







模型测试
既然你已经了解了如何训练医学诊断模型,那么让我们来谈谈如何测试这样的模型。
接下来你会学习如何测试这样的一个模型。您将学习如何正确使用训练、验证和测试集。以及为了评估你的模型需要强大的ground truth。
当我们在做机器学习时,数据集通常将其分成训练集和测试集。
- 训练集: 用于开发和选择模型。在实际应用中,训练集被进一步分割为训练集和验证集。训练集用于学习模型,验证集用于超参数调整。
- 测试集: 用于最终报告我们的结果
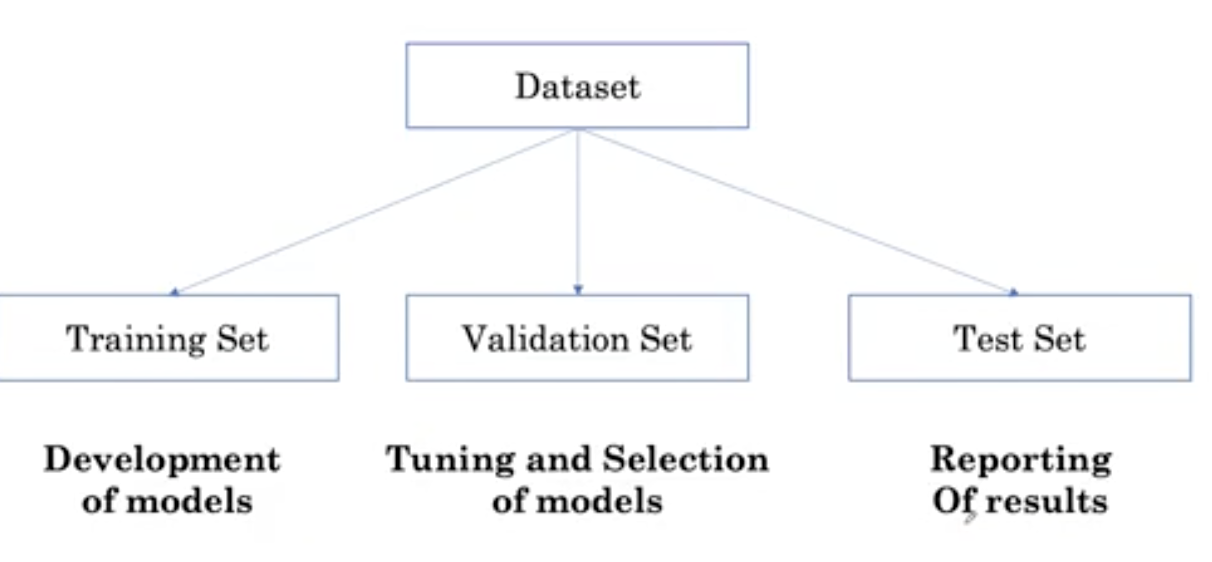
有时,为了减少模型性能估计中的可变性,可以多次使用称为交叉验证的方法将训练集和验证集分开。
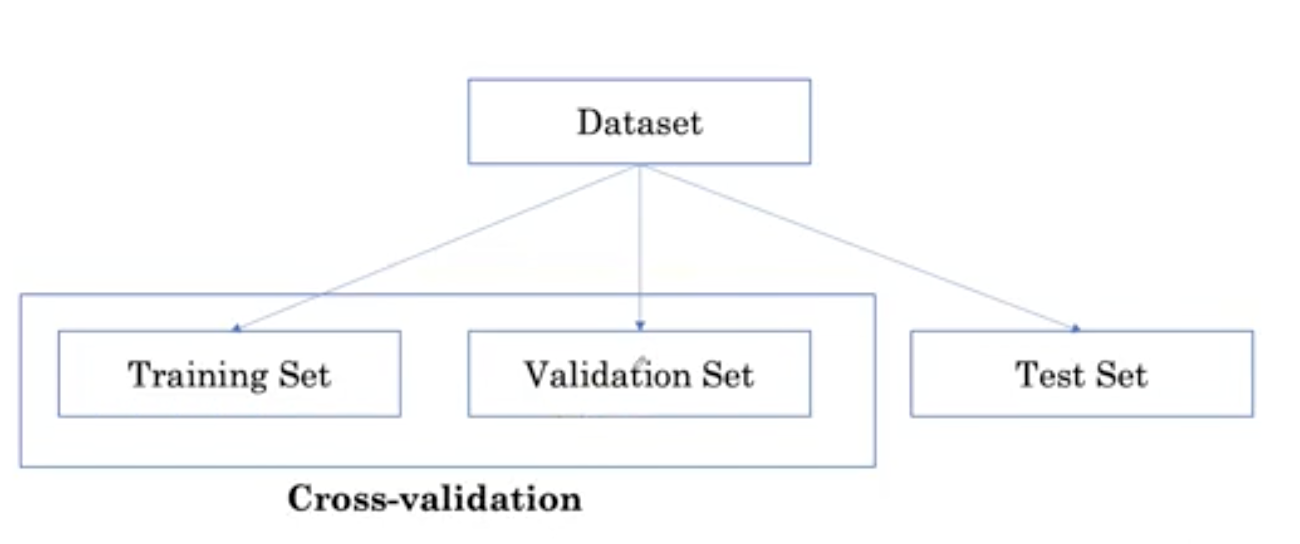
这些集合有时也有不同的名称,比如验证集可以称为调整集或深度集,训练集可以称为开发集,而测试集可以被称为无效集,甚至更容易混淆验证集。
为了我们的目的,我们将坚持训练、验证和测试集等术语。
我们将讨论在医学背景下构建这些数据集的三个挑战。
- 第一个挑战涉及到我们如何使这些测试集独立
- 第二个挑战涉及我们如何对它们进行采样
- 第三个挑战涉及我们如何设置 ground truth
我们先讨论一下病人重叠的问题。假设一个病人来做两次x光检查,一次在六月,一次在十一月。两次,他们在拍x光片时都戴着项链。
他们的一张x光片作为训练集的一部分取样,另一张作为测试的一部分。
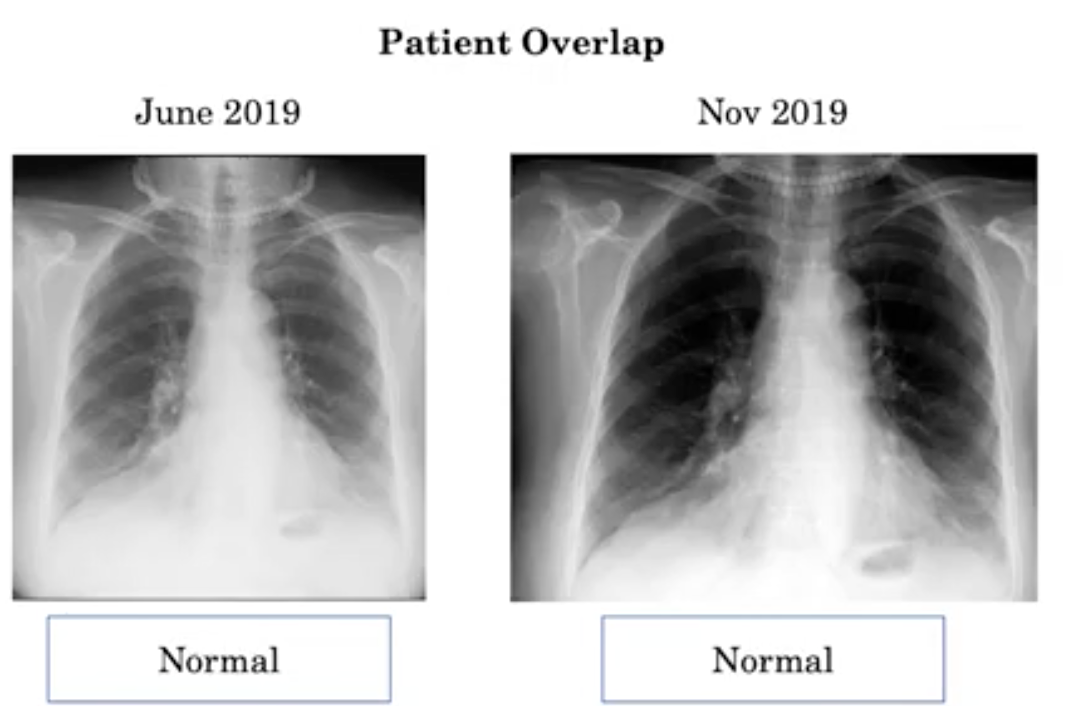
我们训练了我们的深度学习模型,发现它正确地预测了测试集中的x射线:为正常图像。
问题是,当模型看到戴着项链的病人时,它实际上记忆的是脖子上的项链。
