









Content-Aware Transformer for All-in-one Image Restoration

Image restoration has witnessed significant advancements with the development of deep learning models. Although Transformer architectures have progressed considerably in recent years, challenges remain, particularly the limited receptive field in window-based self-attention. In this work, we propose DSwinIR, a Deformable Sliding window Transformer for Image Restoration. DSwinIR introduces a novel deformable sliding window self-attention that adaptively adjusts receptive fields based on image content, enabling the attention mechanism to focus on important regions and enhance feature extraction aligned with salient features. Additionally, we introduce a central ensemble pattern to reduce the inclusion of irrelevant content within attention windows. In this way, the proposed DSwinIR model integrates the deformable sliding window Transformer and central ensemble pattern to amplify the strengths of both CNNs and Transformers while mitigating their limitations. Extensive experiments on various image restoration tasks demonstrate that DSwinIR achieves state-of-the-art performance. For example, in image deraining, compared to DRSformer on the SPA dataset, DSwinIR achieves a 0.66 dB PSNR improvement. In all-in-one image restoration, compared to PromptIR, DSwinIR achieves over a 0.66 dB and 1.04 dB improvement on three-task and five-task settings, respectively.
图像修复技术随着深度学习模型的发展取得了显著进步。尽管近年来Transformer架构取得了长足发展,但仍存在挑战,特别是基于窗口的自注意力机制中感受野受限的问题。本文提出DSwinIR(可变形滑动窗口Transformer图像修复模型),该模型引入了一种新颖的可变形滑动窗口自注意力机制,能够根据图像内容自适应调整感受野,使注意力机制能够聚焦重要区域并增强与显著特征对齐的特征提取能力。此外,本文还引入了中心集成模式,以减少注意力窗口中无关内容的干扰。通过这种方式,所提出的DSwinIR模型整合了可变形滑动窗口Transformer和中心集成模式,在充分发挥CNN和Transformer各自优势的同时,有效缓解了它们的局限性。在各种图像修复任务上的大量实验表明,DSwinIR实现了最先进的性能表现。例如,在图像去雨任务中,与DRSformer在SPA数据集上的表现相比,DSwinIR实现了0.66 dB的PSNR提升。在全能型图像修复任务中,与PromptIR相比,DSwinIR在三任务和五任务设置下分别实现了超过0.66 dB和1.04 dB的性能提升。
Figure 1. Comparative analysis of feature extraction mechanisms with an anchor token (marked by ⋆) as the reference point. (a) Vanilla convolution applies a fixed sampling pattern, leveraging neighborhood features. (b) Deformable convolution introduces adaptive sampling locations based on content, enabling more effective feature integration from relevant regions. (c) Window attention suffers from boundary constraints where anchor tokens near window edges (especially corners) have limited receptive fields, resulting in suboptimal feature extraction. (d) Our proposed Deformable Sliding Window (DSwin) extends window attention with token-centric paradigm and the content-adaptive reception field, ensuring robust feature aggregation for anchor tokens.
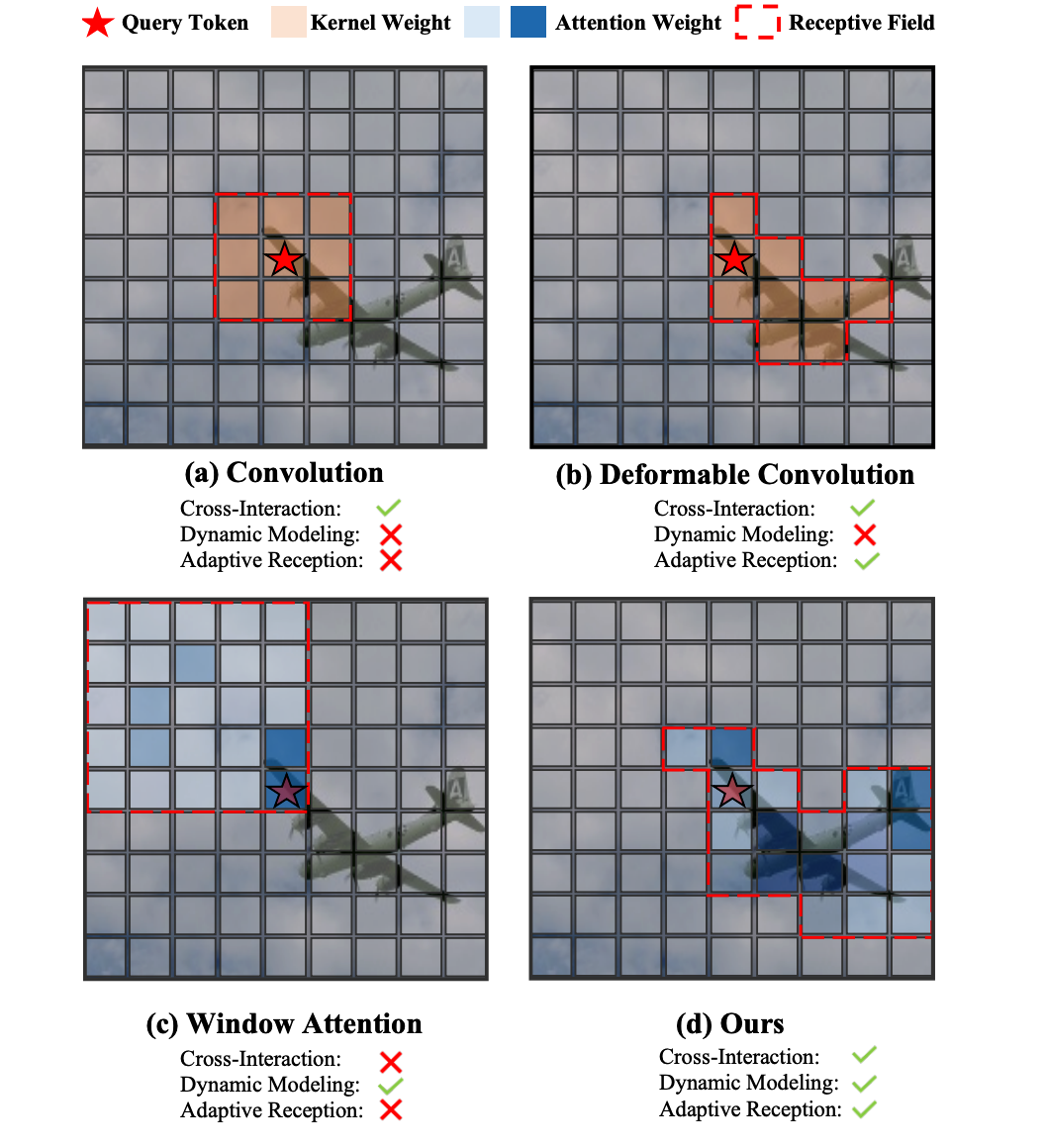
1. Introduction
Image restoration, a fundamental challenge in computer vision, aims to recover high-quality images from degraded observations. Deep learning approaches have revolutionized this field, delivering remarkable progress in specialized tasks such as image deraining, dehazing, and denoising [9, 22, 25]. Recently, the development of unified models capable of addressing multiple degradation types simultaneously has gained significant attention due to their practical value in real-world applications [29].
