FPGA通过集成大量的可重构逻辑单元阵列,可支持硬件架构的重构,从而灵活支持不同的人工智能模型。专用型AI芯片是针对面向特定的、具体的、相对单一的人工智能应用专门设计的芯片,其架构和指令集针对人工智能领域中的各类算法和应用作了专门优化,具体实现方法为在架构层面对特定智能算法作硬化支持,可高效支持视觉、语音、自然语言处理和传统机器学习等智能处理任务。
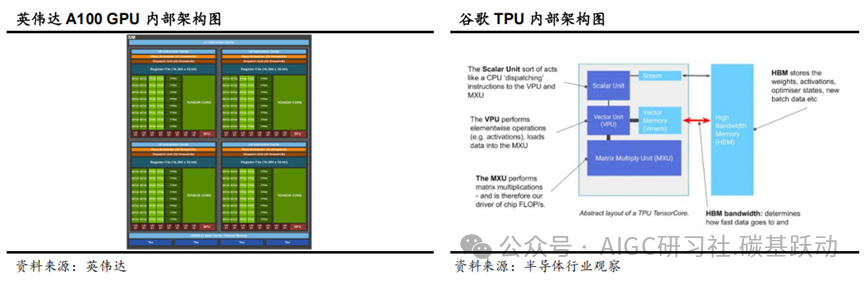
当前AI算力芯片以GPU为主流,英伟达主导全球AI算力芯片市场。
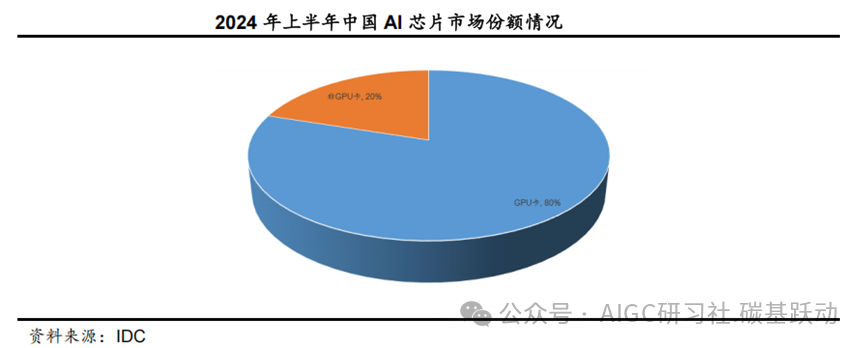
根据的IDC数据,2024上半年,中国AI加速芯片的市场规模达超过90万张;从技术角度来看,GPU卡占据80%的市场份额。根据Precedence Research数据,2022年英伟达占据全球AI芯片市场份额超过80%,其中英伟达占全球AI服务器加速芯片市场份额超过95%。
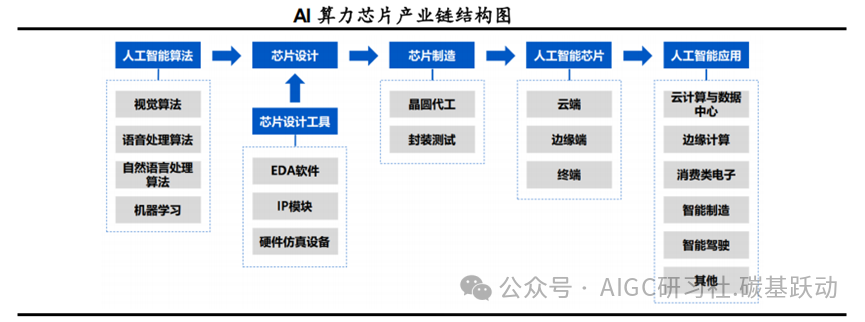
AI算力芯片产业链包括人工智能算法、芯片设计、芯片制造及下游应用环节。
人工智能芯片产业链上游主要是人工智能算法以及芯片设计工具,人工智能算法覆盖广泛,包括视觉算法、语音处理算法、自然语言处理算法以及各类机器学习方法(如深度学习等)。AI算力芯片行业的核心为芯片设计和芯片制造,芯片设计工具厂商、晶圆代工厂商与封装测试厂商为AI算力芯片提供了研发工具和产业支撑。AI算力芯片行业的下游应用场景主要包括云计算与数据中心、边缘计算、消费类电子、智能制造、智能驾驶、智慧金融、智能教育等领域。
2.2、英伟达主导全球GPU市场,GPU生态体系建立极高的行业壁垒
GPU(Graphics Processing Unit)即图形处理单元,是计算机的图形处理及并行计算
的核心。
GPU最初主要应用于加速图形渲染,如3D渲染、图像处理和视频解码等,是计算机显卡的核心;随着技术的发展,GPU也被广泛应用于通用计算领域,如人工智能、深度学习、科学计算、大数据处理等领域,用于通用计算的GPU被称为GPGPU(General- Purpose computing on Graphics Processing Units),即通用GPU。
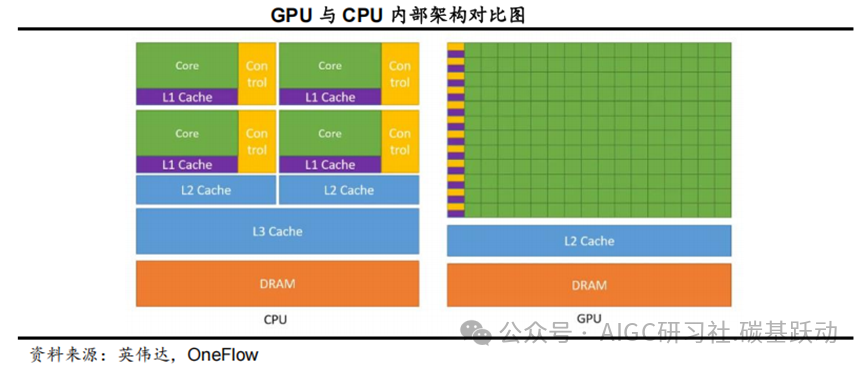
GPU与CPU在内部架构上有显著差异,决定了它们各自的优势领域。
GPU通过大量简单核心和高带宽内存架构,优化并行计算能力,适合处理大规模数据和高吞吐量任务;CPU通过少量高性能核心和复杂控制单元优化单线程性能,适合复杂任务和低延迟需求。
GPU硬件性能可以通过多个参数综合评估,包括核心数量、核心频率、显存容量、显存
位宽、显存带宽、显存频率、工艺制程等。
