







文章目录
介绍
降维(Dimensionality Reduction)是机器学习中用来减少数据集特征数量的技术,其目的是在尽可能保留原始数据信息的同时降低数据的复杂度。降维不仅可以加速模型训练、减少计算资源消耗,还能帮助消除噪声、提高模型性能,并且有助于可视化高维数据。以下是几种常见的降维算法:
-
主成分分析 (PCA, Principal Component Analysis)
PCA 是一种线性降维方法,它通过找到一组新的正交基(主成分),将原始数据投影到这些新轴上。新的坐标系中的每个维度都是原始变量的线性组合,且各维度之间相互独立。PCA的目标是在尽可能少的维度上保留尽可能多的数据方差。 -
线性判别分析 (LDA, Linear Discriminant Analysis)
LDA 是一种监督学习的降维方法,主要用于分类问题。与PCA不同,LDA考虑了类别标签信息,试图最大化类间差异同时最小化类内差异,以找到最佳的特征子空间来区分不同的类别。 -
核主成分分析 (KPCA, Kernel PCA)
KPCA 是PCA的一种非线性扩展,它利用核函数(如RBF核、多项式核等)将原始数据映射到一个更高维的空间,在这个空间中执行PCA。这样可以在不增加太多计算成本的情况下捕捉到数据中的非线性结构。 -
局部线性嵌入 (LLE, Locally Linear Embedding)
LLE是一种非线性降维技术,它假设数据点可以由其邻居点的线性组合表示。LLE尝试保持这种局部线性关系,即使在低维空间中也是如此,从而能够很好地保留数据的拓扑特性。 -
t-分布随机邻域嵌入 (t-SNE, t-Distributed Stochastic Neighbor Embedding)
t-SNE 是一种概率模型,特别适合于数据的可视化。它通过将高维空间中的相似度转换为概率分布,并尽量使低维空间中的点对也具有类似的概率分布,来实现降维。t-SNE对于捕捉局部结构非常有效,但不适合全局结构的保持。 -
自编码器 (Autoencoder)
自编码器是一种基于神经网络的无监督学习方法,它尝试重构输入数据本身。网络中间层通常包含较少的节点,因此可以作为降维后的表示。自编码器可以通过添加稀疏性约束或使用深度架构来增强其表达能力。 -
随机投影 (Random Projection)
随机投影是基于Johnson-Lindenstrauss引理的一种快速降维方法。它通过乘以一个随机矩阵来将高维数据映射到低维空间。这种方法简单高效,但在某些情况下可能会损失较多信息。 -
多维尺度分析 (MDS, Multidimensional Scaling)
MDS 是一种用于可视化和分析距离矩阵的方法,它可以将原始数据转换成一个新的低维空间,使得在这个新空间中两点之间的距离尽可能接近原始空间的距离。 -
Isomap
Isomap(等距映射)是一种保持测地距离的非线性降维方法。它首先构建k近邻图,然后计算图中所有节点间的最短路径,最后通过经典MDS将这些距离映射到低维空间。
每种降维方法都有其适用场景和局限性,选择哪种方法取决于具体的应用需求以及数据的性质。在实际应用中,可能需要根据实验结果调整参数或者尝试多种方法来获得最好的效果。
1、相关背景
- 在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析研究寻找规律。多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的工作量。更重要的是在很多情形下,多变量之间可能存在相关性,从而增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。
- 因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。
- 数据的形式是多种多样的,维度也是各不相同的,当实际问题中遇到很高的维度时,如何给他降到较低的维度上?进行属性选择,当然这是一种很好的方法,这里另外提供一种从高维特征空间向低纬特征空间映射的思路。
2、数据降维
- 降维就是一种对高维度特征数据预处理方法。降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法。
- 数据降维,直观地好处是维度降低了,便于计算和可视化,其更深层次的意义在于有效信息的提取综合及无用信息的摈弃。
- 跟射人先射马,擒贼先擒王一样的道理。抓住主要的,忽略次要的。
- 人的消化系统就是数据(食物)降维过程,变成基本的葡萄糖和氨基酸以及维生素。
- 降维具有如下一些优点:
-
- 减少所需的存储空间
-
- 加快计算速度(例如在机器学习算法中),更少的维数意味着更少的计算,并且更少的维数可以允许使用不适合大量维数的算法。
- 3)去除冗余特征,例如在以平方米和平方公里在存储地形尺寸方面,两者一起用没有意义(数据收集有缺陷)。
-
- 将数据的维数降低到2D或3D可以允许我们绘制和可视化它,可能观察模式,给我们提供直观感受。
-
- 太多的特征或太复杂的模型可以导致过拟合。
-
- 较简单的模型在小数据集上有更强的鲁棒性
-
3、数据降维的方法
- 主要的方法是线性映射和非线性映射方法两大类。
- 线性映射方法的代表方法有:PCA(Principal Component Analysis),LDA(Discriminant Analysis)
- 非线性映射方法的代表方法有:核方法(KernelPCA)、流形学习(ISOMap,LLE)
- 非负矩阵分解(NMF)是在矩阵中所有元素均为非负数的约束条件之下的矩阵分解方法
4、PCA降维
-
PCA(Principal Components Analysis)即主成分分析,是图像处理中经常用到的降维方法。它不仅仅是对高维数据进行降维,更重要的是经过降维去除了噪声,发现了数据中的模式。PCA把原先的n个特征用数目更少的m个特征取代,新特征是旧特征的线性组合,这些线性组合最大化样本方差,尽量使新的m个特征互不相关。
-
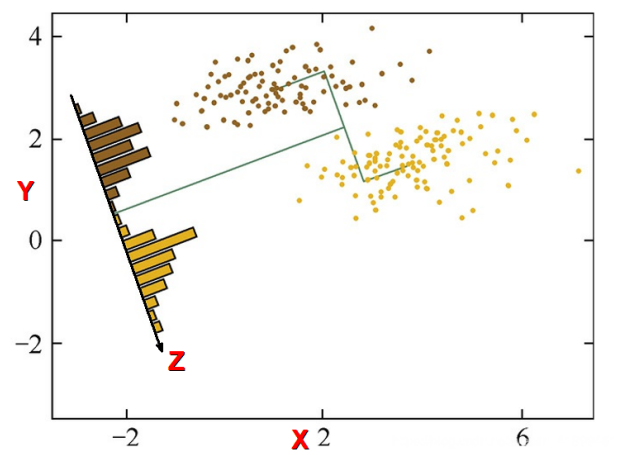
PCA方法通过消除数据的相关性,找到一个空间,使得各个类别的数据在该空间上能够很好地分离。在下图中,有一些离散的二维分布点,其中棕色表示一类集合,黄色表示另一类集合,假设这两个类别可以用特征X和特征Y进行描述,由图可知,在X轴和Y轴上这两个类别的投影是重叠的,表明这些点的两个特征X和Y没有表现出突出的识别性。但是两个类的投影在Z轴上区分度较大,显示出很好的识别性。PCA就是这样的一个工具,它可以产生非常好的降维效果。
-
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
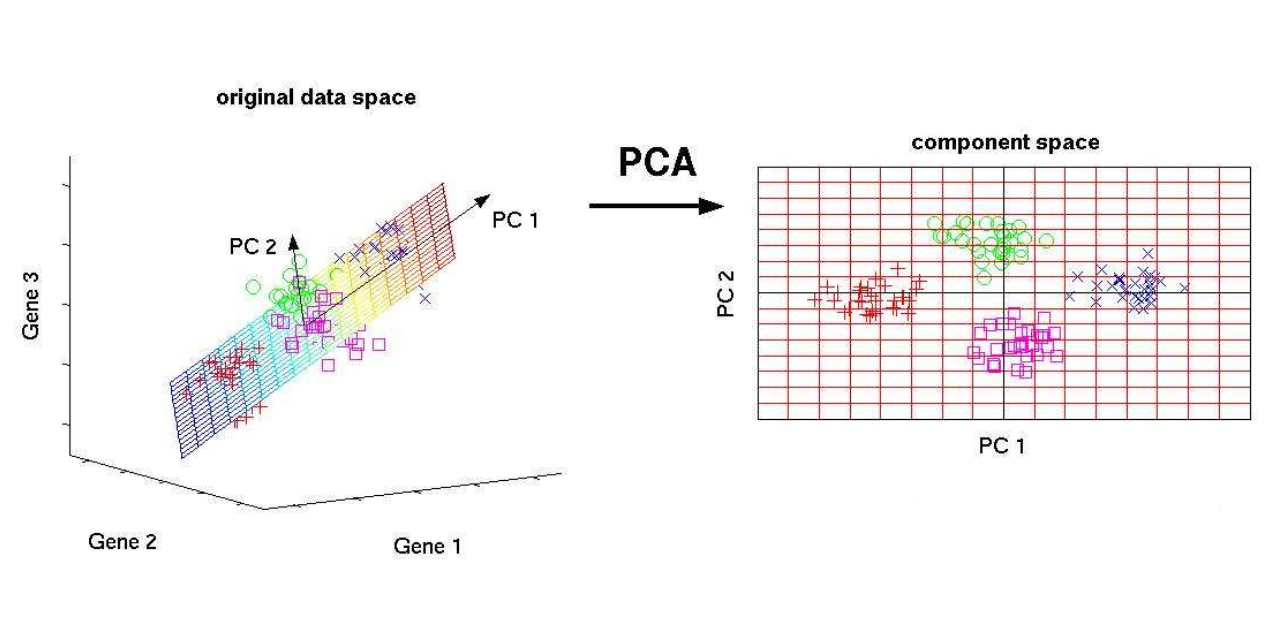
思考:我们如何得到这些包含最大差异性的主成分方向呢?
通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
由于得到协方差矩阵的特征值特征向量有两种方法:特征值分解协方差矩阵、奇异值分解协方差矩阵,所以PCA算法有两种实现方法:基于特征值分解协方差矩阵实现PCA算法、基于SVD分解协方差矩阵实现PCA算法。
-
pca降维原理
4.1. 协方差和散度矩阵样本均值
x ˉ = 1 n ∑ i = 1 n x i \bar x = \frac{1}{n}\sum_{i=1}^nx_i xˉ=n1i=1∑nxi
样本方差
S 2 = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) 2 S^2 = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar x)^2 S2=n−11i=1∑n(xi−xˉ)2
样本X和样本Y的协方差
C o n v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] Conv(X,Y) = E[(X - E(X))(Y - E(Y))] Conv(X,Y)=E[(X−E(X))(Y−E(Y))]
