









caffe SSP(Spatial Pyramid Pooling) 分析
首先摘抄一下 一篇博客
文章:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
来源:Technicalreport
大意:通过图像金字塔来实现识别中的尺度无关性;
作者:KaimingHe,Xiangyu Zhang, Shaoqing Ren, Jian Sun ,来自微软
主要内容:
由于之前的大部分CNN模型的输入图像都是固定大小的(大小,长宽比),比如NIPS2012的大小为224X224,而不同大小的输入图像需要通过crop或者warp来生成一个固定大小的图像输入到网络中。这样子就存在问题,1.尺度的选择具有主观性,对于不同的目标,其最适合的尺寸大小可能不一样,2.对于不同的尺寸大小的图像和长宽比的图像,强制变换到固定的大小会损失信息;3.crop的图像可能不包含完整的图像,warp的图像可能导致几何形变。所以说固定输入到网络的图像的大小可能会影响到他们的识别特别是检测的准确率;
而这篇文章中,提出了利用空间金字塔池化(spatial pyramid pooling,SPP)来实现对图像大小和不同长宽比的处理,这样产生的新的网络,叫做SPP-Net,可以不论图像的大小产生相同大小长度的表示特征;这样的网络用在分类和检测上面都刷新的记录;并且速度比较快,快30-170倍,因为之前的检测方法都是采用:1.滑动窗口(慢) 2.对可能的几个目标(显著性目标窗口,可能有几千个)的每一个都进行识别然后再选出最大值作为检测到的目标;
利用这种网络,我们只需要计算完整图像的特征图(feature maps)一次,然后池化子窗口的特征,这样就产生了固定长度的表示,它可以用来训练检测器;
为什么CNN需要固定输入图像的大小,卷积部分不需要固定图像的大小(它的输出大小是跟输入图像的大小相关的),有固定输入图像大小需求的是全连接部分,由它们的定义我们可以知道,全连接部分的参数的个数是需要固定的。综上我们知道,固定大小这个限制只是发生在了网络的深层(高层)处。
文章利用了空间金字塔池化(spatial pyramidpooling(SPP))层来去除网络固定大小的限制,也就是说,将SPP层接到最后一个卷积层后面,SPP层池化特征并且产生固定大小的输出,它的输出然后再送到第一个全连接层。也就是说在卷积层和全连接层之前,我们导入了一个新的层,它可以接受不同大小的输入但是产生相同大小的输出;这样就可以避免在网络的输入口处就要求它们大小相同,也就实现了文章所说的可以接受任意输入尺度;
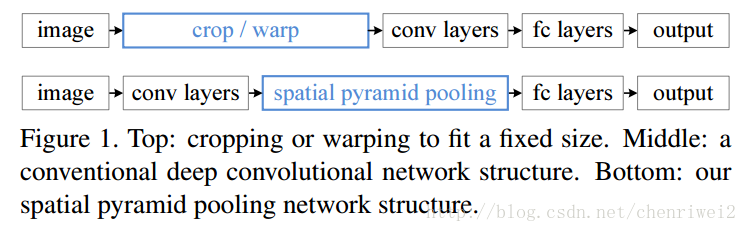
文章说这种形式更符合我们的大脑,我们的大脑总不会是说先对输入我们视觉的图像进行切割或者归一化同一尺寸再进行识别,而是采用先输入任意大小的图像,然后再后期进行处理。
SSP或者说是空间金字塔匹配(spatial pyramid matching or SPM)是BoW的一个扩展,它把一张图片划分为从不同的分辨率级别然后聚合这些不同分辨率的图像,在深度学习之前SPM取得了很大的成功,然是在深度学习CNN出现之后却很少被用到,SSP有一些很好的特征:1.它可以不论输入数据的大小而产生相同大小的输出,而卷积就不行 2.SPP使用多级别的空间块,也就是说它可以保留了很大一部分的分辨率无关性;3.SPP可以池化从不同尺度图像提取的特征。
对比于R-CNN,R-CNN更耗时,因为它是通过对图像的不同区域(几千个,通过显著性)提取特征表示,而在这篇文章中,只需要运行卷积层一次(整幅图像,无论大小),然后利用SPP层来提取特征,它提取的特征长度是相同的,所以说它减少了卷积的次数,所以比R-CNN快了几十倍到一百多倍的速度;
