







一、 插入排序
1. 插入排序伪代码:
int insertionSort(int *A, int n)
{
for(int i = 2; i <= n; i++){
int tmp = A[i];
for(int j = i-1; j > 0; j--)
if(A[j] > tmp)
A[j+1] = A[j];
else{
A[j+1] = tmp;
break;
}
}
return 0;
}2. 循环不变式(loop invariant)
在循环内及循环结束时都成立的表达式,用于证明算法的正确性。
初始化:它在循环的第一轮迭代开始前应该是正确的;
保持:如果在循环的某一轮迭代前它是正确的,那么在下一次迭代开始前它也应该是正确的;
终止:当循环结束时,循环不变式给我一个有用的性质,它有助于证明算法是正确的。
二、 算法分析
1. 算法分析是指对一个算法所需要的资源进行预测,资源通常包含内存、带宽、硬件、时间等。
2. RAM模型:通用的单处理器,随机存取RAM模型
a、 指令一条接一条地执行,没有并发操作;
b、 包含了真实计算机中常见的指令:算术指令、数据移动指令、控制指令;
c、 每条指令所需时间都为常量;
d、 数据类型有整数类型和浮点实数类型;
RAM模型没有对常见的存储层次的建模。
3. 一般来说,算法所需的时间是与输入规模同步增长的,一个算法的运行时间是其输入的函数。
4. 最坏情况:一个算法的最坏情况运行时间是在任何输入下运行时间的一个上界。大致上来看,平均情况通常与最坏情况一样差;在某些情况下我们可能对一个算法的平均情况或期望的运行时间感兴趣。
5. 概率分析技术:可以用来确定一个算法的期望运行时间。
6. 增长的量级:
a、忽略每条语句的真实代价, 用某个常量Ci表示;
b、 更加简单,忽略常系数对Ci的依赖性;
c、只考虑公式中的最高次项;
d、忽略高次项的常数系数;
如果一个算法的最坏情况运行时间比另一个要低,那么我们认为他的效率更高。
三、 算法设计方法——分治法
1. 分治法Divide and Conquer
特点:结构上是递归的;将原问题划分成n个与原问题结构相似而规模较小的子问题;递归地解决这些子问题,然后将结果合并,就得到原问题的解。
2. 分治模式在每一层上都有三个步骤:
分解(devide):将原问题分解为一些列的子问题;
解决(conquer):递归地解决各个子问题,如果子问题足够小,则直接求解;
合并(combine):将子问题的结果合并为原问题的解;
3. 归并排序算法:
合并排序算法代码如下
#include <iostream>
#include <string>
#include <map>
#define INF 99999999
using namespace std;
int merge(int *A, int p, int q, int r)
{
int n1 = q - p + 1;
int n2 = r - q;
int *L = new int(n1+1);
int *R = new int(n2+1);
int i, j = 0;
for(i = p; i <= q; ++i)
L[j++] = A[i];
L[j] = INF;
j = 0;
for(i = q+1; i <= r; ++i)
R[j++] = A[i];
R[j] = INF;
i = 0;
j = 0;
for(int k = p; k <= r; k++)
if(L[i] <= R[j])
A[k] = L[i++];
else
A[k] = R[j++];
}
void mergeSort(int *A, int p, int r)
{
if(p < r)
{
int q = (p + r)/2;
mergeSort(A, p, q);
mergeSort(A, q+1, r);
merge(A, p, q, r);
}
}
int main(int argc, char *argv[])
{
int A[100], n;
while(cin>>n)
{
for(int i = 1; i <= n; i++)
cin>>A[i];
mergeSort(A, 1, n);
for(int j = 1; j <= n; j++)
cout<<A[j]<<" ";
cout<<endl;
}
return 0;
}4. 分治算法分析:
a、结构上是递归的;
b、运行时间可以用一个递归方程来表示:
问题足够小的时候,得到直接解的时间为常量。
我们把原问题分解为a个子问题,每个子问题的大小都是原问题的1/b,设分解该问题的时间为D(n),合并该问题的时间为C(n):
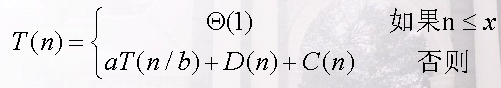
5. 合并排序算法时间分析:
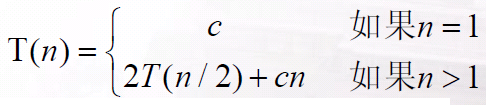
由主定理可知合并排序的运行时间为Θ(nlogn).















 1914
1914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









