







构造 chatbot 的难点:
1. 计算机需要理解你所问的内容
2. 计算机需要对你的问题生成有意义的序列,这需要领域知识、对话上下文、世界知识
背景知识
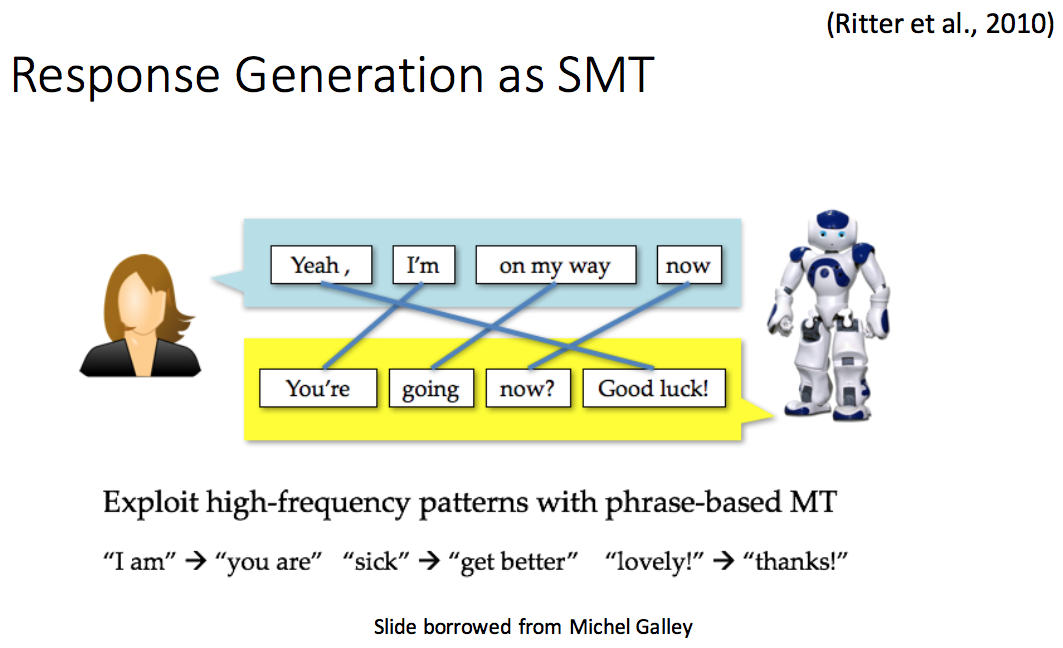
一开始利用 SMT 来生成响应,利用 phrase-base MT 抽取高频模式:
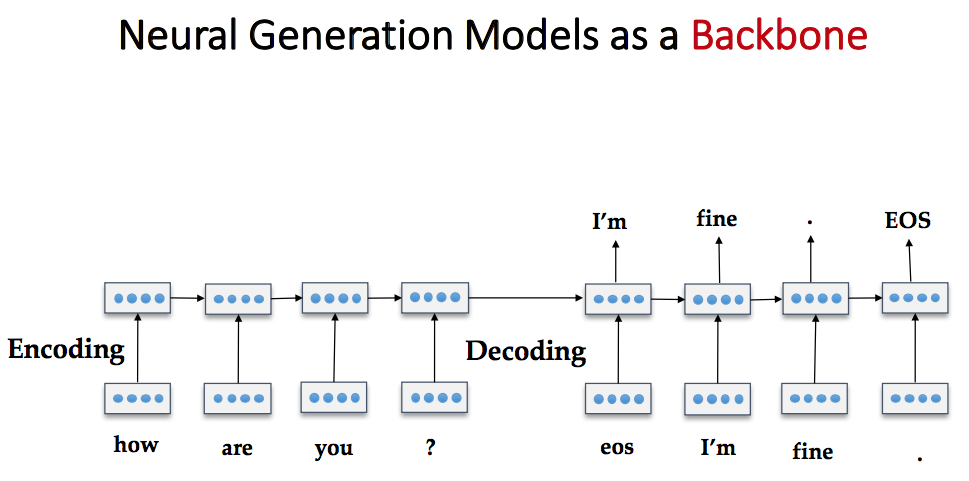
后来用神经网络 encoder-decoder 架构来做:
Mutual Information for Response Generation
一般的 seq2seq 模型总是趋向于生成一些很宽泛的回答,比如“I don’t know”等等,而一些特定的、有意义的回答就排的比较靠后。
解决这一问题的一种方式是增加一些规则,但是效果并不好。所以考虑引入源端和目标端的互信息,利用互信息来减少这些宽泛的响应,从而生成有意义的响应。
A Diversity-Promoting Objective Function for Neural Conversation Models 利用下面的公式作为目标函数
最终在 Twitter 对话数据集上获得了很好的效果。结果示例