= 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) =\frac{1}{n-1}\sum_{i=1}^n(x_i - \bar x)(y_i - \bar y) =n−11i=1∑n(xi−xˉ)(yi−yˉ)
由上面的公式,我们可以得到以下结论:
- 方差的计算公式是针对一维特征,即针对同一特征不同样本的取值来进行计算得到;而协方差则必须要求至少满足二维特征;方差是协方差的特殊情况。
- 方差和协方差的除数是n-1,这是为了得到方差和协方差的无偏估计。
- 协方差为正时,说明X和Y是正相关关系;协方差为负时,说明X和Y是负相关关系;协方差为0时,说明X和Y是相互独立。Cov(X,X)就是X的方差。
- 当样本是n维数据时,它们的协方差实际上是协方差矩阵(对称方阵)。例如,对于3维数据(x,y,z),计算它的协方差就是:
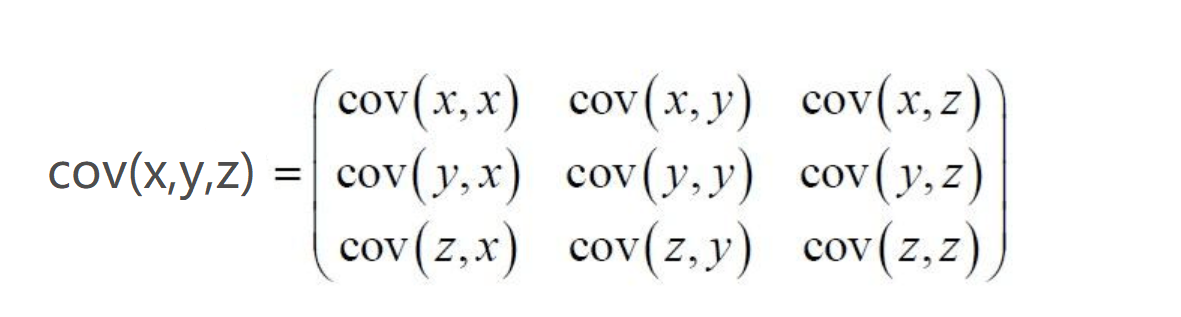
对于数据X的散度矩阵为Scatter matrix。其实协方差矩阵和散度矩阵关系密切,散度矩阵就是协方差矩阵乘以(总数据量n-1)。因此它们的特征值和特征向量是一样的。这里值得注意的是,散度矩阵是SVD奇异值分解的一步,因此PCA和SVD是有很大联系。
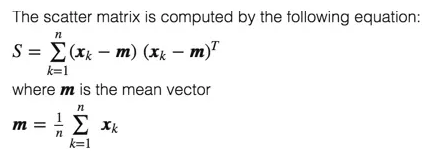
A = np.random.randint(0,10,size = (3,3)) # 协方差 cov = np.cov(A,rowvar=True) # 散度矩阵 B = (A - A.mean(axis = 1).reshape(-1,1)) scatter = B.dot(B.T) display(A,cov,scatter)4.2.特征值分解矩阵原理
-
特征值与特征向量
A v = λ v Av = \lambda v Av=λv
其中,λ是特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量
-
特征值分解矩阵
对于矩阵A,有一组特征向量v,将这组向量进行正交化单位化,就能得到一组正交单位向量。特征值分解,就是将矩阵A分解为如下式:
A = P ∧ P − 1 A = P \wedge P^{-1} A=P∧P−1
其中,P是矩阵A的特征向量组成的矩阵, ∧ \wedge ∧则是一个对角阵,对角线上的元素就是特征值。
4.3.SVD分解矩阵原理
- 是一种因子分解运算,将一个矩阵分解为3个矩阵的乘积
- 3个矩阵: U, Σ 和 V,其中U和V是正交矩阵,分别称为左奇异值、右奇异值,Σ 为奇异值
- 奇异值分解是一个能适用于任意矩阵的一种分解的方法,对于任意矩阵A总是存在一个奇异值分解:
- A = ≈ U Σ V T A = \approx UΣV^T A=≈UΣVT


-
PCA算法两种实现方式:
5.1.基于特征值分解协方差矩阵实现PCA算法:
- 去平均值(即去中心化),即每一位特征减去各自的平均值
- 计算协方差矩阵
- 用特征值分解方法求协方差矩阵的特征值与特征向量
- 对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵ev
- 将数据转换到k个特征向量构建的新空间中,即X_pca= X ⋅ e v X \cdot ev X⋅ev
# 1、去中心化 B = X - X.mean(axis = 0) B[:5] # 2、协方差 # 方差是协方差特殊形式 # 协方差矩阵 V = np.cov(B,rowvar=False,bias = True) # 3、协方差矩阵的特征值和特征向量 # 特征值和特征向量矩阵的概念 eigen,ev = np.linalg.eig(V) display(eigen,ev) # 4、降维标准,2个特征,选取两个最大的特征值所对应的特征的特征向量 # 百分比,计算各特征值,占权重,累加可以 cond = (eigen/eigen.sum()).cumsum() >= 0.98 index = cond.argmax() ev = ev[:,:index + 1] # 5、进行矩阵运算 pca_result = B.dot(ev) # 6、标准化 pca_result = (pca_result -pca_result.mean(axis = 0))/pca_result.std(axis = 0) pca_result[:5]5.2.基于SVD分解协方差矩阵实现PCA算法
- 去平均值(即去中心化),即每一位特征减去各自的平均值
- 通过SVD对第一步结果进行奇异值分解
- 特征值默认从大到小排列,选择k个作为降维特征,对左奇异值矩阵进行切片即可(U[:,:k])
- 归一化处理(无偏差、偏差)
- 无偏估计
- S = 1 n ∑ i = 1 n ( x i − μ ) 2 S = \sqrt{\frac{1}{n}\sum\limits_{i = 1}^n(x_i - \mu)^2} S=n1i=1∑n(xi−μ)2 总体标准差
- S = 1 n − 1 ∑ i = 1 n ( x i − X ‾ ) 2 S = \sqrt{\frac{1}{n-1}\sum\limits_{i = 1}^n(x_i - \overline{X})^2} S=n−11i=1∑n(xi−X)2 样本标准差
from scipy import linalg n_components_ = 3 X,y = datasets.load_iris(return_X_y = True) # 1、去中心化 mean_ = np.mean(X, axis=0) X -= mean_ # 2、奇异值分解 U, S, Vt = linalg.svd(X, full_matrices=False) # 3、符号翻转(如果为负数,那么变成正直) max_abs_cols = np.argmax(np.abs(U), axis=0) signs = np.sign(U[max_abs_cols, range(U.shape[1])]) U *= signs # 4、降维特征筛选 U = U[:, :n_components_] # 5、归一化 # U = (U - U.mean(axis = 0))/U.std(axis = 0) U *= np.sqrt(X.shape[0] - 1) U[:5] -
PCA降维手写数字,支持向量机SVC进行训练和预测
7.1.PCA降维手写数字数据,保留95%的重要特征
7.2.使用降维数据和原始数据分别进行训练和预测
7.3.对比算法学习降维数据和原始数据准确率与运行时间
5、LDA线性判别
-
LDA线性判别分析也是一种经典的降维方法,LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。什么意思呢? 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
可能还是有点抽象,我们先看看最简单的情况。假设我们有两类数据分别为红色和蓝色,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。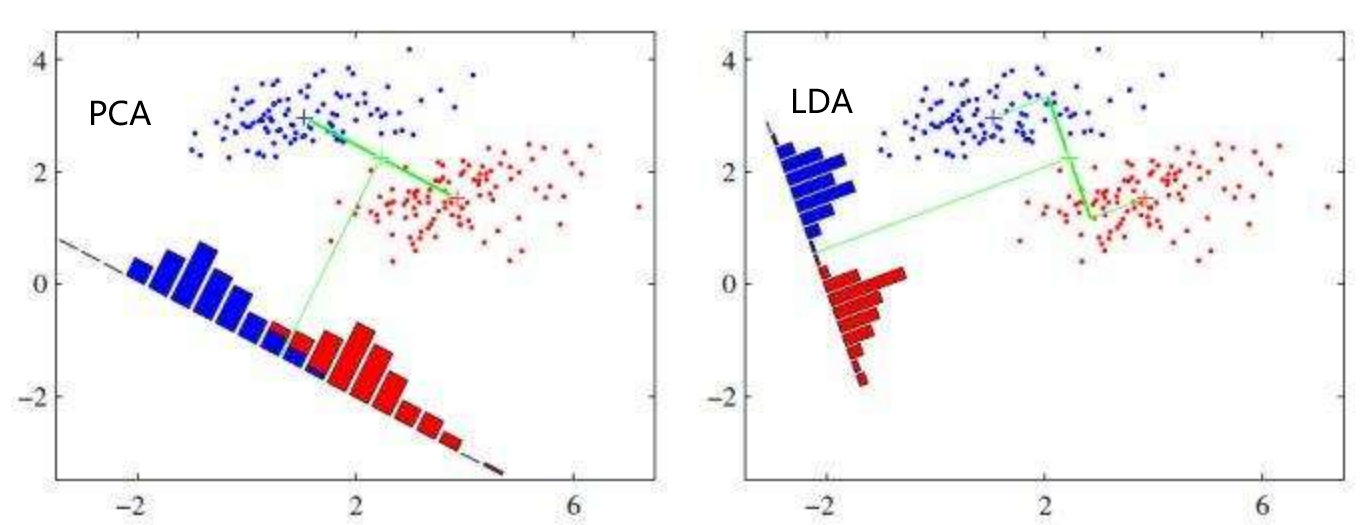
-
给定训练集样例,设法将样例投影到一条直线上,使得同类样例的投影尽可能接近,异类样例的投影点尽可能原理;在对新的样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别
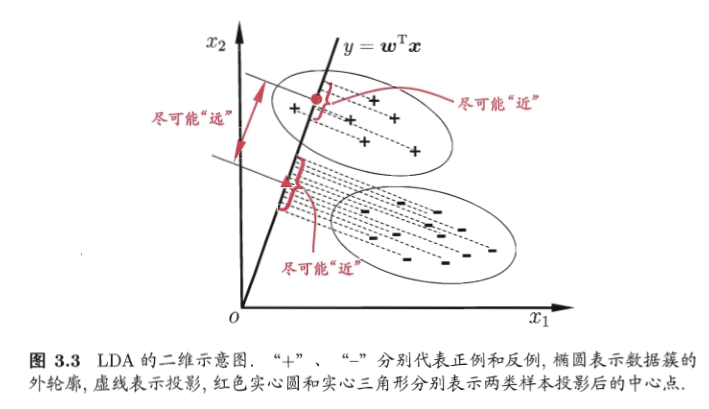
-
LDA算法实现方式

