







无监督学习

费曼的思想:what i can not create, i do not understand
不知道怎么产生的话,是不能完全理解的。
Create - Image Processing

Generative Models
PixelRNN
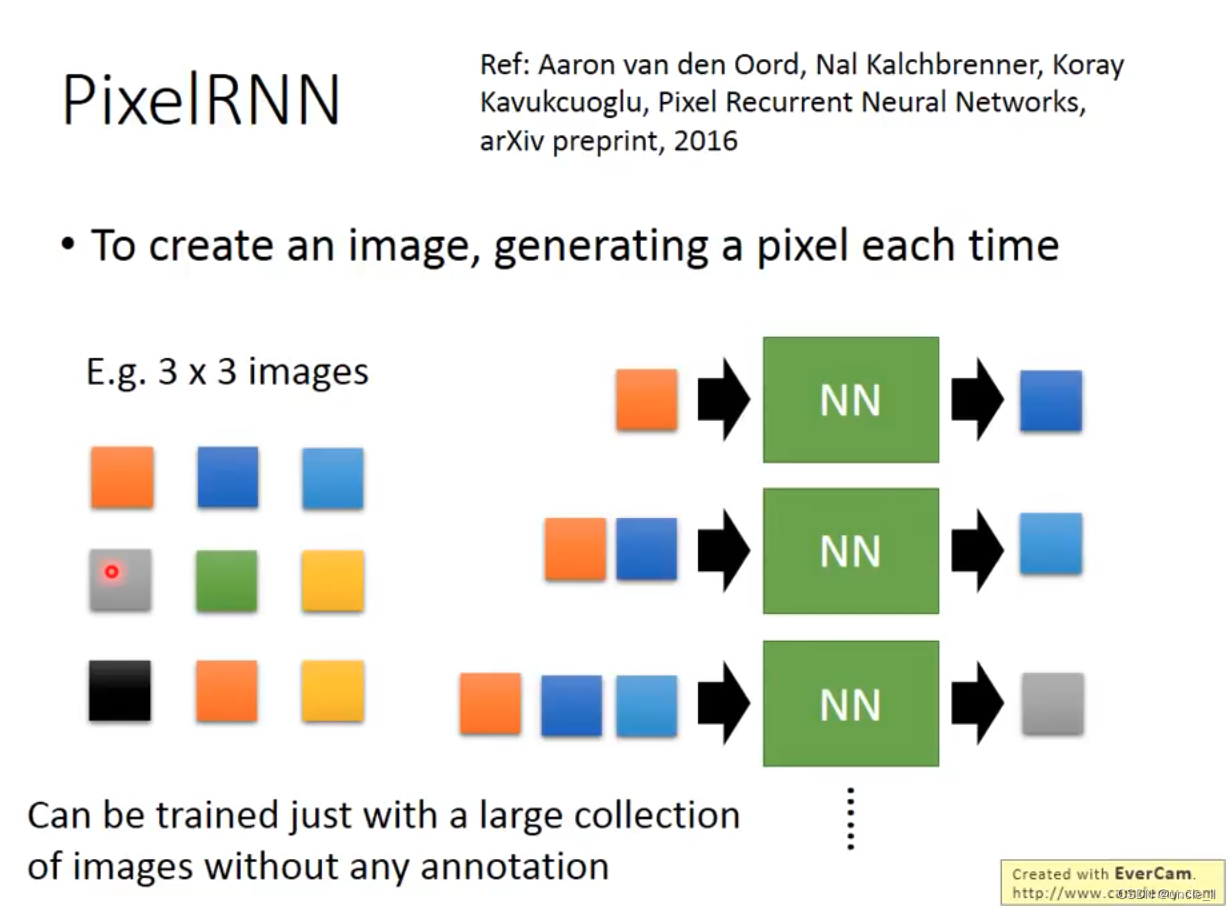
输入一个3x3的像素块,输出3x3的像素块。再把所有的加入继续送入网络输出,注意这里每次输出都是3x3的,最终得到9个图像块组合得到一个一张生成的大图。
这种模型训练也非常简单,从大图切分为小图即可,不需要任何标注。

把下半身遮掉,让机器自动填充下半身

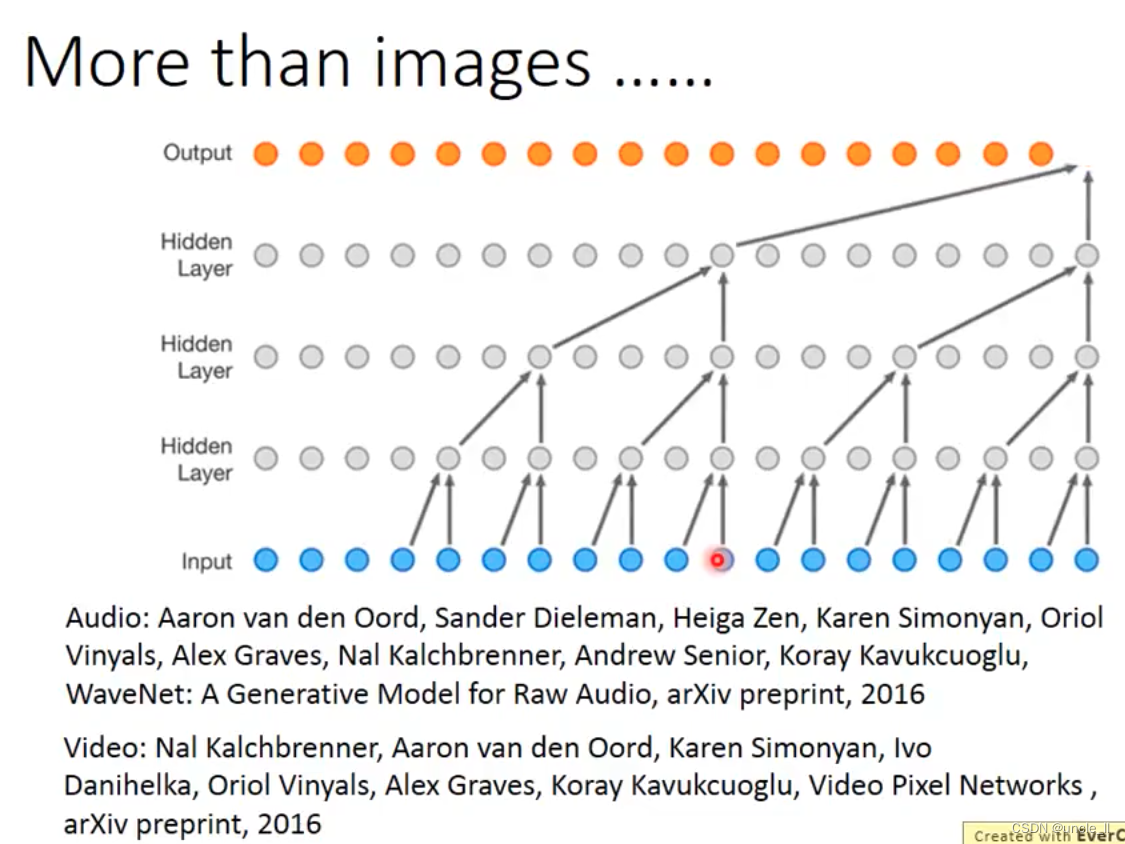
声音领域也可以使用这种思想,合成出一段声音。
实践项目-生成宝可梦

像素大小40x40 或者20x20,下面有一些实践经验:
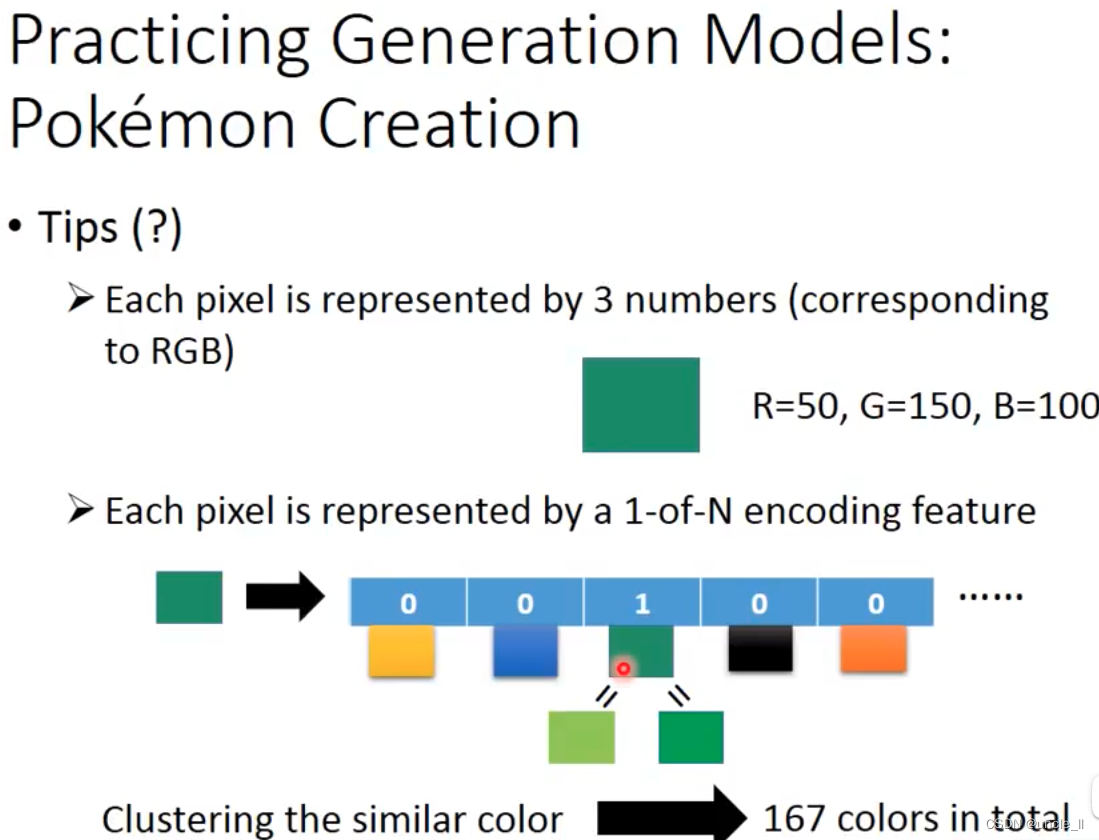
不用rgb来表示,这样生成的图像偏灰色,而是使用一维向量表示每个像素点,但是像素范围比较多,256256256, 为了降低复杂度,对相近颜色进行聚类。

