







 本文在Kaggle数字识别比赛中运用5层CNN,通过数据处理、模型构建、数据增强等手段,实现了0.997的准确率。详细介绍了CNN结构、数据预处理、优化算法与退火策略,以及防止过拟合的数据增强技术。
本文在Kaggle数字识别比赛中运用5层CNN,通过数据处理、模型构建、数据增强等手段,实现了0.997的准确率。详细介绍了CNN结构、数据预处理、优化算法与退火策略,以及防止过拟合的数据增强技术。
Introduction to CNN Keras — Acc 0.997
数字识别-CNN介绍
Kaggle链接:https://www.kaggle.com/yassineghouzam/introduction-to-cnn-keras-0-997-top-6/comments
数字识别是kaggle上关于深度学习的入门比赛,等同与深度学习的hello world程序。
1. 介绍
2. 数据处理
3. CNN模型
4. 模型评价
5. 预测和提交
1.介绍
本文打算在数字识别数据集上训练5层卷积神经网络,并且使用以Tensorflow为后端的Keras API实现。并且在单CPU的情况下训练CNN模型2个半小时达到了99.671%的准确率。由于计算能力的原因,这里设置迭代的次数为2,如果想达到更多的准确率99%+可以将迭代次数设置为30或者更高。
本文主要分为三个部分:
(1)数据处理
(2)CNN模型和评价
(3)预测结果
实现CNN,需要安装如下python包,有关keras包,可以直接在pycharm中安装或者通过pip手动安装(python的环境建议直接安装anaconda3):
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as img
import seaborn as sns
import itertools
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from keras.utils.np_utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D
from keras.optimizers import RMSprop
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ReduceLROnPlateau2.数据处理
2.1 加载数据集
# 2.1 加载数据集 28 * 28 = 784
train = pd.read_csv('/Users/xudong/kaggleData/digit-recognizer/train.csv')
test = pd.read_csv('/Users/xudong/kaggleData/digit-recognizer/test.csv')
print(train.head(5))
# 标签列
Y_train = train['label']
# 丢弃label列
X_train = train.drop(labels=['label'], axis=1)
# 删除train,释放空间
del train
# 画出数据的统计图
sns.set(style='white', context='notebook', palette='deep')
snss = sns.countplot(Y_train)
plt.show()
print(Y_train.value_counts())可以画图显示当前所有类别数字的数量统计(0~9):
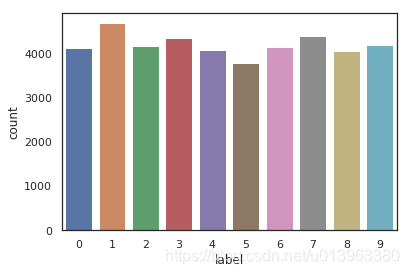
2.2 数据预处理
这个部分主要是对数据进行处理,包括检查缺失数据、数据标准化、数据转化、类别标签的编码和划分数据集。
# 1 检查所有的null或者缺失数据
print(X_train.isnull().any().describe())
# print(test.isnull().any().describe())
# 2 数据标准化 本来就是0-255
# CNN在0-1上收敛要更快
X_train = X_train / 255.0
test = test / 255.0
print(X_train.head(5))
# 3 转换图片数据为三个纬度(长& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6642
6642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