import numpy as np from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn import datasets # scipy这个模块下的线性代数子模块 from scipy import linalg # 加载数据 X,y = datasets.load_iris(return_X_y=True) X[:5] # 1、总的散度矩阵 # 协方差 St = np.cov(X.T,bias = 1) St # 2、类内的散度矩阵 # Scatter散点图,within(内) Sw = np.full(shape = (4,4),fill_value=0,dtype=np.float64) for i in range(3): Sw += np.cov(X[y == i],rowvar = False,bias = 1) Sw/=3 Sw # 3、计算类间的散度矩阵 # Scatter between Sb = St - Sw Sb # 4、特征值,和特征向量 eigen,ev = linalg.eigh(Sb,Sw) ev = ev[:, np.argsort(eigen)[::-1]][:,:2] ev # 5、删选特征向量,进行矩阵运算 X.dot(ev)[:5] -
自己写代码完成LDA操作
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
X,y = datasets.load_iris(return_X_y=True)
# solver : {'svd', 'lsqr', 'eigen'}
lda = LinearDiscriminantAnalysis(solver='eigen',n_components=2)
X_lda = lda.fit_transform(X,y) # 有监督,数据X对应着y
# pca.fit_transform(X) # 无监督,只需要传入X,降维
np.set_printoptions(suppress=True)
# scipy比numpy更加高级的科学计算库
# pip install scipy
from scipy import linalg # 线性代数
# 1、总的散度矩阵
# 协方差,计算的列的,Scatter _ total
St = np.cov(X.T,rowvar = True,bias = 1) # bias偏差,截距
# 2、类内散度矩阵,分3类:0、1、2
# Sw within类内
Sw = np.full(shape = (4,4),fill_value=0,dtype=np.float64) # 声明了一个空的,全是0
for i in range(3): # i = 0,1,2
Sw += np.cov(X[y ==i],rowvar=False,bias=1)
Sw/=3 # 三个类别的平均【类内的散度矩阵】
# 3、计算类间的散度矩阵
Sb = St - Sw
# 4、计算特征值和特征向量
eigen,ev = linalg.eigh(Sb,Sw) # 类间和类内,特征值从小到大
np.argsort(eigen) # 排序索引
n_components = 2
ev = ev[:,[3,2,1,0]][:,:n_components] # 从大到小
# 5、进行矩阵运算
X.dot(ev)[:5]
array([[6.01716893, 7.03257409],
[5.0745834 , 5.9344564 ],
[5.43939015, 6.46102462],
[4.75589325, 6.05166375],
[6.08839432, 7.24878907]])
X_lda[:5]
array([[6.01716893, 7.03257409],
[5.0745834 , 5.9344564 ],
[5.43939015, 6.46102462],
[4.75589325, 6.05166375],
[6.08839432, 7.24878907]])
6、NMF非负矩阵分解
-
NMF的基本思想可以简单描述为:对于任意给定的一个非负矩阵A,NMF算法能够寻找到一个非负矩阵U和一个非负矩阵V,使得满足 ,从而将一个非负的矩阵分解为左右两个非负矩阵的乘积。
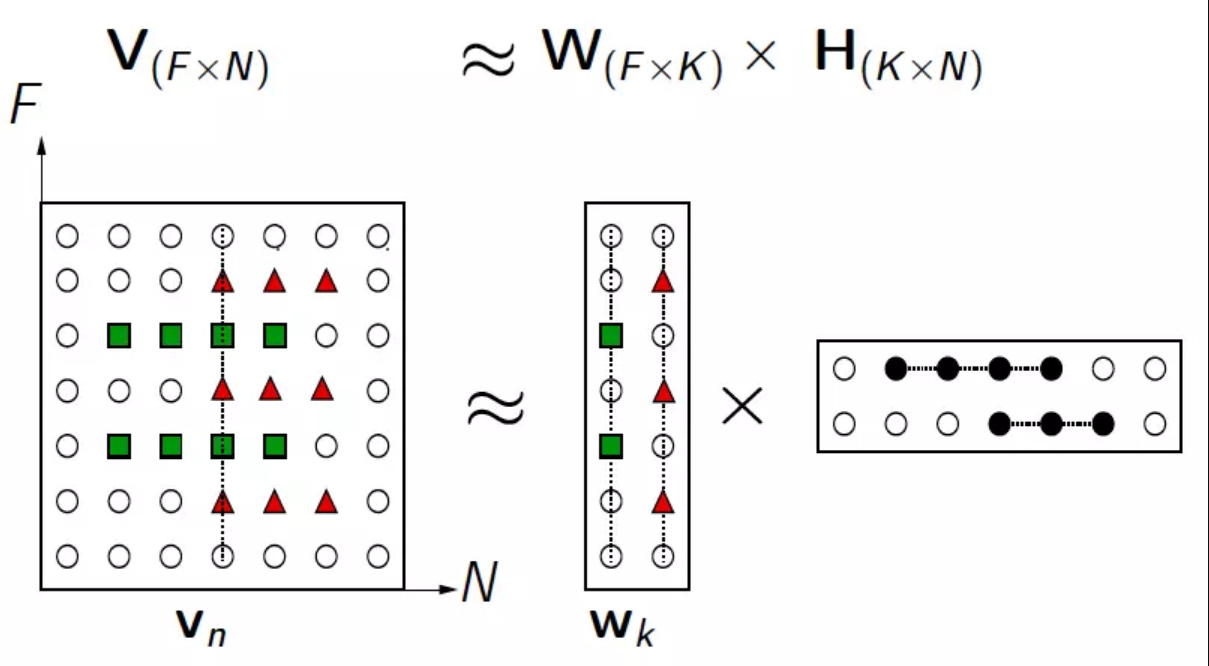
-
解前后可理解为:原始矩阵V的列向量是对左矩阵W中所有列向量的加权和,而权重系数就是右矩阵对应列向量的元素,故称W为基矩阵,H为系数矩阵。一般情况下 k k k(W矩阵的列数)的选择要比N小,满足KaTeX parse error: Expected 'EOF', got '&' at position 7: (F+N)k&̲#x3c;FN,这时用基矩阵W代替原始矩阵,就可以实现对原始矩阵进行降维,得到数据特征的降维矩阵,从而减少存储空间,减少计算机资源。
-
原矩阵V中的一列向量可以解释为对左矩阵W中所有列向量(称为基向量)的加权和,而权重系数为右矩阵H中对应列向量中的元素。这种基于基向量组合的表示形式具有很直观的语义解释,它反映了人类思维中“局部构成整体”的概念。
-
虽然NMF是一个很厉害的算法,但其实质是加权和,我们可以在原理上等效为基本的线性方程:
y = a 1 x 1 + a 2 x 2 + … … + a n x n y = a_1x_1 + a_2x_2 +……+ a_nx_n y=a1x1+a2x2+……+anxn
y y y构成了原矩阵中的元素, α \alpha α是权重, x x x是特征。矩阵乘法中特征用列向量表示,权重系数用行向量表示,所以成了图中所看到的样子。
-
NMF降维算法示例
import numpy as np from sklearn import datasets from sklearn.decomposition import NMF # 加载数据 X,y = datasets.load_iris(return_X_y=True) # 声明算法 nmf = NMF(n_components=2,init = 'nndsvda',max_iter=1000) # 降维之后的数据 W = nmf.fit_transform(X) display(W[:5]) # NMF另一半矩阵H H = nmf.components_ # X ≈ W • H
7、LLE局部线性嵌入降维算法
-
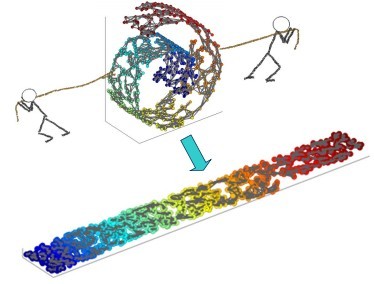
所谓LLE(局部线性嵌入)即”Locally Linear Embedding”的降维算法,在处理所谓流形降维的时候,效果比PCA要好很多。首先,所谓流形,我们脑海里最直观的印象就是Swiss roll,在吃它的时候喜欢把它整个摊开成一张饼再吃,其实这个过程就实现了对瑞士卷的降维操作,即从三维降到了两维。降维前,我们看到相邻的卷层之间看着距离很近,但其实摊开成饼状后才发现其实距离很远,所以如果不进行降维操作,而是直接根据近邻原则去判断相似性其实是不准确的。
-
和传统的PCA,LDA等关注样本方差的降维方法相比,LLE关注于降维时保持样本局部的线性特征(保持原有拓扑结构),由于LLE在降维时保持了样本的局部特征,它广泛的用于图像识别,高维数据可视化等领域。LLE是非线性降维技术,可以说是流形学习方法最经典的算法之一。很多后续的流形学习、降维方法都与LLE有密切联系。
3.传统的机器学习方法中,数据点和数据点之间的距离和映射函数都是定义在欧式空间中的,然而在实际情况中,这些数据点可能不是分布在欧式空间中的(比如黎曼空间),因此传统欧式空间的度量难以用于真实世界的非线性数据,从而需要对数据的分布引入新的假设。黎曼空间就是弯曲的空间

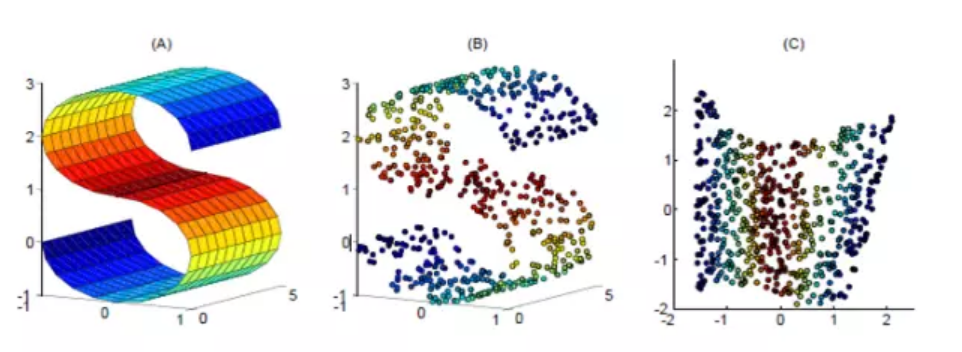
4.LLE的降维实现过程,直观的可视化效果如下图所示
5.LLE算法认为每一个数据点都可以由其近邻点的线性加权组合构造得到,LLE算法主要步骤:
- 寻找每个样本点的k个近邻点;
- 由每个样本点的近邻点计算出该样本点的局部重建权值矩阵;
- 由该样本点的局部重建权值矩阵和其近邻点计算出该样本点的输出值。
6.LLE算法示例:
# 降维,高维数据降成低维的数据
# manifold 流形
from sklearn.manifold import LocallyLinearEmbedding
from sklearn.decomposition import PCA
from sklearn import datasets