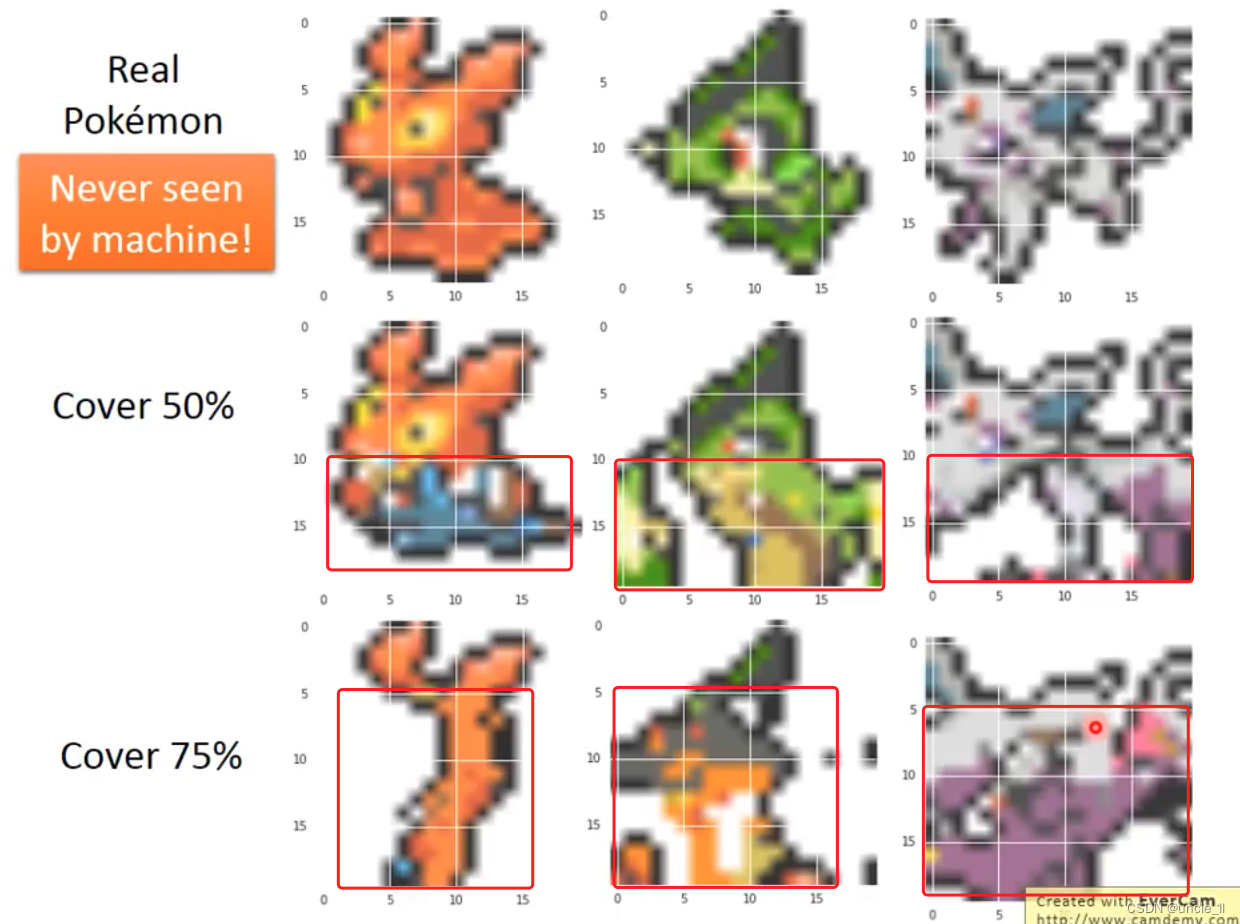
生成的图像无法衡量评估

Variational AutoEncoder
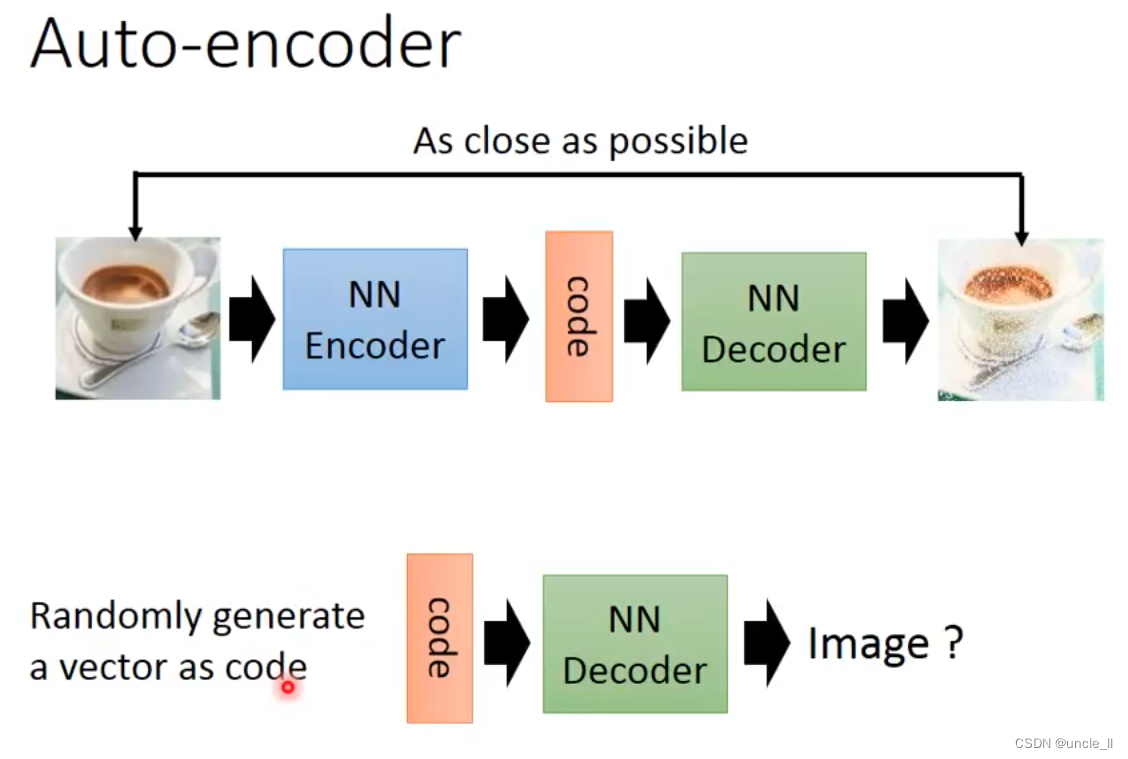
通过图片训练一个编码器和解码器。然后只用decoder, 对输入进行编码。
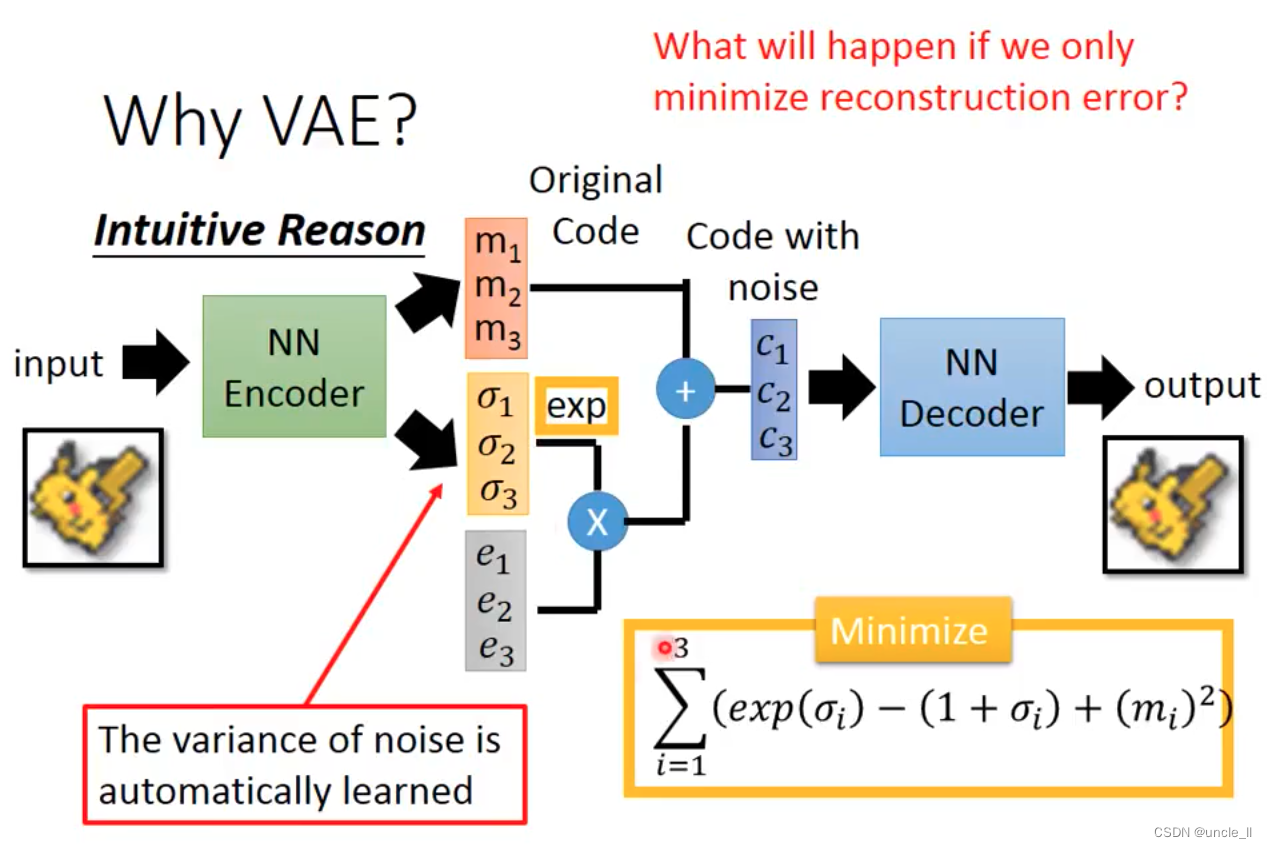
但上述效果一般不好,改成VAE效果会好一些。
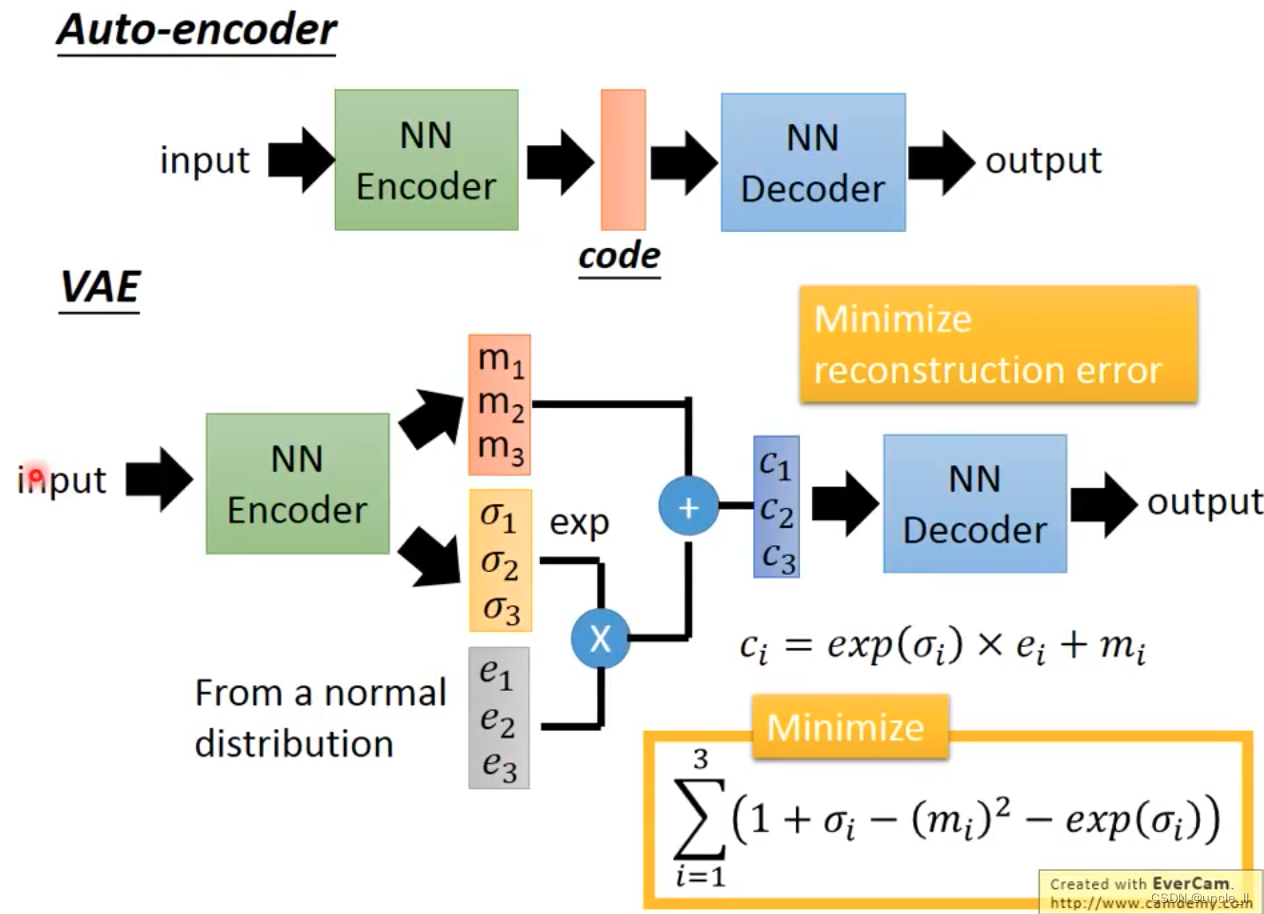
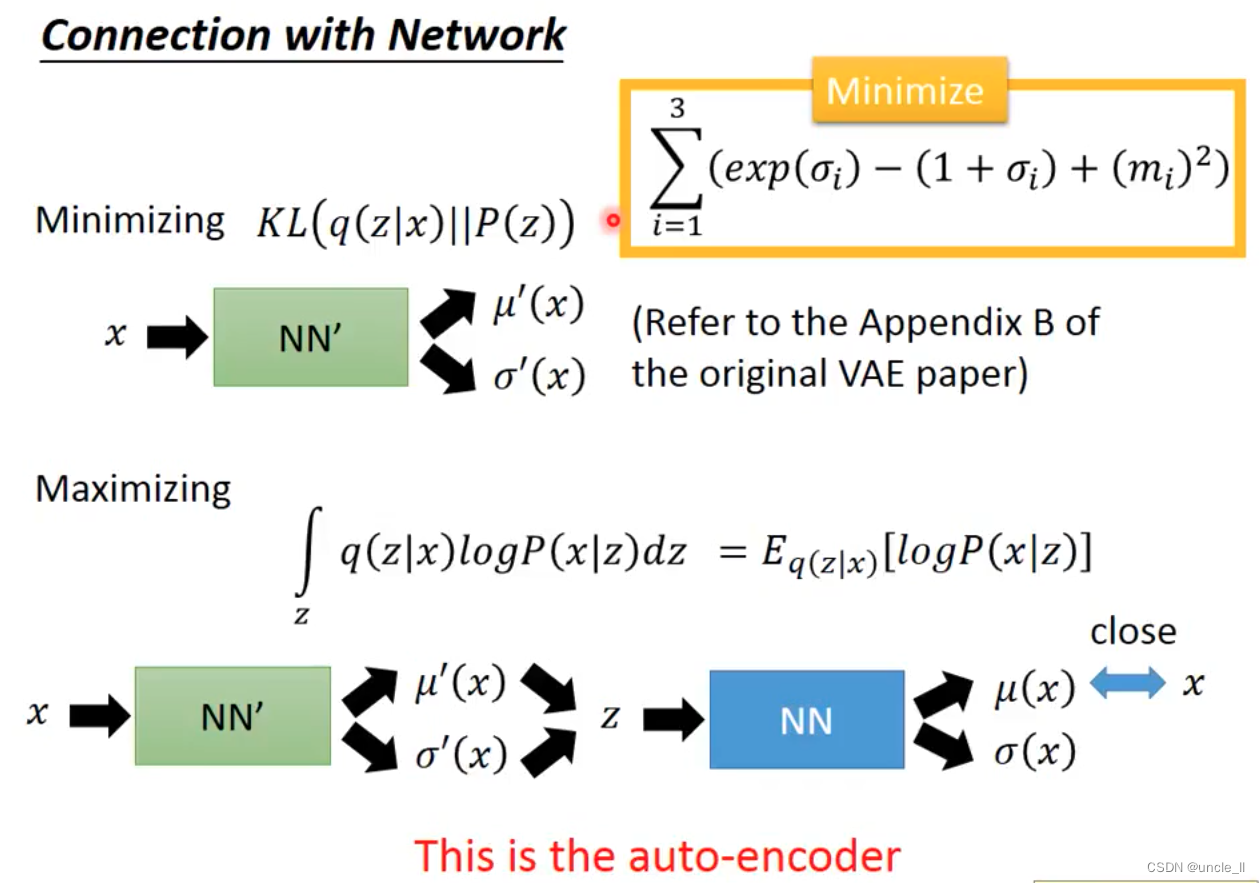
loss有两项,第一项是重构错误要小,第二项是中间层的三个变量关系也要小。
生成结果
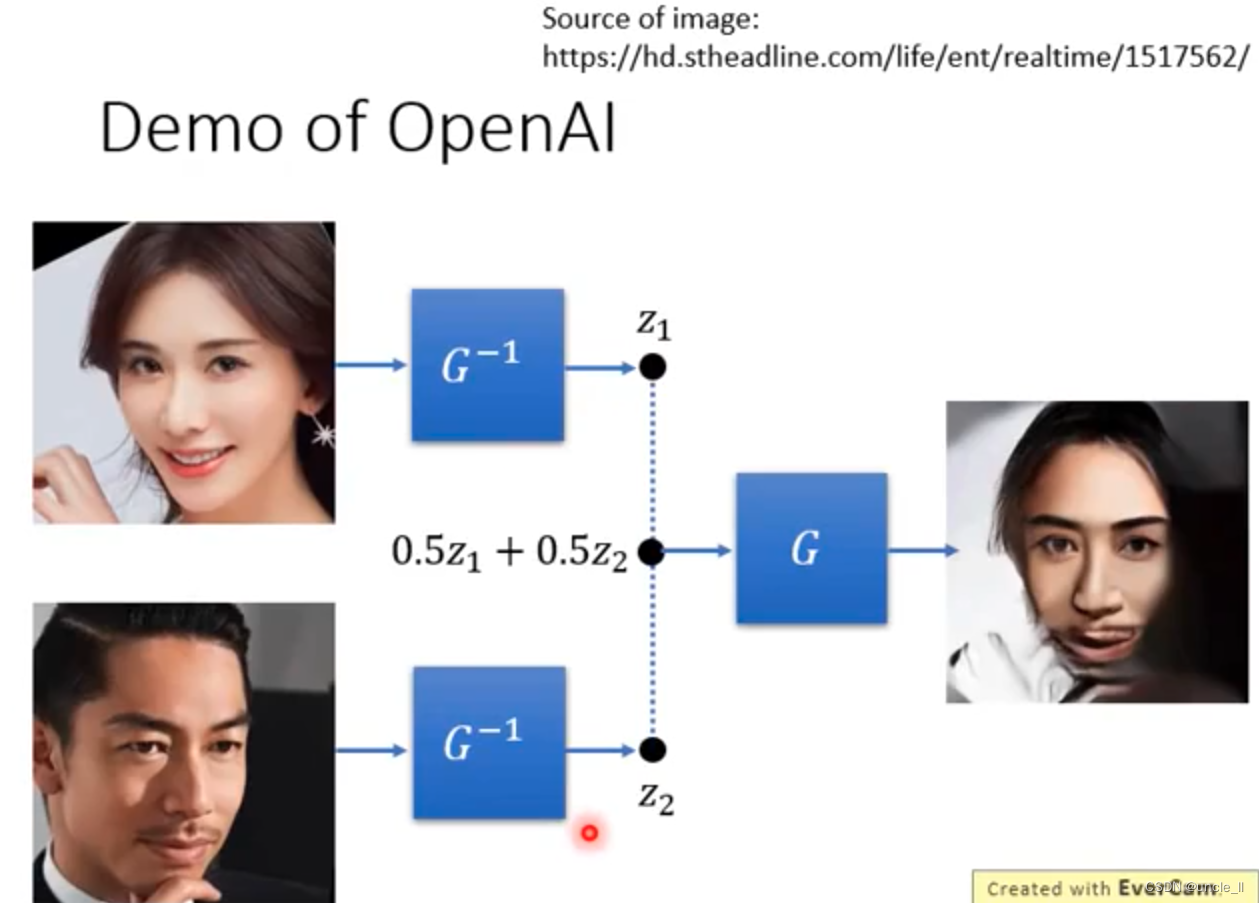
图像生成

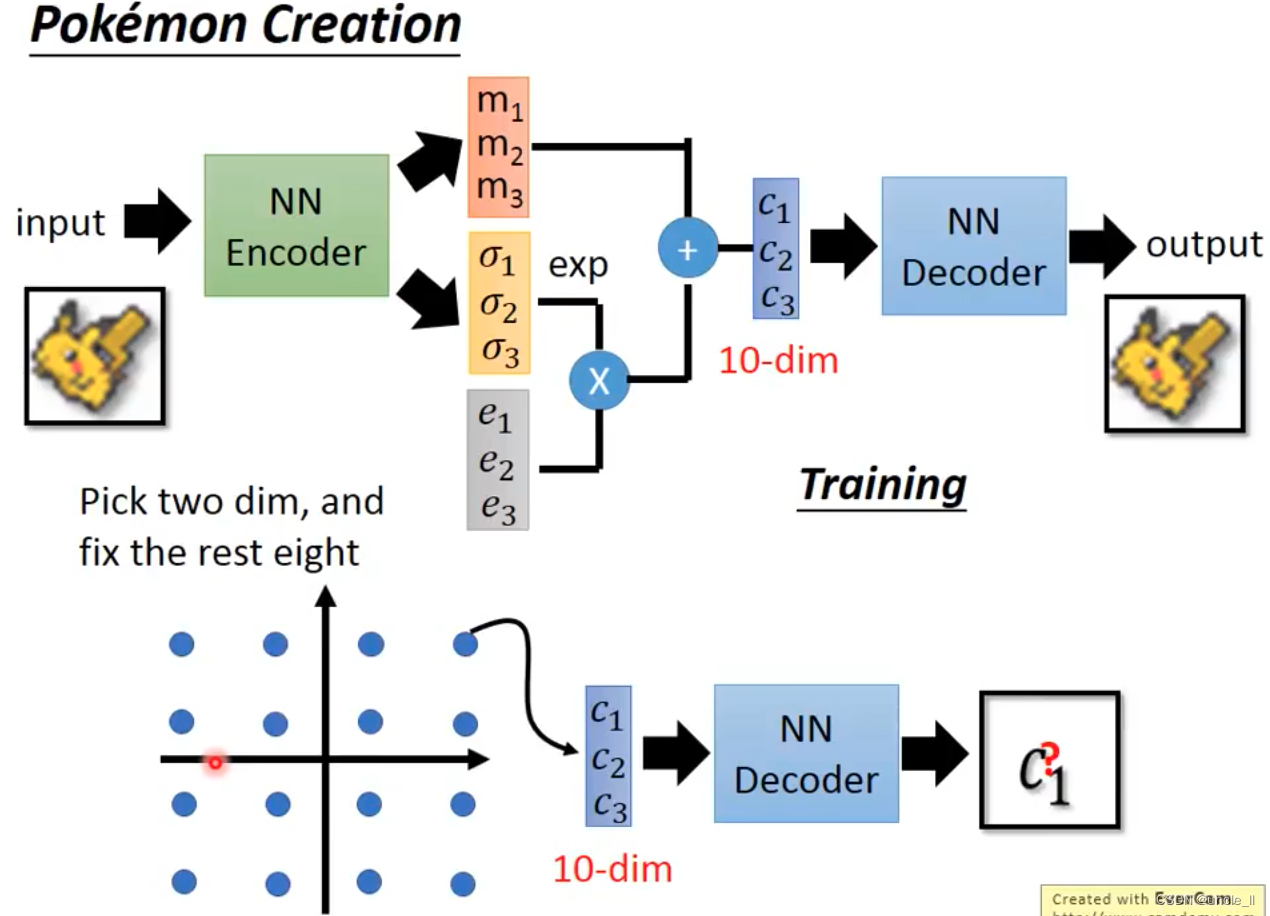
固定8个dim,而从中随机改变两个dim,这样能观察每个dim对生成效果的影响,所以每个dim当作一个控制调整变量,可以调整生成效果。