池化层(Poolinglayer)在滑动窗口的角度下,也可以看作为卷积层,卷积层的输出称之为featuremap,它表示了响应的强度和位置信息;
在利用SPP层替换最后一个卷积层后面的池化层中,
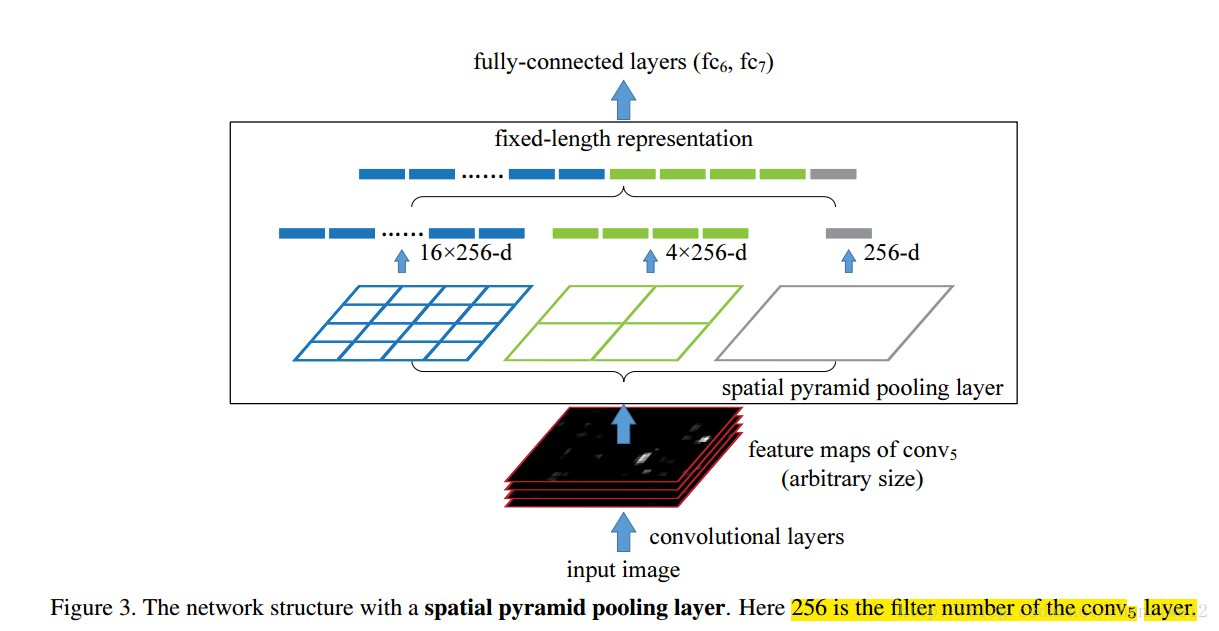
在每一个空间块(bin)中,池化每一个滤波器的响应,所以SPP层的输出为256M维度,其中256是滤波器的个数,M是bin的个数(?)(很显然,M是根据不同的图像大小计算出来的),这样不同输入图像大小的输出就可以相同了。
对于给定的输入图像大小,我们可以先计算出它所需要的空间bin块的多少,计算如下:
比如一张224*224的图像,它输入到conv5的输出为a*a(13*13),当需要n*n级别的金字塔时候,每个采样窗口为win=【a/n】步长为【a/n】,当需要l个金字塔的时候,计算出l个这样的采样窗口和步长,然后将这些l个输出的bin连接起来作为第一个全连接层的输出;
caffe SSP 代码 , 看明白pooling 这个就很简单。 只是 增加了一个自动去kernel size的函数, 这个函数
num_bins = 2^pyramid_level 金字塔块大小
#include <algorithm>
#include <cfloat>
#include <vector>
#include "caffe/common.hpp"
#include "caffe/layer.hpp"
#include "caffe/syncedmem.hpp"
#include "caffe/util/math_functions.hpp"
#include "caffe/vision_layers.hpp"
// Does spatial pyramid pooling on the input image by taking the max, average, etc. within regions
// so that the result vector of different sized images are of the same size
namespace caffe {
using std::min;
using std::max;
template <typename Dtype>
LayerParameter SPPLayer<Dtype>::GetPoolingParam(const int pyramid_level,
const int bottom_h, const int bottom_w, const SPPParameter spp_param) {
LayerParameter pooling_param;
// num_bins = 2^pyramid_level
int num_bins = pow(2, pyramid_level);
// find padding and kernel size so that the pooling is
// performed across the entire image
int kernel_h = ceil(bottom_h / static_cast<double>(num_bins));
// remainder_h is the min number of pixels that need to be padded before
// entire image height is pooled over with the chosen kernel dimension
int remainder_h = kernel_h * num_bins - bottom_h;
// pooling layer pads (2 * pad_h) pixels on the top and bottom of the
// image.