import matplotlib.pyplot as plt
%matplotlib inline
from mpl_toolkits.mplot3d.axes3d import Axes3D
X,t = datasets.make_swiss_roll(n_samples=1500,noise=0.05,random_state= 1024)
fig = plt.figure(figsize=(12,9))
# axes3D = Axes3D(fig)
axes3D = fig.add_subplot(projection = '3d')
axes3D.view_init(7,-80)
axes3D.scatter(X[:,0],X[:,1],X[:,2],c = t)
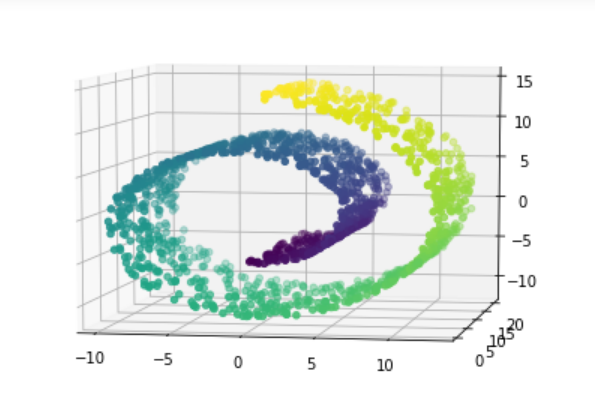
pca = PCA(n_components= 2)
X_pca = pca.fit_transform(X)
plt.scatter(X_pca[:,0],X_pca[:,1],c = t)
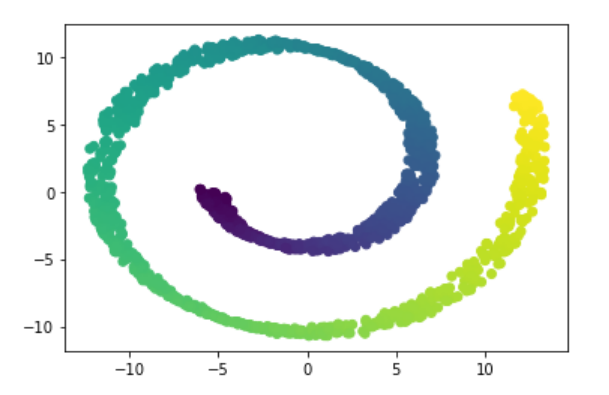
lle = LocallyLinearEmbedding(n_neighbors=10,n_components=2)
lle.fit(X)
X_lle = lle.transform(X)
plt.scatter(X_lle[:,0],X_lle[:,1],c = t)
8、降维-手写数字识别
import numpy as np
import pandas as pd
加载数据
data = pd.read_csv('./digits.csv')
data.head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
| label | pixel0 | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | ... | pixel774 | pixel775 | pixel776 | pixel777 | pixel778 | pixel779 | pixel780 | pixel781 | pixel782 | pixel783 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 785 columns
y = data['label']
X = data.iloc[:,1:]
display(y.head(),X.head())
0 1
1 0
2 1
3 4
4 0
Name: label, dtype: int64
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
| pixel0 | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | pixel9 | ... | pixel774 | pixel775 | pixel776 | pixel777 | pixel778 | pixel779 | pixel780 | pixel781 | pixel782 | pixel783 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 784 columns
X.shape
展示数据
import matplotlib.pyplot as plt
y
# 784像素,28行和28列组成的
image = X.iloc[41997].values.reshape(28,28)
plt.figure(figsize=(2,2))
plt.imshow(image,cmap='gray')
数据拆分
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 1000,random_state = 0)
display(X_train.shape,X_test.shape)
(41000, 784)
(1000, 784)
建模【逻辑斯蒂回归】
%%time
# from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(X_train,y_train)
y_ = model.predict(X_test)
display(y_test[:20],y_[:20])
%%time
model.score(X_test,y_test) #模型进行预测时花费时间比较长
数据降维
from sklearn.decomposition import PCA
pca = PCA(n_components=0.95)
# 标准化处理,算法KNN,距离计算,不需要标准化,如果是梯度下降算法【必须归一化】
X_pca = pca.fit_transform(X)
display(X.shape,X_pca.shape)
display(X_pca[:5])
(42000, 784)
(42000, 154)
array([[-6.61595780e+02, -6.99311328e+02, 1.83282040e+02,
1.20611394e+02, -8.10818105e+01, 4.89461886e+02,
-6.83470838e+02, 8.55593866e+01, 3.48548052e+02,
2.02978545e+02, -3.64559949e+02, 2.12657559e+01,
4.04441449e+02, -9.70525455e+01, 6.18399356e+01,
-8.67800272e+01, 1.76581436e+01, 2.85484696e+02,
1.88273028e+01, 2.07642731e+02, 4.42436003e+01,
2.21894370e+02, 5.72274592e+01, -1.48674962e+02,
1.43435889e+01, -4.15560311e+01, -3.33723659e+02,
2.08978881e+02, 5.98136306e+01, 8.45544647e+01,
6.94293060e+00, -5.29995065e+00, 1.95709336e+02,
-5.32292285e+01, -6.88959872e+00, -1.46886583e+02,
-4.94066227e+01, -8.80639802e+01, -1.61589210e+02,
-1.40787617e+02, 1.04959060e+02, 2.00310607e+01,
4.15619445e+01, -3.65287408e+01, -2.06185633e+02,
3.34091629e+01, -5.41183777e+01, -5.62953193e+01,
-7.53699522e+01, 6.90935930e+01, 7.33123981e+01,
-1.18059337e+02, -9.73279782e+01, -2.95899110e+01,
4.46566576e+01, 2.27470430e+01, 1.12695968e+02,
-7.15693177e+01, 1.47451510e+01, -3.70484637e+00,
2.11584606e+00, 4.29406155e+01, -4.34704246e+01,
-9.63272075e+01, 3.64223881e+01, 1.18598347e+02,
-1.77235255e+01, 5.29303605e+01, 5.25332827e+01,
-2.00622353e+01, -8.88999545e+01, 1.36938121e+01,
-1.50529835e+01, -5.39919251e+01, 1.05550832e+02,
-5.03088487e+01, -7.74394518e+00, -1.73007189e+01,