Speaker Consistency
目前的模型下,多轮对话中存在响应不一致的问题:同样的问题,换一种问法之后得到了不同的答案,而且答案不一致。

A Persona-Based Neural Conversation Model 针对这个问题,将用户身份(比如背景信息、用户画像,年龄等信息)考虑到模型中,构建出一个个性化的 seq2seq 模型,为不同的用户,以及同一个对不同的对象对话生成不同风格的响应。
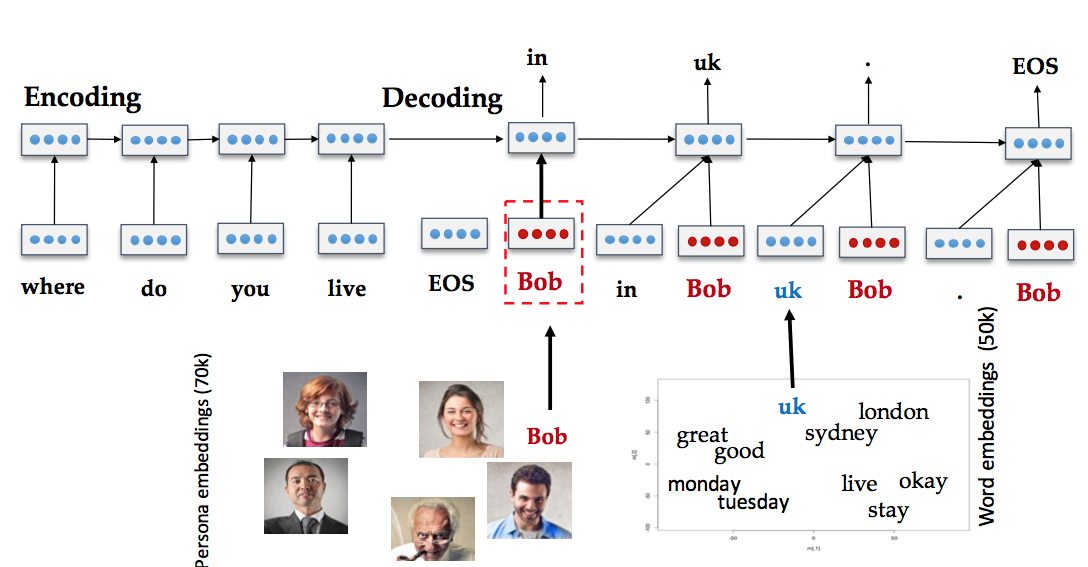
下面给出了结果,User1 采用这篇文章的模型,User2 是普通的 seq2seq 模型,高下立判