GPU的核心数量越多、核心频率越高,GPU的计算能力越强。显存容量越大,GPU能够处理的数据规模就越大;显存带宽越高,GPU 显存与核心之间数据传输的速率越快。GPU的工艺制程越先进,GPU性能越好、功耗越低。

GPU架构对性能影响至关重要,不同架构下的硬件性能参数有所不同。
GPU 架构的每次升级在计算能力、图形处理能力、能效比等多方面对性能产生了显著提升,所以GPU架构对性能影响至关重要。通过对比英伟达GeForce系列RTX 3090、RTX 4090、RTX 5090,不同GPU架构下硬件性能参数有所不同。随着GPU架构的升级,GPU厂商通常会采用更先进的工艺制程,比如英伟达从8nm 工艺的Ampere架构升级到4nm 工艺的Blackwell架构,在相同性能下,新工艺能够降低功耗,或者在相同功耗下提供更高的性能。
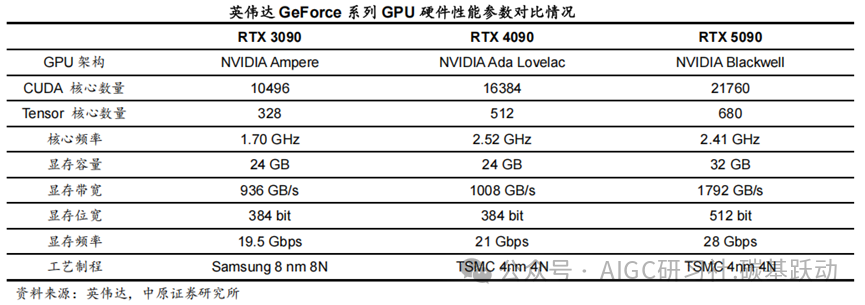
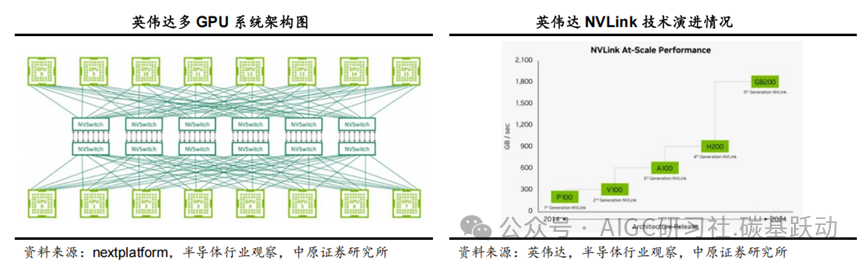
多GPU互连成为行业发展趋势,以提高系统的计算能力。
随着AI大模型时代来临,AI算力需求不断增长,由于单GPU芯片算力和内存有限,无法承载大模型的训练任务,通过多种互连技术将多颗GPU芯片互连在一起提供大规模的算力,已成为行业发展趋势。对于多GPU系统,如何实现GPU之间的高速数据传输和协同工作是关键问题。英伟达推出NVLink、NVSwitch等互连技术,通过更高的带宽和更低的延迟,为多GPU系统提供更高的性能和效率,支持GPU 之间的高速数据传输和协同工作,提高通信速度,加速计算过程等。NVLink用于连接多个GPU之间或连接GPU与其他设备(如CPU、内存等)之间的通信,它允许GPU之间以点对点方式进行通信,具有比传统的PCIe 总线更高的带宽和更低的延迟。NVSwitch实现单服务器中多个GPU之间的全连接,允许单个服务器节点中多达16个GPU实现全互联,每个GPU都可以与其他GPU直接通信,无需通过CPU或其他中介。经过多年演进,NVLink技术已升级到第5代,NVLink 5.0数据传输速率达到100GB/s,每个Blackwell GPU有18个NVLink连接,Blackwell GPU将提供1.8TB/s的总带宽,是PCIe Gen5总线带宽的14倍;NVSwitch也升级到了第四代,每个NVSwitch支持144个NVLink端口,无阻塞交换容量为14.4TB/s。
GPU应用场景广泛,数据中心GPU市场快速增长。
GPU最初设计用于图形渲染,但随着其并行计算能力的提升,GPU的应用场景已经扩展到数据中心、自动驾驶、机器人、区块链与加密货币、科学计算、金融科技、医疗健康等多个领域。近年来数据中心GPU市场在全球范围内呈现出快速增长的趋势,尤其是在人工智能、高性能计算和云计算等领域。