-3.64719081e+01, -5.50678419e+01, -6.35349144e+01,
-5.62571565e+01, 2.69855005e+01, -3.60697595e+01,
-9.05306937e+00, -5.79513256e+00, 3.96563814e+01,
3.88313575e+01, 1.44954749e+00, -1.73833777e+01,
-5.40012250e+01, 8.01308775e+01, -1.08551289e+01,
6.08951080e+01, 1.36194560e+01, -3.01334206e+00,
3.02487724e+01, 3.06759331e+01, -6.19120027e+01,
-3.19584159e+00, 4.00223122e+01, -3.34308164e+00,
1.84193391e+01, 7.26215209e+00, 1.13363672e+01,
3.23230244e+01, 6.85752152e-02, 2.61286835e+01,
1.40324266e+01, -1.12007991e+01, 1.13033938e+01,
-4.99136166e+01, 4.85901221e+01, -3.72712473e+01,
1.07513167e+01, 1.79894516e+00, -1.51096415e+01,
1.47954742e+00, 5.96809033e+00, 6.56583371e+01,
-6.61924098e+00, -2.49765684e+01, -1.10602525e+01,
-1.65329098e+01, 1.28775170e+01, 2.35936793e+01,
-2.13854589e+01, -3.38218724e+01, 4.54300062e+01,
2.98272565e+01, 3.20597698e+01, 2.08734236e+01,
6.73706581e-01, -2.47116248e+01, 1.42380020e+01,
-5.14823407e+00, 2.03060774e+01, -4.24404029e+00,
2.74662728e+01, 2.49457426e+01, -6.55663259e+00,
-1.06552736e+01, -5.70361182e-01, -3.10174825e+00,
-1.70984362e+01, -5.83392490e+01, 1.58231499e+01,
-9.28701108e+00, -1.84827260e+01, -1.85209618e+01,
-5.67210146e+00, -3.36801973e+01, -5.44911389e+01,
-9.79971911e+00],
[ 1.70145168e+03, -3.60551556e+02, -5.01805594e+02,
3.35423656e+02, -4.42378933e+02, 7.38404049e+02,
6.53875438e+02, -1.76600677e+02, -7.52017489e+00,
6.78462729e+01, 3.42218036e+01, 4.65518418e+01,
-7.04357747e+01, -3.42692097e+02, 3.77839952e+02,
-5.66582709e+00, 3.17765748e+02, 8.76126182e+01,
-9.45311679e+01, -1.75028270e+02, -2.13086598e+02,
-2.72411966e+02, 7.16761158e+00, -2.26351490e+01,
-3.46085889e+01, 2.64486976e+02, -7.66219279e+01,
1.40261297e+01, -8.04273396e+01, -8.76849867e+01,
-2.78225440e+01, 1.88784153e+02, 1.15953010e+02,
5.79216955e+01, -1.04447859e+01, -9.17363969e+01,
-1.10514502e+02, -4.06033466e+01, 1.11846730e+02,
8.71131357e+01, 1.29083932e+01, 3.61403609e+00,
9.69595459e+00, -4.54692379e+01, -1.09212609e+02,
-4.30923540e+01, -4.06763000e+01, -1.51213971e+02,
1.18322989e+02, -2.81103331e+00, 8.24000681e+01,
-1.30732237e+02, 1.04359128e+02, -2.87063844e+01,
9.08563145e+01, -6.80761315e+01, 1.20763651e+02,
4.15327152e+00, 1.37151596e+01, -1.53550509e+02,
6.48142955e+01, -9.93565544e+01, -5.09957206e+01,
-5.03832932e+01, -8.65479701e+01, -1.00344086e+02,
1.42230986e+01, -1.01693485e+02, 5.14566575e+01,
-7.14545714e+01, -5.49704534e+01, 4.98682959e+01,
-9.67656929e+01, 4.57448853e+00, -7.46269237e+01,
2.61507478e+01, -1.20750221e+02, -1.21755999e+02,
-9.10553442e+01, 2.77135345e+01, -6.40562448e+01,
1.96350686e+01, -2.68977531e+01, -1.93850803e+01,
-4.90527783e+01, 3.09887052e+01, 8.83521542e+01,
-5.76627974e+01, 2.50123452e+01, -2.78118447e+01,
-4.91492700e+01, -7.74837879e+01, -7.46169539e+01,
1.36761793e+02, -2.21230577e+01, 4.61429728e+01,
2.87432992e+01, -4.63809154e+01, 2.82468042e-01,
-9.21023015e+01, -9.57079848e+01, -2.68850849e+01,
-2.24328362e+01, 1.28613688e+01, 3.12120394e+01,
3.78667410e+00, 7.24426778e+01, -4.90498959e+01,
7.59582760e+01, -3.34000564e+01, 5.03948367e+01,
1.51187415e+01, 1.00554104e+01, 2.57652673e+01,
4.85278335e+01, -8.89046863e+01, 2.31881486e+01,
4.35448786e+01, 7.75342325e+00, -4.66799744e+01,
-2.92814811e+01, 6.66177307e+01, -2.92195228e+01,
-1.01330724e+01, 3.55674762e+01, -5.53170164e+01,
-5.43178943e+01, -5.47585793e+01, 4.01446867e+01,
2.95289123e+01, 1.13607589e+01, 2.69898293e+01,
1.87278278e+01, -4.86957839e+01, -3.87900164e+01,
1.58172124e+01, 2.66032806e+00, -2.12699093e+01,
