







监督学习与非监督学习
Supervised Learning有监督式学习:
输入的数据被称为训练数据,一个模型需要通过一个训练过程,在这个过程中进行预期判断,如果错误了再进行修正,训练过程一直持续到基于训练数据达到预期的精确性。其关键方法是分类和回归,比如逻辑回归(Logistic Regression)和BP神经网络(Back Propagation Neural Network)。
举个栗子:
小时候考试,考不好,开完家长会,回去就是皮带炒肉丝,臭小子,下次再考不好,劳资打死你,你躲在角落瑟瑟发抖,不敢说话。

Unsupervised Learning无监督学习:
没有任何训练数据,基于没有标记的输入数据采取推导结构的模型,其关键方式是关联规则学习和聚合,比如k-means.
广阔天地,大有所为,随便浪。

深度学习的推理和训练
训练(
Training):
一个初始神经网络通过不断的优化自身参数,来让自己变得准确。这整个过程就称之为训练(Traning)。
考前疯狂刷题,零食抱佛脚

推理(
Inference):
你训练好了一个模型,在训练数据集中表现良好,但是我们的期望是它可以对以前没看过的图片进行识别。你重新拍一张图片扔进网络让网络做判断,这种图片就叫做现场数据(live data),如果现场数据的区分准确率非常高,那么证明你的网络训练的是非常好的。这个过程,称为推理(Inference)。
好了,经验刷的差不多了,要上战场了。

选中了正确答案,好的,推理成功了
没选中,继续训练,下次一定

优化和泛化
深度学习的根本问题是优化和泛化之间的对立。
•
优化(optimization)是指调节模型以在训练数据
上得到最佳性能(即机器学习中的学习)。(刷题提高争取率)
•
泛化(generalization)是指训练好的模型在前所未见的数据
上的性能好坏。(考试)
数据集的分类
数据集可以分为:
1. 训练集:实际训练算法的数据集;用来计算梯度,并确定每次迭代中网络权值的更新;
2. 验证集:用于跟踪其学习效果的数据集;是一个指示器,用来表明训练数据点之间所形成的网络函数发生了什么,并且验证集上的误差值在整个训练过程中都将被监测;
3. 测试集:用于产生最终结果的数据集 。
为了让测试集能有效反映网络的泛化能力:
1. 测试集绝不能以任何形式用于训练网络,即使是用于同一组备选网络中挑选网络。测试集只能在所有的训练和模型选择完成后使用;
2. 测试集必须代表网络使用中涉及的所有情形。
交叉验证
这里有一堆数据,我们把他切成3个部分(当然还可以分的更多)
第一部分做测试集,二三部分做训练集,算出准确度;
第二部分做测试集,一三部分做训练集,算出准确度;
第三部分做测试集,一二部分做训练集,算出准确度;
之后算出三个准确度的平局值,作为最后的准确度。
BP神经网络
•
BP网络(
Back-Propagation Network)
是1986年被提出的,是一种按误差逆向传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一,用于函数逼近、模型识别分类、数据压缩和时间序列预测等。
•
BP网络又称为反向传播神经网络,它是一种有监督的学习算法,具有很强的自适应、自学习、非线性映射能力,能较好地解决数据少、信息贫、不确定性问题,且不受非线性模型的限制。
• 一个典型的BP网络应该包括三层:输入层、隐藏层和输出层。各层之间全连接,同层之间无连接。隐藏层可以有很多层。
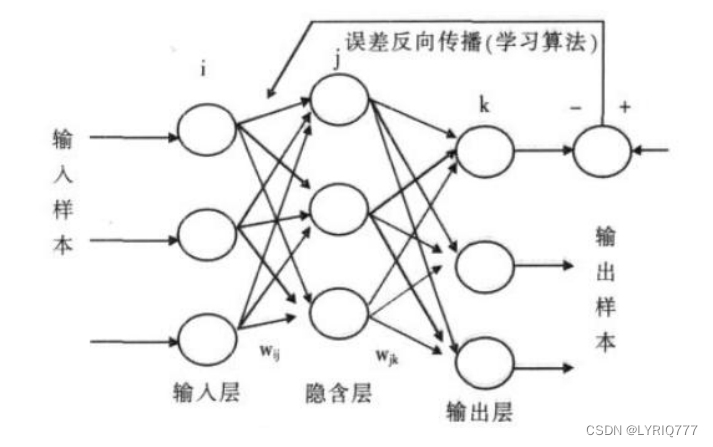
我们利用神经网络去解决图像分割,边界探测等问题时候,我们的输入(假设为x),与期望的输出(假设为y)之间的关系究竟是什么?也就是
y=f(x)
中,
f是什么
,我们也不清楚,但是我们对一点很确信,那就是
f不是一个简单的线性函数