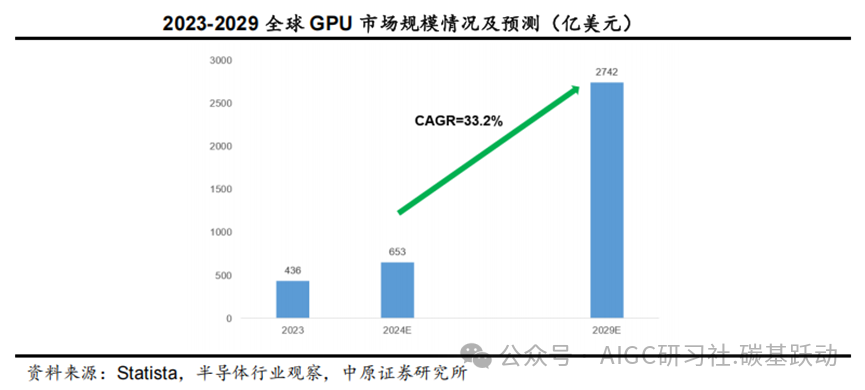
GPU是AI服务器算力的基石,有望畅享AI算力需求爆发浪潮。
GPU是AI服务器算力的基石,随着AI算力规模的快速增长将催生更大的GPU芯片需求。根据Statista的数据,2023年全球GPU市场规模为436亿美元,预计2029年市场规模将达到2742亿美元,预计2024-2029年复合增速达33.2%。
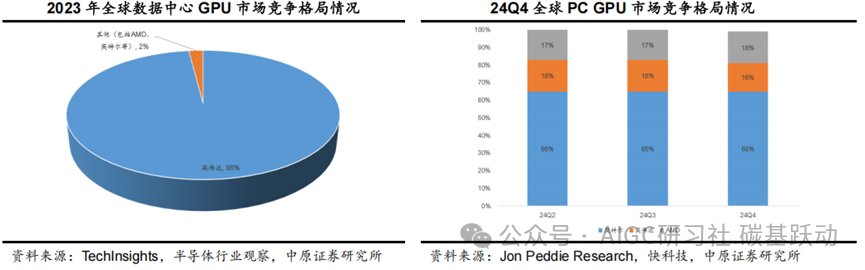
英伟达主导全球GPU市场。
根据TechInsights的数据,2023年全球数据中心GPU总出货量达到了385万颗,相比2022年的267万颗同比增长44.2%,其中英伟达数据中心2023年GPU出货量呈现爆发式增长,总计约376 万台,英伟达在数据中心GPU出货量中占据98%的市场份额,英伟达还占据全球数据中心GPU 市场98%的收入份额,达到362 亿美元,是2022 年109 亿美元的三倍多。根据Jon Peddie Research的数据,2024年第四季度全球PC GPU出货量达到7800万颗,同比增长0.8%,环比增长6.2%,其中英特尔、AMD、英伟达的市场份额分别为65%、18%、16%。
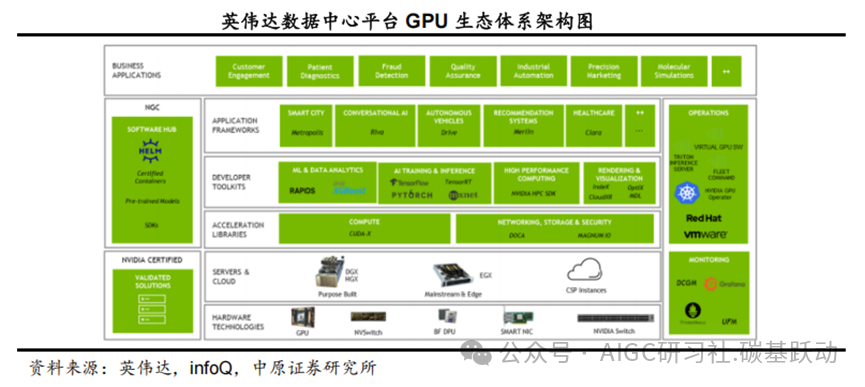
GPU生态体系主要由三部分构成,包括底层硬件,中间层API接口、算法库、开发工具
等,上层应用。
以英伟达数据中心平台GPU生态体系为例,底层硬件的核心是英伟达的GPU产品、用于GPU之间高速连接的NVSwitch 、节点之间互联的各种高速网卡、交换机等,以及基于GPU 构建的服务器;中间层是软件层面的建设,包括计算相关的CUDA-X、网络存储及安全相关的DOCA 和MAGNUM IO加速库,以及编译器、调试和优化工具等开发者工具包和基于各种行业的应用框架;上层是开发者基于英伟达提供的软硬件平台能力,所构建的行业应用。
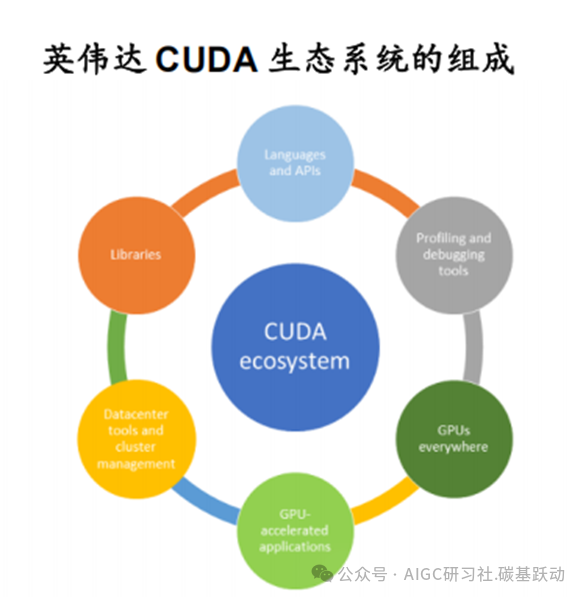
GPU厂商非常重视软件生态系统的构建,英伟达CUDA生态几乎占据通用计算GPU领
域的全部市场。
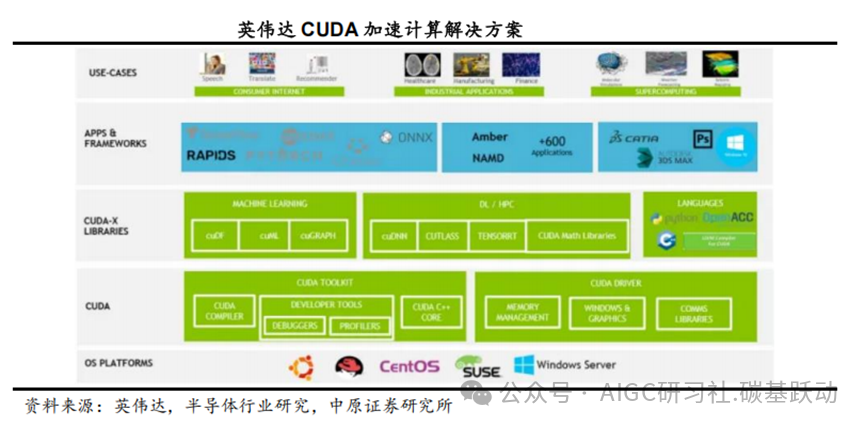
CUDA全称为Compute Unified DeviceArchitecture,即统一计算设备架构,是英伟达推出的基于其GPU的通用高性能计算平台和编程模型。目前CUDA 生态包括编程语言和API、开发库、分析和调试工具、GPU加速应用程序、GPU与CUDA架构链接、数据中心工具和集群管理六个部分。