-3.39283913e+00, 3.25941090e+01, -4.95273383e+01,
-1.19803715e+01, 2.22178557e+01, 1.52321606e+00,
-4.34070141e+01, -3.64909623e+01, 4.09806457e+01,
-1.06851215e+01, 6.62211767e+01, 3.22940309e+01,
1.08598132e+01, -1.85578044e+01, 1.17929699e+01,
4.09376819e+01],
[-8.86894434e+02, -2.93765782e+02, 6.71553099e+01,
7.82637628e+01, -4.73715921e+02, -3.23540638e+02,
4.37799098e+02, -3.05377740e+02, -1.95295503e+02,
-2.56260228e+01, 3.67595529e+02, 2.52106647e+02,
5.45578883e+01, -5.85908920e+01, 1.63090574e+02,
-1.62494140e+02, -1.00318548e+02, -1.55369350e+02,
7.02048839e+01, -1.82797458e+02, -1.04940439e+02,
1.28626995e+02, 1.52009387e+02, 5.23957225e+01,
-1.12874077e+02, 8.81437286e+01, -2.29586767e+02,
1.06927395e+02, -1.05151323e+01, 1.21363326e+02,
8.81425935e+01, 4.06864624e+01, -4.89212903e+01,
-1.18051804e+02, -1.68743865e+01, -1.79646525e+00,
-5.18193048e+01, 6.64473434e+01, -1.15008861e+02,
-3.82815600e+01, 1.60549673e+02, 3.02159364e+01,
7.95183866e+01, 1.10227196e+02, 3.35974573e+01,
1.34010930e+02, 6.79676195e+00, -1.12585583e+01,
-6.76870236e+01, -4.46430476e+01, -4.06015004e+01,
5.89196602e+01, -1.63459609e+01, 6.73010165e-01,
-2.71289283e+01, -4.32034805e+01, -4.10370095e+01,
-2.22570040e+01, 9.53603455e+01, -6.07336681e+01,
1.04715804e+02, -7.85031319e+00, -7.73380818e+01,
-1.95167098e+00, -1.09032511e+01, -5.42613021e+01,
-9.32714842e+01, 6.97832925e-01, -4.92824731e+01,
7.18092321e+01, 3.88141733e+01, 5.38351333e+01,
6.10290154e+01, -2.32615423e+01, -2.36596752e+01,
8.02447283e+01, -3.92682995e+00, -1.00187382e+01,
1.03873881e+01, -7.03179103e+00, 1.10624254e+02,
2.71506364e+01, -1.92435214e+01, 5.16848951e+01,
1.43871171e+01, 2.75343447e+01, -5.40658819e+01,
4.94337194e+01, 2.56945120e+01, 3.25121921e+01,
5.69744242e+00, -4.76823021e+01, -3.99170629e+00,
6.19715493e+00, -2.40840705e+01, -3.88714369e+00,
-3.10129487e+00, 8.39920146e+01, -8.26400271e+00,
-1.22765770e+02, -3.49254298e+01, 9.76447268e+00,
-4.53428082e+01, -8.97723873e+00, 8.41053145e+00,
-2.67659808e+01, -4.81520970e+00, 7.21262021e+01,
-7.54685090e+00, 1.42584261e+01, -3.99130566e+00,
-2.32812102e+01, -5.32141364e+01, 6.49398772e+00,
1.79971056e+01, -2.60001432e+01, 1.76192622e+01,
2.50932785e+01, -2.74308464e+01, -2.54059641e+01,
-9.12780187e-01, 1.77040308e+01, 1.80411955e+00,
1.69189559e+01, 3.61654453e+00, -2.20463124e+01,
-3.09807698e+01, 4.00492801e+01, 4.37472525e+01,
4.84945813e+01, -4.58043686e+01, 8.23717741e+01,
1.66444036e+01, -3.98177957e+01, 4.74083457e+00,
1.36895921e+01, 2.32459561e+01, -5.15853958e+01,
1.89833906e+01, 1.23794336e+01, -5.21912471e+01,
-1.20142424e+01, -1.56003041e+01, -1.41413307e+01,
-1.38810111e+01, 3.76859877e+01, 2.93525063e+01,
-1.29888909e+01, -6.04163784e+01, 5.40199634e+00,
1.13841986e+01, 1.31771706e+01, -1.36829320e+01,
2.05854394e+01],
[-1.65755602e+02, 3.00182761e+02, -6.41454852e+01,
7.59706261e+02, -4.25844379e+02, 1.57390337e+02,
-3.04099140e+02, 2.76408982e+02, -4.58672154e+01,
-2.95477581e+02, -2.74648031e+00, -2.56884297e+02,
-8.77341898e+01, -1.75361267e+02, 4.00517078e+01,
-8.75363241e+01, 5.42788813e+01, 1.99848998e+02,
-1.18262009e+01, 2.98091710e+02, -2.32160006e+02,
-8.98548411e+01, 2.92732889e+02, 1.25822780e+02,
-6.87010304e+01, -1.93423679e+02, -1.84238504e+02,
8.28971095e+01, 2.14449496e+02, 1.91178375e+02,
-1.02968026e+02, -3.05483875e+01, 1.16253694e+02,
1.52968593e+01, 1.17492107e+02, 1.14581023e+02,
-6.62112174e+01, 7.46613408e+01, 2.76481750e+01,
1.19080519e+02, -6.18255697e+01, 1.43193263e+02,
