







本次简单介绍一下MSRA初始化方法,方法同样来自于何凯明paper 《Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification》.
Motivation
网络初始化是一件很重要的事情。但是,传统的固定方差的高斯分布初始化,在网络变深的时候使得模型很难收敛。此外,VGG团队是这样处理初始化的问题的:他们首先训练了一个8层的网络,然后用这个网络再去初始化更深的网络。
“Xavier”是一种相对不错的初始化方法,我在我的另一篇博文“深度学习——Xavier初始化方法”中有介绍。但是,Xavier推导的时候假设激活函数是线性的,显然我们目前常用的ReLU和PReLU并不满足这一条件。
MSRA初始化
只考虑输入个数时,MSRA初始化是一个均值为0方差为2/n的高斯分布:
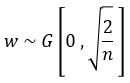
推导证明
推导过程与Xavier类似。
首先,用下式表示第L层卷积:
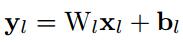
则其方差为:(假设x和w独立,且各自的每一个元素都同分布,即下式中的n_l表示输入元素个数,x_l和w_l都表示单个元素)
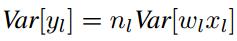
当权重W满足0均值时,上述方差可以进一步写为:
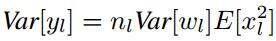
对于ReLU激活函数,我们有:(其中f是激活函数)
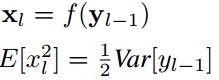
带入之前的方差公式则有:
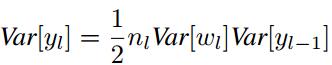
由上式易知,为了使每一层数据的方差保持一致,则权重应满足:
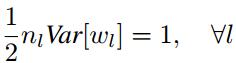
补充说明
(1) 对于第一层数据,由于其之前没有经过ReLU,因此理论上这一层的初始化方差应为1/n。但是,因为只有一层,系数差一点影响不大,因此为了简化操作整体都采用2/n的方差;
(2) 反向传播需要考虑的情况完全类似于“Xavier”。对于反向传播,可以同样进行上面的推导,最后的结论依然是方差应为2/n,只不过因为是反向,这里的n不再是输入个数,而是输出个数。文章中说,这两种方法都可以帮助模型收敛。
(3) 对于PReLU激活函数来说,条件变成了:
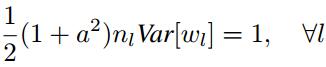
因此初始化和PReLU有关,但是目前caffe的代码并不在支持在MSRA初始化时手动指定a的值。
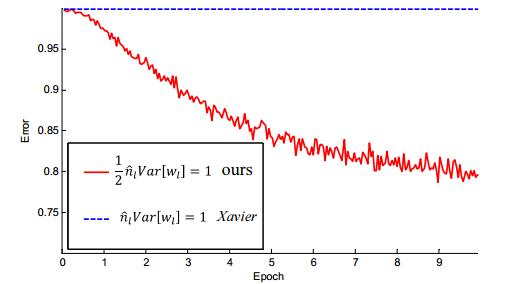
(4) 文章做了一些对比试验,表明在网络加深后,MSRA初始化明显优于Xavier初始化。
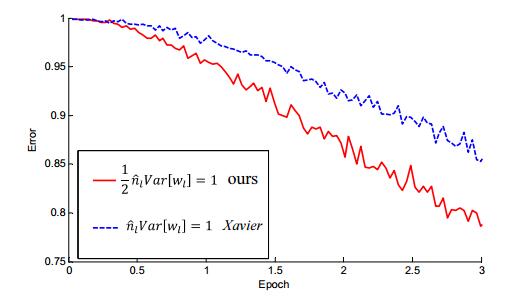
特别当网络增加到33层之后,对比效果更加明显















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









