







API应用
分类
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=2) #KNN分类模型,K值为2
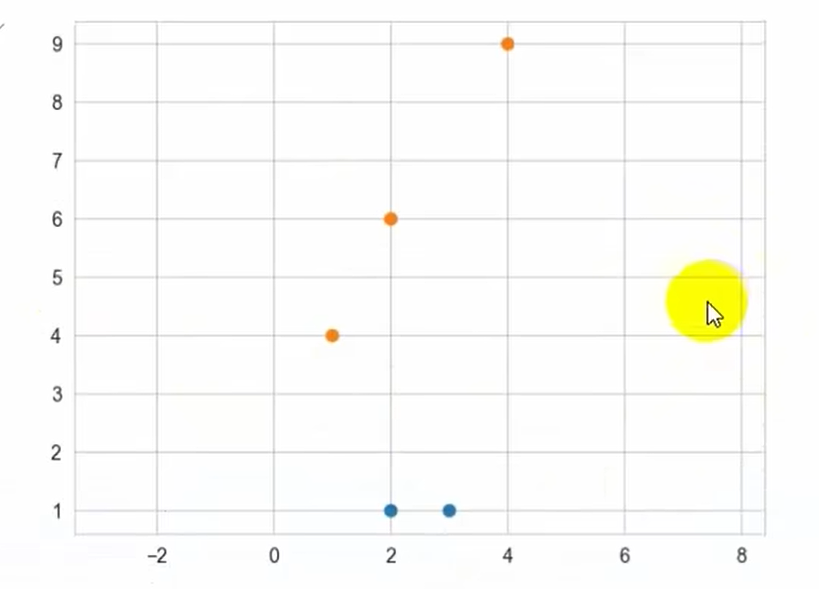
X = np.array([[2,1],[3,1],[1,4],[2,6]]) #特征
y = np.array([0,0,1,1])#标签
knn.fit(X,y) #模型训练
X = np.array([[4,9]])
X_class = knn.predict(X)#预测
print(X_class)
#画图
fig,ax = plt.subplots()
ax.axis('equal')
#使用布尔索引将两类点分开
X1 = X[y==0]
X2 = X[y==1]
#定义不同的颜色,画两组点
colors = ["C0","C1"]
plt.scatter(X1[:,0],X1[:,1],c=colors[0])