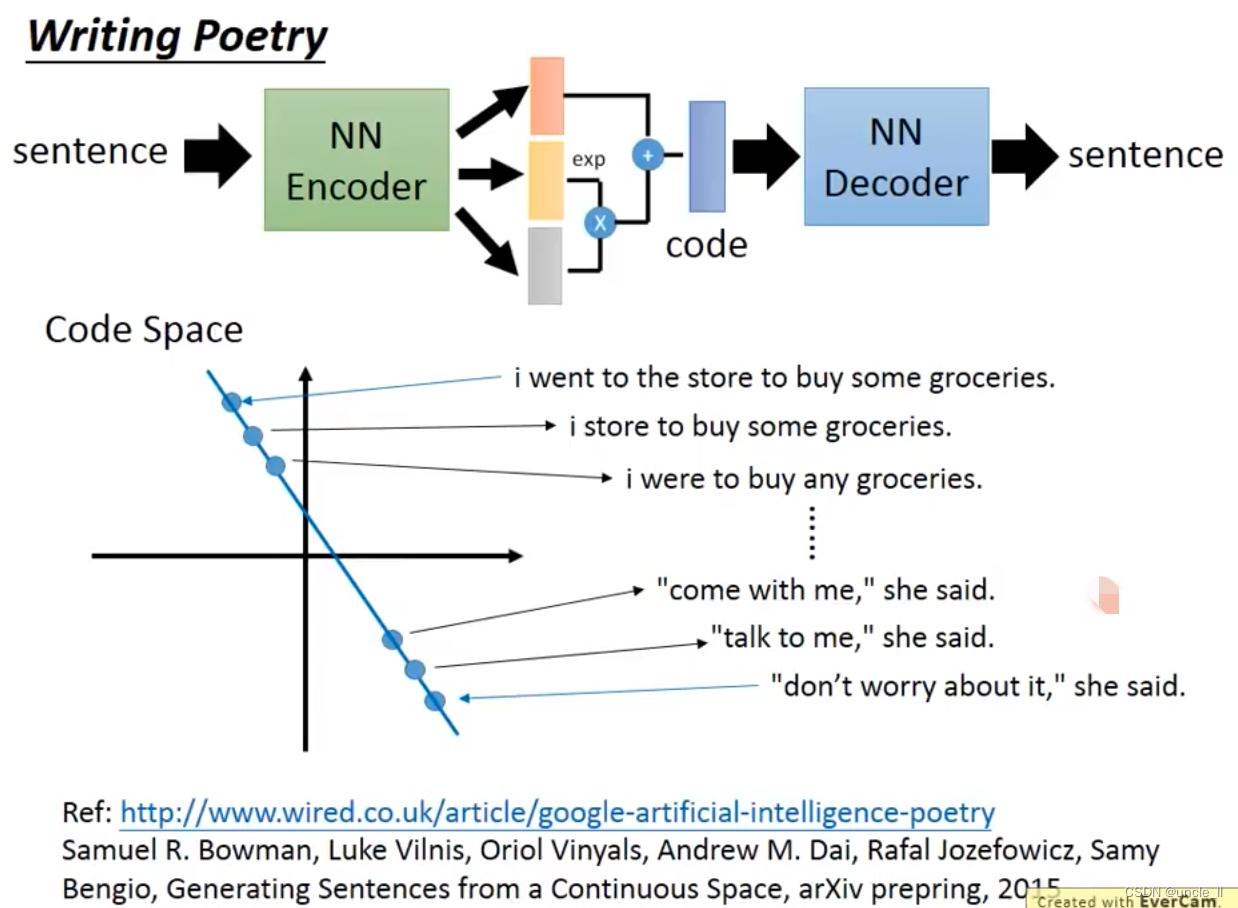
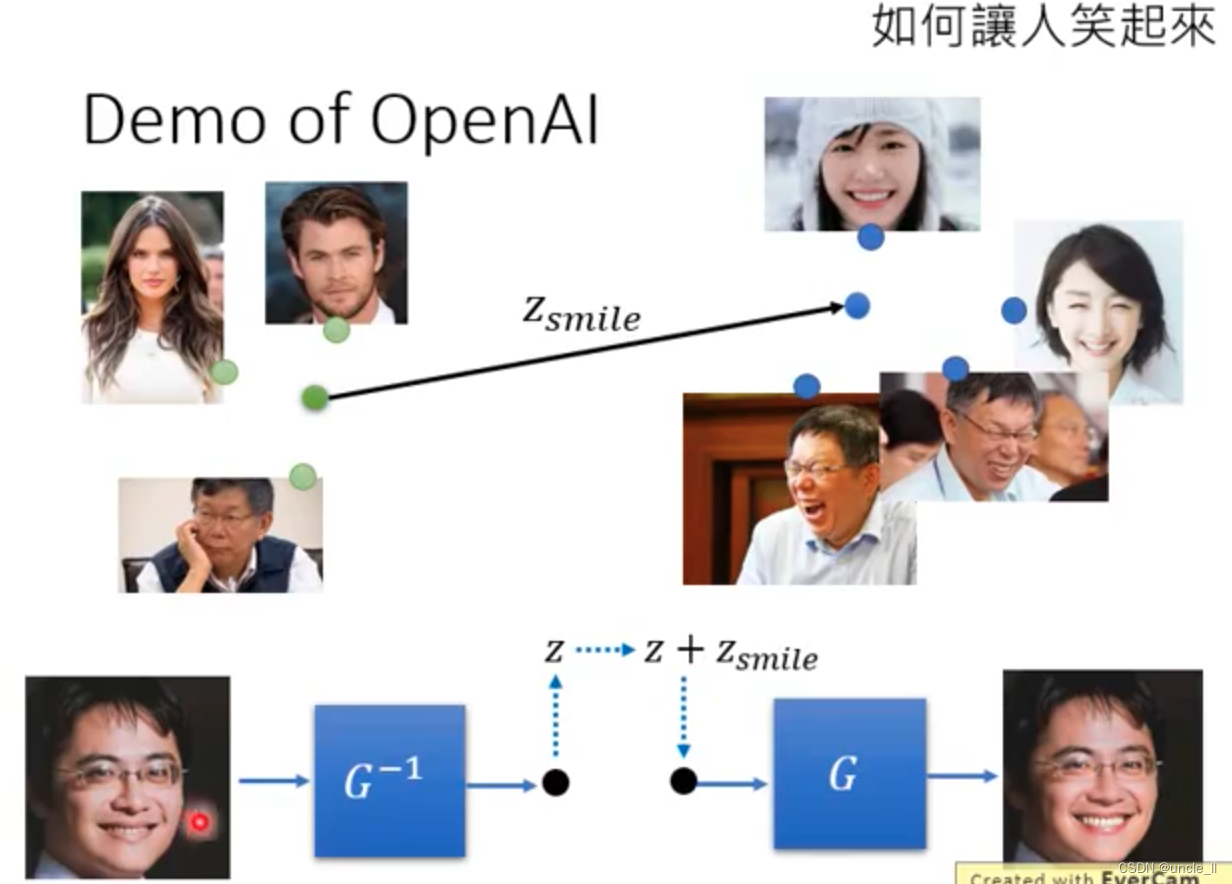
write poetry
也可以让机器写诗,空间稍微变一下,输出也不一样
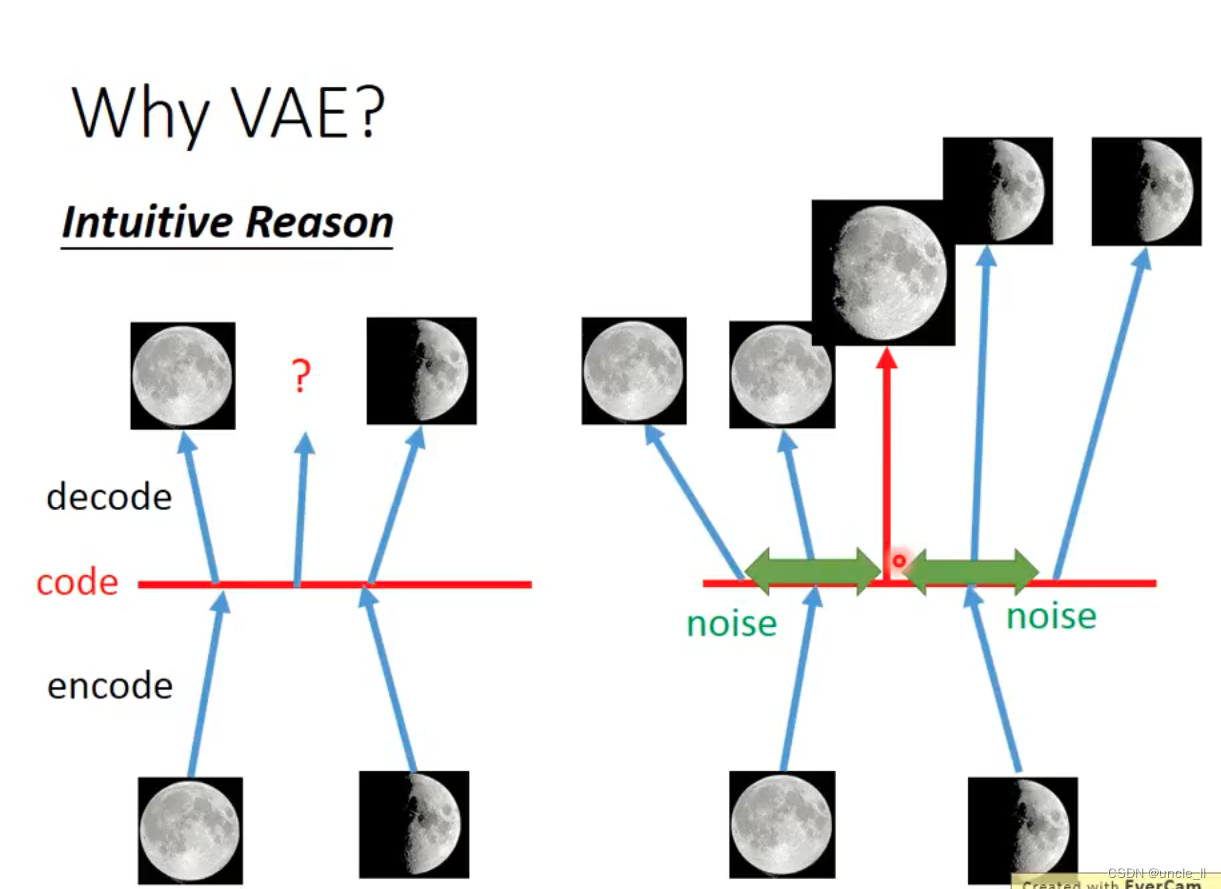
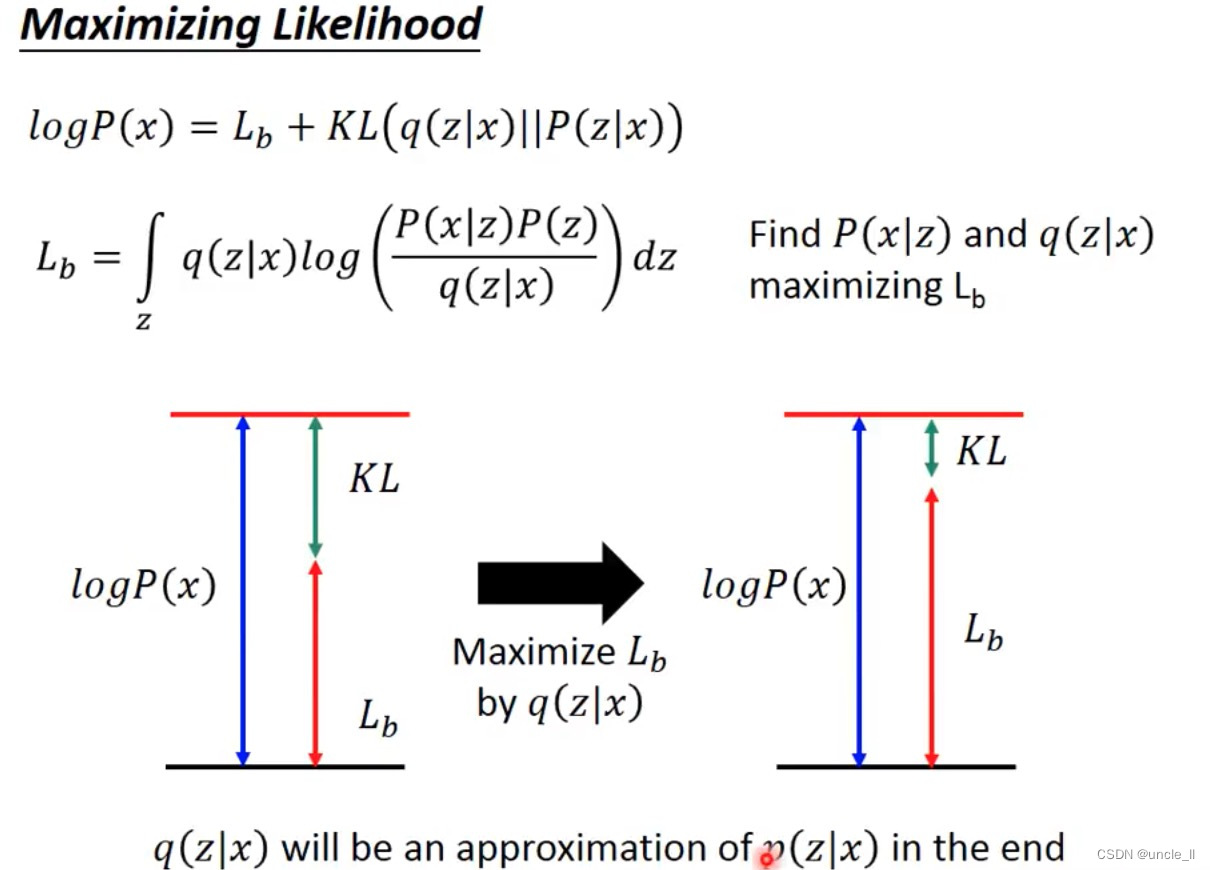
Why VAE
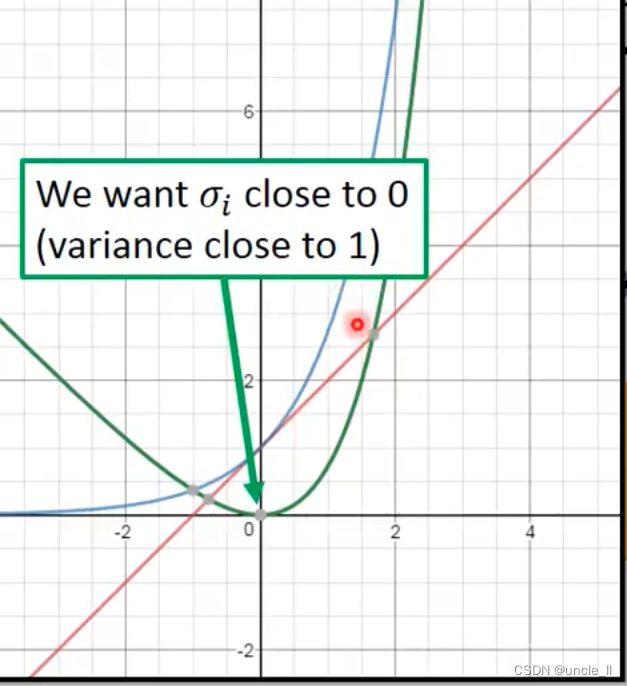
exp是蓝色线,1+delta是红色线,二者相减是绿色的线,后面那一项是L2正则
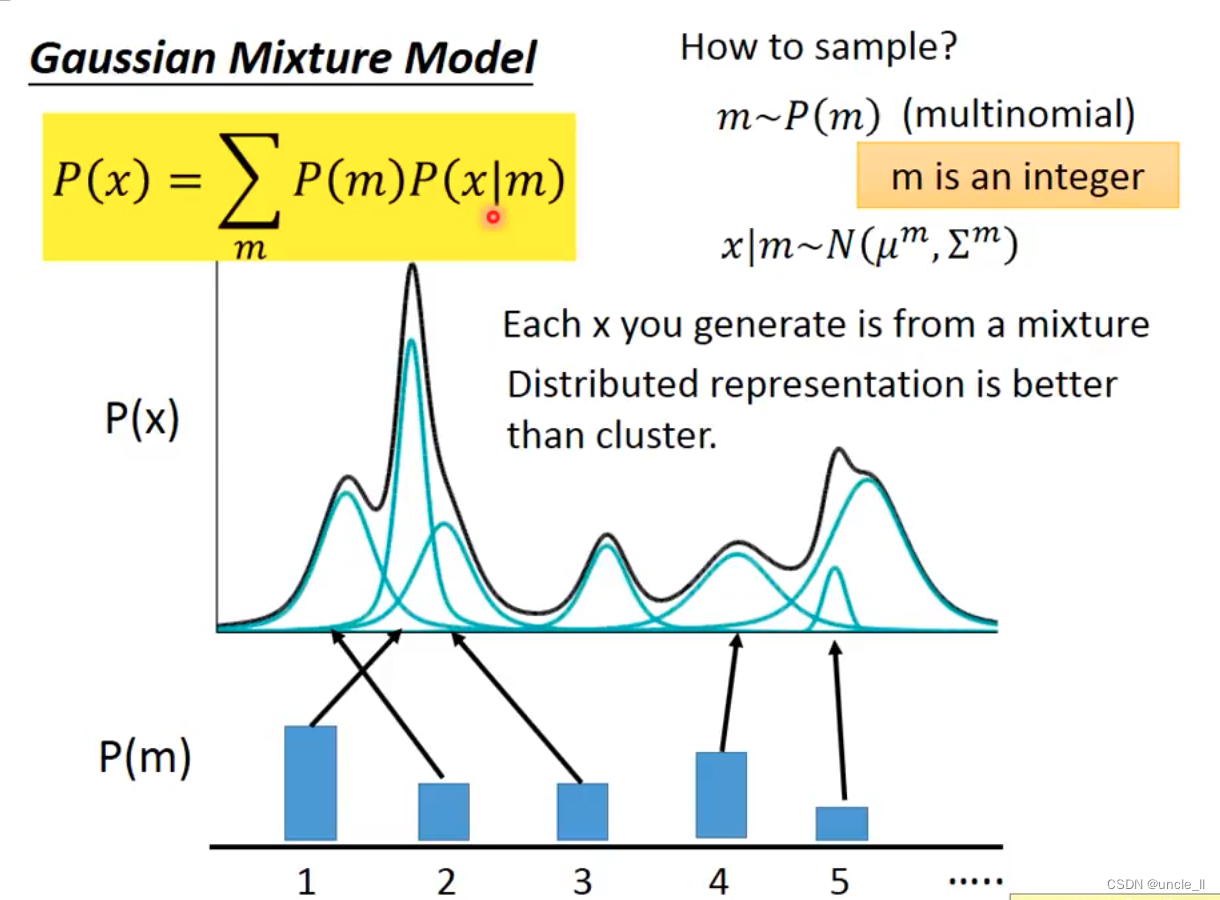
- 第一步先基于权重找到应该选哪个高斯分布
- 第二步再从该高斯分布中随机生成
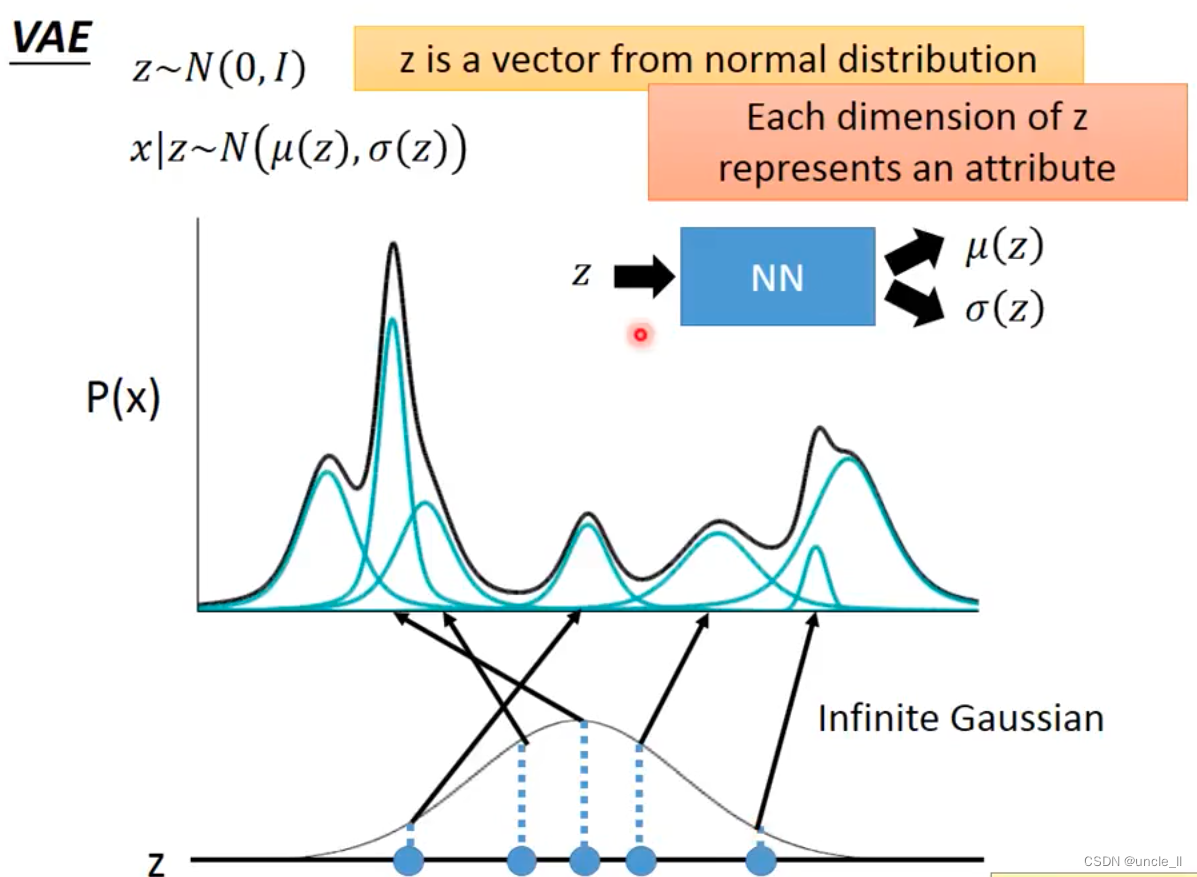
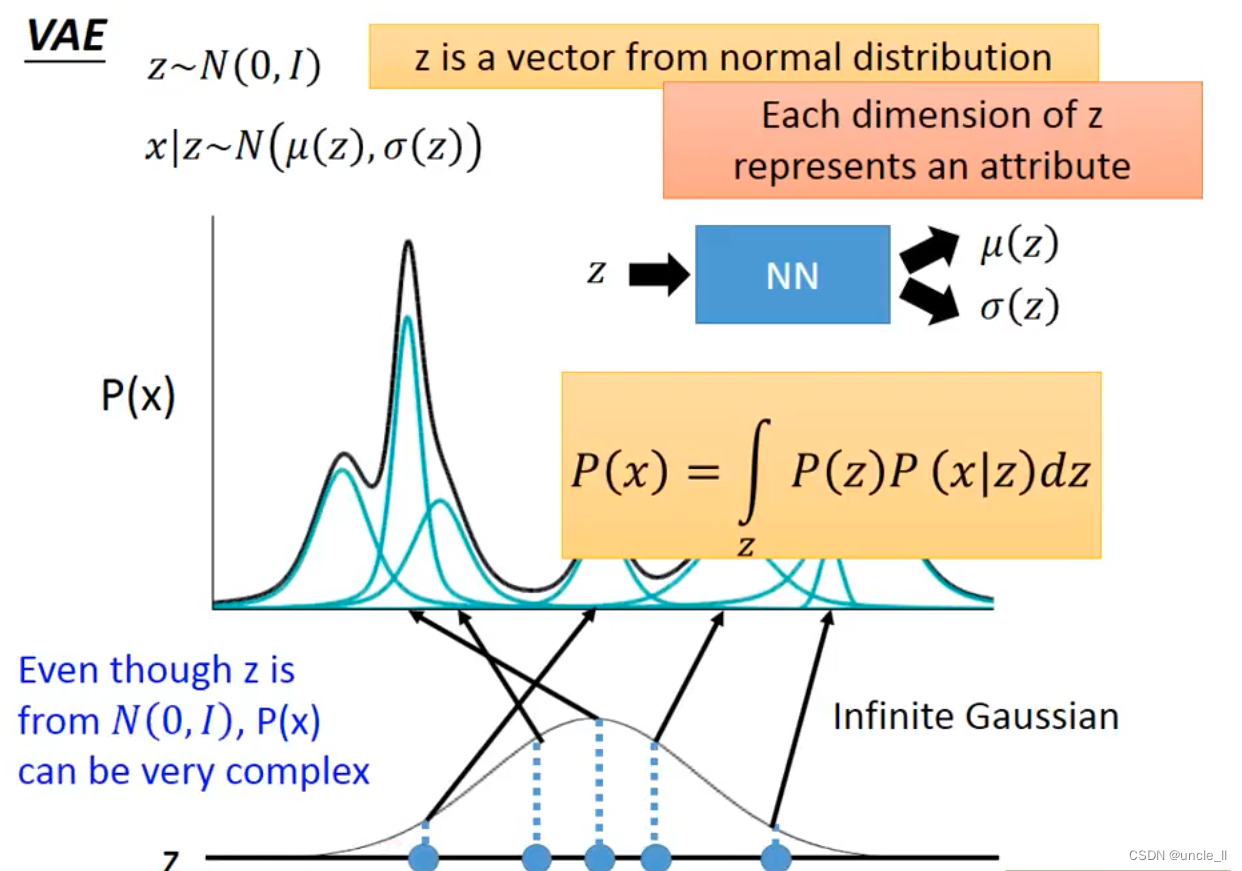
每个分布大多数是一个高斯分布,积分算得P(x)
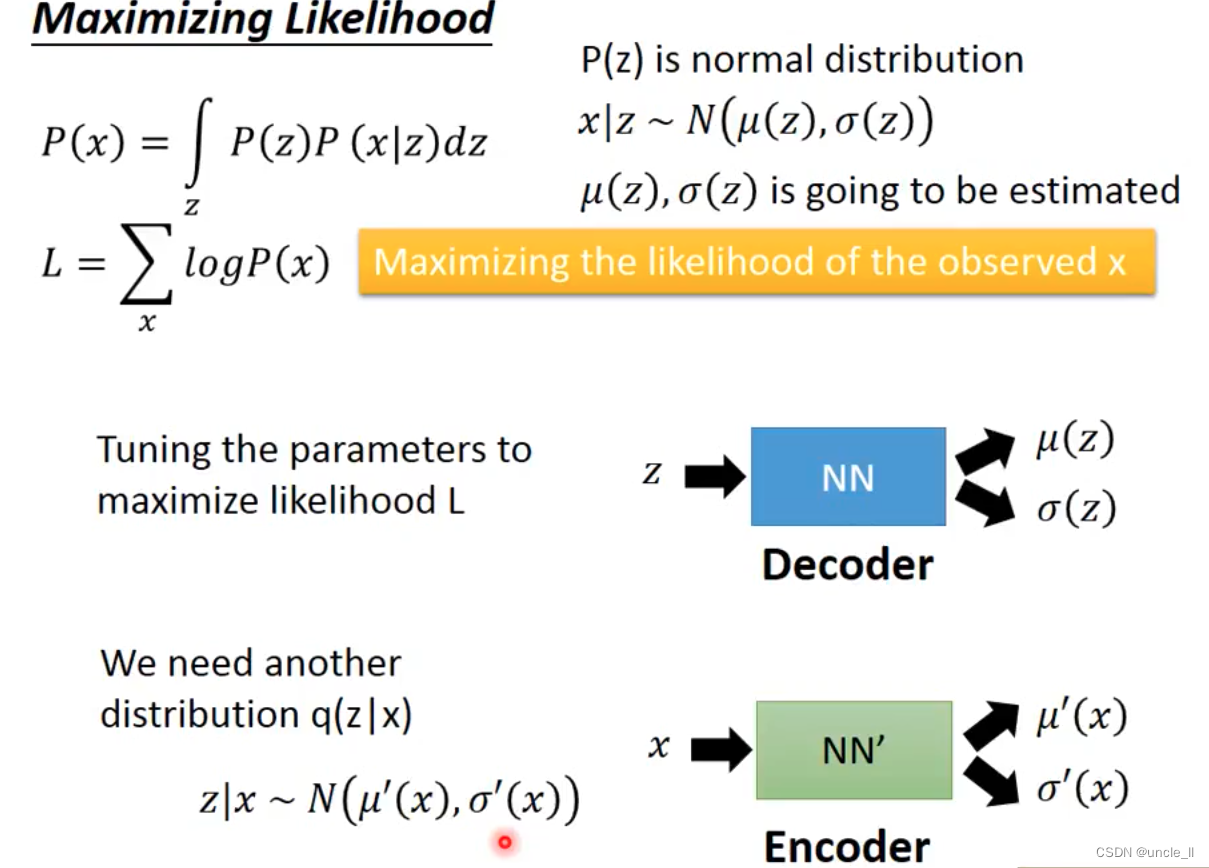