,应该是一个抽象的复杂的关系,那么利用神经网络就是去学习这个关系,存放在model中,利用得到的model去推测训练集之外的数据,得到期望的结果
。
说人话,就是猜,对应的函数是什么样子的,但是不单单是满足这一个点,是满足大部分的点(比如十个里面有六七个,如果能全中,卧槽,那就牛逼了),毕竟机器不会到达100%的正确率,不然要人干嘛呢。
训练(学习)过程:
正向传播
输入信号从输入层经过各个隐藏层向输出层传播。在输出层得到实际的响应值,若实际值与期望值误差较大,就会转入误差反向传播阶段。
反向传播
按照梯度下降的方法从输出层经过各个隐含层并逐层不断地调整各神经元的连接权值和阈值,反复迭代,直到网络输出的误差减少到可以接受的程度,或者进行到预先设定的学习次数。
概念:
代(Epoch):
使用训练集的全部数据对模型进行一次完整训练,被称为“一代训练”。
批大小(Batch size):
使用训练集的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为“一批数据”
迭代(Iteration):
使用一个Batch数据对模型进行一次参数更新的过程,被称为“一次训练”(一次迭代)。
每一次迭代得到的结果都会被作为下一次迭代的初始值。一个迭代=一个正向通过+一个反向通过。

比如训练集有
500
个样本,
batchsize = 10
,那么训练完整个样本集:
iteration=50
,
epoch=1.
神经网络的训练过程
说人话版本:
1、选择样本集合的一个样本(Ai,Bi),Ai为数据、Bi为标签(所属类别)
2、送入网络,计算网络的实际输出Y,(此时网络中的权重应该都是随机量)
3、计算D=Bi
−
Y(即预测值与实际值相差多少)
4、根据误差D调整权重矩阵W
5、对每个样本重复上述过程,直到对整个样本集来说,误差不超过规定范围
不说人话版本:
更具体的:
1 参数的随机初始化
•
