







RT-1: ROBOTICS TRANSFORMER
摘要
这是一个基于Transformer的机器人网络。可以学习到高数据量的模型。
introduction
端到端机器人学习,近年来,视觉、NLP和其他领域发生了转变,从孤立的、小规模的数据集和模型转向在广泛的、大型数据集上预训练的大型、通用模型。这种模型成功的关键在于开放式的任务不可知训练,结合能够吸收大规模数据集中所有知识的高容量架构。如果一个模型能够“吸取”经验,学习语言或感知方面的一般模式,那么它就能更有效地利用这些经验来完成个别任务。虽然在监督学习中消除对大型特定任务数据集的需求通常很有吸引力,但在机器人技术中更为关键,其中数据集可能需要大量工程自动化操作或昂贵的人工演示。因此,我们要问:我们能否在由各种各样的机器人任务组成的数据上训练一个单一的、有能力的、大型的多任务骨干模型?这样的模型是否享受到在其他领域观察到的好处,表现出对新任务、环境和对象的零概率泛化?
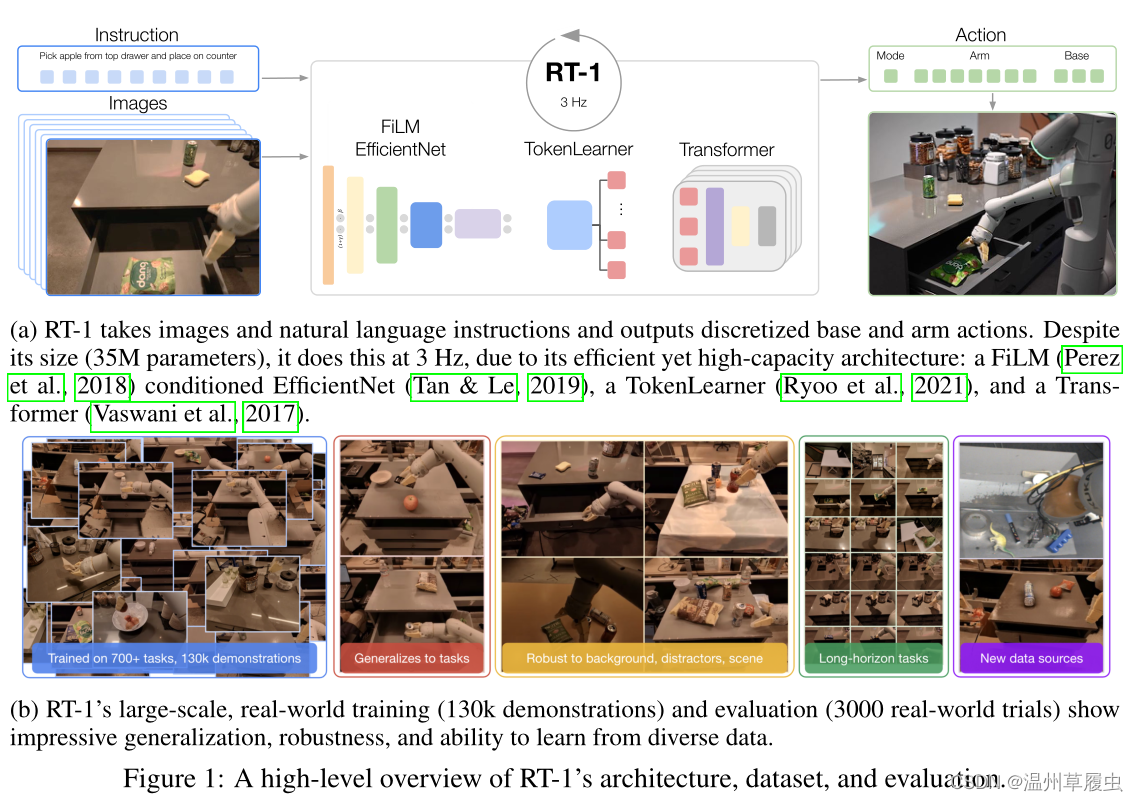 第一个挑战是训练集:这个数据集是我们在17个月的时间里收集的,由13个机器人组成,包含约130k集和700多个任务,我们在评估中删除了这个数据集的各个方面。
第一个挑战是训练集:这个数据集是我们在17个月的时间里收集的,由13个机器人组成,包含约130k集和700多个任务,我们在评估中删除了这个数据集的各个方面。
第二个挑战是模型本身
我们的贡献是RT-1模型,并在现实世界机器人任务的大而广泛的数据集上使用该模型进行实验。我们的实验不仅证明了RT-1与之前的技术相比,可以表现出显著改善的泛化和鲁棒性,而且还评估和消除了模型和训练集组成中的许多设计选择。我们的结果表明,RT-1可以以**97%**的成功率执行700多个训练指令,并且可以泛化到新的任务、干扰因素和背景,分别比下一个最佳基线高出25%、36%和18%。这种性能水平允许我们在SayCan (Ahn et al, 2022)框架中执行非常长期的任务,多达50个阶段。我们进一步表明,RT-1可以整合来自模拟甚至其他机器人类型的数据,保持原始任务的性能,并提高对新场景的泛化能力。
RELATED WORK
叙述了一些机器人端到端深度强化学习模型
PRELIMINARIES
机器人学习:设置了一个动作决策序列,通过动作策略 π \pi π,指令为 i i i,初始图像 x 0 x_0 x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1319
1319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









