








 超级会员免费看
超级会员免费看
作者:禅与计算机程序设计艺术
1.简介
中文手语识别(Chinese Speech Recognition)主要包括了汉语普通话和粤语方言之间的文本转写、语音合成以及语音识别三种任务,其研究和应用的研究范畴都十分广泛。近年来,基于深度学习(Deep Learning)和强化学习(Reinforcement Learning)的最新模型方法取得了很大的成功,特别是在文本转写和语音识别方面,取得了前所未有的效果。本文将介绍基于LSTM(长短时记忆神经网络)和CRF(条件随机场)的中文手语识别模型,并从各个角度对模型进行阐述,希望能够为中文手语识别领域的研究者提供一些借鉴参考。
2.相关背景
2.1 中文手语识别的定义
中文手语识别,是指通过自动化的技术或手工的方法,将不规范的中文语言文本转换为标准的英文字母数字字符串,或者将人类的普通话声音转换成相应的文字输入形式。中文手语识别属于信息技术(IT)技术的重要分支之一,因为在线中文新闻、论坛、微博等社交媒体、电商、客服机器人的应用中,手语转换功能必不可少。
2.2 深度学习与机器学习的关系
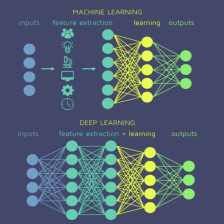
机器学习是人工智能领域的一个子领域,它旨在利用数据训练计算机模型,使得模型可以从数据中学到知识、解决问题,得到预测能力。机器学习分为监督学习、无监督学习、半监督学习、强化学习四类,其中深度学习与机器学习密切相关。深度学习是机器学习中的一个子集,它是利用多层次的神经网络来进行数据的学习和推理。通过学习特征表示和权重共享,深度学习可以自动发现数据中隐含的模式,在图像、语音、文本等不同类型的数据上,都可以获得显著的性能提升。

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