Transformer-based architectures have become the de facto models for image restoration owing to their dynamic and long-range modeling capabilities [2, 21, 41]. Particularly, Swin Transformer-based methods have achieved widespread adoption in image restoration [37, 51, 57, 59], where its efficient local attention mechanism achieves an exceptional balance between computational cost and restoration quality for dense prediction problems. However, two challenges remain due to the limitations of local window partition: insufficient interaction among different windows and limited receptive field. Subsequent works have attempted to address these challenges by exploiting ingenious window design through cross-aggregation [11, 53], increasing window overlap [10], or employing sparse token selection strategy [8, 71]. While these ingenious window designs have indeed extended the performance of local attention, they are still based on fixed prior patterns, such as stacking horizontal and vertical windows to improve performance. These methods have not completely solved the two challenges brought by window partitioning.
图像修复作为计算机视觉领域的基础性挑战,其核心目标是从质量退化的观测数据中恢复高质量图像。深度学习方法已彻底革新了这一领域,在图像去雨、去雾和去噪等专项任务中取得了突破性进展。近年来,能够同时处理多种退化类型的统一模型因其在实际应用中的重大价值而备受关注。
基于Transformer的架构凭借其动态长程建模能力,已成为图像修复领域的事实标准模型。特别是基于Swin Transformer的方法,其高效的局部注意力机制在密集预测问题中实现了计算成本与修复质量的卓越平衡。然而,由于局部窗口划分的固有局限,仍存在两大挑战:窗口间交互不足与感受野受限。后续研究尝试通过交叉聚合、增加窗口重叠或采用稀疏令牌选择策略等创新窗口设计来解决这些问题。尽管这些精妙的窗口设计确实提升了局部注意力的性能,但它们仍依赖于固定先验模式(如通过堆叠水平和垂直窗口来提升性能),尚未完全克服窗口划分带来的双重挑战。
In this work, we revisit the inductive biases of convolutional operations and introduce a novel Deformable Sliding Window (DSwin) attention mechanism, as illustrated in Fig.1. Inspired by the proven effectiveness of sliding patterns in convolutional neural networks, we transform the conventional window-first paradigm into a token-centric approach. This fundamental shift enables smoother cross-window interaction through overlapping receptive fields.
To further enhance flexibility, we incorporate adaptive window partitioning inspired by deformable convolution[16]. Instead of fixed window regions, our DSwin attention dynamically reorganizes receptive fields based on content-aware offsets learned from center token features, resulting in more effective feature extraction tailored to image content.
Building upon this foundation, we present the Deformable Sliding Window Transformer for Image Restoration (DSwinIR). A key component of our architecture is the Multiscale DSwin module (MSDSwin), which employs DSwin attention with varying kernel sizes across different attention heads to capture rich multiscale features—a crucial capability for effective image restoration.
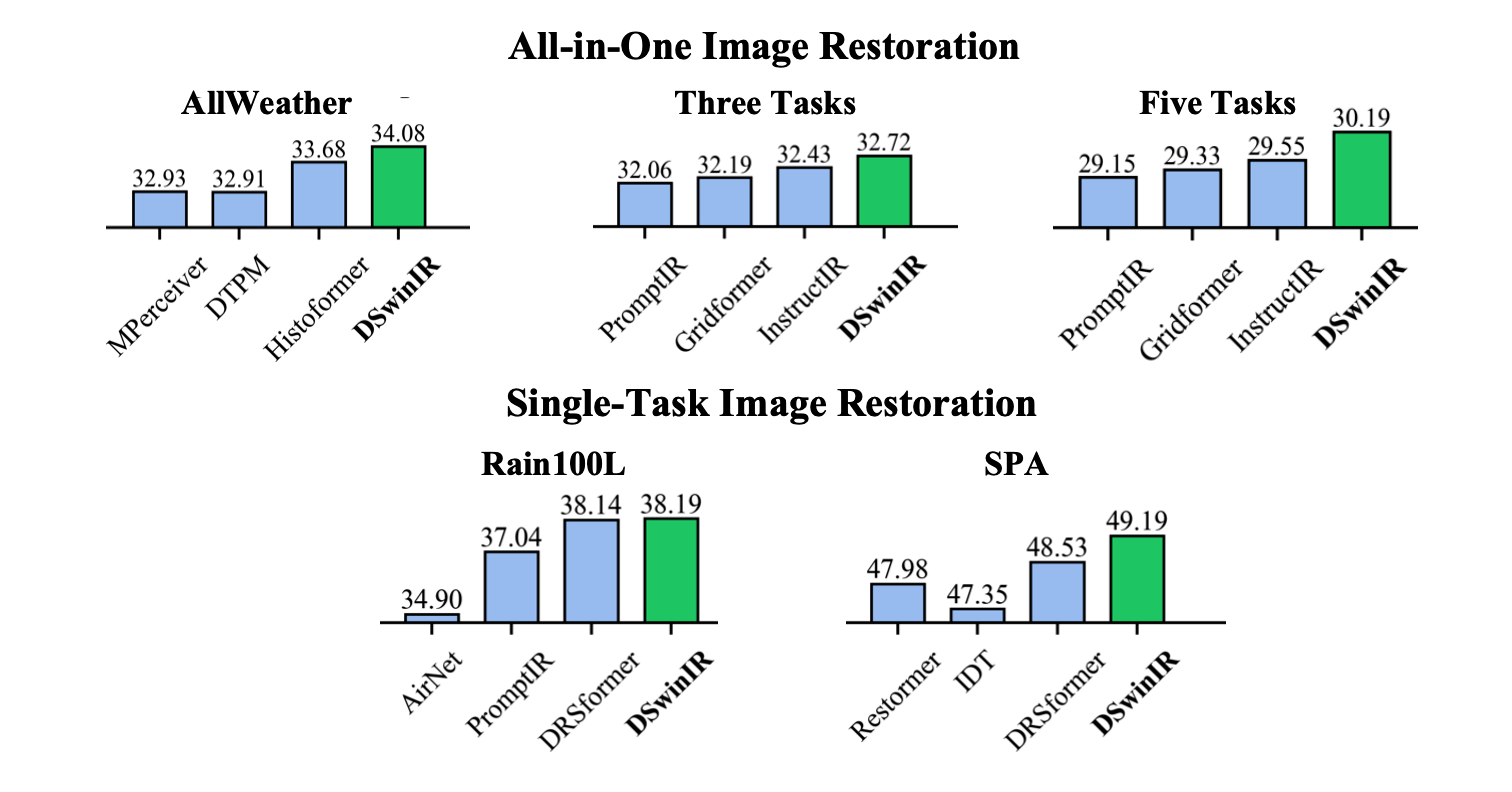
We conduct extensive evaluations across diverse image restoration tasks, spanning both all-in-one multiple degradation scenarios and specialized single-task settings. As demonstrated in Fig.2, DSwinIR delivers substantial improvements of 2.1 dB and 1.3 dB in synthetic and real-world deweathering tasks, respectively. Moreover, our approach establishes new state-of-the-art performance on three-task and five-task degradation benchmarks, outperforming previous methods by approximately 0.7 dB and 0.9 dB. For single-task restoration, DSwinIR surpasses the current leading method DRSformer[8] by 0.62 dB on the challenging real-world deraining SPA dataset [55].