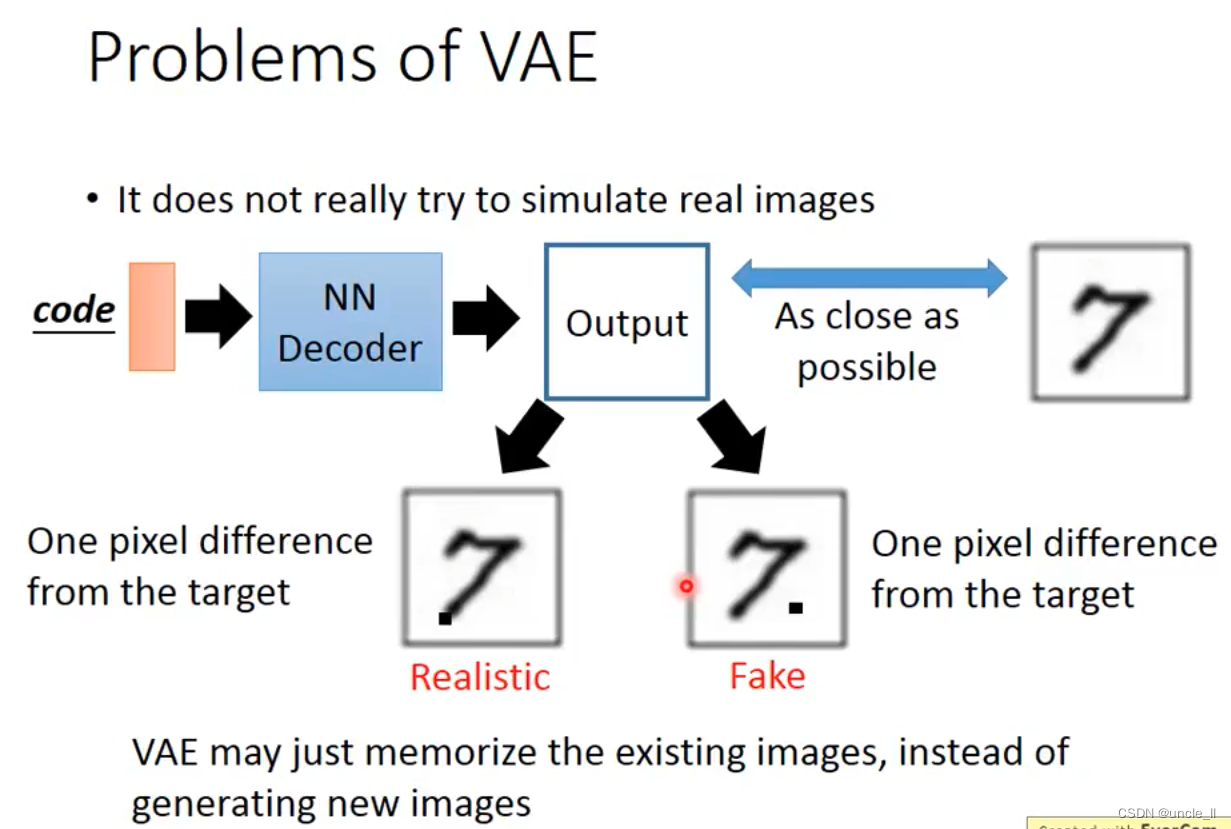
VAE的问题是可能只是记得现有的图像,生成的图像可能只是少量pixel值不一样而已
GAN