对于所有的参数我们必须初始化它们的值,而且它们的初始值不能设置成一样,比如都设置成0或1。如果设置成一样那么更新后所有参数都会相等。即所有神经元的功能都相等,造成了高度冗余。所以我们必须随机化初始参数。
•
特别的,如果神经网络没有隐藏层,则可以把所有参数初始化为0。(但这也不叫深度神经网络了)
标准化
原因:由于进行分类器或模型的建立与训练时,输入的数据范围可能比较大,同时样本中各数据可能量纲不一致,这样的数据容易对模型训练或分类器的构建结果产生影响,因此需要对其进行标准化处理,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
y=(x-min)/(max-min),重点,要记下来
z-score标准化(零均值归一化
zero-mean normalization
):
•
经过处理后的数据均值为0,标准差为1(正态分布)
•
其中μ是样本的均值, σ是样本的标准差
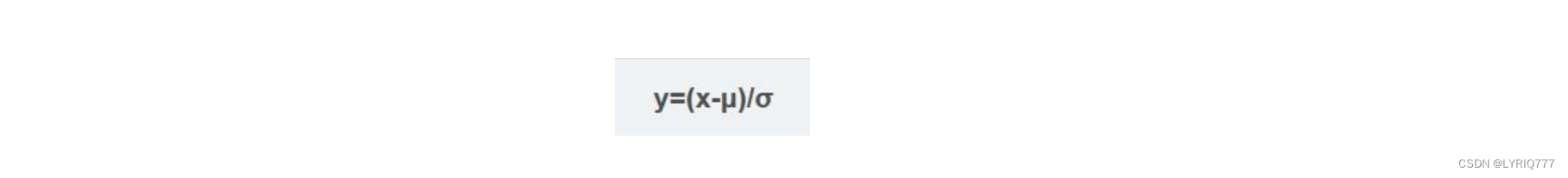
•
dropout的缺点就在于训练时间是没有dropout网络的2-3倍。
2 前向传播计算每个样本对应的输出节点激活函数值
3 计算损失函数
损失函数
损失函数用于描述模型预测值与真实值的差距大小。一般有有两种常见的算法——均值平方差(MSE)和交叉熵。
•
均值平方差(Mean Squared Error,MSE),也称“均方误差”:
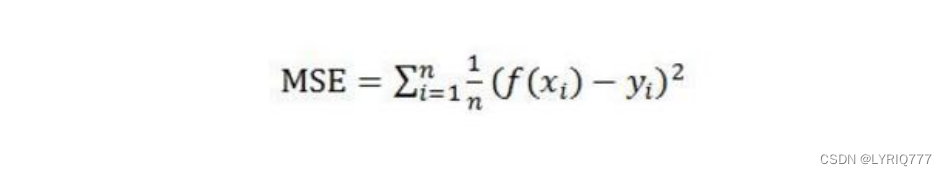
•
交叉熵(cross entropy)也是loss算法的一种,一般用在分类问题上,表达意思为预测输入样本属于哪一类的概率。值越小,代表预测结果越准。(y代表真实值分类(0或1),a代表预测值):
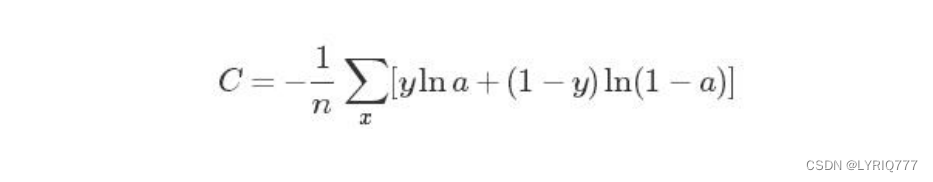
损失函数的选取取决于输入标签数据的类型:
1. 如果输入的实数、无界的值,损失函数使用MSE。