plt.scatter(X2[:,0],X2[:,1],c=colors[1])
#新点的颜色
x_color = colors[0] if x_class == 0 else colors[1]
plt.scatter(X[:,0],X[:,1],c=x_color)
plt.show()
回归
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor(n_neighbors=2,weights='distance') #KNN回归模型,K为2
X = [[2,1],[3,1],[1,4],[2,6]]
y = [0.5,0.33,4,3]
knn.fig(X,y)
knn.predict([4,9])
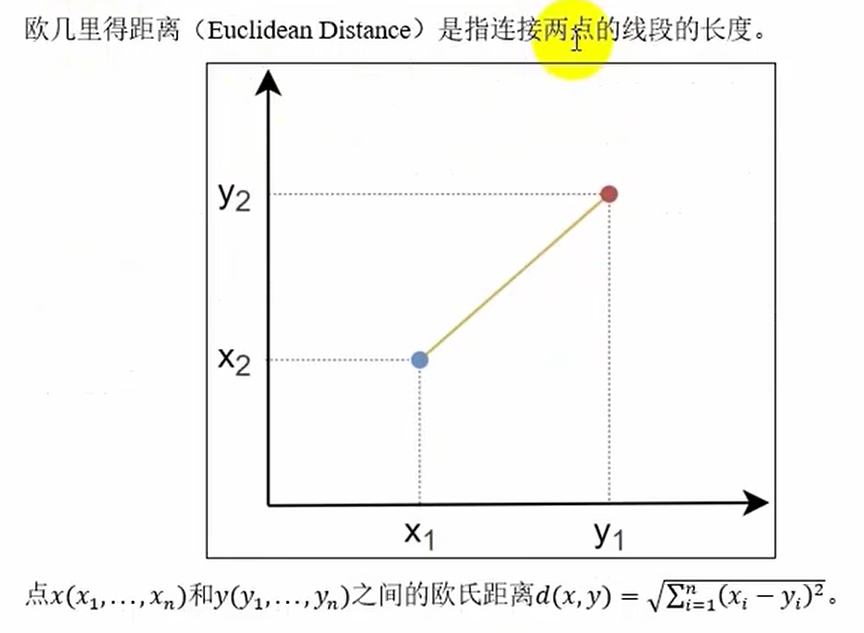
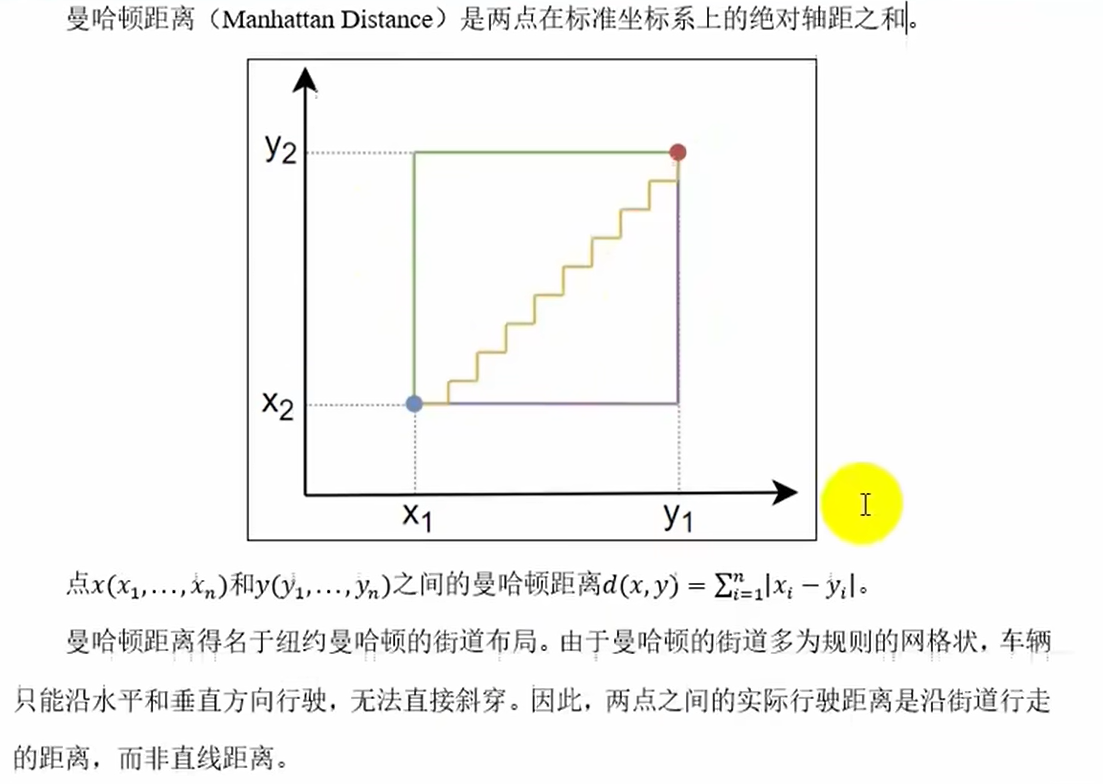
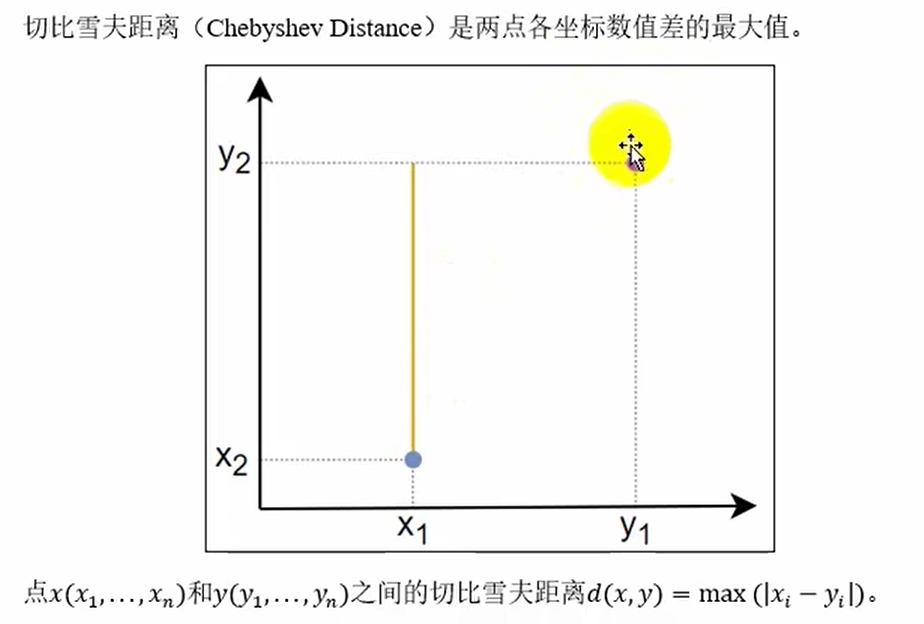
常见距离度量方法

