







本人不喜欢简单问题复杂化以及晦涩难懂的所谓术语,所以以下基本都为大白话。
1. 混合模型的概念
J为N种概率分布的集合,对于随机变量x,可以用J集合中N种概率分布的线性组合来拟合x的概率分布:
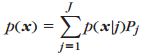 (1)
(1)
其中,Pj为取J中第j个概率分布的概率。所以有:
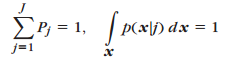 (2)
(2)
现在假设J集合中都为高斯概率分布(当然它们各自的参数并不相同),多维高斯概率分布如下,
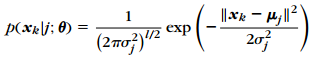
为所有未知参数的缩写。但由于我们并不知各个高斯分布的参数(均值,方差),所以要用某种方法来估计各个参数。
估计模型的参数,自然而然想到最大似然值(ML)和最大后验概率(MAP)。这两者区别在于后者将参数当做随机变量而已。对于现有的情况,高斯分布的参数显然应该当作未知的常量来求解,所以应该选择最大似然值的方法。
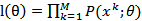
取它的等价形式:
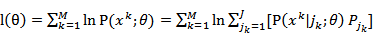
表示对应的概率分布,以后简化为j。
这样我们的目标函数就初步完成,一般的思想是对求导,从未得到其最大值是的值就万事大吉。还是那句熟到烂的老话“理想是丰满的,现实是骨感的”,困难是大大的有的。因为是非凸函数,求导只能得到局部最优。。。但道高一尺,魔高一丈(额。。。),人类也是很狡猾的,非凸函数是吧,那就转化呗。这样就引出高大上的EM(Expectation Maximization)算法。
2. 期望最大(EM)算法
EM算法的基本思路是:在最大化目标函数时,先固定一个变量时整体函数变为凸优化函数,求导得到最值,然后将最值是的参数带回被固定的变量,进入下一个循环。这样就能等到全局最优。
下面我们先复习下高数中的一个定理,为了直观,我用下图说明:
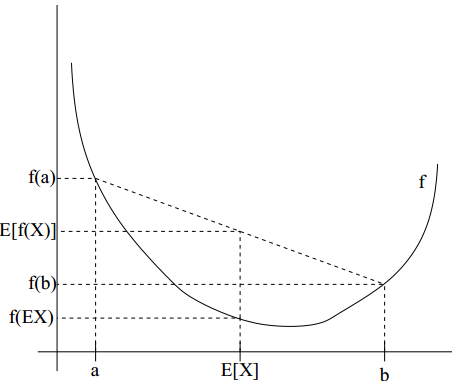
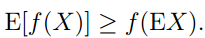
以上不等式相比无任何异议吧。这样回到我们的目标函数
我们引入Q(j)将上式变为:
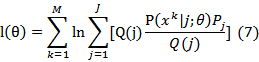
将Q(j)看做概率密度,则上式等价
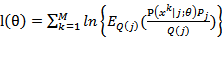
f(x)=lnx是凸函数,就有和(6)式相反的结论
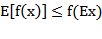
所以(8)式有
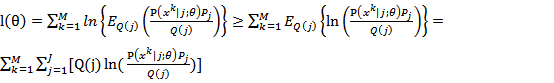
至此,EM算法的精髓粗线,就是我们要不断地迭代寻找的最大下限。然而什么时候取等号?答案是函数的自变量为常数时,即为常数。Q(j)是我们引入的变量,我们并不知道它的数学表达式,不过我们可以联想
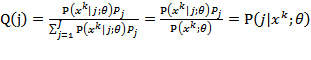
为分子的归一化形式,这样自变量就为常数了。
剩下的就是在t时刻固定Q(j),对各个模型的均值,方差和对应取之概率求导得到(t+1)时刻的未知参数:
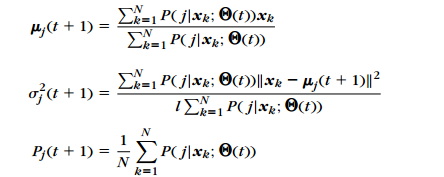
一直迭代知道收敛,即参数不再变化为止。
这样就得到了J中所有高斯分布的具体模型,应用时将样本x分别带入各个高斯模型中,取最大概率的模型最为器最终类别标签。















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