Figure 2. Quantitative comparison of the proposed DSwinIR against existing methods across diverse image restoration tasks, achieving consistent superior performance. All metrics are reported in PSNR (dB).
本研究重新审视了卷积操作的归纳偏置,创新性地提出了可变形滑动窗口(DSwin)注意力机制(如图1所示)。受卷积神经网络中滑动模式已验证的有效性启发,本文将传统的窗口优先范式转变为以令牌为中心的方法。这一根本性转变通过重叠感受野实现了更流畅的跨窗口交互。
为进一步增强灵活性,本文借鉴可变形卷积的思想,引入了自适应窗口划分机制。不同于固定窗口区域,本文的DSwin注意力基于从中心令牌特征学习到的内容感知偏移量,动态重组感受野,从而实现更贴合图像内容的特征提取。
基于此,提出了可变形滑动窗口图像修复Transformer(DSwinIR)。其核心组件是多尺度DSwin模块(MSDSwin),该模块通过在不同注意力头中采用可变卷积核尺寸的DSwin注意力,有效捕获丰富的多尺度特征——这对实现高质量图像修复至关重要。
本文在多样化图像修复任务上进行了全面评估,涵盖一体化多重退化场景和专业化单任务场景。如图2所示,DSwinIR在合成和真实场景的去天气任务中分别取得2.1dB和1.3dB的显著提升。更重要的是,本方法在三任务和五任务退化基准测试中创造了新的性能记录,相较现有方法分别提升约0.7dB和0.9dB。在单任务修复方面,DSwinIR以0.62dB的优势超越当前最优方法DRSformer,这一成果在极具挑战性的真实场景去雨SPA数据集上得到验证。
Our main contributions can be summarized as follows:
• We propose a novel Deformable Sliding Window Attention mechanism that transforms window-based attention into a token-centric paradigm with adaptive, content-aware receptive fields, significantly enhancing feature extraction capabilities and inter-window interaction.
• We develop DSwinIR, a comprehensive image restoration framework built upon our deformable sliding window attention. The architecture incorporates a multiscale attention module that leverages varying kernel sizes across attention heads to capture rich hierarchical features essential for high-quality image restoration.
• Through extensive experiments across multiple image restoration tasks, including both all-in-one settings and specialized single-task scenarios, we demonstrate that DSwinIR consistently outperforms existing methods, establishing new state-of-the-art results on numerous benchmarks.
本研究的主要贡献可总结如下:
• 提出创新的可变形滑动窗口注意力机制,将传统的基于窗口的注意力转化为具有自适应内容感知感受野的以令牌为中心的范式,显著提升了特征提取能力和窗口间交互效率。
• 开发了DSwinIR这一基于可变形滑动窗口注意力的完整图像修复框架。该架构包含多尺度注意力模块,通过在不同注意力头中采用可变卷积核尺寸,有效捕捉对实现高质量图像修复至关重要的多层次丰富特征。
• 在涵盖一体化多任务场景和专业化单任务场景的多种图像修复任务上进行系统实验,证明DSwinIR持续超越现有方法,在多个基准测试中创造了新的性能记录。
2. Method
In this section, we present DSwinIR, a novel architecture for image restoration that introduces the Deformable Sliding Window (DSwin) attention mechanism. We first provide an architectural overview, followed by detailed descriptions of our key components: the DSwin attention module and its multi-scale extension.
本节详细介绍图像修复的新型架构DSwinIR,重点介绍其核心创新——可变形滑动窗口(DSwin)注意力机制。首先给出整体架构概览,随后深入解析两个关键组件:DSwin注意力模块及其多尺度扩展实现。
2.1. Overview
DSwinIR adopts a U-shaped encoder-decoder architecture with our proposed DSwin attention module and MSG-FFN as core components, as shown in Figure 3. The network is optimized using L1 loss between the restored output yˆ and ground truth y:
Figure 3. Overview of the proposed DSwinIR architecture, illustrating the integration of the DSwin module and the MSG-FFN within a U-shaped network. (a) Detail implementation of the proposed DSwin. (b) Illustration of the proposed multi-scale DSwin attention module. (c) The improved FFN with multi-scale feature extraction.
