







目录

一、幻觉率
1.1、什么是幻觉率
幻觉率是指大语言模型在回答问题时出现答非所问、胡说八道的现象的比例。具体来说,当大语言模型在回答用户问题时,如果生成的内容与用户问题的实际需求不符,或者生成了错误的信息,这些情况都可以被视为幻觉。
幻觉率的高低直接反映了模型在生成内容时的准确性和可靠性。幻觉率是衡量大语言模型在回答问题时出现错误或不符合实际需求的情况的比例。具体表现为模型在生成内容时可能会编造不存在的信息,或者提供错误的知识点。这种幻觉现象在使用大语言模型时需要特别注意,因为它可能导致用户对信息的误解或错误决策。
1.2、DeepSeek的幻觉率
DeepSeek系列模型在很多方面的表现都很出色,但“幻觉”问题依然是它面临的一大挑战。在Vectara HHEM人工智能幻觉测试(行业权威测试,通过检测语言模型生成内容是否与原始证据一致,从而评估模型的幻觉率,帮助优化和选择模型)中,下面是DeepSeek家族几个模型的分值情况,DeepSeek-R1显示出14.3%的幻觉率。
| 模型 |
幻觉率 |
| deepseek/deepseek-r1 |
14.3 |
| deepseek/deepseek-v3 |
3.9 |
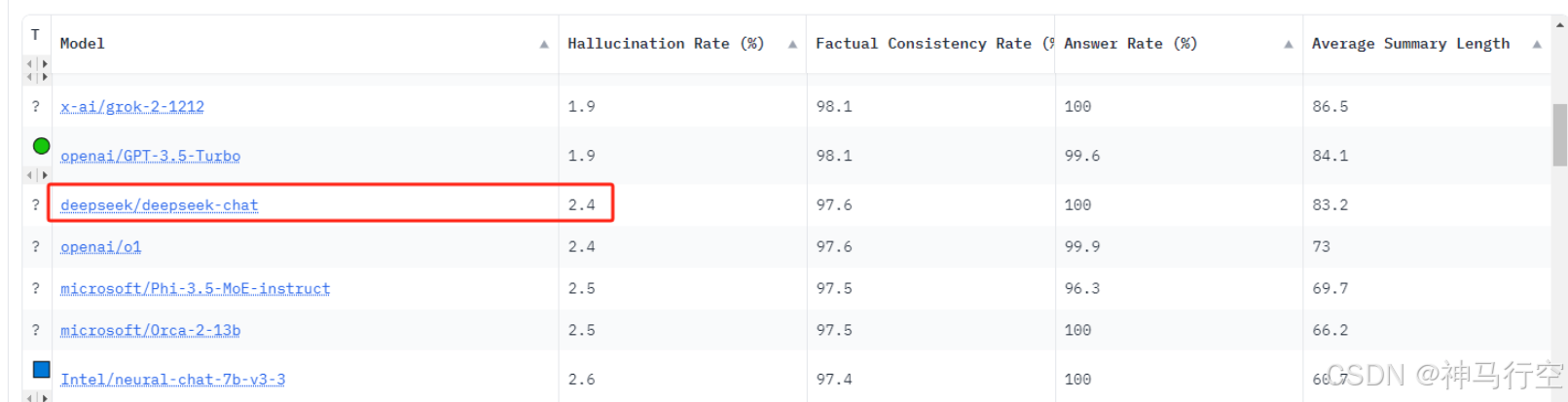
| deepseek/deepseek-chat |
2.4 |
- deepseek/deepseek-r1
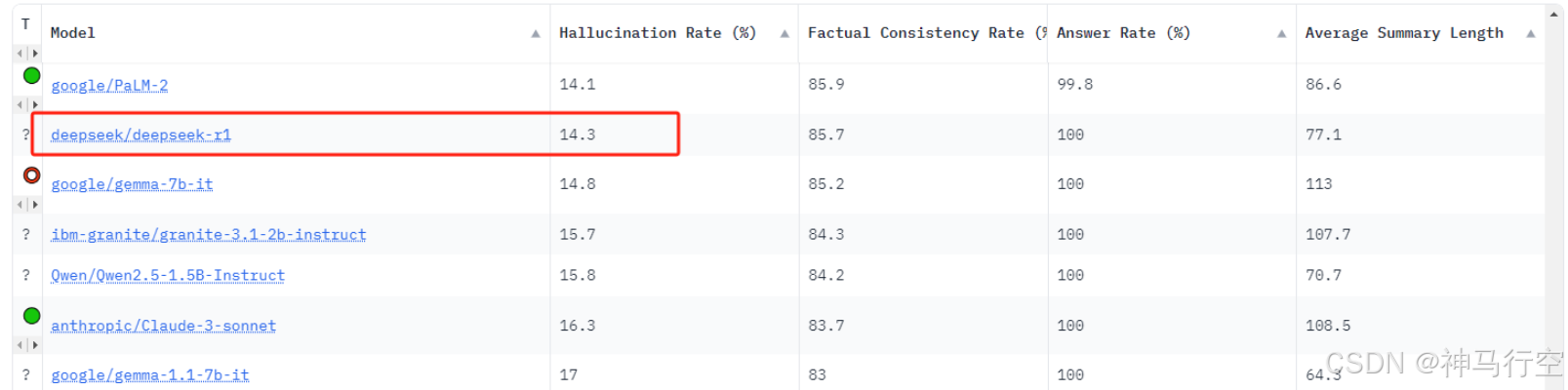
- deepseek/deepseek-v3

- deepseek/deepseek-chat
评测站点:https://huggingface.co/spaces/vectara/leaderboard
下图是DeepSeek在不同基准测试中的情况,DeepSeek-R1的幻觉率不仅是 DeepSeek-V3的近4倍,也远超行业平均水平。这一结果挑战了“模型越聪明,幻觉越少”的传统认知。例如,在需要严格遵循事实的任务(如新闻摘要)中,R1常因过度推理而“添油加醋”,生成原文未提及的内容。这种“创造性编造”反映了模型的核心矛盾——研发团队通过强化“思维链(CoT)”(即让模型像人类一样逐步推理)显著提升了它的数学、代码和文学创作能力,但这一设计也让模型在面对简单任务时“想太多”。例如,用户要求翻译一句话,R1会先脑补上下文、分析潜在意图,再生成结果。这种复杂化处理在文学创作中是优势,但在事实性任务中却导致答案偏离真实,形成“能力越强,编造越多”的悖论。
DeepSeek-R1超高幻觉率解析:为何大模型总“胡说八道”?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5777
5777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