int pad_h = (remainder_h + 1) / 2;
// similar logic for width
int kernel_w = ceil(bottom_w / static_cast<double>(num_bins));
int remainder_w = kernel_w * num_bins - bottom_w;
int pad_w = (remainder_w + 1) / 2;
pooling_param.mutable_pooling_param()->set_pad_h(pad_h);
pooling_param.mutable_pooling_param()->set_pad_w(pad_w);
pooling_param.mutable_pooling_param()->set_kernel_h(kernel_h);
pooling_param.mutable_pooling_param()->set_kernel_w(kernel_w);
pooling_param.mutable_pooling_param()->set_stride_h(kernel_h);
pooling_param.mutable_pooling_param()->set_stride_w(kernel_w);
switch (spp_param.pool()) {
case SPPParameter_PoolMethod_MAX:
pooling_param.mutable_pooling_param()->set_pool(
PoolingParameter_PoolMethod_MAX);
break;
case SPPParameter_PoolMethod_AVE:
pooling_param.mutable_pooling_param()->set_pool(
PoolingParameter_PoolMethod_AVE);
break;
case SPPParameter_PoolMethod_STOCHASTIC:
pooling_param.mutable_pooling_param()->set_pool(
PoolingParameter_PoolMethod_STOCHASTIC);
break;
default:
LOG(FATAL) << "Unknown pooling method.";
}
return pooling_param;
}
template <typename Dtype>
void SPPLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
SPPParameter spp_param = this->layer_param_.spp_param();
bottom_h_ = bottom[0]->height();
bottom_w_ = bottom[0]->width();
CHECK_GT(bottom_h_, 0) << "Input dimensions cannot be zero.";
CHECK_GT(bottom_w_, 0) << "Input dimensions cannot be zero.";
pyramid_height_ = spp_param.pyramid_height();
split_top_vec_.clear();
pooling_bottom_vecs_.clear();
pooling_layers_.clear();
pooling_top_vecs_.clear();
pooling_outputs_.clear();
flatten_layers_.clear();
flatten_top_vecs_.clear();
flatten_outputs_.clear();
concat_bottom_vec_.clear();
// split layer output holders setup
for (int i = 0; i < pyramid_height_; i++) {
split_top_vec_.push_back(new Blob<Dtype>());
}
// split layer setup
LayerParameter split_param;
split_layer_.reset(new SplitLayer<Dtype>(split_param));
split_layer_->SetUp(bottom, split_top_vec_);
for (int i = 0; i < pyramid_height_; i++) {
// pooling layer input holders setup
pooling_bottom_vecs_.push_back(new vector<Blob<Dtype>*>);
pooling_bottom_vecs_[i]->push_back(split_top_vec_[i]);
// pooling layer output holders setup
pooling_outputs_.push_back(new Blob<Dtype>());
pooling_top_vecs_.push_back(new vector<Blob<Dtype>*>);
pooling_top_vecs_[i]->push_back(pooling_outputs_[i]);
// pooling layer setup
LayerParameter pooling_param = GetPoolingParam(
i, bottom_h_, bottom_w_, spp_param);
pooling_layers_.push_back(shared_ptr<PoolingLayer<Dtype> > (
new PoolingLayer<Dtype>(pooling_param)));
pooling_layers_[i]->SetUp(*pooling_bottom_vecs_[i], *pooling_top_vecs_[i]);
// flatten layer output holders setup
flatten_outputs_.push_back(new Blob<Dtype>());
flatten_top_vecs_.push_back(new vector<Blob<Dtype>*>);
flatten_top_vecs_[i]->push_back(flatten_outputs_[i]);
// flatten layer setup
LayerParameter flatten_param;
flatten_layers_.push_back(new FlattenLayer<Dtype>(flatten_param));
flatten_layers_[i]->SetUp(*pooling_top_vecs_[i], *flatten_top_vecs_[i]);
// concat layer input holders setup
concat_bottom_vec_.push_back(flatten_outputs_[i]);
}
// concat layer setup
LayerParameter concat_param;
concat_layer_.reset(new ConcatLayer<Dtype>(concat_param));
concat_layer_->SetUp(concat_bottom_vec_, top);
}
template <typename Dtype>
void SPPLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
CHECK_EQ(4, bottom[0]->num_axes()) << "Input must have 4 axes, "
<< "corresponding to (num, channels, height, width)";
