






写在前面
本文是对论文Incorporating Learnable Membrane Time Constant to Enhance Learning of Spiking Neural Networks的阅读笔记,本文架构与原论文一致。文末是本人的一些想法。
如遇SNN相关概念不明白,见SpikingJelly文档。
ABSTRACT
讲述了本文做的工作,大概两点:
- 让膜时间常数( membrane time constant)成为可学习的参数,而不是预置的超参数。
- 在SNN中使用最大池化,而不是通常认为的平均池化。最大池化具有更多优势。
1. INTRODUCTION
首先,大概讲述了一下SNN的概况。
其次,论述将膜时间参数作为训练参数的优点:符合生物脑神经元的特点、增强神经元表达力。
最后,讲述本文做的三点贡献:
- 使用PLIF(也就是带参数的LIF神经元)作为神经元,基于反向传播进行训练。这提高了模型的鲁棒性和学习速度。
- 重新评估池化方法。证明最大池化性能不比平均池化差,还能降低计算成本(二进制位运算)、保留神经元放电的异步性(下文详细说明)。
- 在一些数据集上检验本文的模型,效果很好。
2. RELATED WORKS
讲述了一些基于SNN的训练方法和模型等,可做学习和了解用,不加赘述。
3. METHODS
3.1. LIF模型
描述LIF神经元的阈下动力学的微分方程为:
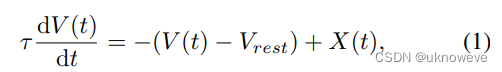
V就是神经元的当前电压;X是输入;Vrest(或者说Vreset,论文中认为二者等价)是神经元的静息电位值,也就是说当输入X为0时,电压V的稳态值是静息电位。
3.2. 突触权值和膜时间常数的影响
从数学公式的角度更好理解。
突触权值,可以理解为上述方程(1)中的X(t),也就是对神经元的输入;膜时间参数,就是方程(1)中的τ。
所以这里实质就是探讨,改变X(t)、改变τ分别会对方程产生什么影响。
(学过电路理论的朋友,应该更懂是什么意思,电容的充电放电方程)
论文中举了详细的例子,还画出了图表,来探讨这个问题,详见原论文。
主要结论就是τ影响神经元的“敏感度”,这从上述微分方程上很好理解。
3.3. Parametric LIF模型
描述PLIF神经元的阈下动力学的微分方程,还是方程(1),只不过我们现在把τ看做变量。
特点如下:同层神经元τ相同,不同层神经元τ不同。这是因为,想操纵同层的神经元比较难,所以训练是layer-level的。
接下来是描述神经元行为的方程,包括充电、释放脉冲、脉冲后电压变化。采取差分方程的形式(即微分方程的离散版),如下:
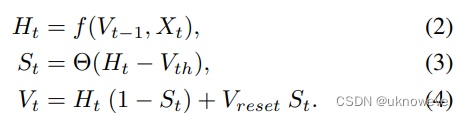
以及
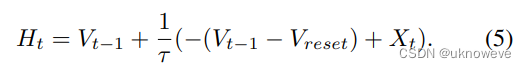
- 这里的H和V都是电压值,而V特指“脉冲后电压”,所以引入H来避免混淆。
- 方程(2)见方程(5)。
- 方程(5)其实就是方程(1)的离散版本(差分方程),也就是描述神经元在没达到阈值(threshold)时怎么充电和漏电。
- 方程(3)描述如何释放脉冲,这个函数是阶跃函数。意思是如果H比Vth(也就是阈值)高,则值为1(释放脉冲),反之值为0(不释放脉冲)。
- 方程(4)描述脉冲后,神经元电压变化。若释放了脉冲,即S为1,则电压变为H;若未释放脉冲,即S为0,则电压变为Vreset。总之,意思是没脉冲就继续充电漏电,释放了脉冲就变回静息电位。
接下来,在实际训练时,如果直接训练方程(5)的τ参数,会很困难(因为在分母上)。所以令τ=1/k(a),而k(a)是以a为参数的sigmoid函数,这样就变成了训练参数a。
为什么这样做呢?则需要数学上的解释:
方程(5)作为方程(1)的离散近似,只有在τ>1时才是有效近似,这是因为方程(1)的dt是无穷小的时间片(t的微分),而方程(5)的时间片大小为Δt=t-(t-1)=1,所以需要τ>Δt。
而规定τ=1/k(a)恰可以满足τ的值域为(1,正无穷)。
3.4. 从RNN的角度解释LIF和PLIF
当规定静息电位Vreset为0时,方程(5)可写做
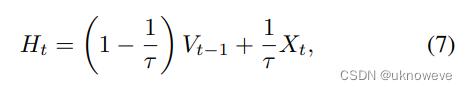
因为方程(5)本身就是描述充电和漏电的,那么从方程(7)来看,两个加数项:
- 第一项是漏电,也就是t时刻的电压比t-1时刻的电压更小。变化倍率为1-1/τ。
- 第二项是充电,从当前输入中获取电压。倍率为1/τ。
- 从权重角度看,1-1/τ和1/τ是权重,和为1,τ可以调节两项权重的占比。
- 从RNN角度看,漏电过程是遗忘过程,充电过程是记忆过程。更多相关见LSTM网络。
3.5. Network Formulation
讲述了网络架构。
重点是:
- 第一层卷积和神经元激活,作为编码器,而不是用传统的泊松编码器。
- 突触连接(即卷积层和全连接层),都是无状态的,也就是说仅仅做线性变换而已。而只有神经元是有状态的,因为数值和时间有关。
3.6. 最大池化
以往研究认为最大池化会丢失信息。
在论文模型中,池化层在神经元之后,也就是说是对脉冲(非0即1的二进制信息)进行池化。如果采用最大池化,那么只有产生脉冲(值为1)的神经元的信息会经过池化而到达下一层,而没产生脉冲的神经元就不会与下一层进行连接(这在论文中被称为“赢家通吃”)。(看上去这样的设计比较符合生物学)
另外,释放脉冲后的神经元短时间内难以再次脉冲,所以神经元释放脉冲不会是同步的,而是异步的。举例来说,3个突触前神经元a,b,c,1个突触后神经元d,a,b,c异步释放脉冲,那么采取最大池化时,d近似于时时刻刻都在被充电,可以快速达到阈值。这样模型时间域的拟合能力不强(我暂时不懂),而且看上去也比较合理。
而且,最大池化传递的信息都是二进制的,可以采用位运算,平均池化却要进行浮点数运算,显然前者对硬件更友好。
依我看,最大池化的优点就是:符合生物学(产生脉冲的才连接到下一层,反之不连接);运算优势。
3.7. Training Framework
暂略
4. Experiments
略
5. Conclusion
PLIF,最大池化的优势。
写在后面
我学到了什么:
- 描述神经元行为的严谨数学公式,PLIF中τ=1/k(a)的设计及其原因。
- 充电与漏电的平衡,遗忘与记忆的平衡。
- 最大池化的探讨与优点(主要)。
Brain Storm:
- SNN的一大特点,就是部分信息以二进制形式(脉冲)传递,基于此我们才有了使用最大池化的机会。或许可以利用该特点做更多事情。
- 论文中规定Vrest与Vreset一致,其实可以认为,Vrest是缓慢漏电渐渐回到的静息电位,Vreset是释放脉冲后立刻跃变回静息电位。在生物学中,后者这个过程,是存在过极化的,也就是生物体内Vreset应该比Vrest低一点。如果SNN中也这样设计,会达到什么效果呢?















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