编程语言和API支持C、C++、Fortran、Python 等多种高级编程语言;英伟达提供的CUDA 工具包可用于在GPU 上开发、优化和部署应用程序,还支持第三方工具链,如PyCUDA、AltiMesh Hybridizer、OpenACC、OpenCL、Alea -GPU 等,方便开发者从不同的编程接口来使用CUDA。英伟达在CUDA 平台上提供了CUDA-X,它是一系列库、工具和技术的集合,其中包括数学库、并行算法库、图像和视频库、通信库、深度学习库等,同时还支持OpenCV、FFmpeg 等合作伙伴提供的库。英伟达提供了多种工具来帮助开发者进行性能分析和调试,NVIDIA Nsight是低开销的性能分析、跟踪和调试工具,提供基于图形用户界面的环境,可在多种英伟达平台上使用;CUDA GDB 是Linux GDB 的扩展,提供基于控制台的调试接口;CUDA -Memcheck 可用于检查内存访问问题;此外还支持第三方解决方案,如ARM Forge、TotalView Debugger 等。目前几乎所有的深度学习框架都使用CUDA/GPU计算来加速深度学习的训练和推理,英伟达维护了大量经过GPU加速的应用程序。在数据中心中,英伟达与生态系统合作伙伴紧密合作,为开发者和运维人员提供软件工具,涵盖AI 和高性能计算软件生命周期的各个环节,以实现数据中心的轻松部署、管理和运行;例如通过Mellanox 高速互连技术,可将数千个GPU 连接起来,构建大规模的计算集群。CUDA生态系统复杂,建设难度大,CUDA生态几乎占据通用计算GPU领域的全部市场。
GPU生态体系建立极高的行业壁垒。
GPU一方面有对硬件性能的要求,还需要软件体系进行配套,而GPU软件生态系统复杂,建设周期长、难度大。英伟达CUDA生态从2006年开始建设,经过多年的积累,建立强大的先发优势,英伟达通过与客户进行平台适配、软件开源合作,不断加强客户粘性,GPU行业新进入者转移客户的难度极大,GPU生态体系建立极高的行业壁垒。
2.3、云厂商等大厂自研芯片趋势明显,推动定制ASIC芯片市场高速成长
AI ASIC是一种专为人工智能应用设计的定制集成电路,具有高性能、低功耗、定制化、低成本等特点。
与通用处理器相比,AIASIC针对特定的AI任务和算法进行了优化,如深度学习中的矩阵乘法、卷积等运算,能在短时间内完成大量计算任务,提供高吞吐量和低延迟,满足AI应用对实时性的要求;AIASIC通过优化电路设计和采用先进的工艺技术,在处理AI工作负载时具有较高的能效比,适合大规模数据中心等对能耗敏感的场景;虽然前期研发和设计成本较高,在大规模部署时,ASIC的单位计算成本通常低于通用处理器。

AI ASIC与GPU在AI计算任务中各有优势和劣势。