yann lecun 那时候说GAN是无监督学习中最有前景的方法之一。

GAN的过程类似于生物拟态的演化,枯叶蝶和捕食鸟,互相攻防进化。
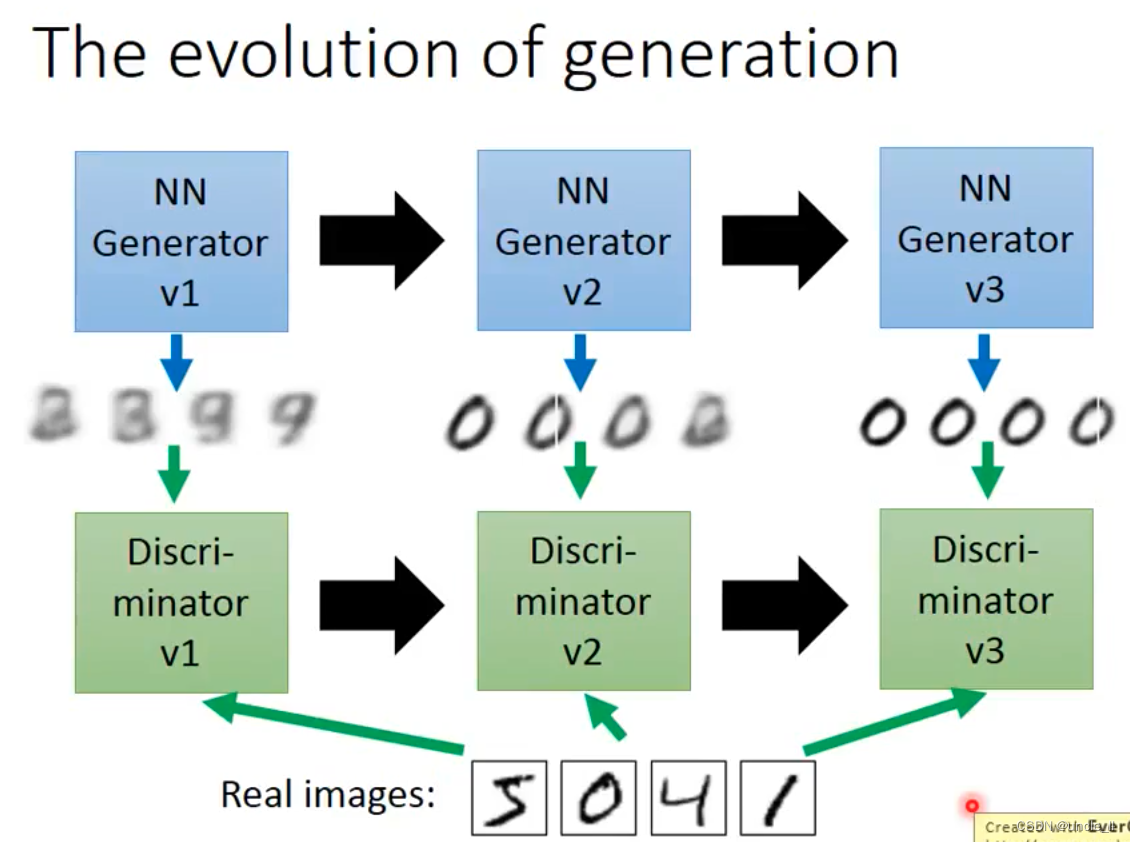
- 下一代的generator能够骗过前一代的discriminator;
- 下一代的discriminator能够区分前一代的generator;
generator是没有见过真实图片的,而discriminator是通过真实样本训练得到的。
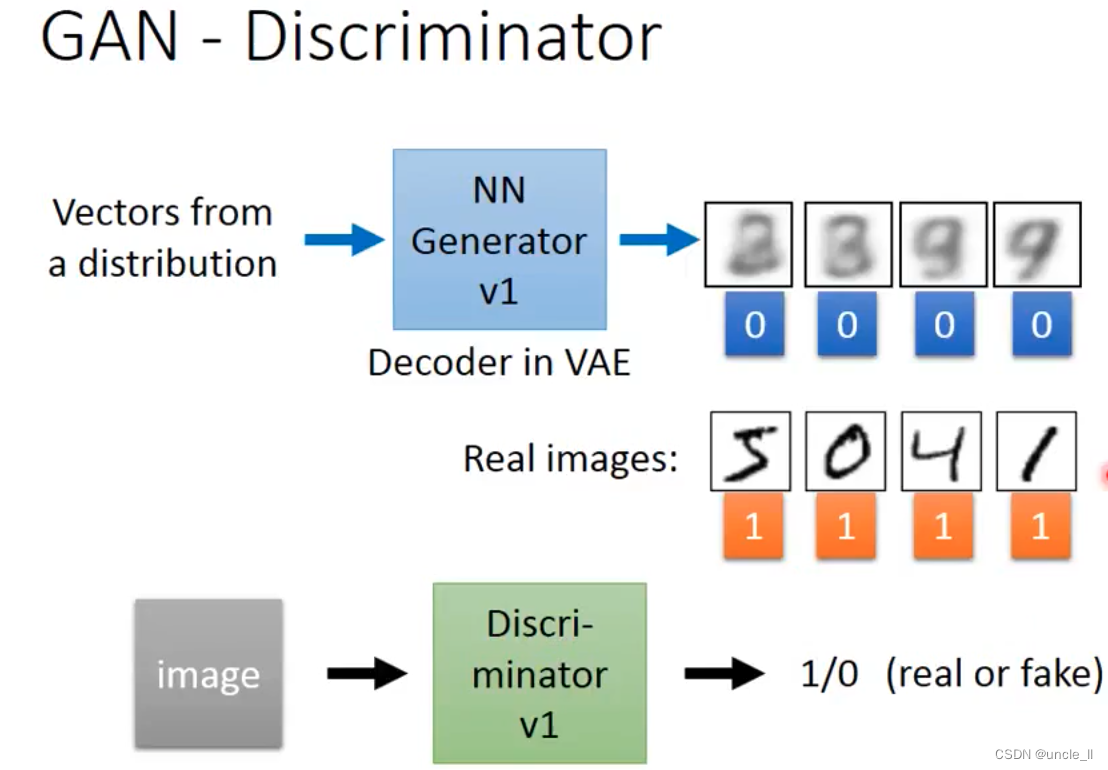
- 0: fake
- 1: real
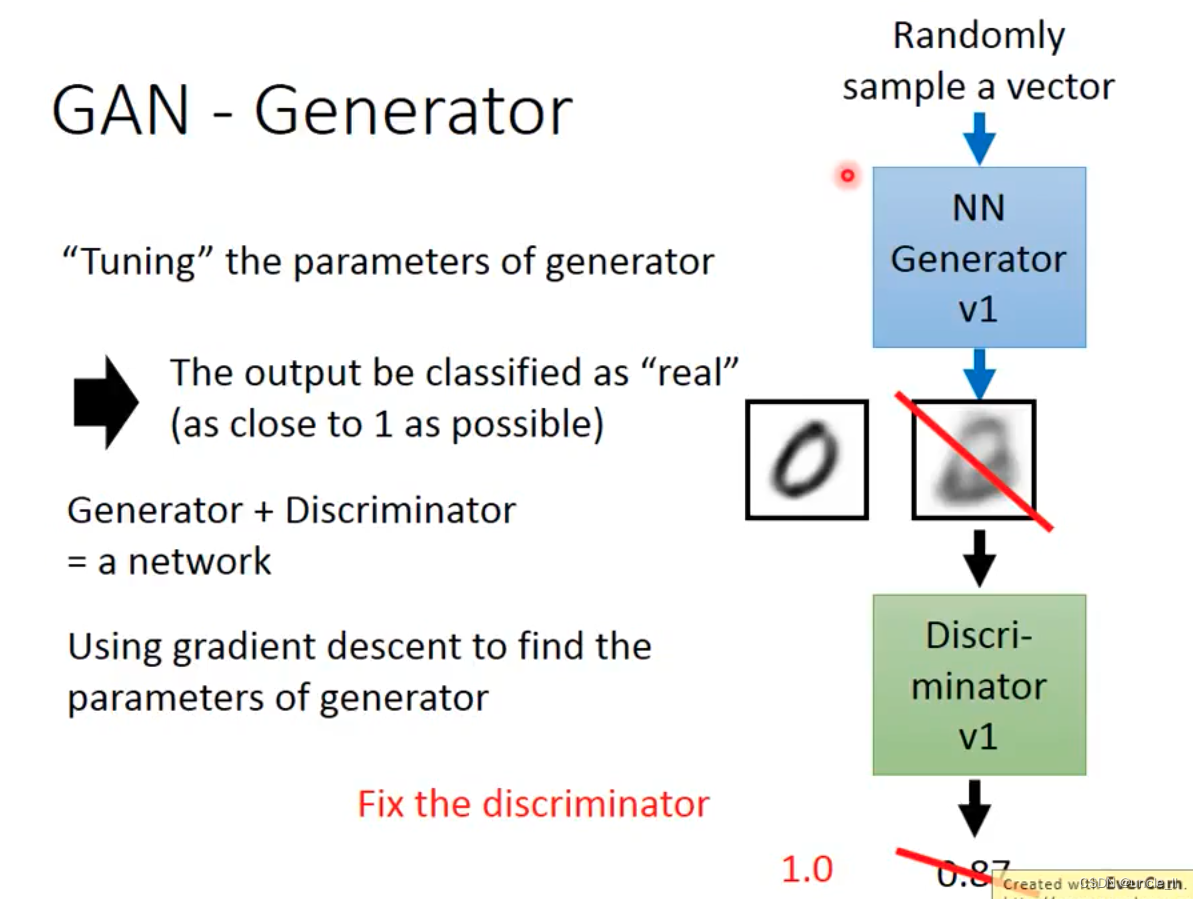
只能调generator的参数,而discriminator的参数固定住。
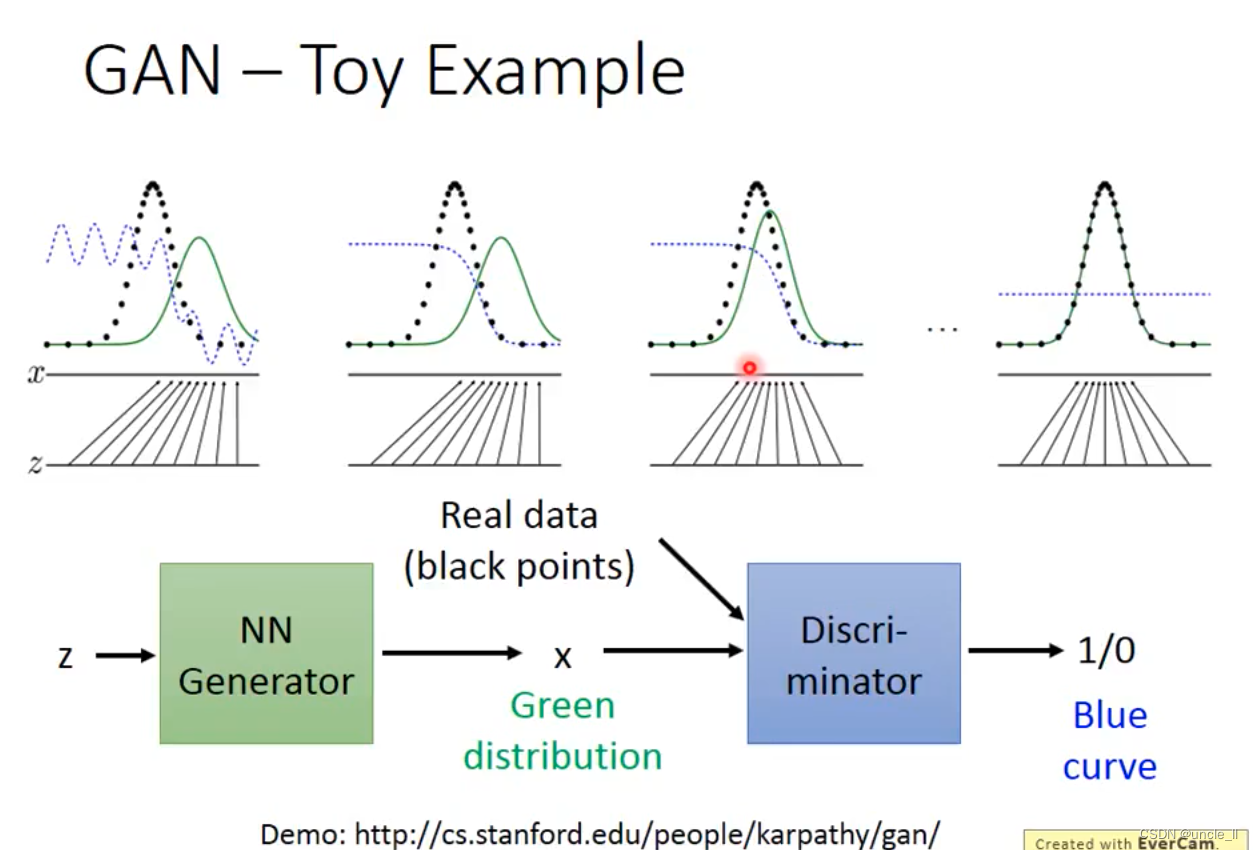
生成的分布是绿色曲线,而真实值是蓝色的曲线,尽可能让绿色曲线和蓝色曲线分布尽可能一致。genertor基于discriminator的反馈结果调整曲线分布。