channels_ = bottom[0]->channels();
bottom_h_ = bottom[0]->height();
bottom_w_ = bottom[0]->width();
SPPParameter spp_param = this->layer_param_.spp_param();
split_layer_->Reshape(bottom, split_top_vec_);
for (int i = 0; i < pyramid_height_; i++) {
LayerParameter pooling_param = GetPoolingParam(
i, bottom_h_, bottom_w_, spp_param);
pooling_layers_[i].reset(
new PoolingLayer<Dtype>(pooling_param));
pooling_layers_[i]->SetUp(
*pooling_bottom_vecs_[i], *pooling_top_vecs_[i]);
pooling_layers_[i]->Reshape(
*pooling_bottom_vecs_[i], *pooling_top_vecs_[i]);
flatten_layers_[i]->Reshape(
*pooling_top_vecs_[i], *flatten_top_vecs_[i]);
}
concat_layer_->Reshape(concat_bottom_vec_, top);
}
template <typename Dtype>
void SPPLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
split_layer_->Forward(bottom, split_top_vec_);
for (int i = 0; i < pyramid_height_; i++) {
pooling_layers_[i]->Forward(
*pooling_bottom_vecs_[i], *pooling_top_vecs_[i]);
flatten_layers_[i]->Forward(
*pooling_top_vecs_[i], *flatten_top_vecs_[i]);
}
concat_layer_->Forward(concat_bottom_vec_, top);
}
template <typename Dtype>
void SPPLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
if (!propagate_down[0]) {
return;
}
vector<bool> concat_propagate_down(pyramid_height_, true);
concat_layer_->Backward(top, concat_propagate_down, concat_bottom_vec_);
for (int i = 0; i < pyramid_height_; i++) {
flatten_layers_[i]->Backward(
*flatten_top_vecs_[i], propagate_down, *pooling_top_vecs_[i]);
pooling_layers_[i]->Backward(
*pooling_top_vecs_[i], propagate_down, *pooling_bottom_vecs_[i]);
}
split_layer_->Backward(split_top_vec_, propagate_down, bottom);
}
INSTANTIATE_CLASS(SPPLayer);
REGISTER_LAYER_CLASS(SPP);
} // namespace caffe
virtualinlineconstchar*type()const { return"SPP"; }
virtual LayerParameter GetPoolingParam(constint pyramid_level,constint bottom_h, constint bottom_w, const SPPParameter spp_param);
int pyramid_height_;
int bottom_h_, bottom_w_;
int num_;
int channels_;
int kernel_h_, kernel_w_;
int pad_h_, pad_w_;
bool reshaped_first_time_;
构建时需要考虑的参数值
1.准备数据,在examples路径下新建一个目录 spp_net,将n03791053摩托车、n03895866客车、n04285008跑车、n04467665大货车、n04487081无轨电车这5类的图片放入到该目录下,每种车型一个目录。
>>ll /root/deep/gjj/caffe-master/examples/spp_net
drwxr-xr-x 2 root root 73728 Mar 30 15:24 n03791053
drwxr-xr-x 2 root root 77824 Mar 30 15:25 n03895866
drwxr-xr-x 2 root root 73728 Mar 30 15:25 n04285008
drwxr-xr-x 2 root root 73728 Mar 30 15:25 n04467665
drwxr-xr-x 2 root root 73728 Mar 30 15:25 n04487081
2.准备标签文件,训练和测试的输入是用train.txt和val.txt来描述的。里面的格式都是路径加文件名 空格 类别号。如下:
train.txt中 n03791053/n03791053_10013.JPEG 670
val.txt中 val/ILSVRC2012_val_00027580.JPEG 705
3.将examples/imagenet/create_imagenet.sh复制到spp_net目录下,并修改里面的内容,在spp_net下生成lmdb格式的图像信息。
EXAMPLE=examples/spp_net
DATA=examples/spp_net/
TOOLS=build/tools
TRAIN_DATA_ROOT=examples/spp_net/
VAL_DATA_ROOT=examples/spp_net/
此外,我把图片的大小改成了224*224
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=224
RESIZE_WIDTH=224
4.没有去做均值,直接构建spp_solver.prototxt和Zeiler_spp_scale224.prototxt
spp_solver.prototxt中设置 solver_mode: CPU
Zeiler_spp_scale224.prototxt将卷积第五层之后的池化改为spp池化,根据caffe.proto中的定义来改
layer {
name: "pool5_spp"
type: "SPP"
bottom: "conv5"
top: "pool5_spp"
spp_param{
pyramid_height:3
pool: MAX
}
}
5.把下面的命令写到spp_train_caffenet.sh中或直接运行:
/root/deep/gjj/caffe-master/build/tools/caffe train --solver=spp_solver.prototxt















 4640
4640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