在算力上,先进GPU比ASIC有明显的优势;ASIC针对特定任务优化,通常能提供更高的计算效率,ASIC在矩阵乘法、卷积运算等特定AI任务上性能可能优于GPU;GPU通用性强,能够运行各种不同类型的算法和模型,ASIC功能固定,难以修改和扩展,灵活性较差;ASIC针对特定任务优化,功耗显著低于GPU;GPU研发和制造成本较高,硬件成本是大规模部署的重要制约因素,ASIC在大规模量产时单位成本相对较低。
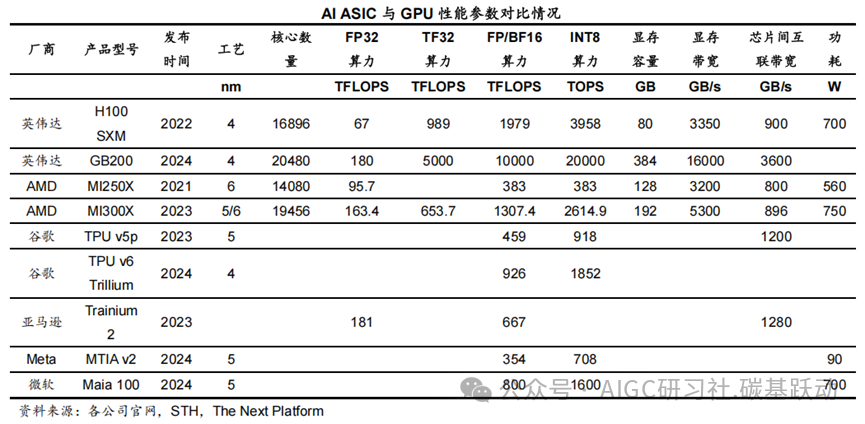
GPU软件生态成熟且丰富,AI ASIC推动软件生态走向多元化。
ASIC的软件生态缺乏通用性,主要是对特定应用场景和算法进行优化;由于ASIC的开发工具和软件库资源相对较少,编程难度比GPU大,开发者在使用ASIC进行开发和调试时所需要花费时间会更多。GPU的软件生态成熟且丰富,如英伟达CUDA和AMD ROCm等,提供了广泛的开发工具、编程语言支持,并拥有大量的开源项目和社区资源。
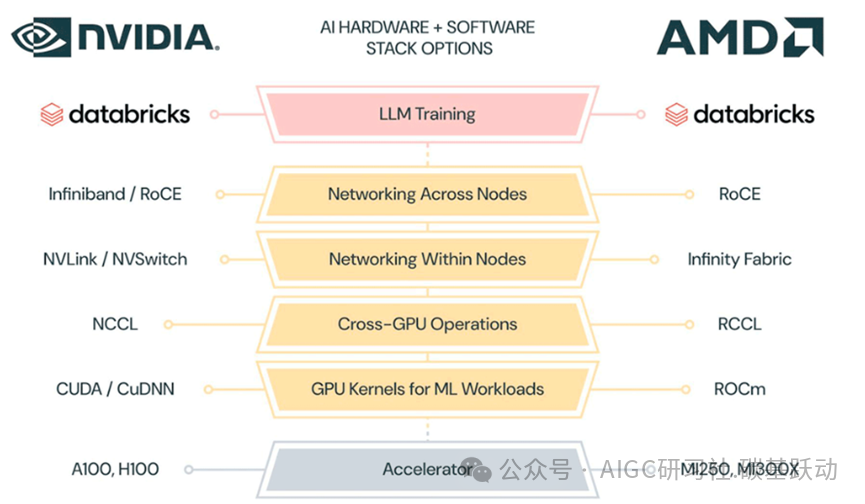
为了提升AI ASIC在特定场景下的计算效率,谷歌、亚马逊、META、微软等厂商为ASIC开发了配套的全栈软件生态,包括编译器、底层中间件等,持续降低从CUDA 生态向其他生态转换的迁移成本,以减轻对CUDA 生态的依赖性。

云厂商等大厂自研芯片趋势明显,推动数据中心定制ASIC芯片市场高速增长。
由于全球头部云厂商、互联网厂商等对AI算力芯片需求量巨大,英伟达垄断全球数据中心GPU市场,因成本、差异化竞争、创新性、供应链多元化等原因,越来越多地大厂开始设计自有品牌的芯片,大厂自研芯片趋势明显;云厂商等大力投入自研AIASIC,推动数据中心定制ASIC芯片市场高速增长,预计增速快于通用AI算力芯片。根据Marvell的数据,2023年数据中心AI算力芯片市场规模约为420亿美元,其中定制ASIC芯片占比16%,市场规模约为66亿美元;预计2028年数据中心定制ASIC芯片市场规模将达到429亿美元,市场份额约为25%,2023-2028年复合增速将达到45%;预计2028年数据中心AI算力芯片市场规模将达约1720亿美元,2023-2028年复合增速约为32%。
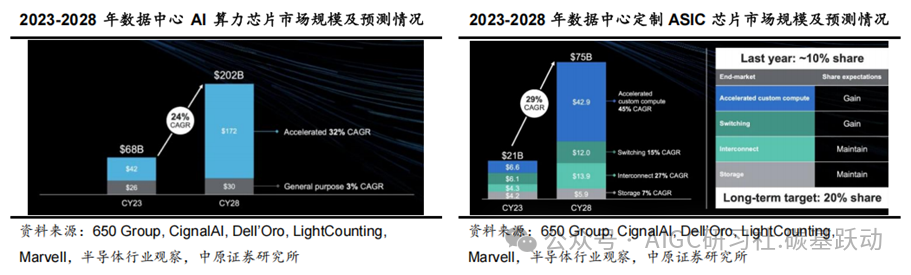
云厂商自研AI ASIC芯片时,通常会与芯片设计厂商合作,然后再由台积电等晶圆代工
厂进行芯片制造,目前全球定制AI ASIC市场竞争格局以博通、Marvell等厂商为主。
博通为全球定制AIASIC市场领导厂商,已经为大客户实现AIASIC大规模量产。博通在多年的发展中已经积累了大量的成体系的高性能计算/互连IP核及相关技术,除了传统的CPU/DSP IP核外,博通还具有交换、互连接口、存储接口等关键IP核;这些成体系的IP核可以帮助博通降低ASIC产品成本和研发周期,以及降低不同IP核联合使用的设计风险,并建立博通强大的竞争优势。博通2024财年AI收入达到120亿美元,公司CEO表示,到2027年,公司在AI 芯片和网络组件的市场规模将达到600亿到900亿美元。