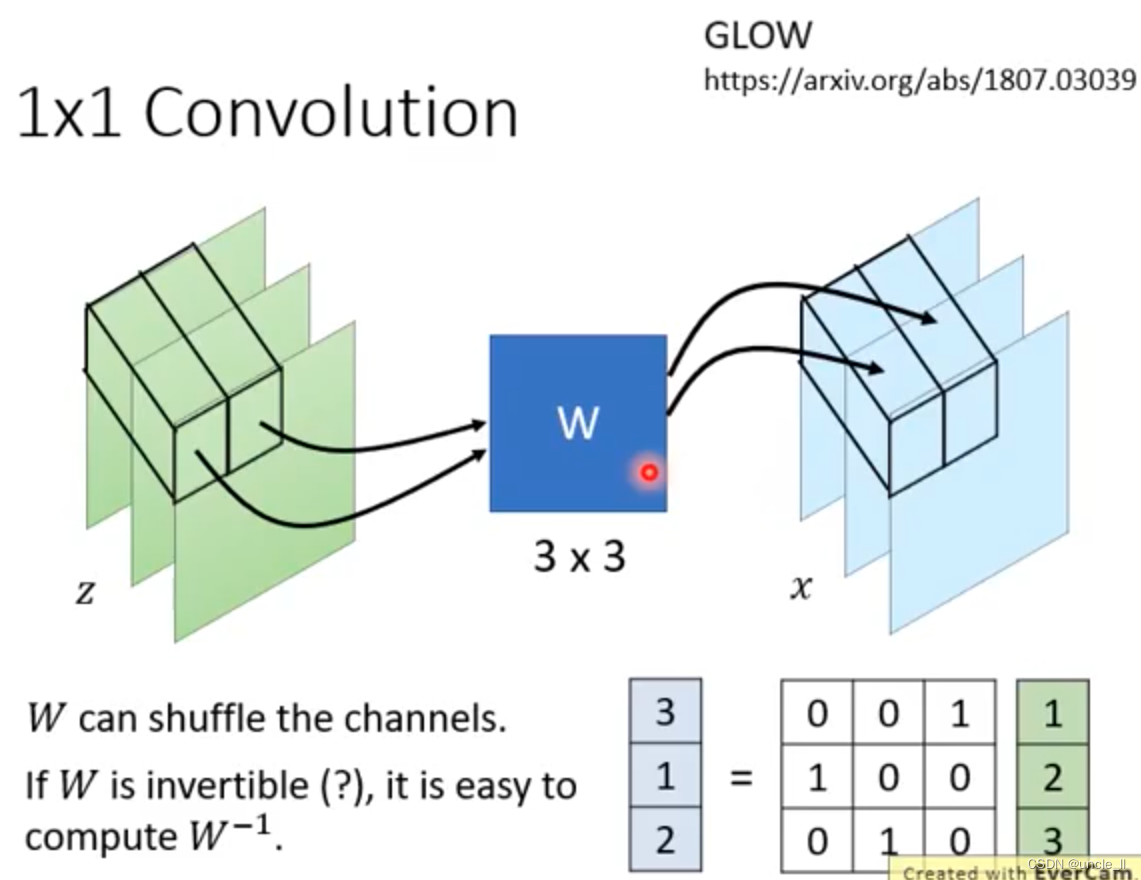
Flow-based Generative Model

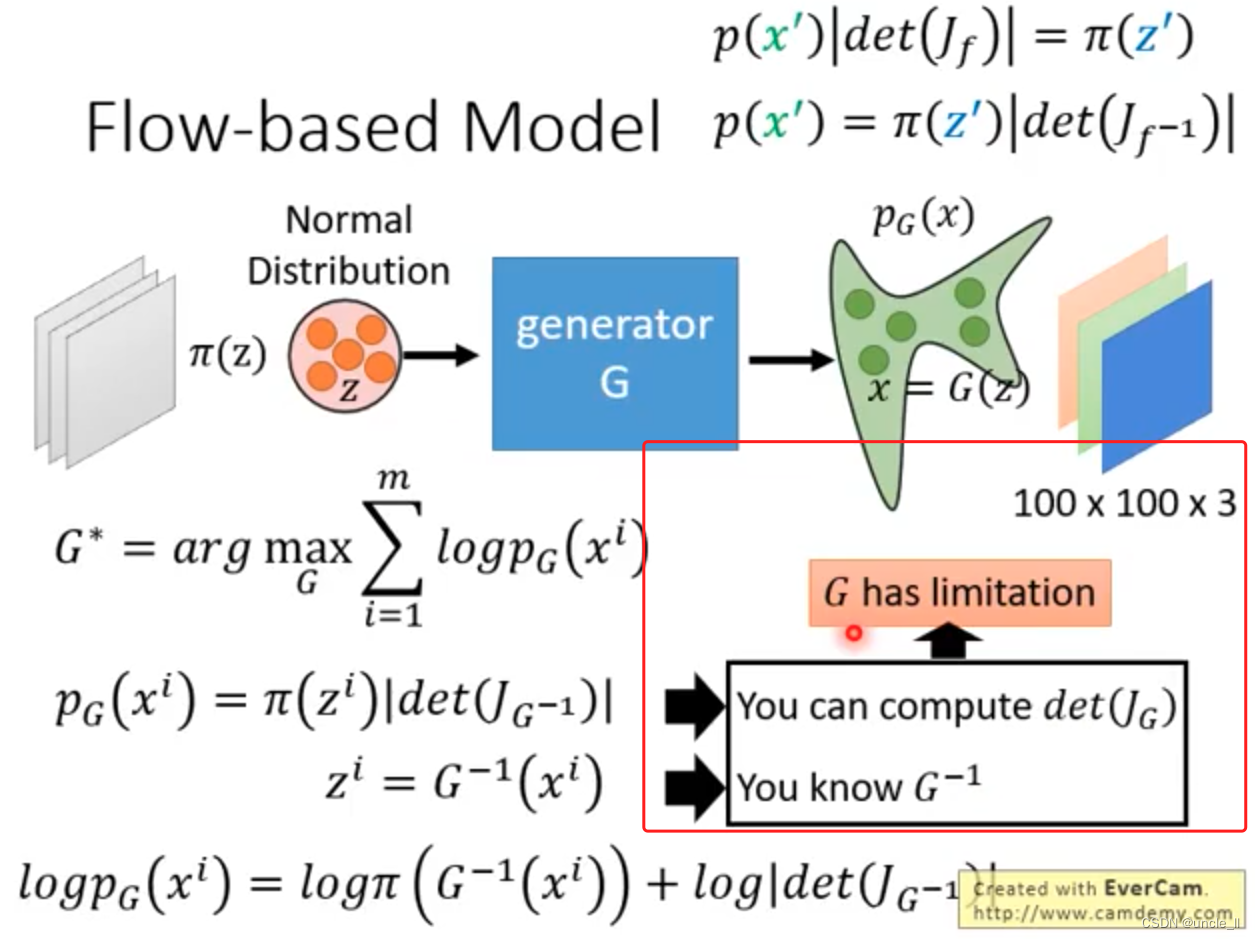
上述三个生成方法的缺点。回顾一下generator:
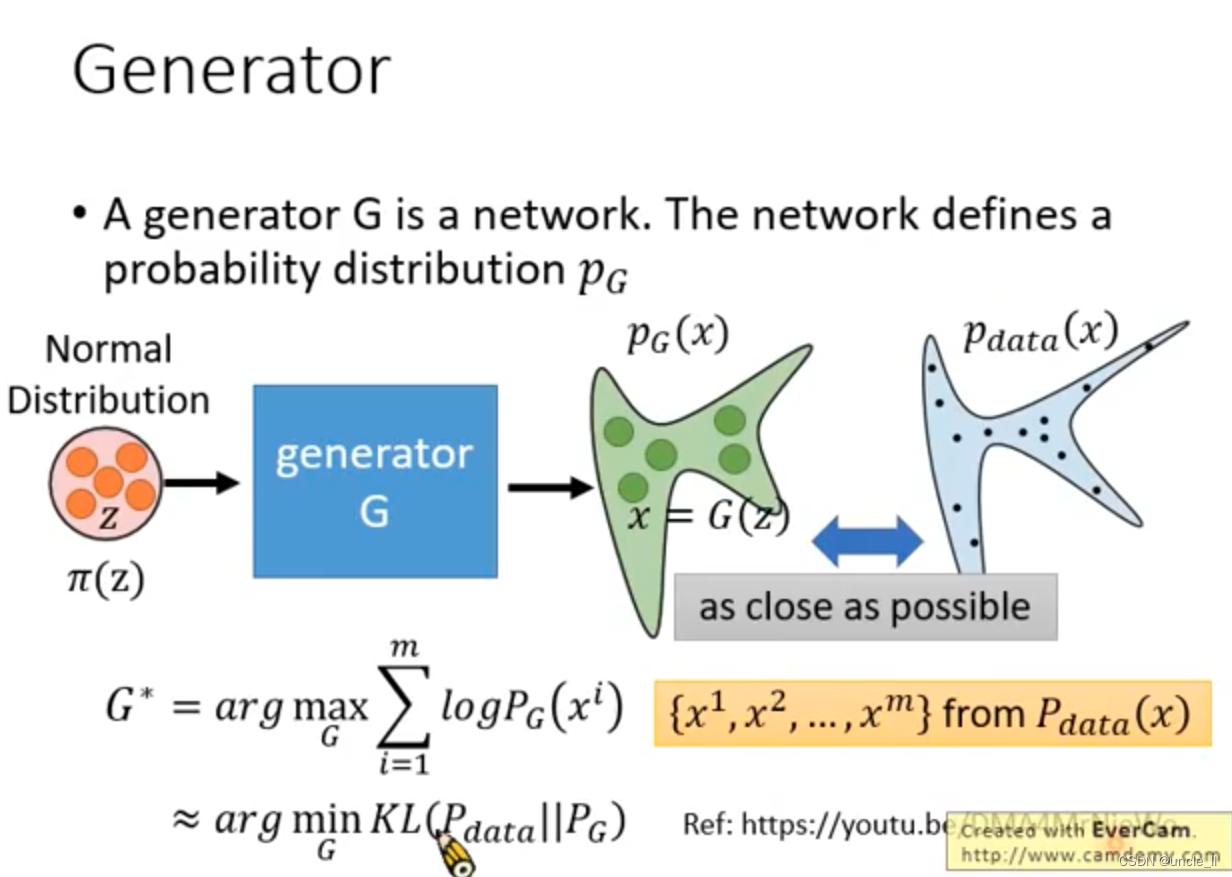
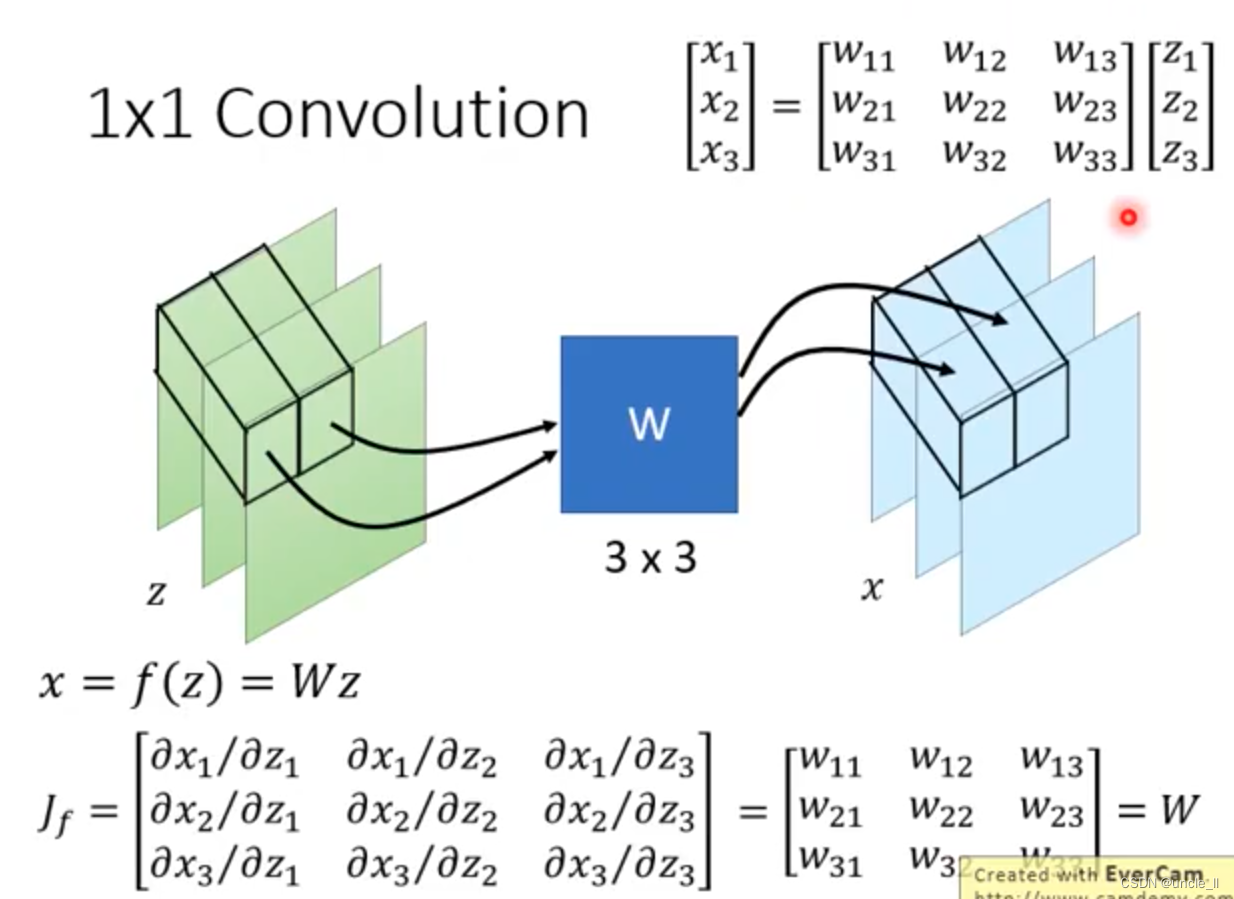
Math Background