Multi-context Response Generation
这主要是要解决多轮对话中利用之前的问题和答案,对新的问题产生答案
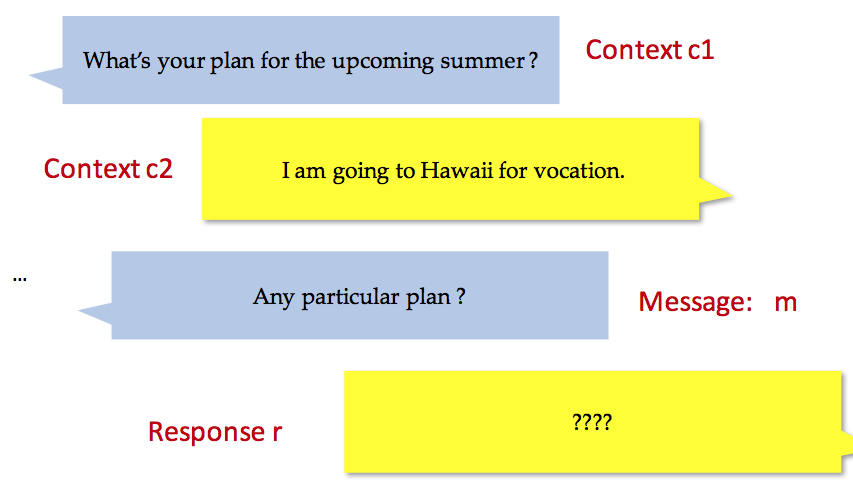
目前最好的方式是 Attention、Memory Networks,平衡多个上文对当前对话的影响
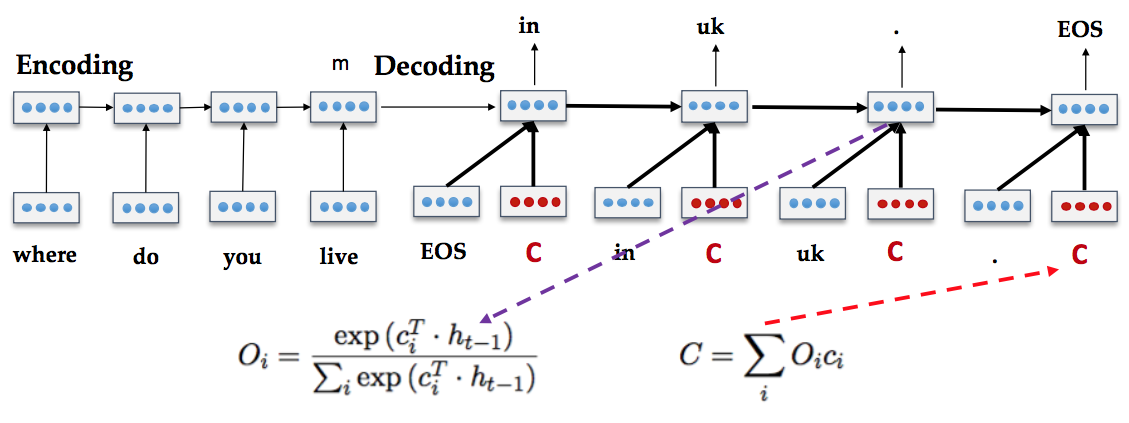
Reinforcement learning for Response Generation
Supervised Learning 针对打好标签的数据能做的不错,但是如果标签在学习时并不明确呢?强化学习就是为解决这类问题而生。它由以下几个部分组成(以围棋 Go 举例):
- 状态集合 S (Go 的当前面板)
- 动作集合 A (在什么位置落子)
- 奖励 Reward(吃掉对手的子或者赢取游戏)
目标是通过最大化全局奖励函数,学习在一个给定状态下采取何种动作。
为什么 RL 能够帮助我们生成对话?
- 一方面,我们可以自己设计真实世界的奖励函数(有趣 VS. 无趣;有信息量 VS. 无信息量)
- 另一方面,我们可以看到这次对话对未来的影响
借助 RL 希望能够将对话持续更久,在多轮后仍然能够产生有意义的响应。
Slide 地址:http://web.stanford.edu/class/cs224u/materials/cs224u-2016-li-chatbots.pdf















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