归一化与标准化
归一化:
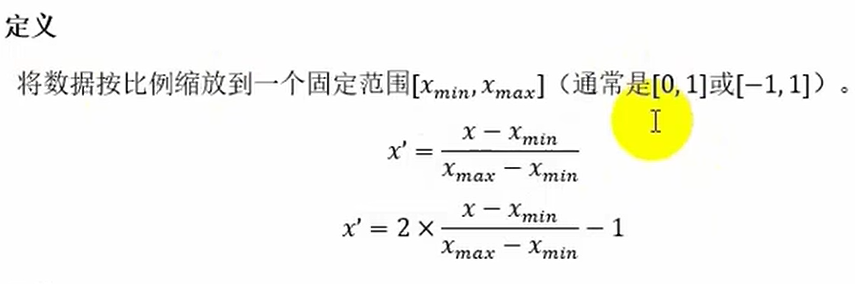
from sklearn.preprocessing import MinMaxScaler
X = [[2,1],[3,1],[1,4],[2,6]]
#定义归一化类的对象
scaler = MinMaxScaler(feature_range=(-1,1))
#将缩放器应用到特征上
X_scaled = scaler.fit_transform(X)
print(X_scaled)

标准化:

from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print(X_scaled)
#均值和方差
print(np.mean(X,axis=0))
print(np.std(X,axis=0))

案例:心脏病预测

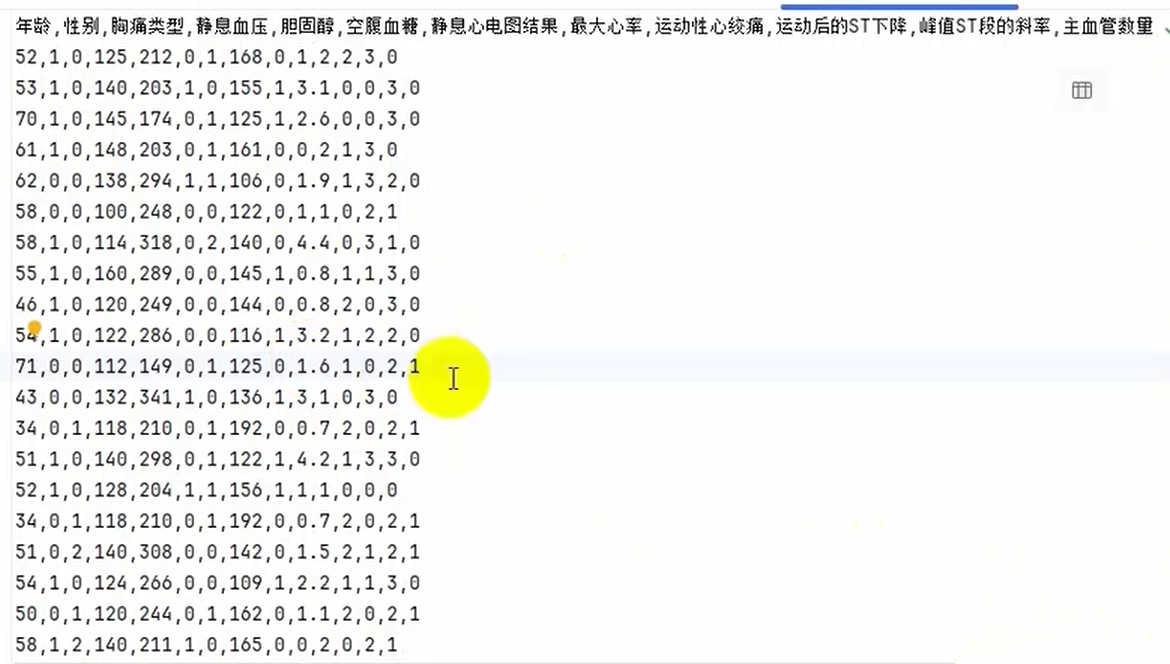
import pandas as pd
import sklearn.model_selection import train_test_split
#加载数据集
heart_disease_data = pd.read_csv("heart_disease.csv")
#处理缺失值
heart_disease_data.dropna(inplace=True)
heart_disease_data.info()
print(heart_disease_data.head())
#数据集划分
X = heart_disease_data.drop("是否患有心脏病",axis=1)
y = heart_disease_data["是否患有心脏病"]
X_tain,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=42)
#如何处理13中特征?