2. 如果输入标签是位矢量(分类标志),使用交叉熵会更适合。
4 反向传播计算偏导数
5 使用梯度下降或者先进的优化方法更新权值
梯度下降法:
•
梯度
∇
f=(
∂
x1∂f;∂
x2∂f;…;∂
xn∂f)指函数关于变量x的导数,梯度的方向表示函数值增大的方向,梯度的模表示函数值增大的速率。
•
那么只要不断将参数的值向着梯度的反方向更新一定大小,就能得到函数的最小值(全局最小值或者局部最小值)。
•
一般利用梯度更新参数时会将梯度乘以一个小于1的
学习速率(
learning rate)
,这是因为往往梯度的模还是比较大的,直接用其更新参数会使得函数值不断波动,很难收敛到一个平衡点(这也是学习率不宜过大的原因)。
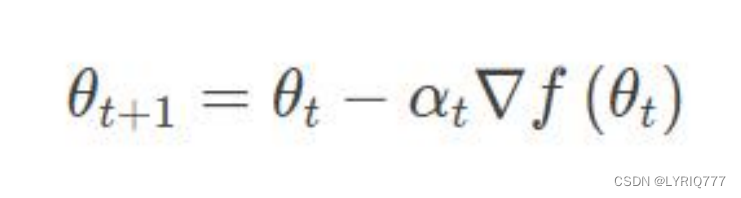
学习率
学习率
是一个重要的超参数,它控制着我们基于损失梯度调整神经网络权值的速度。 学习率越小,我们沿着损失梯度下降的速度越慢。
从长远来看,这种谨慎慢行的选择可能还不错,因为可以避免错过任何局部最优解,但它也意味着我们要花更多时间来收敛,尤其是如果我们处于曲线的至高点。
新权值 = 当前权值 - 学习率 × 梯度
梯度下降法:
按下不表,后期单独出一期,(嘿嘿)
泛化能力分类:
•
欠拟合:模型没有能够很好的表现数据的结构,而出现的拟合度不高的情况。模型不能在训练集上获得足够低的误差;
•
拟合:测试误差与训练误差差距较小;
•
过拟合:模型过分的拟合训练样本,但对测试样本预测准确率不高的情况,也就是说模型泛化能力很差。训练误差和测试误差之间的差距太大;
•
不收敛:模型不是根据训练集训练得到的。
对于各种泛化出现的原因,按下不表*2,再单独出一期,哈哈哈,我太皮了。
Early Stopping(提前停止或有条件退出):
•
在每一个Epoch结束时,计算validation data的accuracy,当accuracy不再提高时,就停止训练。