如果函数互为invers关系, jacobian也是互为invers的关系。

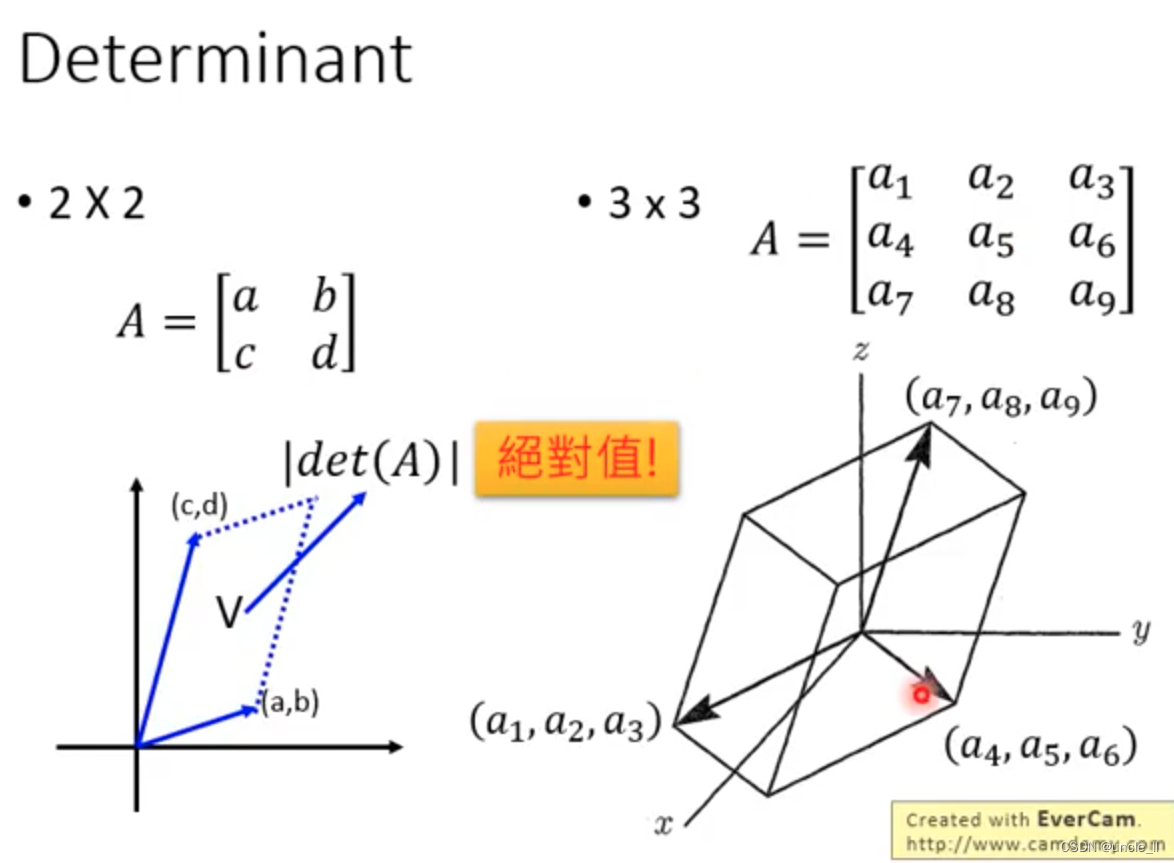
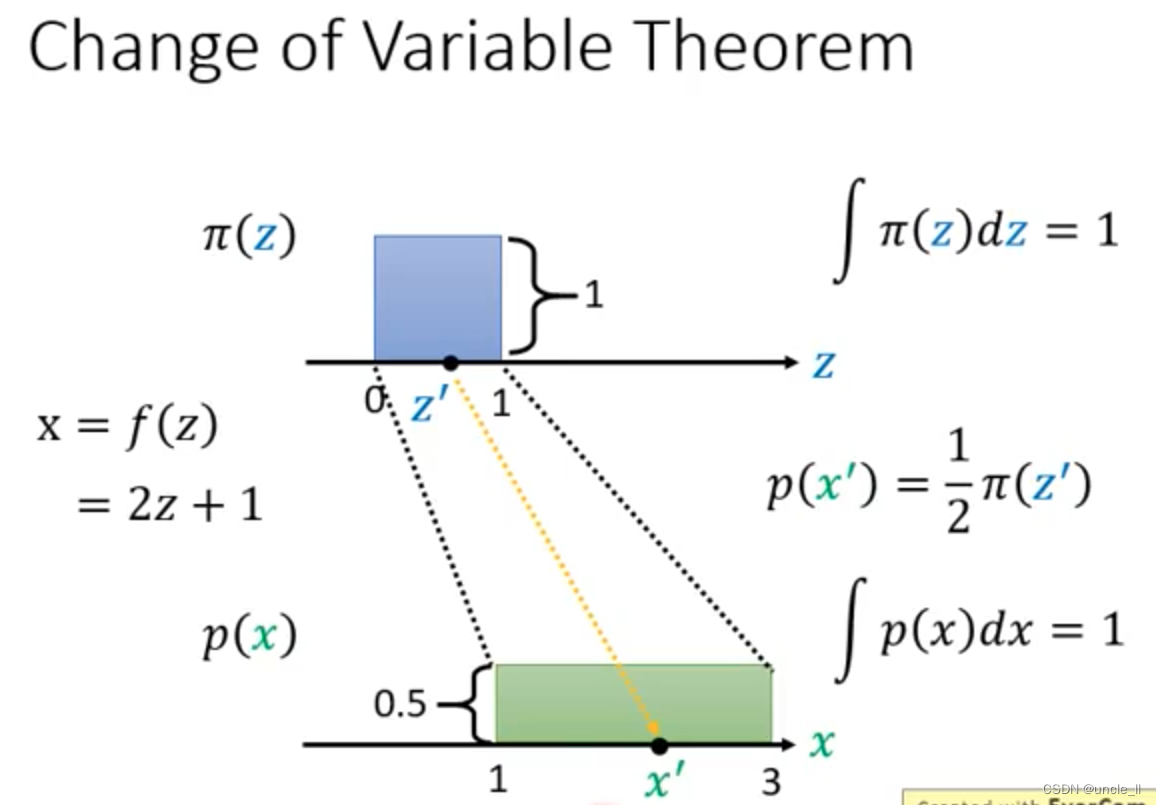
面积要一致,但是长度变长,那么高度要变矮。
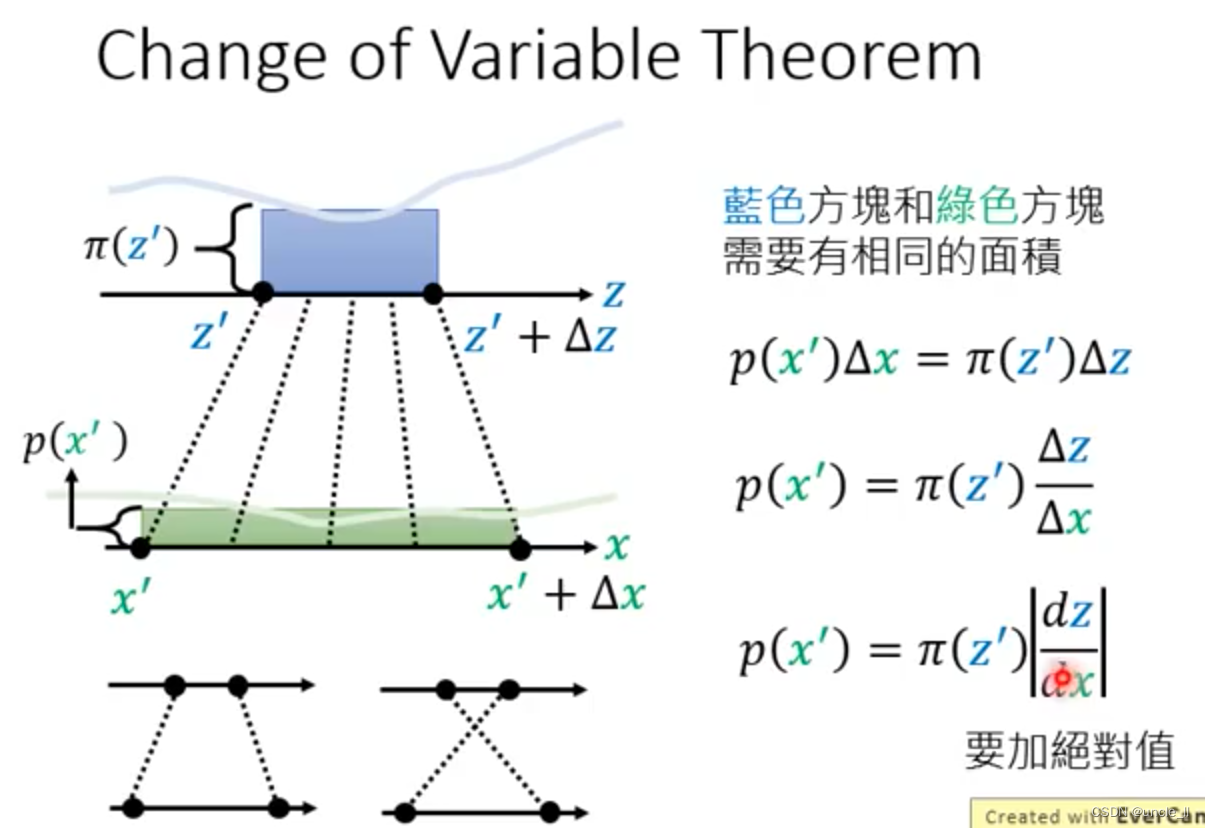
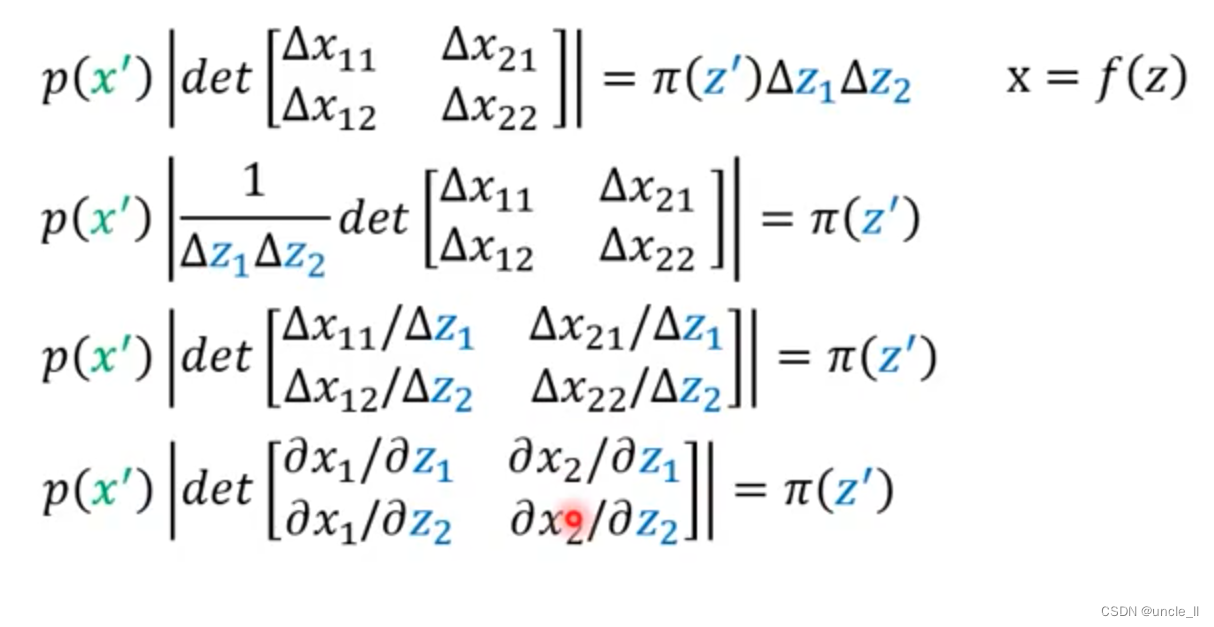
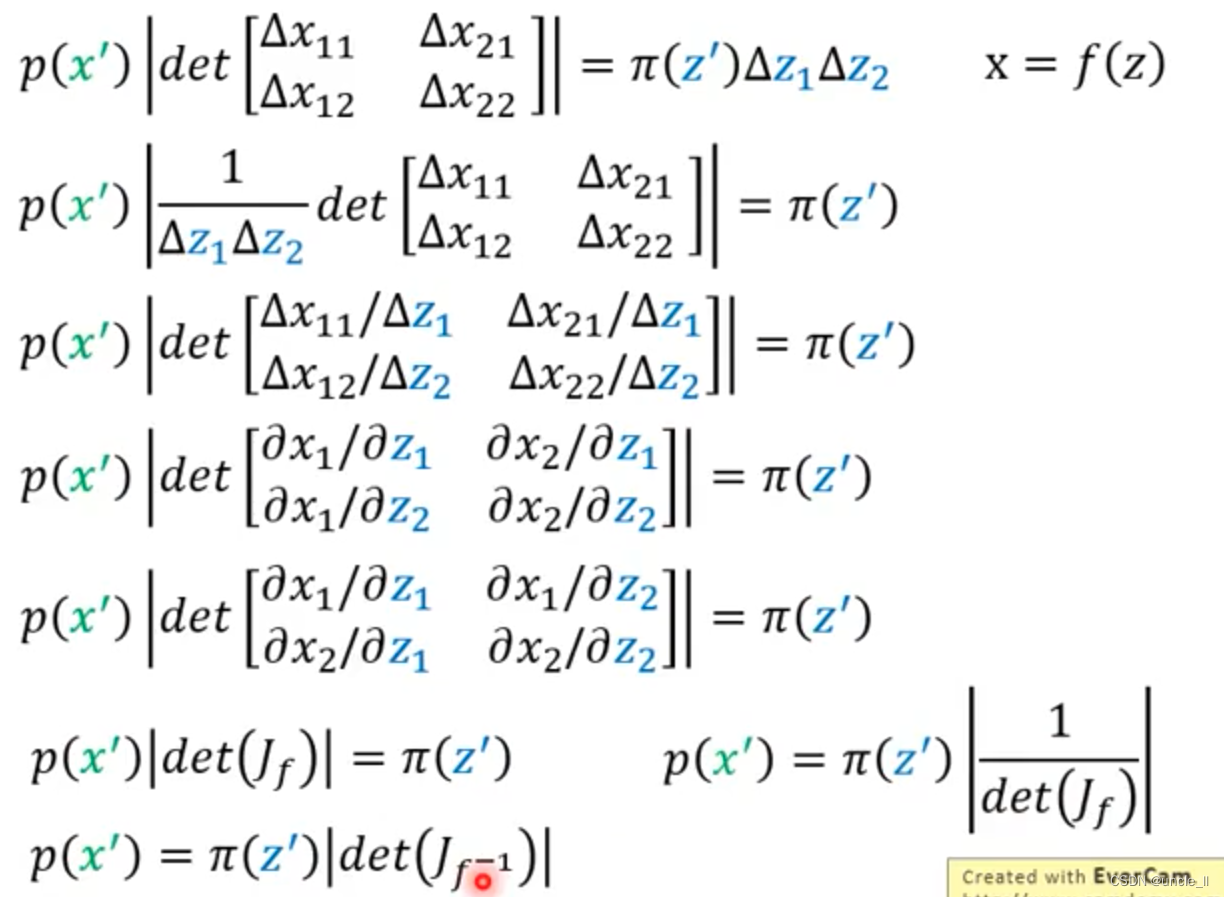
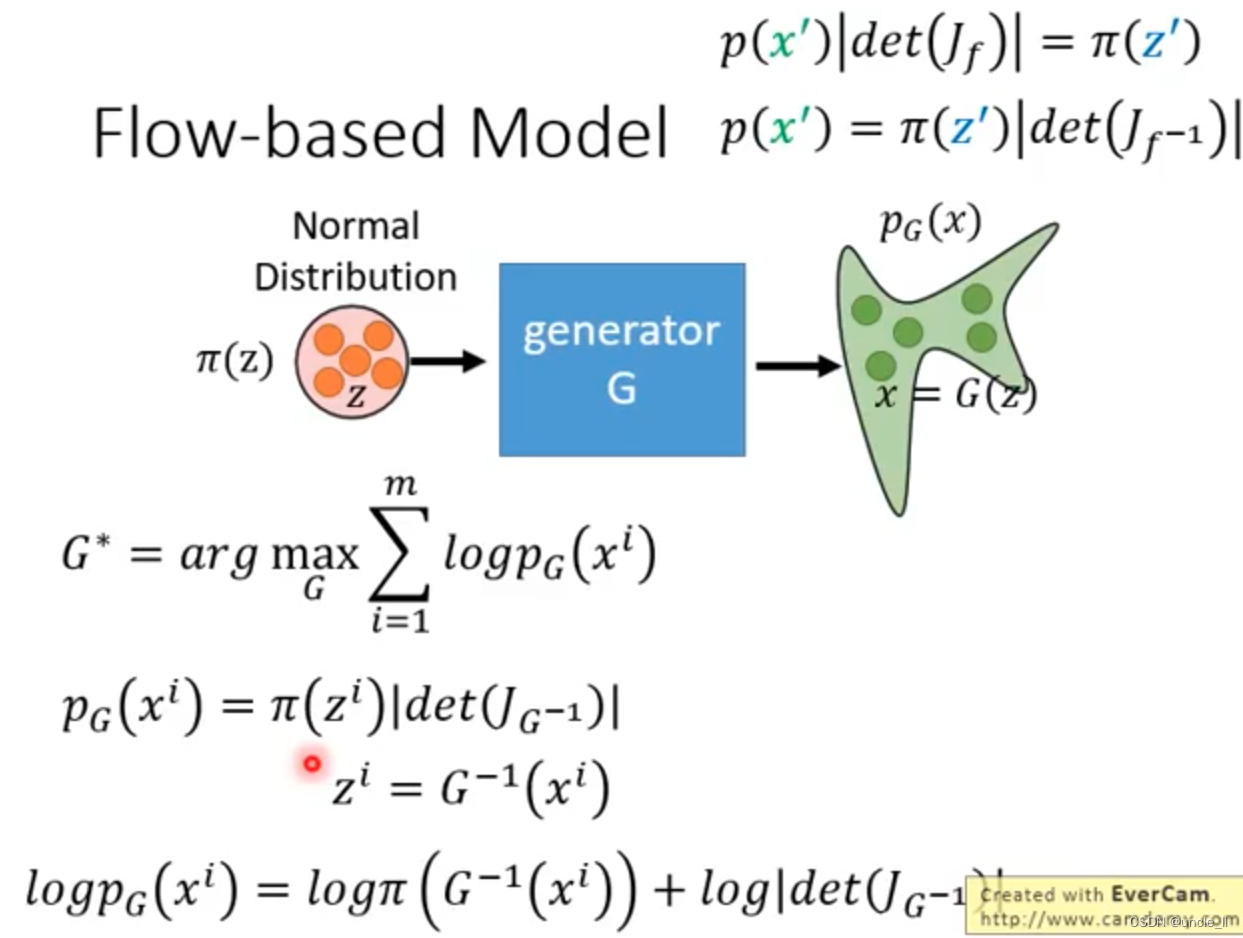
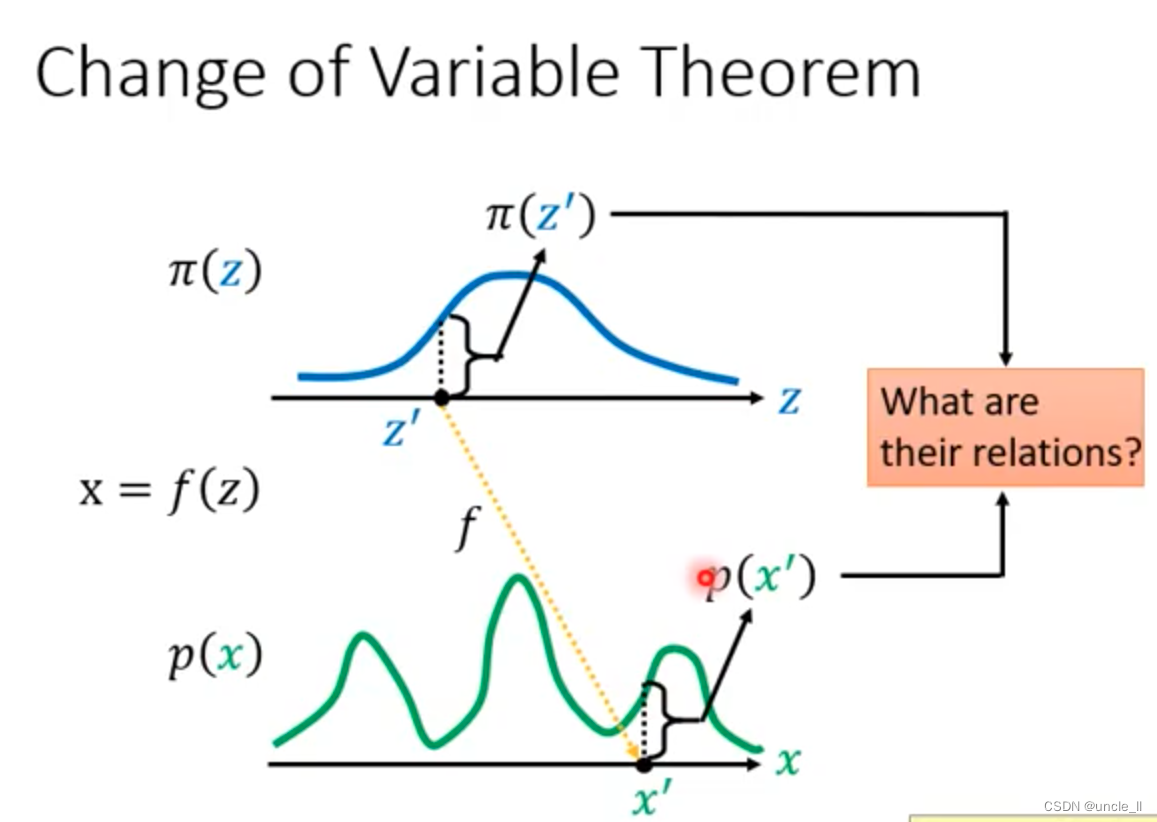
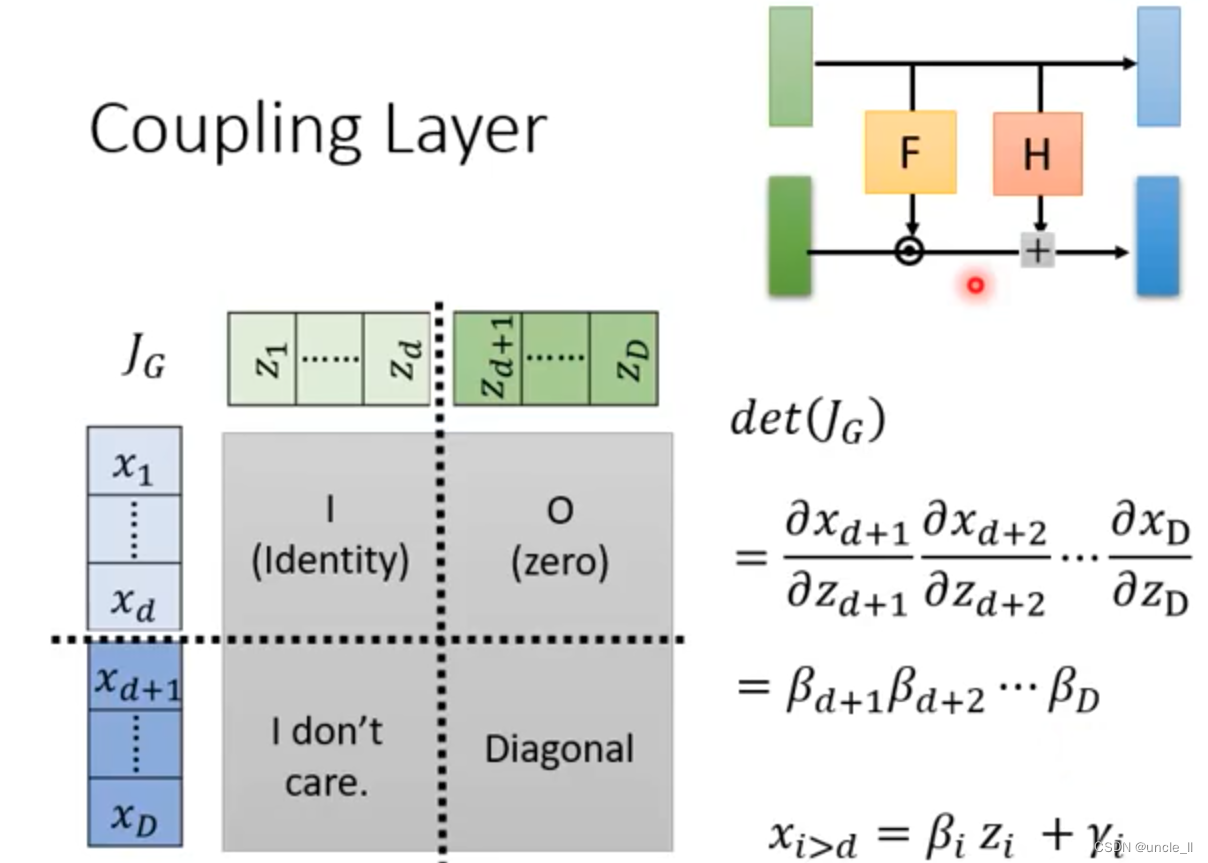
