








TDAN: Temporally-Deformable Alignment Network for Video Super-Resolution


Abstract
Video super-resolution (VSR) aims to restore a photorealistic high-resolution (HR) video frame from both its corresponding low-resolution (LR) frame (reference frame) and multiple neighboring frames (supporting frames). Due to varying motion of cameras or objects, the reference frame and each support frame are not aligned. Therefore, temporal alignment is a challenging yet important problem for VSR. Previous VSR methods usually utilize optical flow between the reference frame and each supporting frame to warp the supporting frame for temporal alignment. However, both inaccurate flow and the image-level warping strategy will lead to artifacts in the warped supporting frames. To overcome the limitation, we propose a temporally-deformable alignment network (TDAN) to adaptively align the reference frame and each supporting frame at the feature level without computing optical flow. The TDAN uses features from both the reference frame and each supporting frame to dynamically predict offsets of sampling convolution kernels. By using the corresponding kernels, TDAN transforms supporting frames to align with the reference frame. To predict the HR video frame, a reconstruction network taking aligned frames and the reference frame is utilized. Experimental results demonstrate that the TDAN is capable of alleviating occlusions and artifacts for temporal alignment and the TDAN-based VSR model outperforms several recent state-of-the-art VSR networks with a comparable or even much smaller model size. The source code and pre-trained models are released in https://github.com/YapengTian/TDAN-VSR.
第一部分,研究背景介绍:VSR 是做什么(将相应的低分辨率 (LR) 帧 (参考帧) 和多个相邻帧 (支持帧) 恢复为逼真的高分辨率 (HR) 视频帧),其核心难题是什么(时间对齐)。
第二部分,现有方法不足:参考帧和每个支持帧之间的光流使支持帧弯曲以便时间对齐,但由于对齐地不准确,导致产生扭曲的支撑帧。
第三部分,本文方法细节:1. 核心方法:提出了一种时间形变对准网络 (TDAN);2. 方法特点:不计算光流的情况下,在特征水平上自适应地对准参考帧和每个支撑帧;3. 方法细节:使用来自参考帧和每个支持帧的特征来动态预测采样卷积核的偏移量,通过使用相应的核函数,TDAN 对支持帧进行变换,使其与参考帧对齐;为了对 HR 视频帧进行预测,使用了一种以对齐帧和参考帧为基准的重构网络。
第四部分,实验结论:1. 小的模型尺寸;2. 超分效果好;3. 缓解遮挡和伪影。
Method
Overview
设 ![]() 为第 t 个 LR 视频帧,
为第 t 个 LR 视频帧,![]() 为对应的 HR 视频帧,其中 s 为升级因子,HxW 为帧大小,C 为信道数。目标是从参考 LR 帧
为对应的 HR 视频帧,其中 s 为升级因子,HxW 为帧大小,C 为信道数。目标是从参考 LR 帧 ![]() 和支持 LR 帧
和支持 LR 帧 ![]() 复原超分帧
复原超分帧 ![]() 。因此,VSR 框架以连续的 2N + 1 帧
。因此,VSR 框架以连续的 2N + 1 帧 ![]() 作为输入,预测 HR 帧
作为输入,预测 HR 帧 ![]() ,如图 2 所示。它由两个主要的子网络组成:一个是时间变形对齐网络 (TDAN),用于将每个支撑框架与参考框架对齐;一个是超分辨率重构网络 (SR),用于预测 HR 框架。
,如图 2 所示。它由两个主要的子网络组成:一个是时间变形对齐网络 (TDAN),用于将每个支撑框架与参考框架对齐;一个是超分辨率重构网络 (SR),用于预测 HR 框架。
![]()
![]()

Temporally-Deformable Alignment Network
给定一个 LR 支持帧 ![]() 和 LR 参考帧
和 LR 参考帧 ![]() ,TDAN 将会暂时对齐
,TDAN 将会暂时对齐 ![]() 和
和 ![]() 。它主要包括三个模块:特征提取、变形对齐和对齐帧重建。
。它主要包括三个模块:特征提取、变形对齐和对齐帧重建。
- Feature Extraction
该模块通过共享的特征提取网络,分别从 ![]() 和
和 ![]() 中提取视觉特征
中提取视觉特征 ![]() 和
和 ![]() 。该网络由一个卷积层和 k1 个残差块组成,ReLUs为激活函数。采用 了[20] 的一个修改后的残差块结构。提取的特征然后用于特征方向的时间对齐。
。该网络由一个卷积层和 k1 个残差块组成,ReLUs为激活函数。采用 了[20] 的一个修改后的残差块结构。提取的特征然后用于特征方向的时间对齐。
- Deformable Alignment
可变形对准模块以 ![]() 和
和 ![]() 为输入,预测特征
为输入,预测特征 ![]() 的采样参数 θ
的采样参数 θ

其中,![]() 为卷积核的偏移量 R = {(−1, −1),(−1, 0), ...,(0, 1),(1, 1)} 提供了 3×3 内核的常规网格。利用 θ 和
为卷积核的偏移量 R = {(−1, −1),(−1, 0), ...,(0, 1),(1, 1)} 提供了 3×3 内核的常规网格。利用 θ 和 ![]() ,通过可变形卷积计算出支撑架的对齐特征
,通过可变形卷积计算出支撑架的对齐特征 ![]()
![]()
更具体地说,对于对齐特征图 F 上的每个位置 p0,有

