






一、背景
NLP任务(包括与对话相关的任务)尝试处理和分析顺序的语言数据点,即使标准神经网络以及CNN是强大的学习模型,它们也具有两个主要限制:
-
一种是它们假定数据点彼此独立。虽然可以独立地产生数据点是合理的,但是在处理相互关联的数据点(例如,文本,音频,视频)时,可能会丢失基本信息。
-
另外,它们的输入通常具有固定的长度,这在处理长度可变的序列数据时是一个限制。因此,能够表示顺序信息流的序列模型是值得被期待的。
隐马尔可夫模型(HMM)之类的马尔可夫模型是传统的序列模型,但是由于推理算法的时间复杂性和转导矩阵的大小随着离散状态空间的增加而显着增长,实际上它们是不适用于处理涉及大量隐藏状态的问题。而马尔可夫模型的隐藏状态仅受直接隐藏状态影响的性质进一步限制了该模型的功能。
因此RNN模型的的出现极大地解决了上述问题,并且某些变体可以惊人地实现与对话相关的任务以及许多其他NLP任务的最新性能。
二、追根溯源RNN****
最早可以追述到1982年,Hopfield介绍了RNN去解决模式识别任务:
- 《Neural networks and physical systems with emergent collective computational abilities》
该文章介绍了两种RNN结构,模型结构如图1:
-
Jordan-Type RNNs(图1a)
-
xt, ht, and yt are the inputs, hidden state, and output of time step t respectively
-
Wh, Wy and Uh are weight matrixes
-
隐藏状态的每次更新由当前输入和上一时间步的输出决定,而每个输出则由当前隐藏状态决定。时间步t的隐藏状态和输出计算公式2、3:
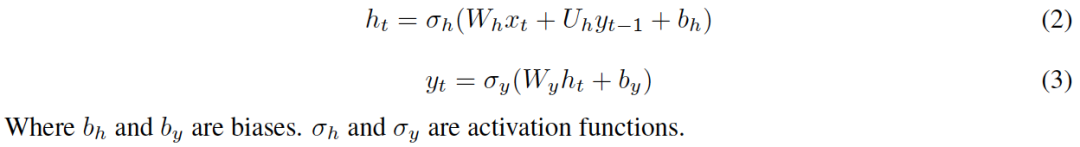
-
Elman-Type RNNs(图1b)
-
不同之处在于每个隐藏状态由当前输入和上一个时间步的隐藏状态决定。时间步t的隐藏状态和输出计算公式4、5:
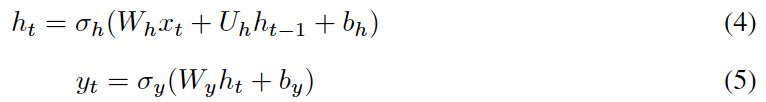
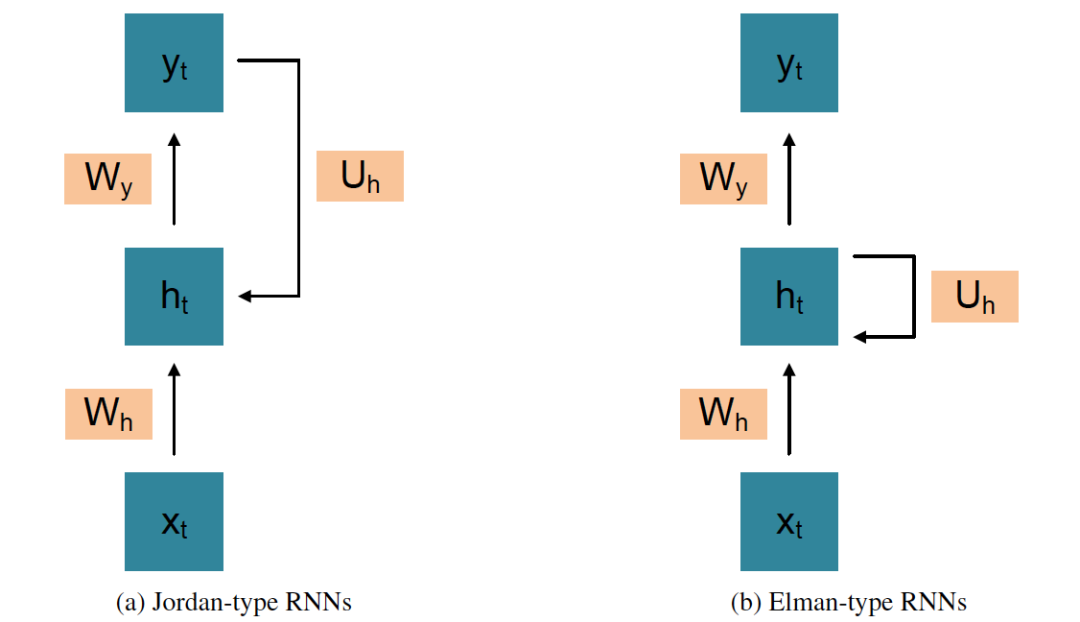
图1 Graphical models of two basic types of RNNs
简单的RNN可以在理论上对长期依赖性进行建模。但是在实际训练中,远程依赖关系很难学习。当在许多时间步长上向后传播误差时,简单的RNN都会遇到称为梯度消失和梯度爆炸的问题。