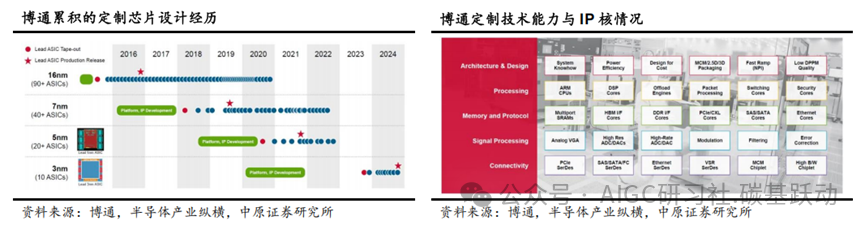
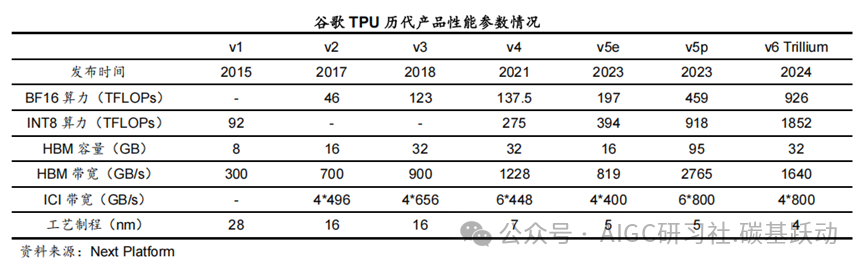
谷歌TPU(Tensor Processing Unit)即张量处理单元,是谷歌专为加速机器学习任务
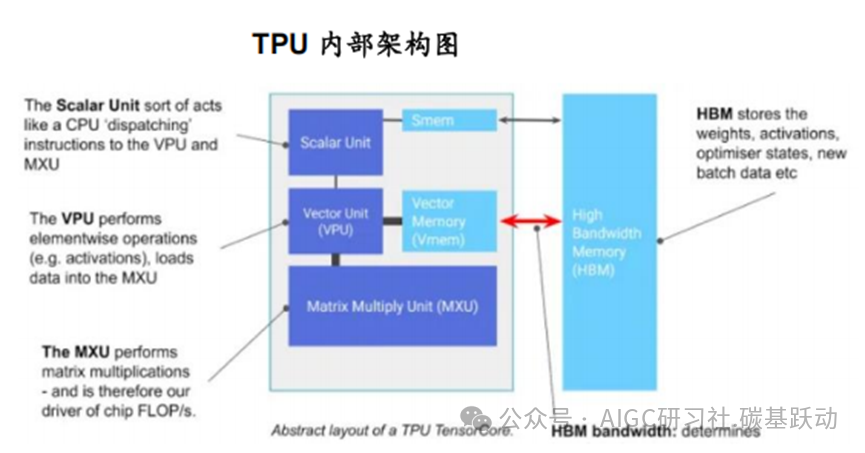
设计的定制ASIC芯片,主要用于深度学习的训练和推理。
TPU 基本上是专门用于矩阵乘法的计算核心,并与高带宽内存(HBM)连接;TPU的基本组件包括矩阵乘法单元(MXU)、矢量单元(VPU)和矢量内存(VMEM);矩阵乘法单元是TensorCore 的核心,矢量处理单元执行一般数学运算,矢量内存是位于TensorCore 中靠近计算单元的片上暂存器;TPU 在进行矩阵乘法方面速度非常快。
目前谷歌TPU已经迭代至第六代产品,每代产品相较于上一代在芯片架构及性能上均有
一定的提升。
2015年谷歌TPU v1推出,主要用于推理任务。2024年谷歌发布第六代产品 TPUv6Trillium,是目前性能最强、能效最高的TPU。TPUv6Trillium与上一代TPU v5e相比,单芯片峰值计算性能提高了4.7倍,HBM容量和带宽均增加一倍,同时芯片间互连带宽也增加一倍;TPUv6Trillium在性能提升的同时,能源效率比上一代提高了67%,显著降低了运营成本;TPUv6Trillium被用于训练谷歌的Gemini 2.0等AI大模型。
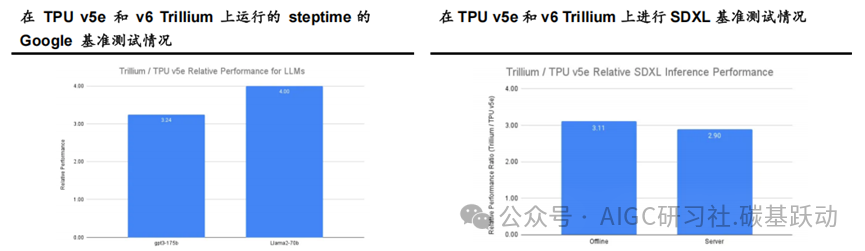
谷歌TPU迭代推动大模型训练与推理效率大幅提升。
Gemini 等AI大模型性能强大且复杂,拥有数十亿个参数,训练如此密集的大模型需要巨大的计算能力以及共同设计的软件优化。与上一代TPU v5e 相比,TPU v6 Trillium 为Llama-2-70b 和gpt3-175b等大模型提供了高达4 倍的训练速度。TPU v6 Trillium 为推理工作负载提供了重大改进,为图像扩散和大模型提供了最好的TPU 推理性能,从而实现了更快、更高效的AI 模型部署;与TPU v5e 相比,TPU v6 Trillium 的Stable Diffusion XL离线推理相对吞吐量(每秒图像数)高出3.1 倍,服务器推理相对吞吐量高出2.9 倍。
谷歌已建立100000TPU芯片算力集群。