•
那么该做法的一个重点便是怎样才认为validation accurary不再提高了呢?并不是说validation accuracy一降下来便认为不再提高了,因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy又上去了,所以不能根据一两次的连续降低就判断不再提高。
•
一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。
•
这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30
Dropout(隐藏个别神经元):
在神经网络中,dropout方法是通过修改神经网络本身结构来实现的:
1. 在训练开始时,随机删除一些(可以设定为1/2,也可以为1/3,1/4等)隐藏层神经元,即认为这些神经元不存在,同时保持输入层与输出层神经元的个数不变。
2. 然后按照BP学习算法对ANN中的参数进行学习更新(虚线连接的单元不更新,因为认为这些神经元被临时删除了)。这样一次迭代更新便完成了。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。这样一直进行,直至训练结束。
Dropout方法是通过修改ANN中隐藏层的神经元个数来防止ANN的过拟合。
为什么Dropout能够减少过拟合:
1. Dropout是随机选择忽略隐层节点,在每个批次的训练过程,由于每次随机忽略的隐层节点都不同,这样就使每次训练的网络都是不一样的, 每次训练都可以当做一个“新”模型;
2. 隐含节点都是以一定概率随机出现,因此不能保证每2个隐含节点每次都同时出现。这样权值的更新不再依赖有固定关系隐含节点的共同作用,阻止了某些特征仅仅在其他特定特征下才有效果的情况。