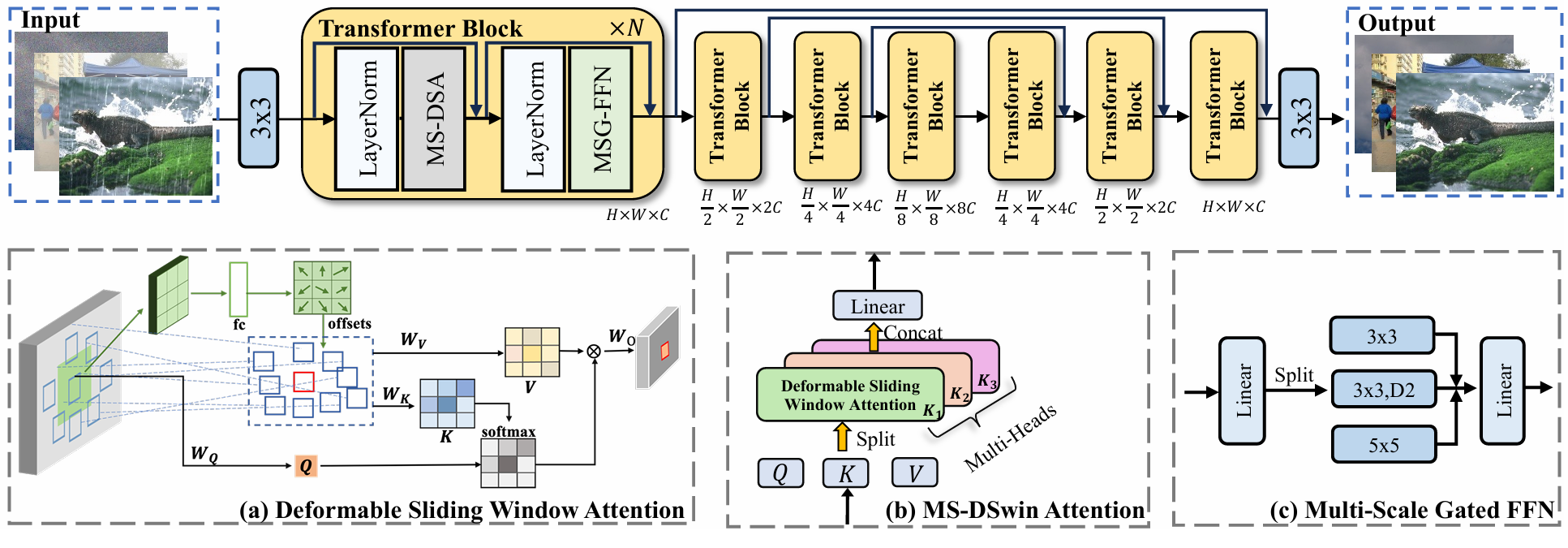
DSwinIR采用U型编解码器架构,其核心组件包括本文提出的DSwin注意力模块和MSG-FFN(如图3所示)。网络通过计算修复输出ŷ与真实值y之间的L1损失进行优化:
![]()
2.2. Deformable Sliding Window Attention Preliminaries
Given an input feature map X ∈ R^(H×W×C), the self-attention is computed by comparing each query feature x_i,j with the features within its receptive field. To incorporate local context, we define the attention weights at position (i, j) as:
where (u, v) ∈ Nk denotes the local neighborhood defined by the kernel size k (such as the window size). The output at position (i, j) is computed as:
This formulation limits the attention computation to a local neighborhood, similar to convolution, making it computationally efficient. Meanwhile, highlighting the crucial role of receptive field.
2.2 可变形滑动窗口注意力基础
给定输入特征图X∈R^(H×W×C),自注意力机制通过比较每个查询特征x_i,j与其感受野内特征的相似度进行计算。为融入局部上下文,定义位置(i,j)处的注意力权重为:
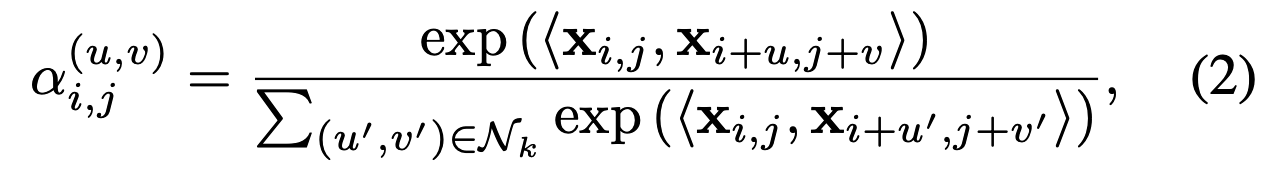
其中(u,v)∈N_k表示由卷积核尺寸k(如窗口尺寸)定义的局部邻域。位置(i,j)的输出特征计算为:
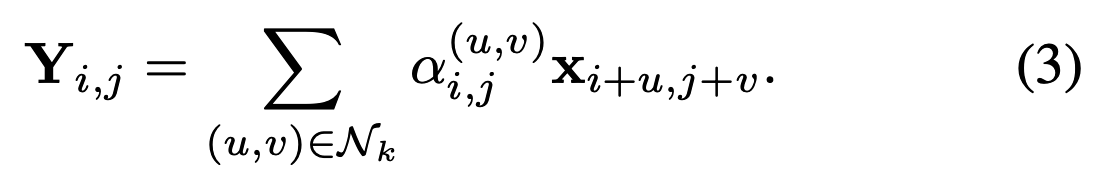
该公式将注意力计算限制在局部邻域内,既保持了与卷积操作相似的计算高效性,又凸显了感受野的关键作用。
Incorporating Deformable Offsets
To adaptively extend the receptive field, we introduce deformable offsets into the attention mechanism. Specifically, we learn offsets ∆p^(u,v)_i,j for each position (i, j) and each location in the local neighborhood (u, v):
where f_θ is a lightweight module that predicts the offsets for the sampling locations.
Leveraging the offsets, we sample the features at deformed positions:
, where ∆u^(u,v)_i,j and ∆v^(u,v)_i,j are the components of ∆p^(u,v)_i,j. The output feature is ensemble with the adaptive selection tokens as:
By introducing deformable offsets, we adaptively adjust the receptive field, allowing the attention to focus on relevant regions beyond the fixed local window regions.