from sklearn.preprocessing import StandardScaler,OneHotEncoder
from sklearn.compose import ColumnTransformer
#数值特征
numerical_features = ["年龄","静息血压","胆固醇","最大心率","运动后的ST下降","主血管数量"]
#类别型特征
categorical_features = ["胸痛类型","静息心电图结果","峰值ST段的斜率","地中黑贫血"]
#二元特征
binary_features = ["性别","空腹血糖","运动性心绞痛"]
#创建列转换器
preprocessor = ColumnTransformer(
transformers=[
#对数值型特征进行标准化
("num",StandardScaler(),numerical_features),
#对类别型特征进行独热编码,使用drop="first"避免多重共线性
("cat",OneHotEncoder(drop="first"),categorical_features),
#二元特征不进行处理
("binary","passthrouth",binary_features),
]
)
#执行特征转换
x_train = preprocessor.fit_trainsform(X_train)#计算训练集的统计信息并进行转换
x_test = preprocessor.transform(X_test) #使用训练集计算的信息对测试集进行转换
print(x_train)
print(x_test)
from sklearn.neighbors import KNeighborsClassifier
import joblib
#创建模型
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train,y_train)
#模型评估,计算预测准确率
score = knn.score(X_test,y_test)
print(score)
#保存模型
joblib.dump(value=knn,filename="knn_model")
#加载保存好的模型做预测
knn_loaded = joblib.load("knn_model")
y_pred = knn_loaded.predict(X_test[10:11])
print(f"预测类别:{y_pred},真实类别:{y_test[10]}")
交叉验证

from sklearn.model_selection import GridSearchCV
#创建KNN分类器
knn = KNeighborsClassifier()
#定义网络搜索参数列表
param_grid = {"n_neigobors":list(range(1,11))}
grid_search_cv = GridSearchCV(estimator=knn,param_grid=param_grid,dv=10)
#模型训练
grid_search_cv.fit(X_train,y_train)
#打印模型评估结果
# results = grid_search_cv.cv_results_
# results = pd.DataFrame(grid_search_cv.cv_results_)
results = pd.DataFrame(grid_search_cv.cv_results_).toString()
print(results)
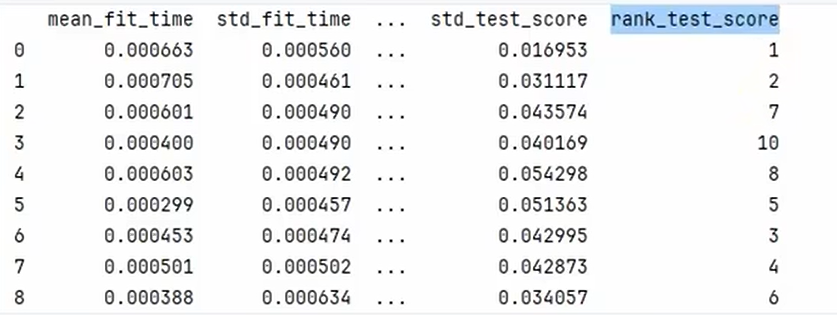
#获取最佳模型、参数和最佳得分
print(grid_search_cv.test_estimator_)
print(grid_search_cv.test_params_)
print(grid_search_cv.best_score_)
#使用最佳模型进行测试评估
knn = grid_search_cv.test_estimater_
print(knn.score(X_test,y_test))
除了上述K值决定的模型优化,此外还有权重影响
#定义网络搜索参数列表
pram_grid = {"n_neighbors":list(range(1,11)),"weights":["uniform","distance"]}

















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