TPU芯片通过ICI 连接成算力集群,TPU 网络可以连接16x16x16TPU v4 和16x20x28TPU v5p。为了满足日益增长的AI计算需求,谷歌已将超过100000 个TPU v6 Trillium芯片连接到一个网络结构中,构建了世界上最强大的AI 超级计算机之一;该系统将超过100000 个TPU v6 Trillium芯片与每秒13 PB 带宽的Jupiter网络结构相结合,使单个分布式训练作业能够扩展到数十万个加速器上。这种大规模芯片集群可以提供强大的计算能力,实现高效的并行计算,从而加速大模型的训练过程,提高人工智能系统的性能和效率。

2.4、美国不断加大对高端AI算力芯片出口管制,国产厂商迎来黄金发展期
美国对高端GPU供应限制不断趋严,国产AI算力芯片厂商迎来黄金发展期。
美国商务部在2022、2023、2025年连续对高端AI算力芯片进行出口管制,不断加大英伟达及AMD 高端GPU芯片供应限制,国产AI算力芯片厂商迎来黄金发展机遇,但国产厂商华为海思、寒武纪、海光信息、壁仞科技和摩尔线程等进入出口管制“实体清单”,晶圆代工产能供应受限,影响国产AI算力芯片发展速度。
近年美国对AI算力芯片相关制裁政策情况

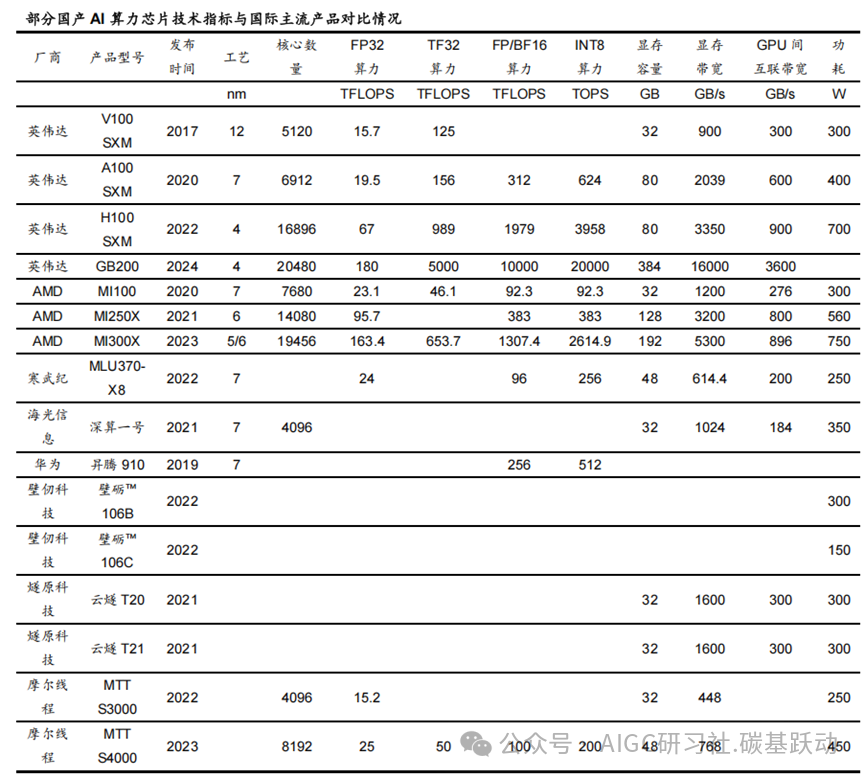
国产AI算力芯片厂商不断追赶海外龙头厂商,但在硬件性能上与全球领先水平仍有一定
的差距。
随着AI应用计算量的不断增加,要实现AI算力的持续大幅增长,既要单卡性能提升,又要多卡组合。从AI算力芯片硬件来看,单个芯片硬件性能及卡间互联性能是评估AI算力芯片产品水平的核心指标。国产厂商在芯片微架构、制程等方面不断追赶海外龙头厂商,产品性能逐步提升,但与全球领先水平仍有1-2代的差距。
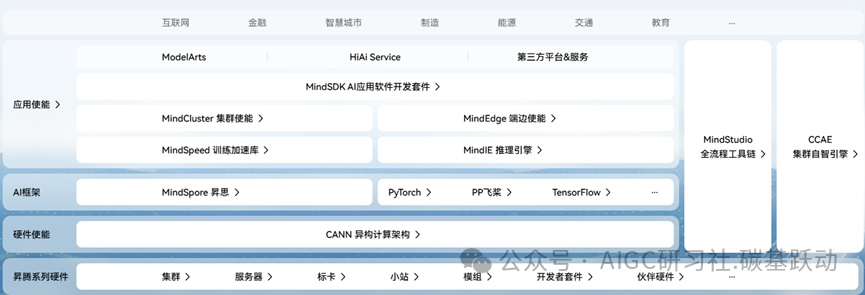
AI算力芯片软件生态壁垒极高,国产领先厂商华为昇腾、寒武纪等未来有望在生态上取
得突破。
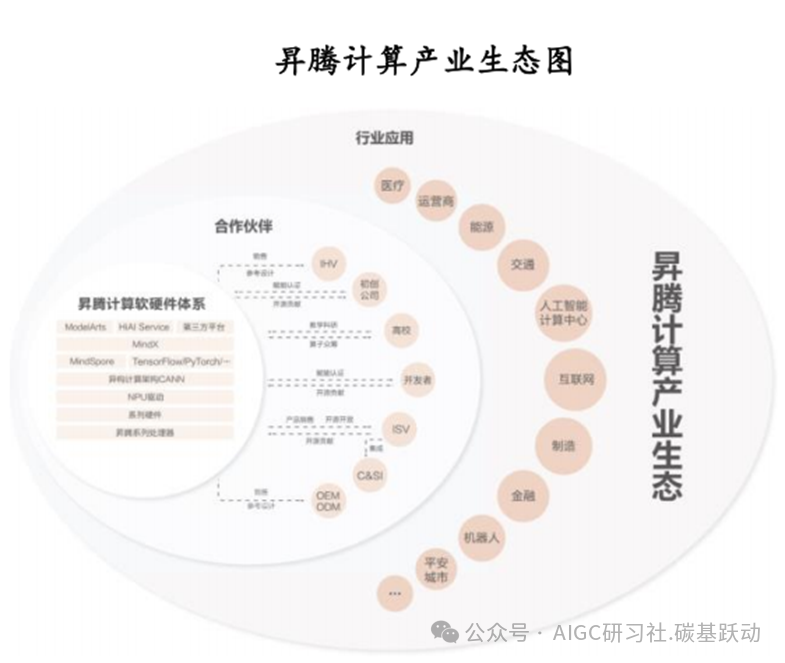
在软件生态方面,英伟达经过十几年的积累,其CUDA生态建立极高的竞争壁垒,国产厂商通过兼容CUDA及自建生态两条路径发展,国内领先厂商华为昇腾、寒武纪等未来有望在生态上取得突破。华为基于昇腾系列AI芯片,通过模组、板卡、小站、服务器、集群等丰富的产品形态,打造面向“端、边、云”的全场景AI基础设施方案。昇腾计算是基于硬件和基础软件构建的全栈AI计算基础设施、行业应用及服务,包括昇腾系列AI芯片、系列硬件、CANN(异构计算架构)、Al计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链。昇腾计算已建立基于昇腾计算技术与产品、各种合作伙伴,为千行百业。
昇腾AI基础软硬件平台
三、国产AI算力芯片发展展望
DeepSeek 通过技术创新实现大模型训练极高的性价比。