在 pn +△pn 的不规则位置上进行卷积,△pn 可以是分数阶的。为了解决这一问题,采用了双线性插值的方法来实现该操作。
这里,可变形对齐模块由几个规则的和可变形的卷积层组成。
对于采样参数生成函数 fθ,它将 ![]() 和
和 ![]() 连接起来,并使用一个 3x3 的瓶颈层来减少连接后的特征映射的通道数。
连接起来,并使用一个 3x3 的瓶颈层来减少连接后的特征映射的通道数。
然后,用一个内核大小为 |R| 的卷积层作为输出通道数来预测采样参数。
最后,通过变换卷积运算,从 θ 和 ![]() 得到了对齐特征
得到了对齐特征 ![]() 。
。
在实践中,除了对齐的可变形卷积外,还在 fdc 前增加了 2 个规则可变形卷积层,在 fdc 后增加了 1 个规则可变形卷积层,以增强模块的转换灵活性和能力。
注意到参考帧 ![]() 的特征仅用于计算偏移量,其信息不会传播到支持帧
的特征仅用于计算偏移量,其信息不会传播到支持帧 ![]() 的对齐特征中。此外,自适应学习的偏移量将隐式捕捉运动线索,并探索在相同的图像结构内的邻近特征进行对齐。
的对齐特征中。此外,自适应学习的偏移量将隐式捕捉运动线索,并探索在相同的图像结构内的邻近特征进行对齐。
- Aligned Frame Reconstruction
尽管可变形对齐具有捕捉运动线索并将 ![]() 和
和 ![]() 对齐的潜力,但在没有监督的情况下,隐式对齐很难学习。因此,为
对齐的潜力,但在没有监督的情况下,隐式对齐很难学习。因此,为 ![]() 恢复一个对齐的 LR 帧
恢复一个对齐的 LR 帧 ![]() ,并利用对齐损失来强制执行可变形对齐模块来采样有用的特征,以实现精确的时间对齐。通过一个 3x3 卷积层,从对齐的特征映射中重构出对齐的 LR 帧
,并利用对齐损失来强制执行可变形对齐模块来采样有用的特征,以实现精确的时间对齐。通过一个 3x3 卷积层,从对齐的特征映射中重构出对齐的 LR 帧 ![]() 。
。
SR Reconstruction Network
使用一个 SR 重构网络来恢复HR视频帧 ![]() 从对齐的 LR 框架和参考框架。该网络包含时间融合、非线性映射和 HR 框架重构三个模块,将来自不同框架的时间信息进行聚合,预测高级视觉特征,并恢复 HR 帧为 LR 参考帧。
从对齐的 LR 框架和参考框架。该网络包含时间融合、非线性映射和 HR 框架重构三个模块,将来自不同框架的时间信息进行聚合,预测高级视觉特征,并恢复 HR 帧为 LR 参考帧。
- Temporal Fusion
为了融合跨时空的不同帧,直接连接 2N + 1 帧,然后将它们送入 3×3 卷积层,输出融合后的特征图。
- Nonlinear Mapping
带有 k2 堆叠残差块的非线性映射模块,将阴影融合特征作为输入来预测深度特征。
- HR Frame Reconstruction
在 LR 空间提取深度特征后,受 EDSR[20] 的启发,利用一个升级层,通过亚像素卷积来增加特征地图的分辨率。在实际操作中,对于 x4 的超分,将使用两个亚像素卷积模块。最终的 HR 视频帧估计 ![]() 将由放大后的 feature map 的卷积层得到。
将由放大后的 feature map 的卷积层得到。
Loss Functions
为了优化 TDAN,利用参考帧作为标签,使对齐的 LR 帧接近参考帧:
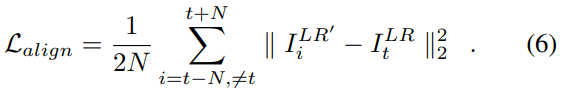
通过 L1 重构损失定义 SR 重构网络的目标函数:
![]()
整体损失函数来训练:
![]()
Analyses of the Proposed TDAN
给定一个参考框架和一组支持框架,所提出的TDAN可以使用时间对齐来将支持框架与参考框架对齐。它有几个优点
- One-Stage Temporal Alignment
已有的算法:
以往的时间对齐方法大多基于光流,将时间对齐问题分为两个子问题:流/运动估计和运动补偿。
本文的方法:
正如本文所讨论的,这些方法的性能高度依赖于流量估计的准确性,而基于流量的图像扭曲会引入伪影。
与这些两阶段时间对齐不同,本文的 TDAN 是一个单阶段的方法,它在特征级别对齐支持帧。它通过自适应的采样参数生成隐式捕捉运动线索,而无需明确估计运动场,并根据对齐的特征重建对齐的帧。
- Self-Supervised Training
已有的算法:
光流估计是两阶段方法的关键。为了保证流量估计的准确性,一些 VSR 网络使用了额外的流估计算法。
本文的方法:
与这些方法不同的是,TDAN 内部没有流量估计,而且它可以在不依赖任何额外监督的情况下以自我监督的方式进行训练。
- Exploration
已有的算法:
对于一帧中的每个位置,光流计算出的运动场仅指向一个潜在位置 p,即扭曲帧中的每个像素只会在 p 处复制一个像素,或者对一个小数位置使用内插值。
本文的方法:
然而,变形对齐模块除了利用 p 的信息外,还可以自适应地在采样位置探索更多的特征,这些特征可能与 p 共享相同的图像结构,有助于聚合更多上下文,从而得到更好的对齐帧重建。















 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