可变形偏移量融合
为实现感受野的自适应扩展,本文在注意力机制中引入可变形偏移量。具体而言,为每个位置(i,j)及其邻域内位置(u,v)学习偏移量Δp_(i,j)^(u,v):
![]()
其中f_θ是预测采样位置偏移量的轻量化模块。
利用这些偏移量,在变形位置处进行特征采样![]() ,其中Δu_(i,j)^(u,v)和Δv_(i,j)^(u,v)是Δp_(i,j)^(u,v)的分量。最终输出特征通过与自适应选择令牌集成得到:
,其中Δu_(i,j)^(u,v)和Δv_(i,j)^(u,v)是Δp_(i,j)^(u,v)的分量。最终输出特征通过与自适应选择令牌集成得到:
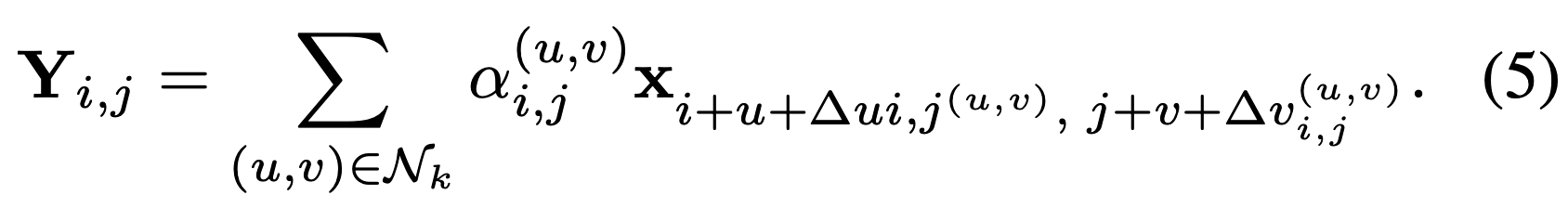
通过引入可变形偏移量,实现了感受野的自适应调整,使注意力能够聚焦于超出固定局部窗口范围的相关区域。
2.3. Multi-Scale DSwin Attention Module
We further extend the basic DSwin attention to a multi-scale variant (MS-DSwin). The key insight is to leverage different receptive fields within a single attention module.
Multi-Scale Design
In MS-DSwin, we assign different kernel sizes to different attention heads within the multi-head attention mechanism. Formally, given H attention heads, each head h ∈ 1, ..., H is associated with a unique kernel size kh. The attention computation for head h can be expressed as:
where N_k_h defines the kernel size k_h for head h, and (∆u^h_i,j , ∆v^h_i,j ) are the learned deformable offsets specific to head h. The outputs from different heads are concatenated through a linear projection:
where W_o ∈ R^C×C is the output projection matrix, and [; ] denotes concatenation.
2.3 多尺度DSwin注意力模块
本文将基础DSwin注意力扩展为多尺度变体(MS-DSwin),其核心思想是在单个注意力模块中利用不同尺度的感受野。
多尺度设计
在MS-DSwin中,本文为多头注意力机制中的每个注意力头分配不同的卷积核尺寸。具体而言,给定H个注意力头,每个头h∈1,...,H对应一个独特的核尺寸k_h。头h的注意力计算可表示为:
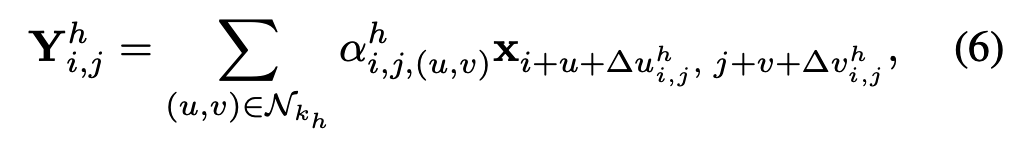
其中N_k_h定义了头h的核尺寸k_h,(Δu^i,j_h, Δv^i,j_h)是头h特有的可学习变形偏移量。不同头的输出通过线性投影进行拼接:
![]()
这里W_o∈R^(C×C)是输出投影矩阵,[;]表示拼接操作。
2.4. Feed-Forward Network
Multi-Scale Guided Feed-Forward Network