5.67925544e+01, 1.49172860e+02, 2.12810009e+02,
2.60773853e+02, 2.10584889e+02, 1.02951733e+02,
-5.33945251e+01, 3.02930240e+01, 6.02796964e+01,
3.11222431e+00, 1.49053354e+02, -7.29759301e+01,
-2.44992479e+02, 5.53495777e+00, 9.09065039e+01,
1.24460604e+02, 1.27360102e+02, 1.31523240e+02,
-8.31338390e+00, 1.95892354e+02, -9.62353337e+01,
1.43062309e+01, -2.15505756e+01, -3.52351052e+01,
5.33091391e+01, 9.80904332e+01, 1.24472966e+02,
1.22015947e+02, -4.78436557e+01, -8.87267924e+01,
-5.75032543e+00, 5.35178808e+01, 2.93858501e+01,
4.00440098e+01, 4.19195442e+01, 8.97934120e+00,
-4.82343074e+01, -9.53922584e+01, -1.49150369e+02,
-3.49906640e+01, -1.27953321e+02, 6.63694239e+01,
3.89104044e+01, -1.95003698e+02, -9.29179244e+01,
-5.88494323e+01, -3.06382983e+01, -3.55512326e+01,
1.71582930e+01, 1.67045900e+02, -2.90435170e+01,
-5.75872865e+01, -1.20187457e+02, 1.63978000e+01,
4.75489900e+01, -9.04425601e+01, 8.37901468e+01,
1.26101041e+02, -1.38993405e+00, -5.82456021e+01,
1.39449369e+02, 2.59664860e+01, -1.48040986e+00,
-2.62898717e+01, 6.15136274e+00, -1.78636386e+01,
-1.44372048e+01, -1.02234554e+02, -1.04831731e+02,
-3.79006359e+01, -4.47181651e+01, 8.91963136e+01,
2.44239024e+01, -4.06833843e+01, 8.62335881e+01,
1.14836970e+02, 5.78946696e+01, 2.25685976e+01,
-9.71623801e+01, 4.07154248e+00, -1.63508058e+01,
-1.96085224e+01, 1.99010040e+01, 1.27243997e+02,
1.25261449e+01, -4.55635613e+01, 5.91789577e+01,
-5.67814625e+01, -1.39057629e+02, -1.09812925e+02,
1.00258856e+02, 2.05797772e+01, 5.79984796e+00,
6.28769275e+00, 9.73633780e+01, -1.87307032e+01,
-9.51149216e+00, -1.42313640e+01, 2.11811902e+01,
-9.20329177e+01, 8.89747285e+00, 7.70305374e+01,
-4.63887074e+00, 6.81820621e+01, 9.48621812e+01,
-1.56225652e+01, -9.62648230e+01, 4.76479305e+01,
-4.18029343e+01, -1.06302453e+01, -2.05083797e+01,
1.18396407e+01],
[ 1.92370972e+03, -4.49153069e+02, -5.48613023e+02,
1.88555147e+02, -6.51736273e+02, 9.90063824e+02,
5.64507042e+02, -2.55915217e+02, 1.24914693e+02,
1.77566843e+02, -1.94919879e+01, 3.33721902e+02,
-2.13056379e+02, -3.54643577e+02, 9.34767364e+01,
2.67942260e+01, 2.32994137e+02, -5.47396479e+01,
-4.53425662e+01, -2.56209640e+02, -1.56581730e+01,
-1.31146570e+02, -1.40317010e+02, -5.69322317e+01,
1.75858593e+02, -8.68099092e+00, 5.03125199e+01,
-1.62724694e+02, -6.94699872e+01, 2.47467752e+01,
-3.60449159e+01, -5.93592246e+00, 1.33813261e+01,
-2.90455335e+01, -1.33364115e+02, 6.87869599e+01,
-7.93284700e+01, 3.85968565e+01, -1.42551687e+01,
-8.99845184e+01, 1.22302622e+02, -8.13655143e+01,
5.19590526e+01, -4.50134784e+01, -1.09727060e+02,
5.20005154e+01, 1.94418663e+01, -2.91526976e+01,
6.50525413e+00, 1.12702451e+02, -9.54009600e+01,
-8.10419486e+01, 2.89031730e+01, 1.03378612e+02,
1.06039713e+02, -5.35574318e+01, 8.50018174e+01,
5.15031029e+01, 2.07020915e+01, -1.25911818e+01,
7.59294369e+01, -6.02391737e+01, 7.23047147e+01,
5.13713353e+01, 1.56050276e+02, -9.27189063e+01,
6.59889761e+01, -8.47849142e+01, -8.66717739e+01,
8.60858508e+01, 7.00212851e+01, 8.36576084e+01,
-2.34220513e+02, -8.11291126e+00, -9.00489503e+01,
-3.55214508e+01, -1.10326687e+00, -3.27045310e+01,
-1.07970844e+01, 7.34549119e+01, -3.45837161e+01,
-3.52878254e+01, -6.38473438e+01, -3.10726111e+01,
-6.98869545e+01, 4.96017648e+01, 5.04410657e+01,
7.19274779e+01, 3.85794055e+00, 3.75004188e+01,
-9.73077590e+01, -4.49733986e+01, -8.11436568e+01,
1.43273216e+02, -1.45373746e+02, 4.94979186e+01,
4.16328101e+01, -1.10732080e+02, -6.12800737e+01,