三、详解循环神经网络(RNN)
循环神经网络的主要用途是处理和预测序列数据。
从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面结点的输出。也就是说,循环神经网络的隐藏层之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上时刻隐藏层的输出。
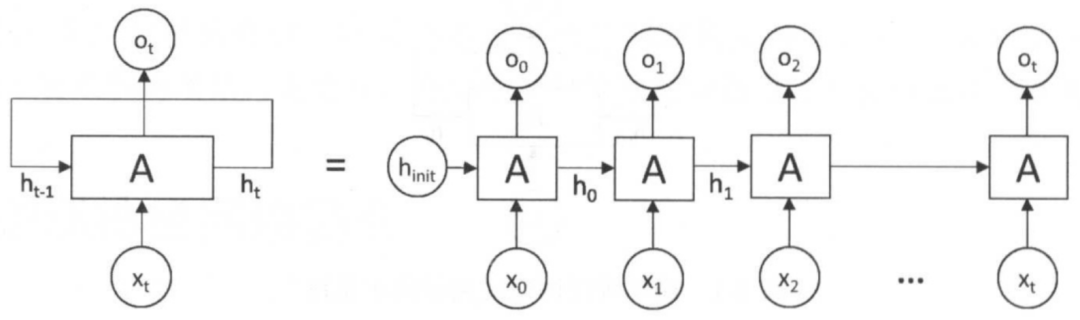
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。
这幅图描述了在序列索引号t附近RNN的模型。其中:
-
xt代表在序列索引号t时训练样本的输入。同样的,xt−1和xt+1代表在序列索引号t−1和t+1时训练样本的输入。
-
ht代表在序列索引号t时模型的隐藏状态。ht由xt和ht−1共同决定。
-
ot代表在序列索引号t时模型的输出。ot只由模型当前的隐藏状态ht决定。
-
A代表RNN模型。
RNN的前向传播
输入为 𝑥1,𝑥2,…,𝑥𝑡 对应的隐状态为 ℎ1,ℎ2,…,ℎ𝑡 。输出为 𝑦1,𝑦2,…,𝑦𝑡 ,则经典RNN的运算过程可以表示为:
ℎ𝑡=𝑓(𝑈𝑥𝑡+𝑊ℎ𝑡−1+𝑏)
𝑦𝑡=𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑉ℎ𝑡+𝑐)
其中 𝑈 , 𝑊 , 𝑉 , 𝑏 , 𝑐 均为参数,而𝑓()表示激活函数,一般为tanh函数。
四、总结
RNN虽然理论上可以很漂亮的解决序列数据的训练,但是它也像DNN一样有梯度消失时的问题,当序列很长的时候问题尤其严重。因此,上面的RNN模型一般不能直接用于应用领域。在语音识别,手写书别以及机器翻译等NLP领域实际应用比较广泛的是基于RNN模型的一个特例LSTM。

点赞+关注 就是最好的打赏

既然大模型现在这么火热,各行各业都在开发搭建属于自己企业的私有化大模型,那么势必会需要大量大模型人才,同时也会带来大批量的岗位?“俗话说站在风口,猪都能飞起来”可以说大模型这对于我们来说就是一个机会,一个可以改变自身的机会,就看我们能不能抓住了。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1368
1368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