To enhance feature processing capabilities, we propose MSG-FFN, a multi-scale guided feed-forward network that extends the FFN design with parallel multi-scale convolution branches. Given an input feature map X, MSG-FFN processes it as follows:
where Conv_k×k denotes convolution with kernel size k, Conv_3 × 3, d = 2 represents dilated convolution with kernel size 3 and dilation rate 2.
2.4 前馈网络
多尺度引导前馈网络
为增强特征处理能力,本文提出MSG-FFN——一种多尺度引导的前馈网络,通过引入并行多尺度卷积分支来扩展标准FFN设计。给定输入特征图X,其处理流程为:
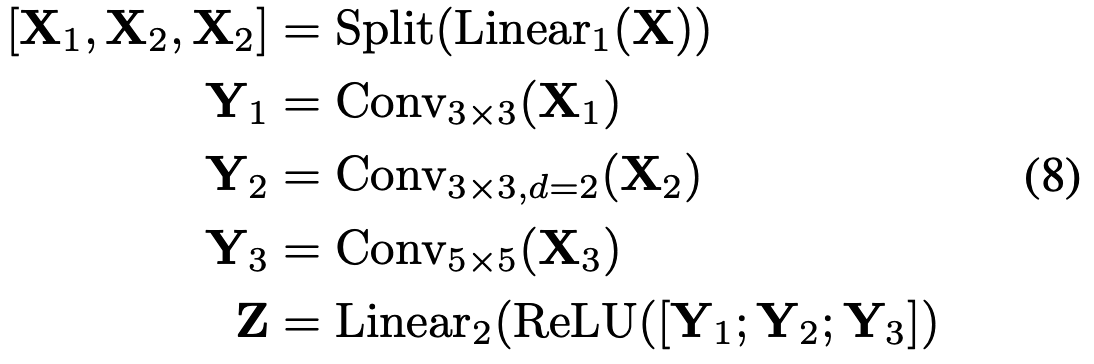
其中Conv_k×k表示核尺寸为k的卷积,Conv_3×3,d=2代表空洞卷积(核尺寸3,空洞率2)。该设计通过多尺度特征融合显著提升了模型对复杂图像退化模式的适应能力。
3 Results
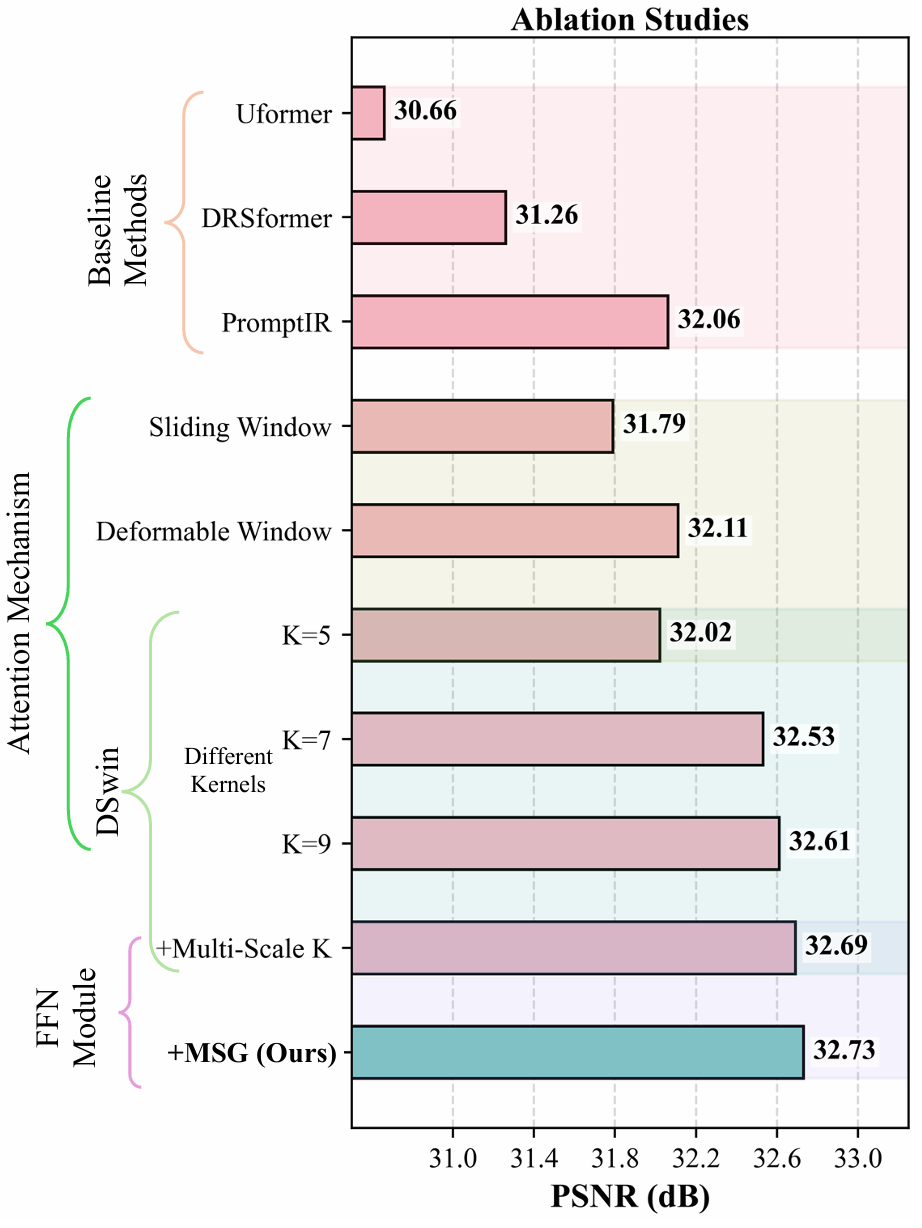
Figure 4. Ablation studies demonstrating the effectiveness of our key components. We evaluate (1) different attention mechanisms, showing improvements from Sliding Window (31.79 dB) and De formable Window (32.11 dB) over baselines; (2) DSwin config urations with various kernel sizes (K=5,7,9) and Multi-scale en hancement (32.69 dB); and (3) FFN module with MSG enhance ment, achieving the best performance (32.73 dB). All experiments report the average performance of three distinct degradation tasks with PSNR values in dB.
Table 1. Comprehensive evaluation of the proposed DSwinIR across diverse experimental settings in existing all-in-one image restoration research.
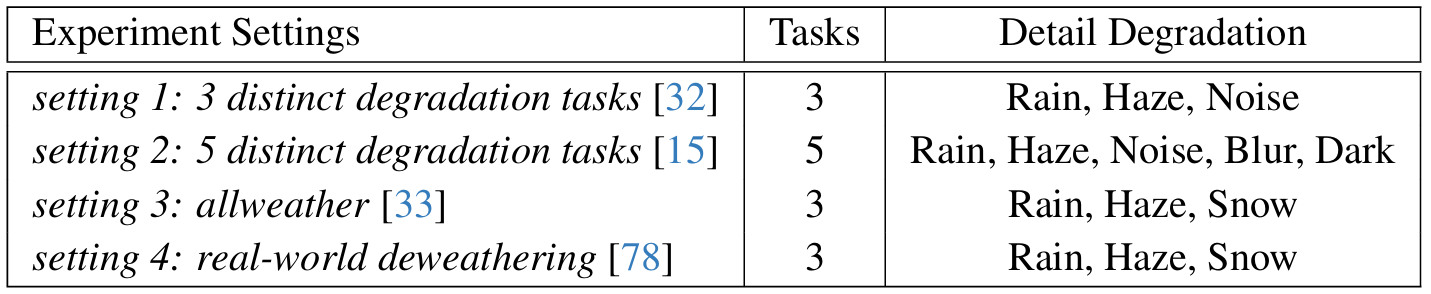

Figure 5. Visual comparison of restoration results across three degradation tasks: noise removal (top row), rain streak removal (middle row), and dehazing (bottom row). Zoom-in regions (shown in colored boxes) demonstrate that our method achieves superior detail preservation and degradation removal.