2024 年 12 月 26 日,DeepSeek正式发布全新系列模型 DeepSeek-V3,DeepSeek-V3 为自研 MoE模型,总参数量为 671B,每个 token 激活 37B 参数,在 14.8T token 上进行了预训练。DeepSeek-V3在性能上对标 OpenAI GPT-4o 模型,并在成本上优势巨大,实现极高的性价比。DeepSeek-V3的技术创新主要体现在采用混合专家(MoE)架构,动态选择最合适的子模型来处理输入数据,以降低计算量;引入多头潜在注意力机制(MLA)降低内存占用和计算成本,同时保持高性能;采用FP8混合精度训练降低算力资源消耗,同时保持模型性能;采用多Token 预测(MTP)方法提升模型训练和推理的效率。

DeepSeek 有望推动推理需求加速释放,国产 AI 算力芯片或持续提升市场份额。
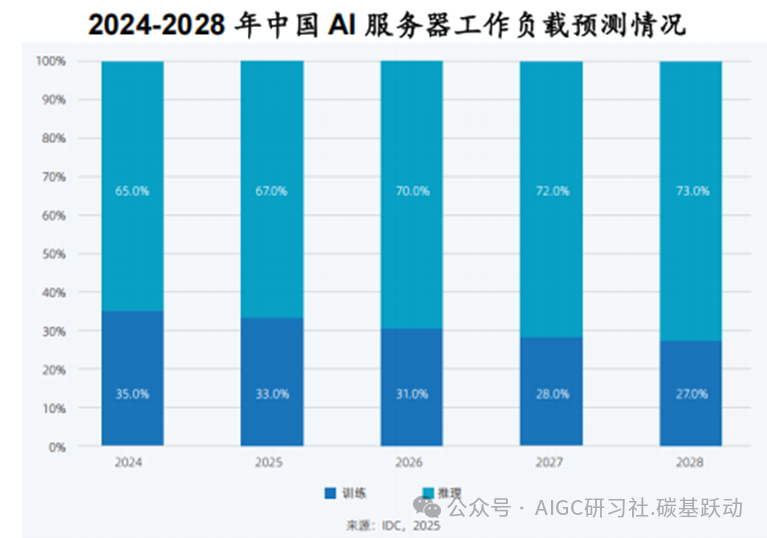
随着大模型的成熟及 AI 应用的不断拓展,推理场景需求日益增加,推理服务器的占比将显著提高;IDC 预计 2028 年中国 AI服务器用于推理工作负载占比将达到 73%。根据的 IDC 数据,2024上半年,中国加速芯片的市场规模达超过 90 万张,国产 AI芯片出货量已接近 20 万张,约占整个市场份额的 20%;用于推理的 AI 芯片占据 61%的市场份额。DeepSeek-R1 通过技术创新实现模型推理极高性价比,蒸馏技术使小模型也具有强大的推理能力及低成本,将助力AI 应用大规模落地,有望推动推理需求加速释放。由于推理服务器占比远高于训练服务器,在AI 算力芯片进口受限的背景下,用于推理的 AI 算力芯片国产替代空间更为广阔,国产 AI 算力芯片有望持续提升市场份额。
国产算力生态链全面适配DeepSeek,国产AI算力芯片厂商有望加速发展。
DeepSeek大模型得到全球众多科技厂商的认可,纷纷对DeepSeek模型进行支持,国内AI算力芯片厂商、CPU厂商、操作系统厂商、AI服务器及一体机厂商、云计算及IDC厂商等国产算力生态链全面适配DeepSeek,有望加速AI应用落地。华为昇腾、沐曦、天数智芯、摩尔线程、海光信息、壁仞科技、寒武纪、云天励飞、燧原科技、昆仑芯等国产AI算力芯片厂商已完成适配DeepSeek,DeepSeek通过技术创新提升AI算力芯片的效率,进而加快国产AI算力芯片自主可控的进程,国产AI算力芯片厂商有望加速发展。

往期推荐
一文解读DeepSeek在保险业的应用_deepseek 保险行业应用-CSDN博客
DeepSeek在金融行业应用_deepseek在金融行业的应用-CSDN博客
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗

















 3948
3948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