-6.74352617e+01, -2.54112008e+01, 1.05102701e+01,
-7.73559659e-01, -7.49674733e+00, -6.96843645e+01,
-3.06581087e+01, 8.19623544e+01, -2.65623443e+01,
-6.53445314e+01, -5.80269421e+01, 4.44027877e+01,
1.75713112e+01, -1.74472946e+01, -1.05012497e+02,
7.80726431e+01, -3.29483168e+01, -2.11975036e+01,
9.22540234e+00, -3.58052604e+01, 4.61742703e+01,
-4.33084640e+01, 9.35875945e+01, 4.47226628e+01,
2.09315707e+00, 3.67702329e+01, -6.11904296e+01,
2.08885377e+00, -5.07955385e+01, -5.18843609e-01,
1.25974155e+00, 1.70192925e+00, 3.23790650e+01,
3.35080578e+01, 1.53509580e+00, 2.16189806e+01,
4.95752311e+01, -2.25657900e+01, -3.77575889e+01,
5.67435740e+01, -1.50723215e+01, -6.66099126e+00,
4.46640852e+01, -2.11696052e+01, -3.64816836e+01,
5.08387059e+01, 1.07749270e+01, 1.00325811e+01,
2.25602038e+01, 9.79546647e+01, -7.58199956e+01,
9.41112601e-01, 5.04847191e+01, -4.47541051e+01,
-1.04896580e+01]])
X_train_pca,X_test_pca,y_train,y_test = train_test_split(X_pca,y,test_size = 1000,random_state = 0)
%%time
knn = KNeighborsClassifier()
knn.fit(X_train_pca,y_train)
y_ = knn.predict(X_test_pca)
display(y_test.values[:20],y_[:20])
knn.score(X_test_pca,y_test)
探索逻辑斯蒂回归【出错】
pip list
%%time
from sklearn.linear_model import LogisticRegression # 刚才的错,sklearn版本的问题,升级了一下,截距
model =LogisticRegression(max_iter=5000)
model.fit(X_train,y_train)
y_ = model.predict(X_test)
display(y_test[:20],y_[:20])
d:\soft\python\396\lib\site-packages\sklearn\linear_model\_logistic.py:444: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
16275 3
19204 6
18518 9
25780 5
16228 6
15824 5
29252 6
28482 0
13779 0
25912 1
27141 7
21848 1
32576 5
7975 7
10594 8
37445 1
12928 1
2747 5
6658 9
8966 6
Name: label, dtype: int64
array([3, 6, 9, 5, 6, 0, 6, 0, 0, 1, 7, 1, 5, 7, 8, 1, 1, 5, 9, 6],
dtype=int64)
CPU times: total: 1h 25min 34s
Wall time: 8min 10s
%%time
model.score(X_test,y_test)
CPU times: total: 15.6 ms
Wall time: 9.98 ms
0.901
%%time
# PCA降维没有进行归一化
from sklearn.linear_model import LogisticRegression # 刚才的错,sklearn版本的问题,升级了一下,截距
model =LogisticRegression(max_iter=5000)
model.fit(X_train_pca,y_train)
y_ = model.predict(X_test_pca)
display(y_test[:20],y_[:20])
model.score(X_test_pca,y_test)
d:\soft\python\396\lib\site-packages\sklearn\linear_model\_logistic.py:444: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
16275 3
19204 6
18518 9
25780 5
16228 6
15824 5
29252 6
28482 0
13779 0
25912 1
27141 7
21848 1
32576 5
7975 7
10594 8
37445 1
12928 1
2747 5
6658 9
8966 6
Name: label, dtype: int64
array([3, 6, 9, 5, 6, 0, 6, 0, 0, 1, 7, 1, 5, 7, 8, 1, 1, 5, 9, 6],
dtype=int64)
CPU times: total: 20min 13s
Wall time: 3min
0.928
降维时候,归一化
pca = PCA(n_components=0.95,whiten=True)
# 标准化处理,算法KNN,距离计算,不需要标准化,如果是梯度下降算法【必须归一化】
X_pca = pca.fit_transform(X)
X_train_pca,X_test_pca,y_train,y_test = train_test_split(X_pca,y,test_size = 1000,random_state = 0)
%%time
# PCA降维进行归一化
from sklearn.linear_model import LogisticRegression # 刚才的错,sklearn版本的问题,升级了一下,截距
model =LogisticRegression(max_iter=5000)
model.fit(X_train_pca,y_train)
y_ = model.predict(X_test_pca)
display(y_test[:20],y_[:20])
model.score(X_test_pca,y_test)
16275 3
19204 6
18518 9
25780 5
16228 6
15824 5
29252 6
28482 0
13779 0
25912 1
27141 7
21848 1
32576 5
7975 7
10594 8
37445 1
12928 1
2747 5
6658 9
8966 6
Name: label, dtype: int64
array([3, 6, 9, 5, 6, 0, 6, 0, 0, 1, 7, 1, 5, 7, 8, 1, 1, 5, 9, 6],
dtype=int64)
CPU times: total: 35.8 s
Wall time: 5.38 s
0.929



















 139
139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