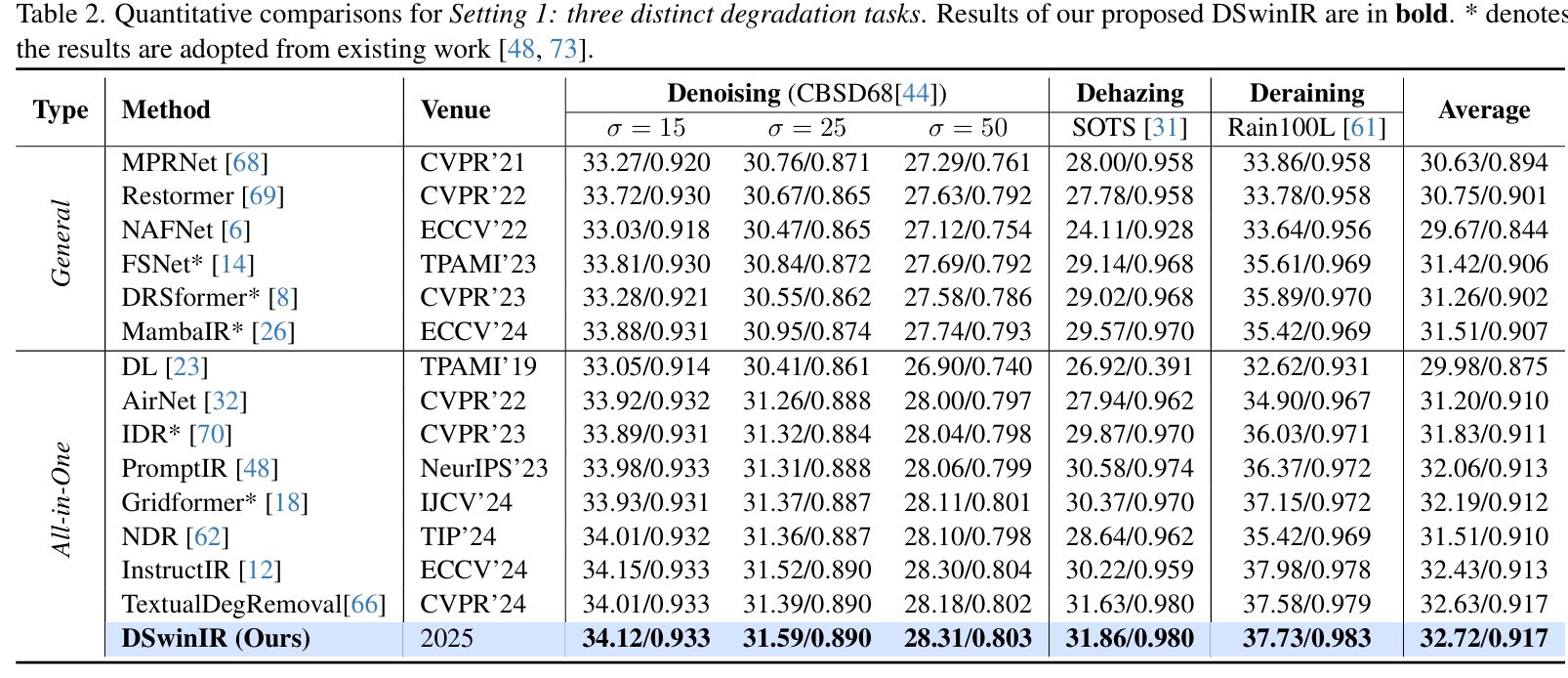
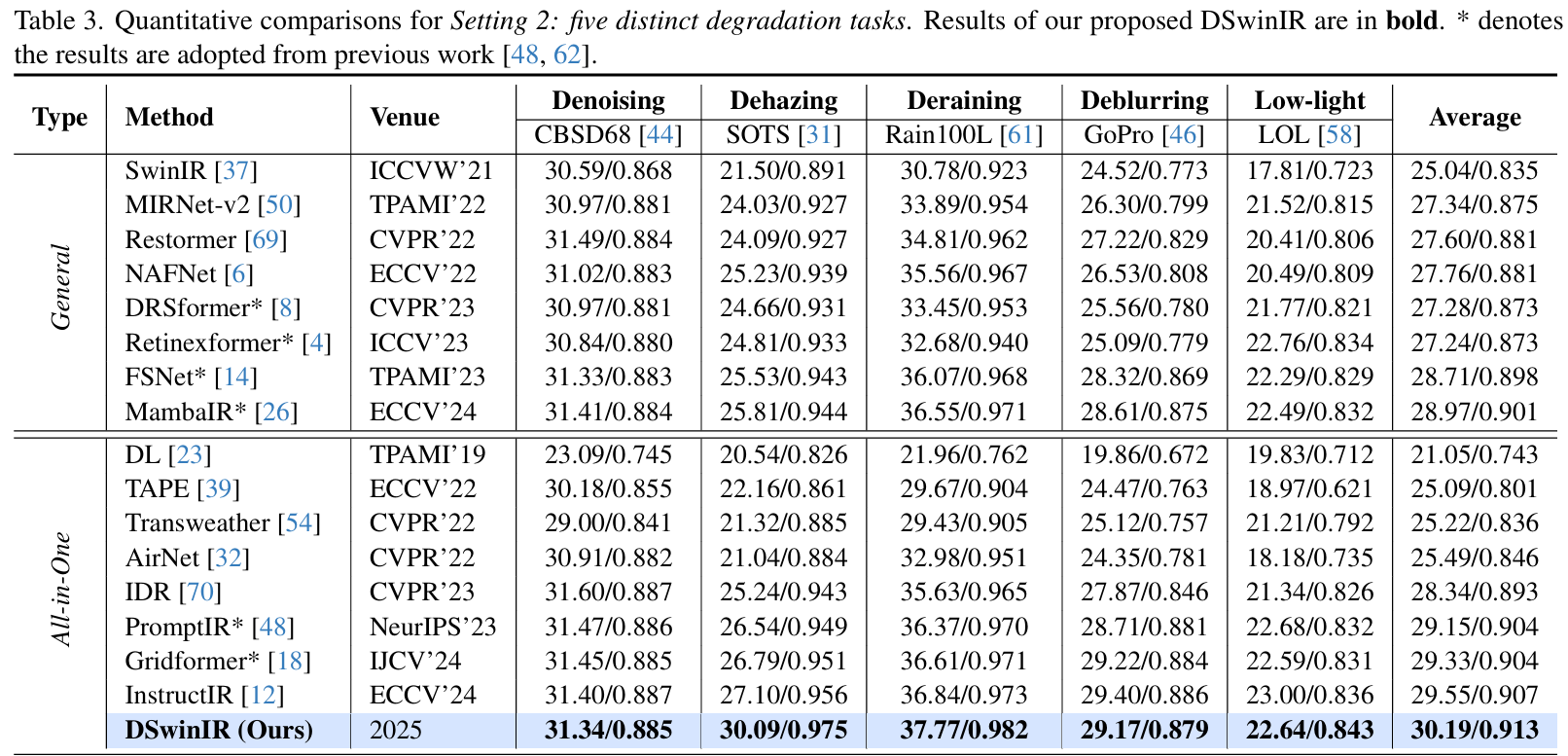

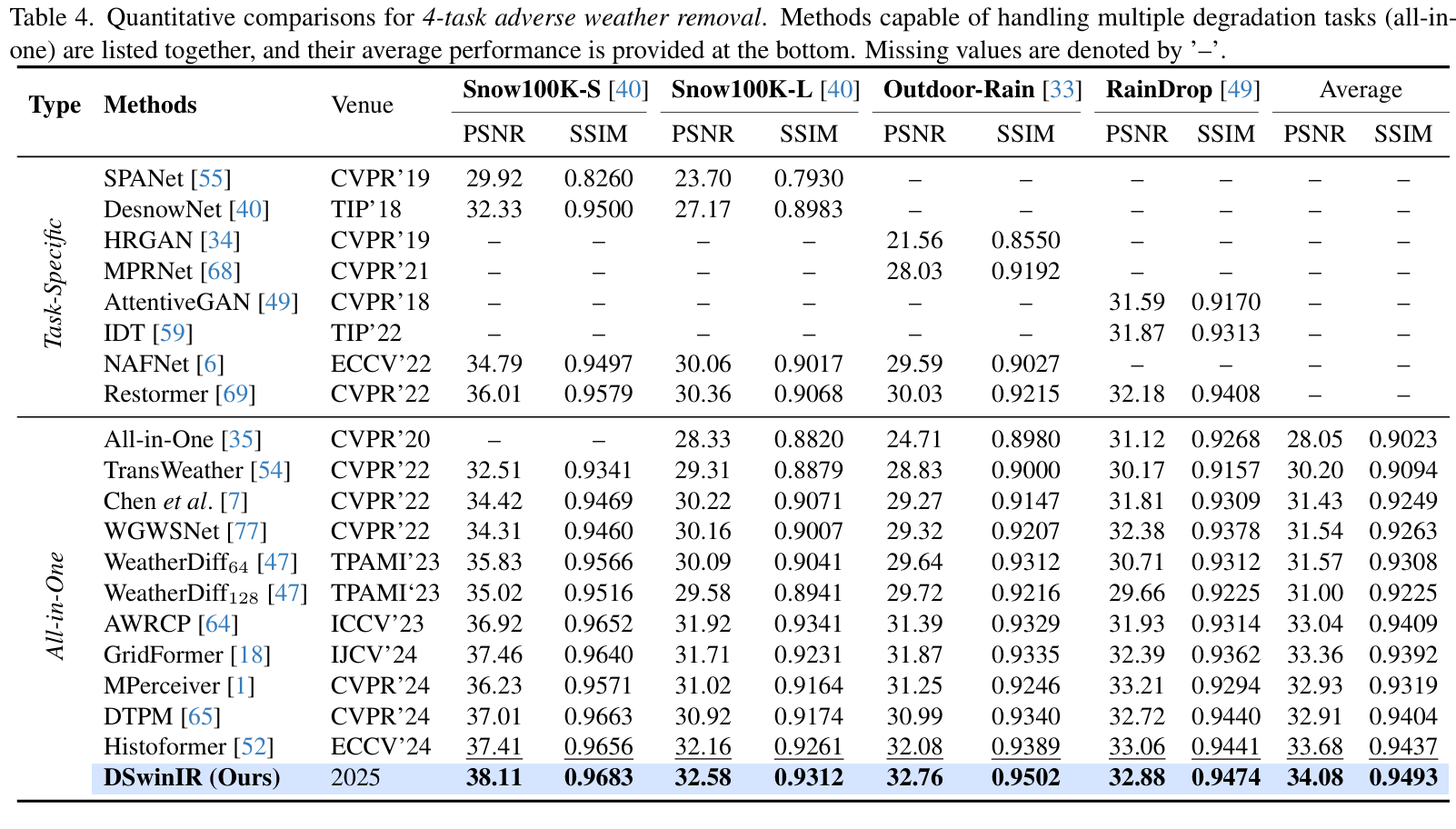
Table 5. Quantitative comparison on setting 4: real-world deweathering following [78]. Results of our DSwinIR is in bold.
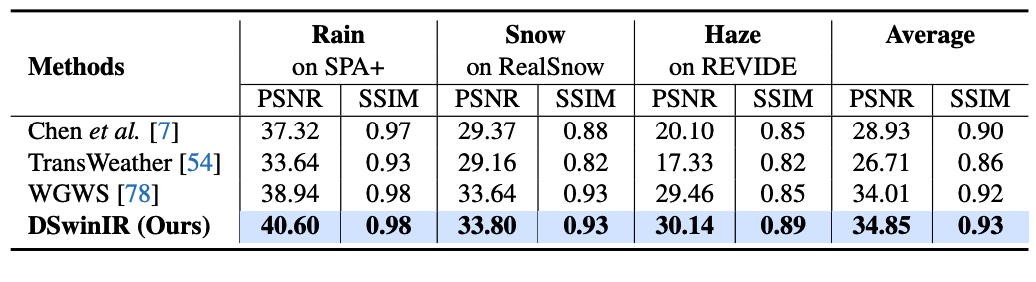
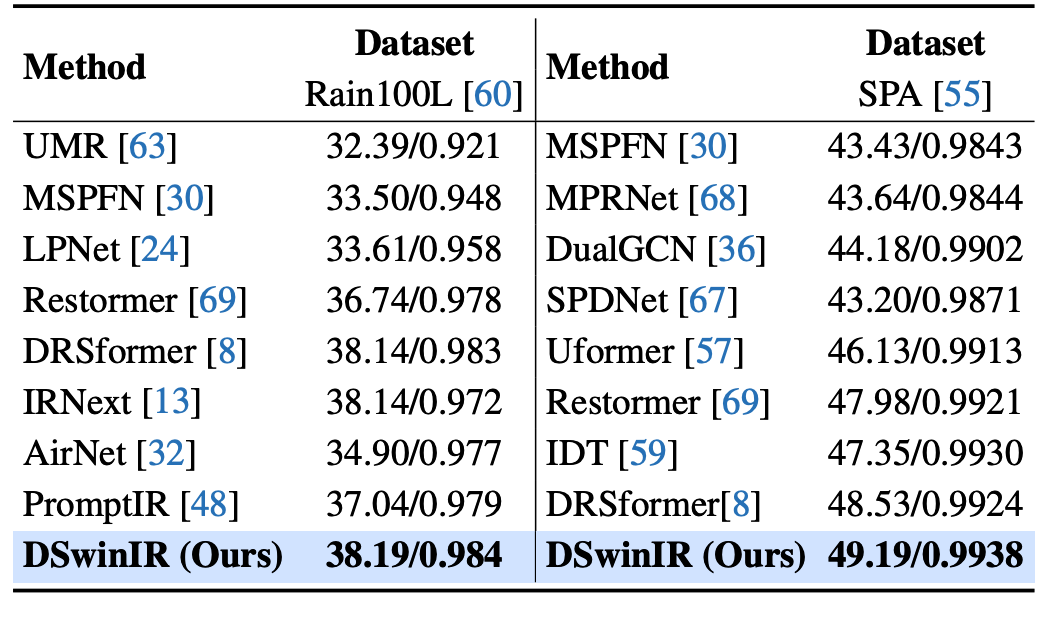
Table 6. Quantitative comparison of different methods on the single image deraining task, evaluated on Rain100L [60] and SPAData [55]. The results are reported in terms of PSNR/SSIM. The best results are highlighted in bold.

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