这不是假设,深度学习模型可以无意中记忆训练数据,而且模型可以记忆患者罕见或独特的训练数据方面,例如项链。
这可以帮助它在对同一个患者进行测试时获得正确答案。这将导致测试集的性能过于乐观,我们会认为我们的模型比实际的要好。
通过病人构建训练集合测试集
为了在我们的数据集中解决这个问题,我们可以确保患者的X光只出现在其中一个数据集中。
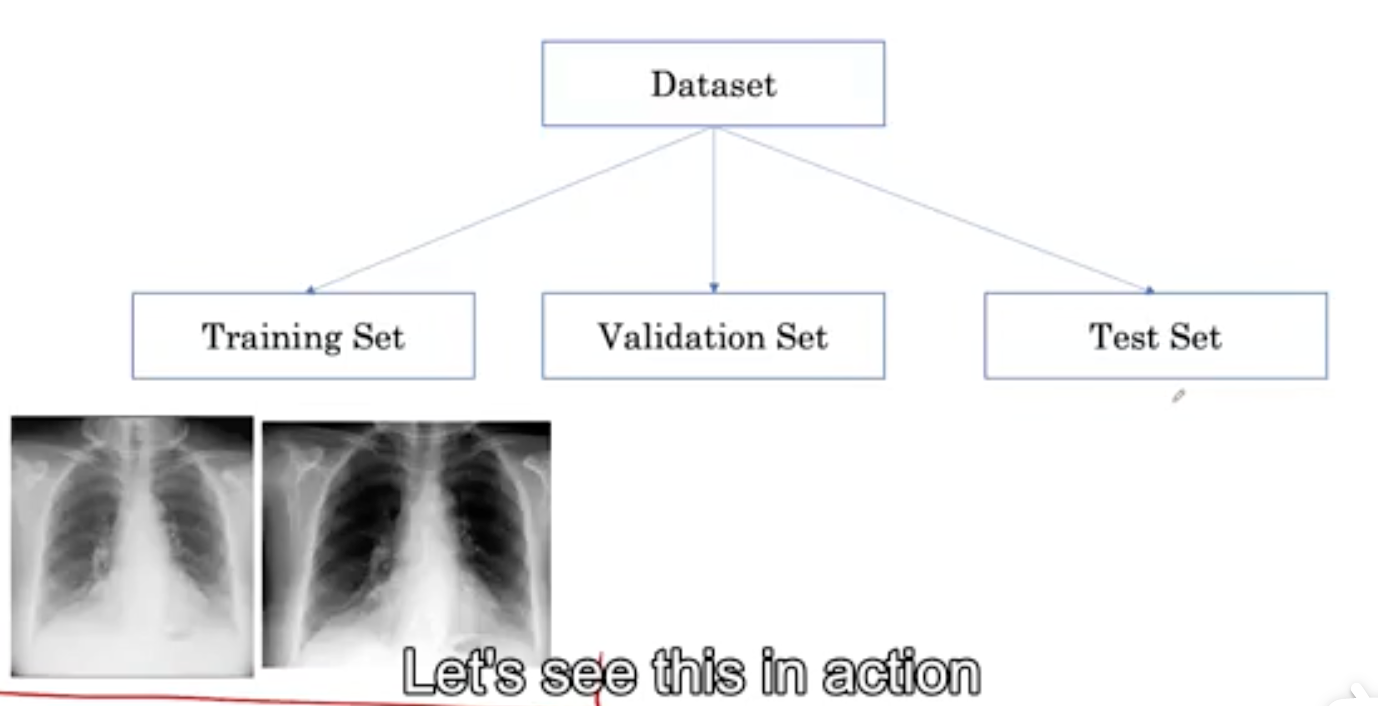
现在,我们把同一个病人的数据都放在训练集中,如果模型记住了病人身上的项链,这并不能帮助它在测试集上获得更高的性能,因为它看不到同一个病人。让我们看看这在所有病人身上的作用。
当我们用传统的方法(按图像分成不同的集合)分割一个数据集时,图像被随机分配到其中一个集合。
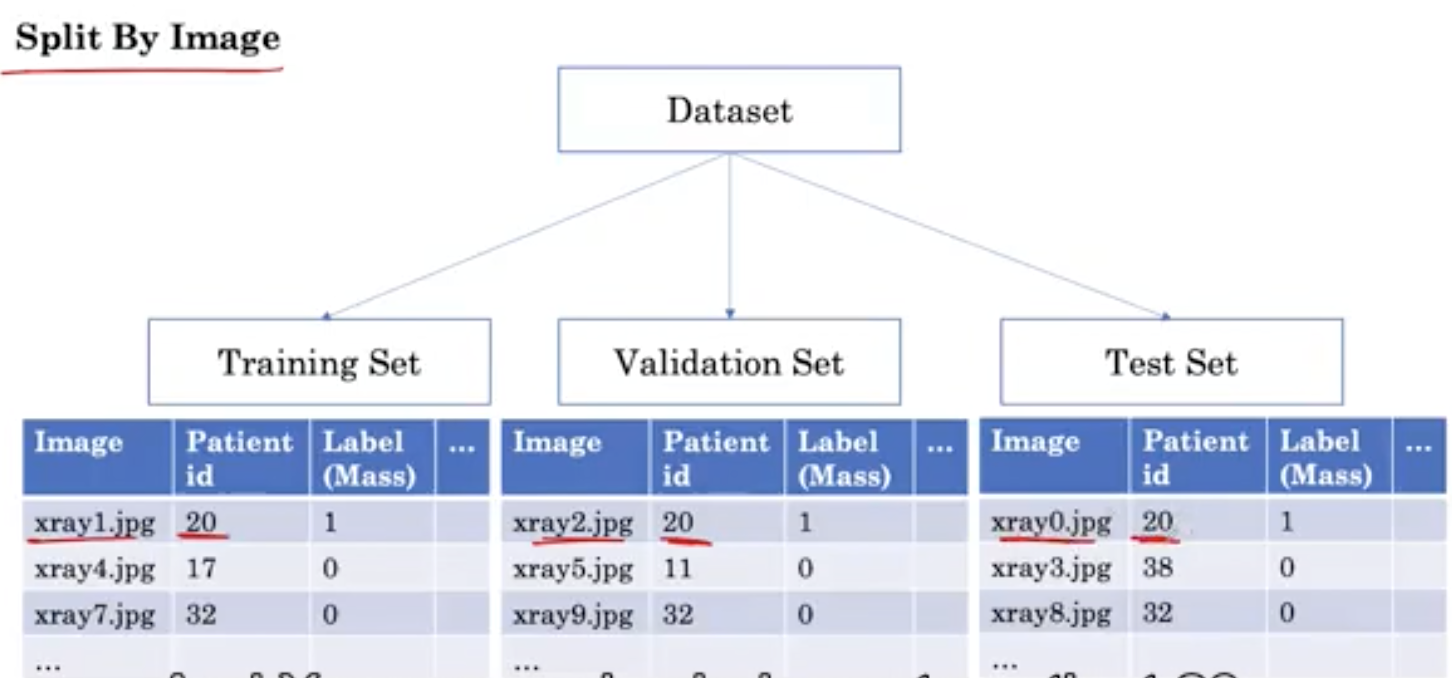
请注意,这样我们就得到了属于同一病人的不同组的X射线。例如,20号病人Xray1.jpg,是训练的一部分。Xray2.jpg也属于20号病人,也是验证的一部分。而Xray0.jpg也属于20号病人,这是测试集的一部分。
这就是病人重叠的问题。相反,当我们按患者分割数据集时,属于同一患者的所有X射线都在同一组中。
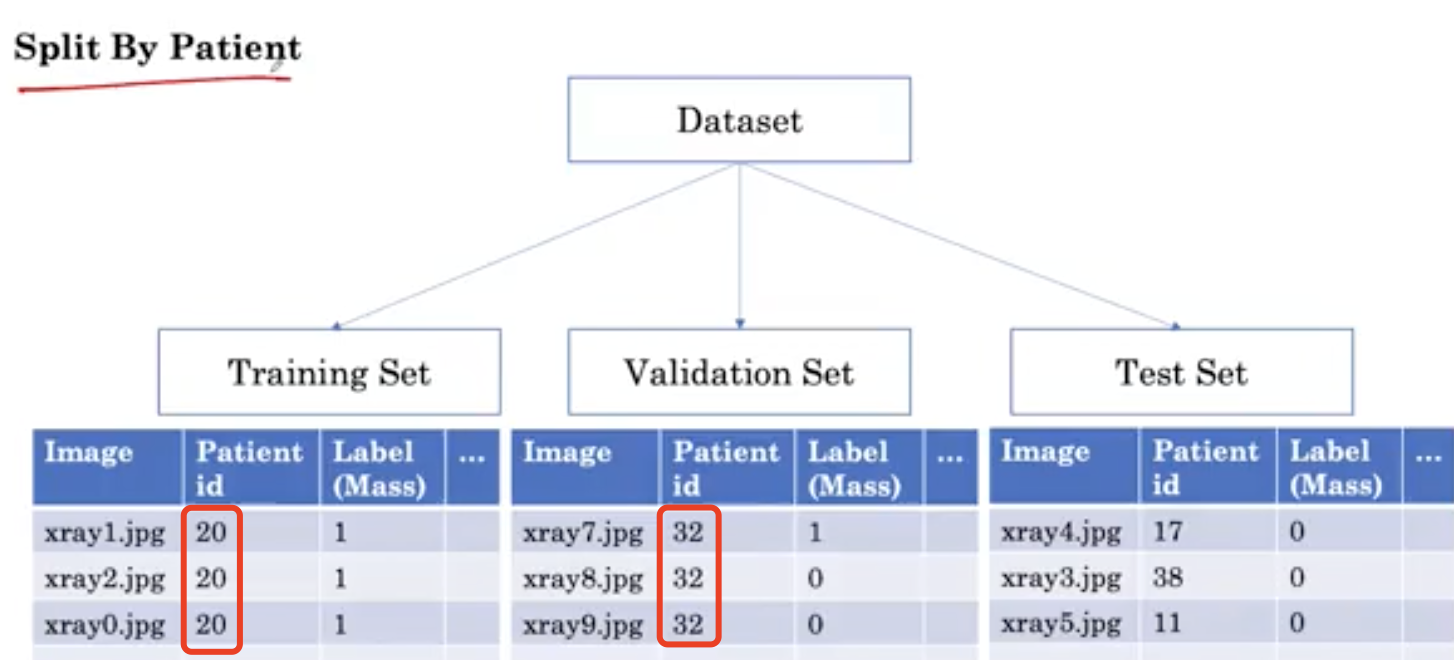
通过以病人来划分数据集,我们就可以确保两组之间没有病人重叠。这涵盖了我们对第一个挑战的解决方案。
作业解读
作业文件:AI4M_C1_W1_lecture_ex_04
了解过chest-xray8这个数据集,就会知道一个病人可能含有多个图像。
医学数据中的病人重叠是机器学习中一个非常普遍的问题,称为数据泄漏(data leakage)。
