







 越复杂的神经网络 , 越多的数据 , 我们需要在训练神经网络的过程上花费的时间也就越多. 原因很简单, 就是因为计算量太大了. 可是往往有时候为了解决复杂的问题, 复杂的结构和大数据又是不能避免的, 所以我们需要寻找一些方法, 让神经网络聪明起来, 快起来.这里我们将介绍四种方法加速梯度下降的执行效果。1、Stochastic Gradient Descent (SGD)随机梯度下
越复杂的神经网络 , 越多的数据 , 我们需要在训练神经网络的过程上花费的时间也就越多. 原因很简单, 就是因为计算量太大了. 可是往往有时候为了解决复杂的问题, 复杂的结构和大数据又是不能避免的, 所以我们需要寻找一些方法, 让神经网络聪明起来, 快起来.这里我们将介绍四种方法加速梯度下降的执行效果。1、Stochastic Gradient Descent (SGD)随机梯度下
越复杂的神经网络 , 越多的数据 , 我们需要在训练神经网络的过程上花费的时间也就越多. 原因很简单, 就是因为计算量太大了. 可是往往有时候为了解决复杂的问题, 复杂的结构和大数据又是不能避免的, 所以我们需要寻找一些方法, 让神经网络聪明起来, 快起来.
这里我们将介绍四种方法加速梯度下降的执行效果。
1、Stochastic Gradient Descent (SGD)随机梯度下降
批量梯度下降法(Batch Gradient Descent,简称BGD)是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新,其数学形式如下:
(1) 对上述的能量函数求偏导:
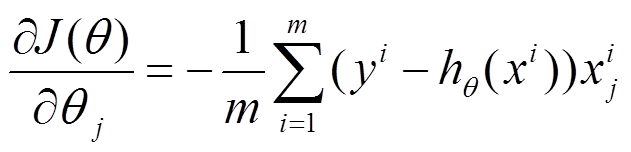
(2) 由于是最小化风险函数,所以按照每个参数  的梯度负方向来更新每个 :
的梯度负方向来更新每个 :
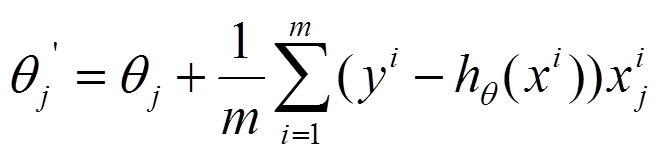
优点:全局最优解;易于并行实现;
缺点:当样本数目很多时,训练过程会很慢。
由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。随机梯度下降法(Stochastic Gradient Descent,简称SGD)正是为了解决批量梯度下降法这一弊端而提出的。
将上面的能量函数写为如下形式:
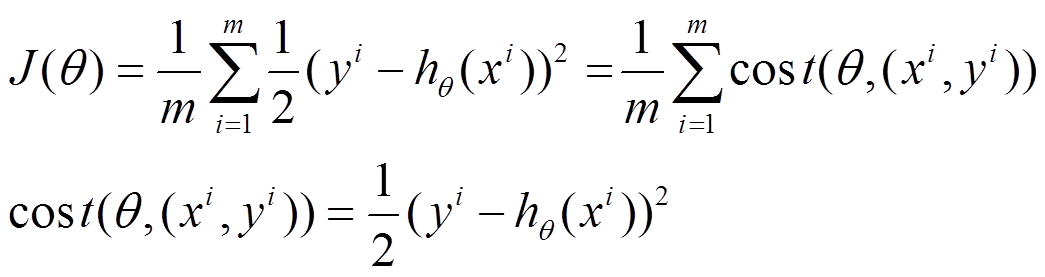
利用每个样本的损失函数对 求偏导得到对应的梯度,来更新 :
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2443
2443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