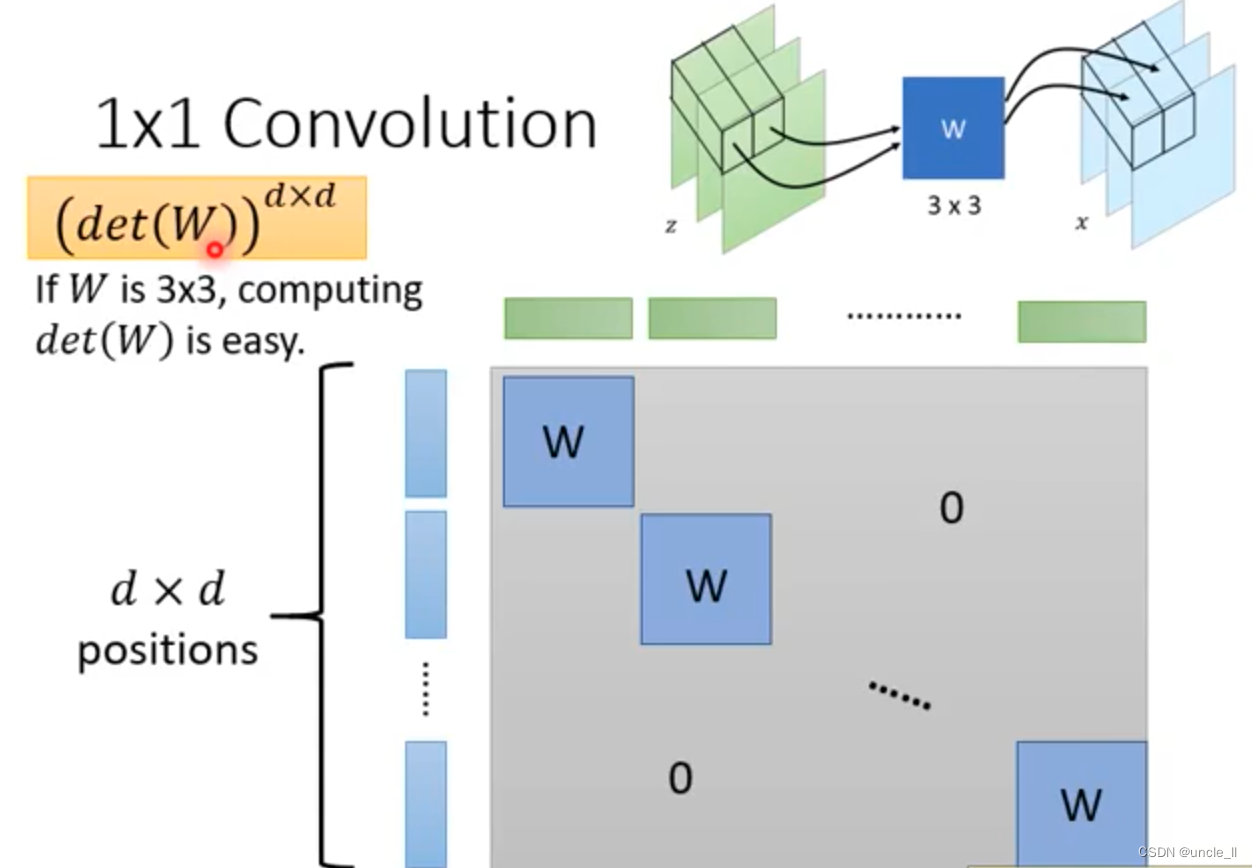
如何计算新的分布呢?需要知道
d
e
t
(
J
G
)
det(J_G)
det(JG)和
G
−
1
G^{-1}
G−1
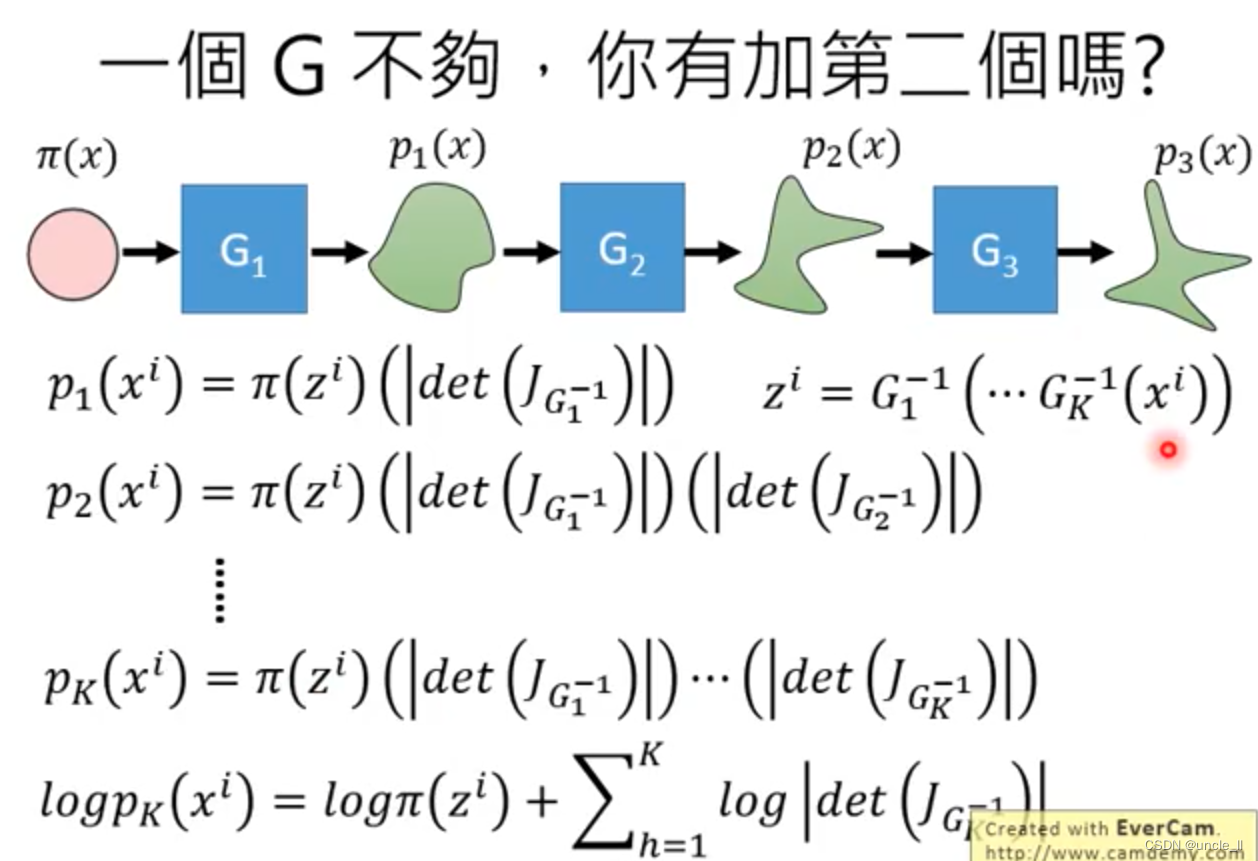
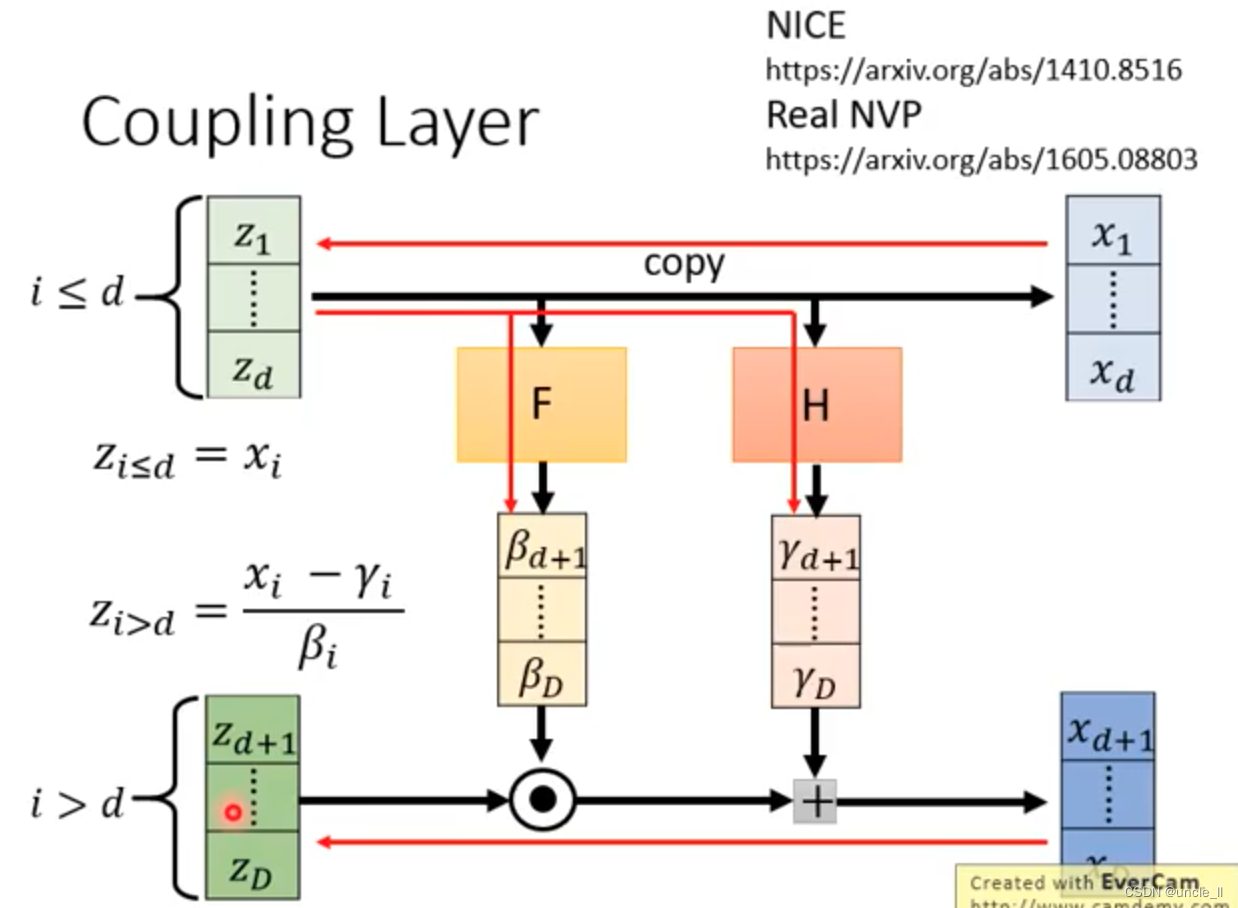
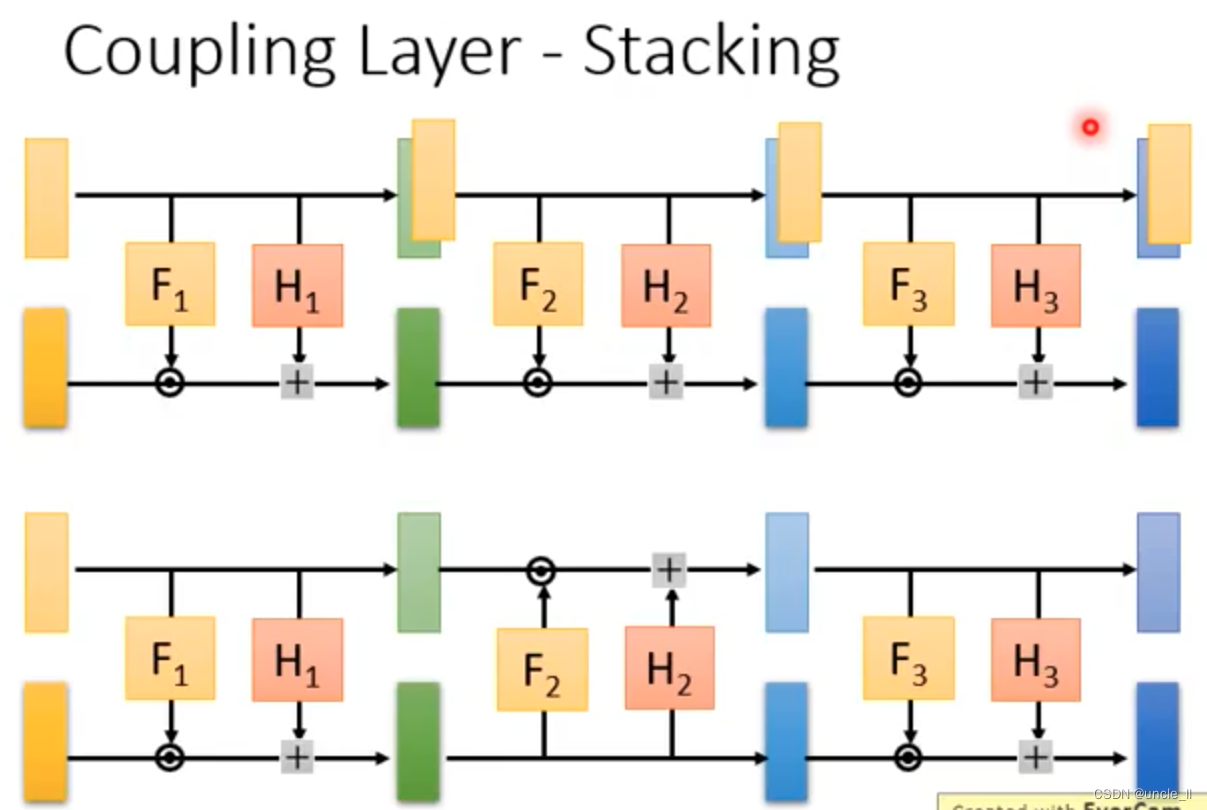
由于一个G的能力是有限的,可以增添多个G
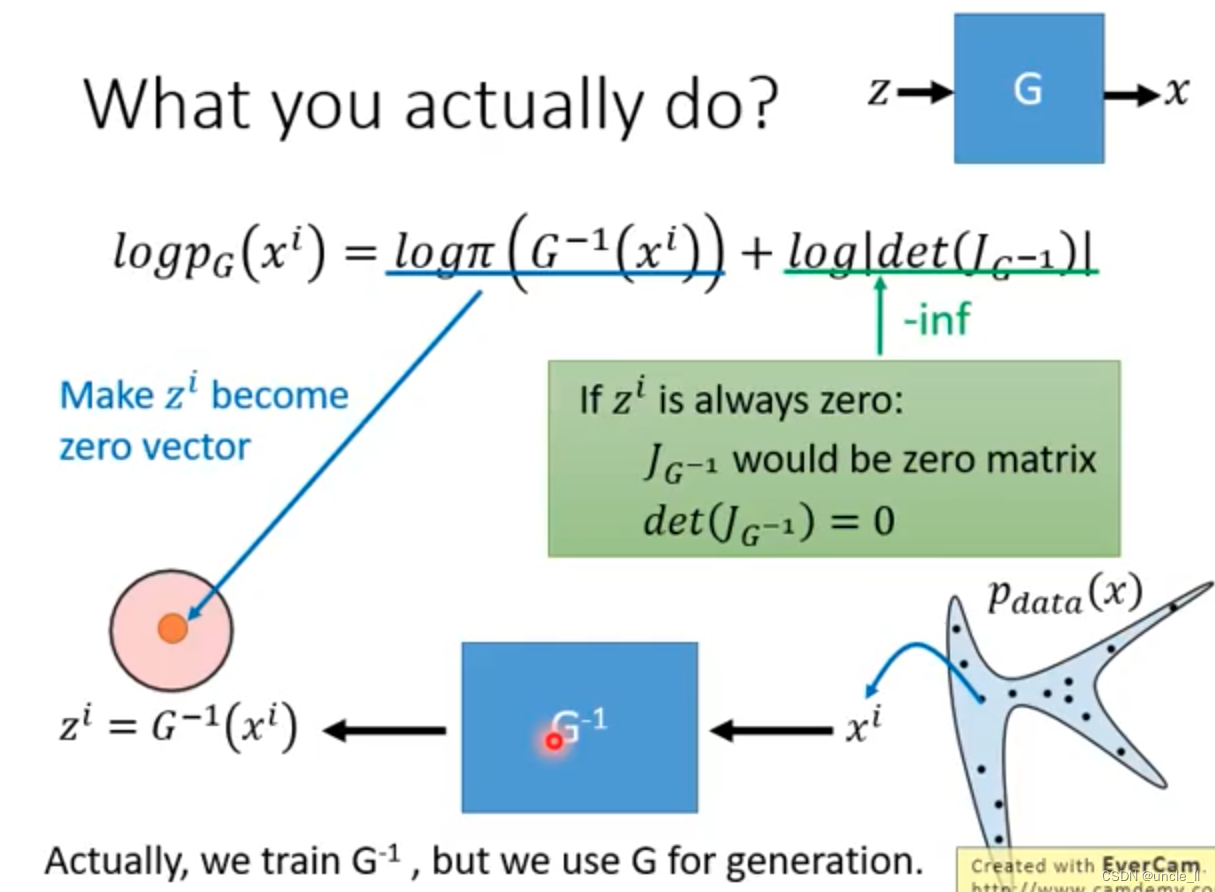
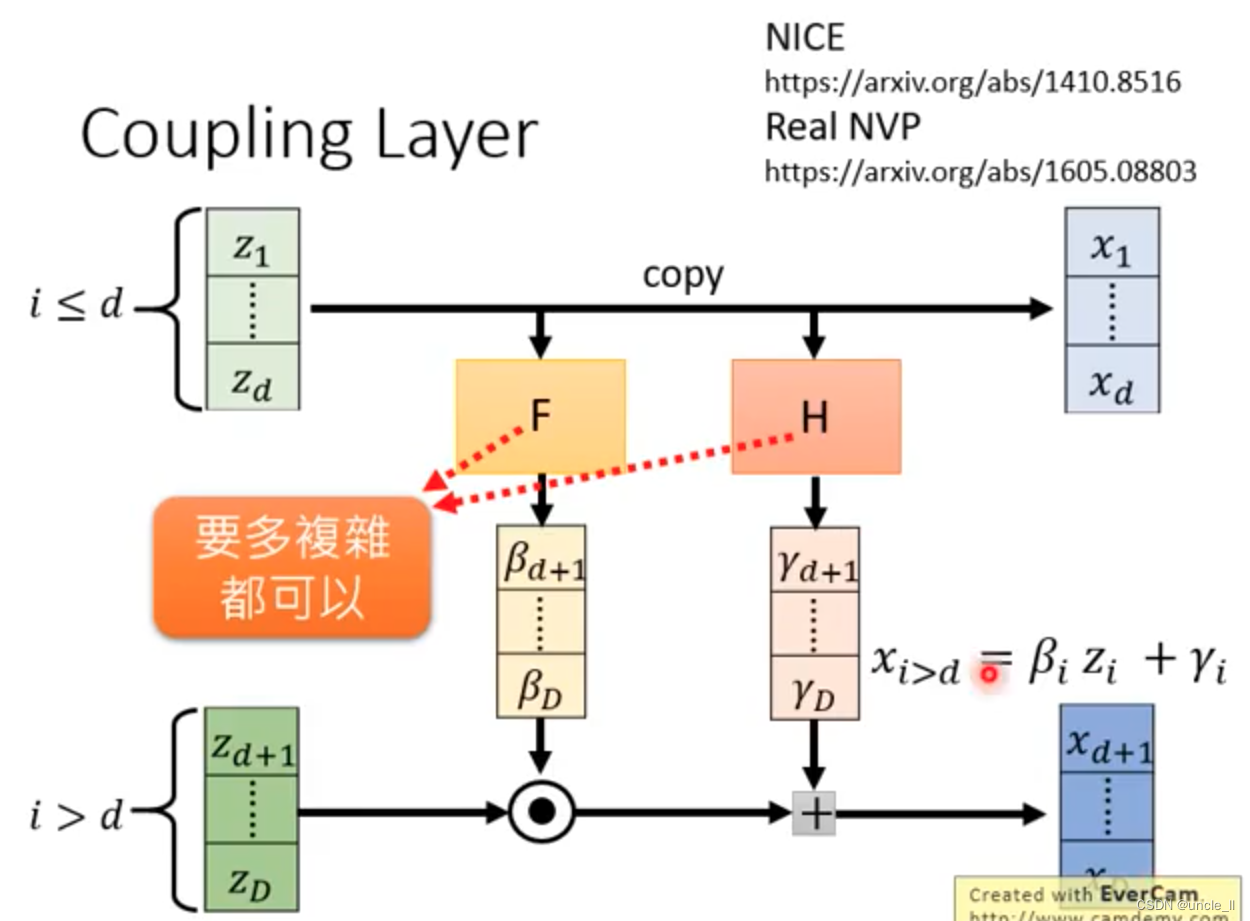




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