总结:Dropout是一个非常有效的神经网络模型平均方法,通过训练大量的不同的网络,来平均预测概率。不同的模型在不同的训练集上训练(每个epoch的训练数据都是随机选择),最后在每个模型用相同的权重来“融合”。
•
经过交叉验证,隐藏节点dropout率等于0.5的时候效果最好。
•
dropout也可以被用作一种添加噪声的方法,直接对input进行操作。输入层设为更接近1的数。使得输入变化不会太大(0.8)
总结一下:
BP算法是一个迭代算法,它的基本思想如下:
1. 将训练集数据输入到神经网络的输入层,经过隐藏层,最后达到输出层并输出结果,这就是前向传播过程。
2. 由于神经网络的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
3. 在反向传播的过程中,根据误差调整各种参数的值(相连神经元的权重),使得总损失函数减小。
4. 迭代上述三个步骤(即对数据进行反复训练),直到满足停止准则。
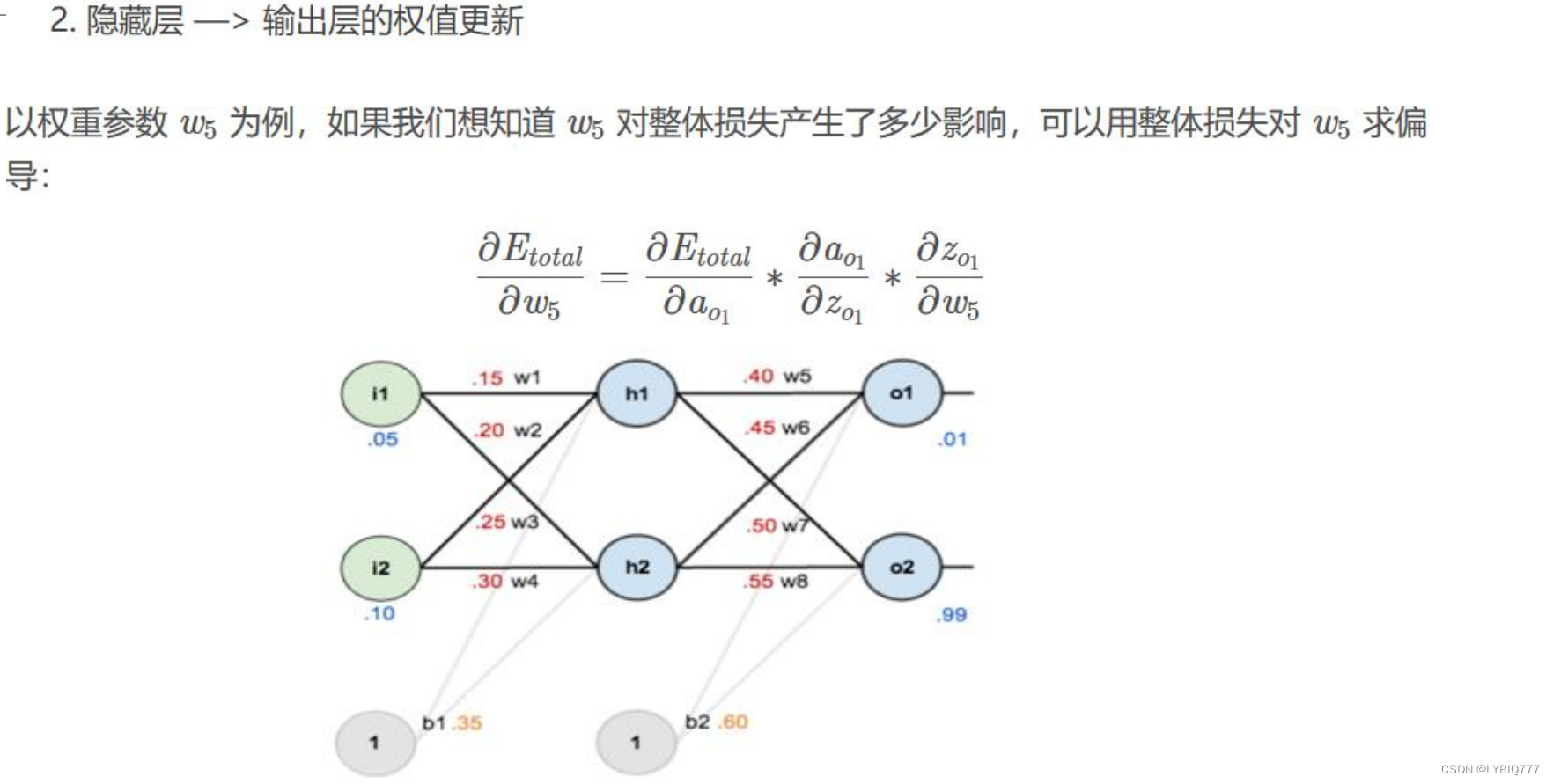
举个栗子(别玩手机了!!!):
1. 第一层是输入层,包含两个神经元:i1,i2和偏置b1;
2. 第二层是隐藏层,包含两个神经元:h1,h2和偏置项b2;
3. 第三层是输出:o1,o2;
4. 每条线上标的 wi是层与层之间连接的权重。
5. 激活函数是 sigmod 函数。
6. 用 z 表示某神经元的加权输入和,用 a 表示某神经元的输出。
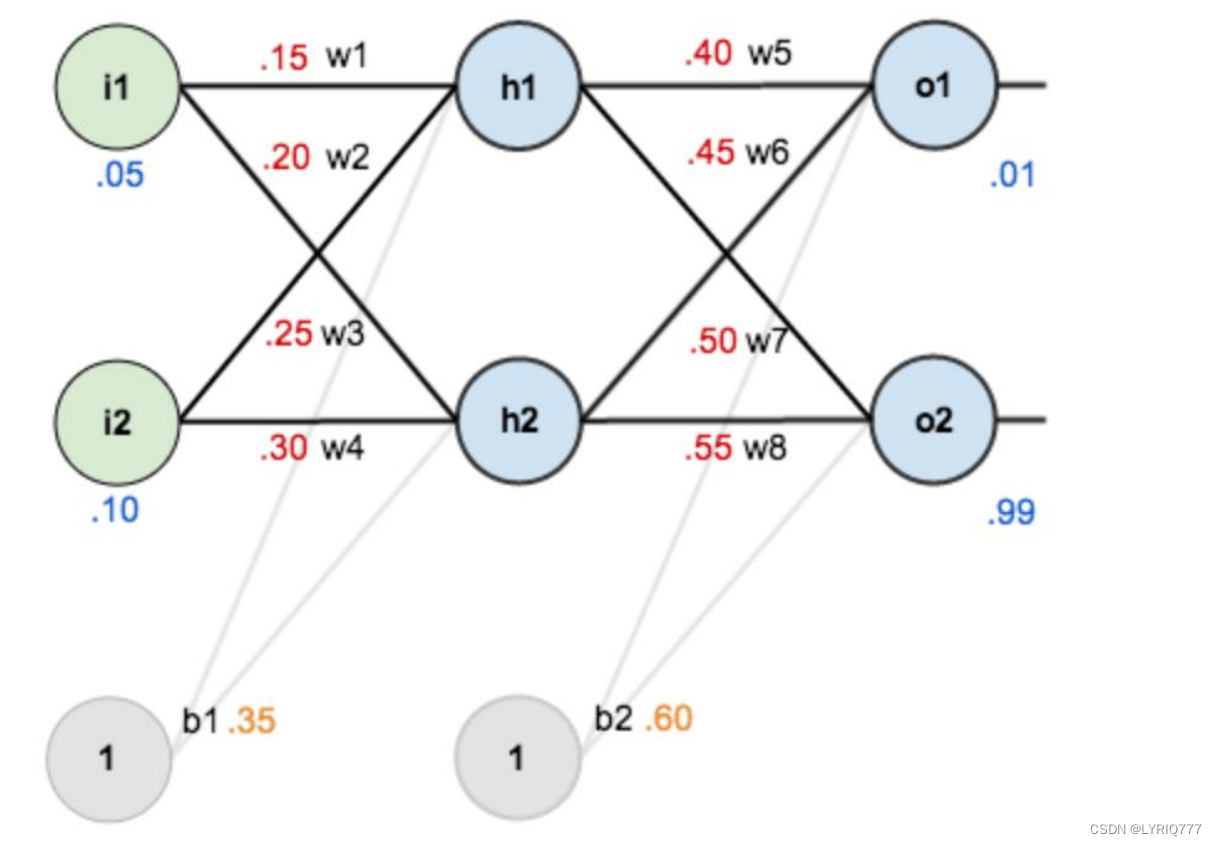
Step 1 前向传播:
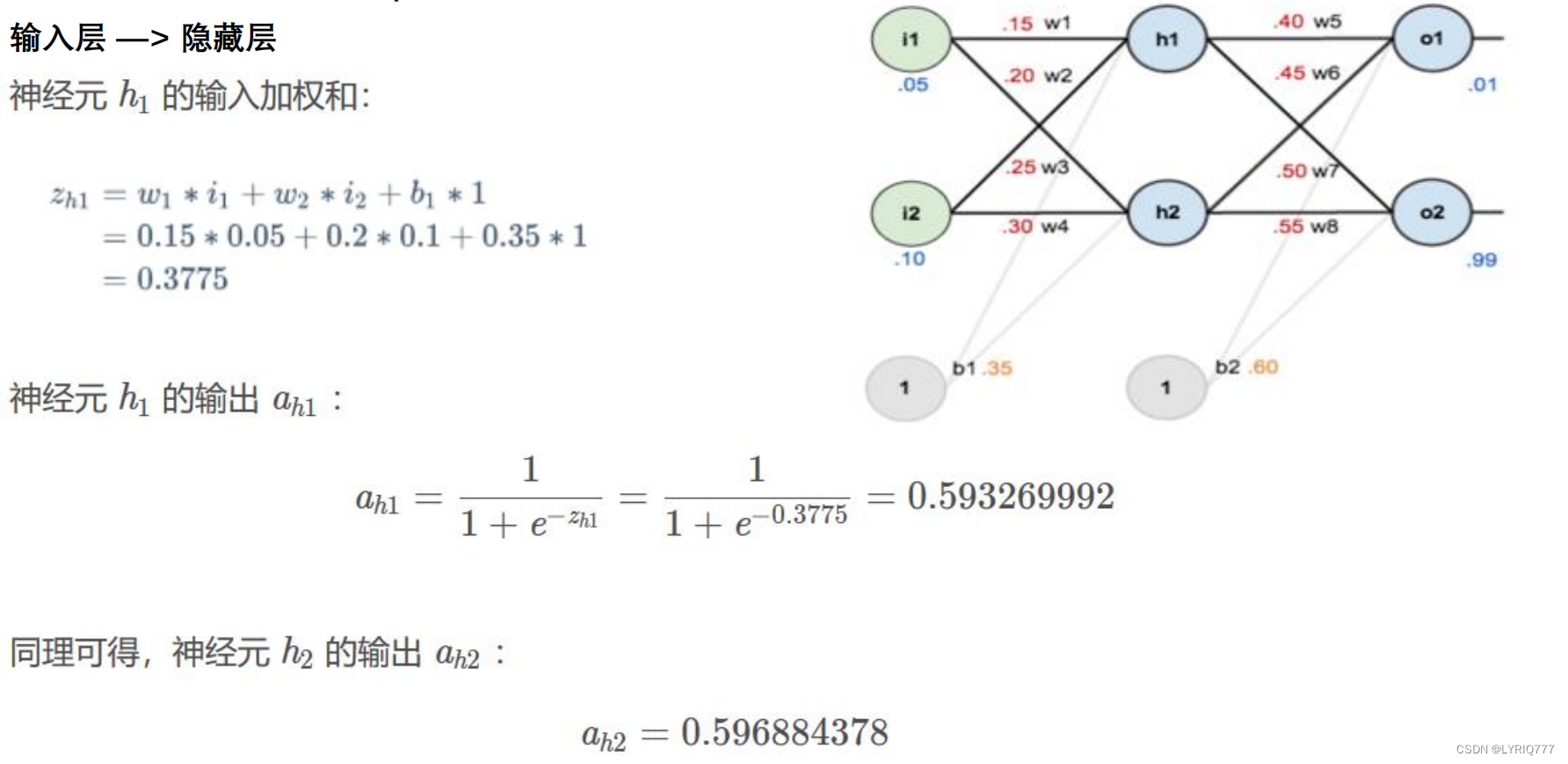
有兴趣的可以自己算一下,我不算了

Step 2 反向传播









Softmax(分类器)















 1605
1605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