要确定本周作业中的患者重叠,您不仅需要检查患者ID是否同时出现在训练集和测试集中。
您还应该检查在训练集和验证集中有没有患者重叠,这就是您将要做的。
下面是一个简单的示例,展示了如何检查和删除训练和验证集中的患者重叠。
tips:我给的代码文件里面没有训练集的csv文件,需要请自行下载。
通过‘valid-small.csv’文件,可以查看数据集的构造。
valid_df = pd.read_csv("nih/valid-small.csv")
print(f'There are {valid_df.shape[0]} rows and {valid_df.shape[1]} columns in the validation dataframe')
valid_df.head()

接下来提取 train 和 valid 的 PatientId
# Extract patient id's for the training set
ids_train = train_df.PatientId.values
# Extract patient id's for the validation set
ids_valid = valid_df.PatientId.values
使用 set() 对 ID 排序
ids_train_set = set(ids_train)
print(f'There are {len(ids_train_set)} unique Patient IDs in the training set')
# Create a "set" datastructure of the validation set id's to identify unique id's
ids_valid_set = set(ids_valid)
print(f'There are {len(ids_valid_set)} unique Patient IDs in the validation set')
+ There are 928 unique Patient IDs in the training set
- There are 97 unique Patient IDs in the validation set
set()函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
然后通过求集合的交集来看是否有重叠的病人
# Identify patient overlap by looking at the intersection between the sets
patient_overlap = list(ids_train_set.intersection(ids_valid_set))
n_overlap = len(patient_overlap)
print(f'There are {n_overlap} Patient IDs in both the training and validation sets')
print('')
print(f'These patients are in both the training and validation datasets:')
print(f'{patient_overlap}')
+ There are 11 Patient IDs in both the training and validation sets
- These patients are in both the training and validation datasets:
- [20290, 27618, 9925, 10888, 22764, 19981, 18253, 4461, 28208, 8760, 7482]
由此,我们就求出了训练集和验证集中有多少病人重叠,以及重叠的病人ID。
接下来,我们就要在训练集或验证集中删除它们。我们选择删除验证集,你也可以选择删除训练集。
方法是通过找到重叠的PatientId的那些行索引,然后删除该行。
train_overlap_idxs.extend(train_df.index[train_df['PatientId'] == patient_overlap[idx]].tolist())
valid_overlap_idxs.extend(valid_df.index[valid_df['PatientId'] == patient_overlap[idx]].tolist())
valid_df.drop(valid_overlap_idxs, inplace=True)
Congratulations!
你已经解决了数据集的第一个挑战!
作业解读只介绍了部分重点,更深刻的理解需要自己去做一做作业。
欢迎继续阅读下一次内容~~~
文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连

















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











