







 SSD(Single Shot MultiBox Detector)是一种直接预测边界框坐标和类别的目标检测算法,避免了传统方法的Proposal过程。通过特征融合,SSD在不同大小的特征图上使用默认框检测物体,提高了检测速度和准确性。相比Faster R-CNN和YOLO,SSD在速度和精度上表现出色。算法基于VGG16网络,通过多个卷积层生成不同尺度和比例的默认框,训练时与Ground Truth匹配,预测物体类别和位置。
SSD(Single Shot MultiBox Detector)是一种直接预测边界框坐标和类别的目标检测算法,避免了传统方法的Proposal过程。通过特征融合,SSD在不同大小的特征图上使用默认框检测物体,提高了检测速度和准确性。相比Faster R-CNN和YOLO,SSD在速度和精度上表现出色。算法基于VGG16网络,通过多个卷积层生成不同尺度和比例的默认框,训练时与Ground Truth匹配,预测物体类别和位置。
这篇博客主要介绍SSD算法,该算法是最近一年比较优秀的object detection算法,主要特点在于采用了特征融合。
论文:SSD single shot multibox detector
论文链接:https://arxiv.org/abs/1512.02325
算法概述:
本文提出的SSD算法是一种直接预测bounding box的坐标和类别的object detection算法,没有生成proposal的过程。针对不同大小的物体检测,传统的做法是将图像转换成不同的大小,然后分别处理,最后将结果综合起来,而本文的ssd利用不同卷积层的feature map进行综合也能达到同样的效果。算法的主网络结构是VGG16,将两个全连接层改成卷积层再增加4个卷积层构造网络结构。对其中5个不同的卷积层的输出分别用两个3*3的卷积核进行卷积,一个输出分类用的confidence,每个default box生成21个confidence(这是针对VOC数据集包含20个object类别而言的);一个输出回归用的localization,每个default box生成4个坐标值(x,y,w,h)。另外这5个卷积层还经过priorBox层生成default box(生成的是坐标)。上面所述的5个卷积层中每一层的default box的数量是给定的。最后将前面三个计算结果分别合并然后传递给loss层。
算法的结果:对于300*300的输入,SSD可以在VOC2007 test上有74.3%的mAP,速度是59 FPS(Nvidia Titan X),对于512*512的输入, SSD可以有76.9%的mAP。相比之下Faster RCNN是73.2%的mAP和7FPS,YOLO是63.4%的mAP和45FPS。即便对于分辨率较低的输入也能取得较高的准确率。可见作者并非像传统的做法一样以牺牲准确率的方式来提高检测速度。作者认为自己的算法之所以在速度上有明显的提升,得益于去掉了bounding box proposal以及后续的pixel或feature的resampling步骤。
code地址:https://github.com/weiliu89/caffe/tree/ssd
算法详解:
SSD算法在训练的时候只需要一张输入图像及其每个object的ground truth boxes。
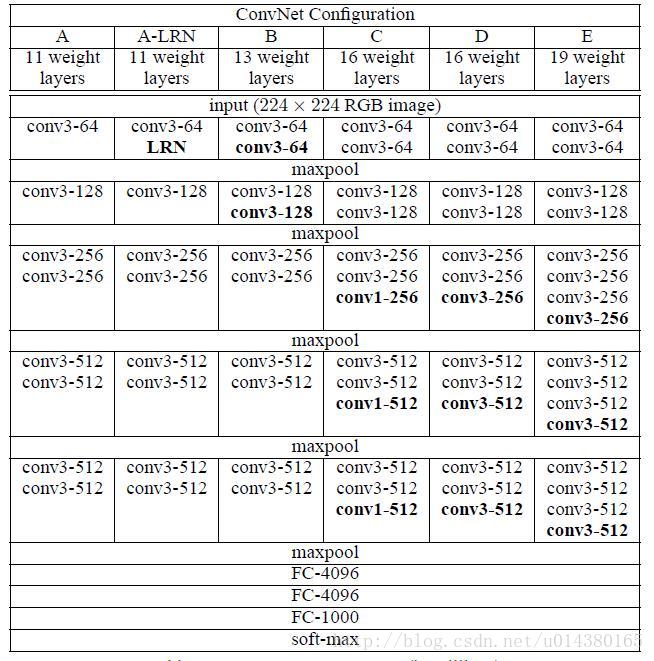
基本的网络结构是基于VGG16,在ImageNet数据集上预训练完以后用两个新的卷积层代替fc6和fc7,另外对pool5也做了一点小改动,还增加了4个卷积层构成本文的网络。VGG的结构如下图所示:
文章的一个核心是作者同时采用lower和upper的feature maps做检测。如下图Fig1,有8*8和4*4两种大小的feature maps,而feature map cell就是其中的每一个小格。另外有一个概念:default box,是指在feature map的每个小格(cell)上都有一系列固定大小的box,如下图有4个(下图中的虚线框,仔细看格子的中间有比格子还小的一个box)。假设每个feature map cell有k个default box,那么对于每个default box都需要预测c个类别score和4个offset,那么如果一个feature map的大小是m*n,也就是有m*n个feature map cell,那么这个feature map就一共有k*m*n个default box,每个default box需要预测4个坐标相关的值和c+1个类别概率(实际code是分别用不同数量的3*3卷积核对该层feature map进行卷积,比如卷积核数量为(c+1)*k对应confidence输出,表示每个default box的confidence,就是类别;卷积核数量为4*k对应localization输出,表示每个default box的坐标)。作者的实验也表明default box的shape数量越多,效果越好。
所以这里用到的defau
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8561
8561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









