






摘要
本周通过对自监督学习的一些案例进行学习从而了解了自监督学习的一些基础概念。自监督学习是无监督学习里面的一种,也被称作pretext task。自监督学习主要是利用辅助任务从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
Abstract
This week, I learned some basic concepts of Self-Supervised Learning by studying some cases of Self-Supervised Learning. Self-Supervised Learning is a type of unsupervised learning, also known as pretext task. Self-Supervised Learning mainly utilizes auxiliary tasks to mine its own supervisory information from large-scale unsupervised data, and trains the network through this constructed supervisory information, thereby learning valuable representations for downstream tasks.
Self-supervised Learning
概念:
自监督学习(Self-supervised learning) 是这两年比较热门的一个研究领域,它旨在对于无标签数据 ,通过设计 辅助任务(Proxy tasks) 来挖掘数据自身的表征特性作为监督信息,来提升模型的特征提取能力。
几种学习类型如下:
有监督(Supervised): 监督学习是从给定的带标签训练数据集中学习出一个函数(模型参数),在输入新的测试数据时,可以根据这个函数预测结果;
无监督(Unsupervised): 无监督学习是从无标签数据中分析数据本身的规律性等解析特征。无监督学习算法分为两大类:基于概率密度函数估计的方法和基于样本间相似性度量的方法;
半监督学习(Semi-supervised): 半监督介于监督学习和无监督之间,即训练集中只有一部分数据有标签,需要通过伪标签生成等方式完成模型训练;
弱监督(Weakly-supervised): 弱监督是指训练数据只有不确切或者不完全的标签信息,比如在目标检测任务中,训练数据只有分类的类别标签,没有包含Bounding box坐标信息。
在上述概念中,无监督和自监督学习相似性最大,两者的训练数据都是无标签,但区别在于:自监督学习会通过构造辅助任务来获取监督信息,这个过程中有学习到新的知识;而无监督学习不会从数据中挖掘新任务的标签信息。
监督学习对比自监督学习:
监督学习是有明确的样本和对应的标签,将样本丢进去模型训练并且将训练结果将标签进行比较来修正模型,如下图:

而自监督学习就是没有标签也要自己创建监督学习的条件,即当前只有样本x但是没有标签,具体的做法就是将样本x分成两部分,其中一部分作为输入模型的样本,另一部分来作为标签:

Bert模型
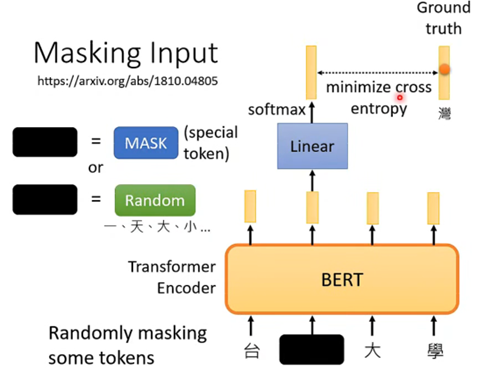
masking
BERT的架构可以简单地看成跟Transformer中的Encoder的架构是相同的,其实现的功能都是接受一排向量,并输出一排向量。而BERT特别的地方在于它对于接受的一排输入的向量(通常是文字或者语音等)会随机选择某些向量进行“遮挡”(mask),而进行遮挡的方式又分为两种:
• 第一种是将该文字用一个特殊的字符来进行替代
• 第二种是将该文字用一个随机的文字来进行替代
而这两种方法的选择也是随机的,因此就是随机选择一些文字再随机选择mask的方案来进行遮挡。然后就让BERT来读入这一排向量并输出一排向量,那么训练过程就是将刚才遮挡的向量其对应的输出向量,经过一个线性变换模型(乘以一个矩阵)再经过softmax模块得到一个result,包含该向量取到所有文字的所有概率,虽然BERT不知道被遮挡的向量代表什么文字但我们是知道的,因此我们就拿答案的文字对应的one-hat-vector来与向量result最小化交叉熵,从而来训练BERT和这个线性变换模块,总体可以看下图:
Next Sentence Prediction
这个任务是判别两个句子它们是不是应该连接在一起,例如判断“我爱”和“中国”是不是应该连在一起,那么在BERT中具体的做法为:
• 先对两个句子进行处理,在第一个句子的前面加上一个特殊的成为CLS的向量,再在两个句子的中间加上一个特殊的SEP的向量作为分隔,因此就拼成了一个较长的向量集
• 将该长向量集输入到BERT之中,那么就会输出相同数目的向量
• 但我们只关注CLS对应的输出向量,因此我们将该向量同样经过一个线性变换模块,并让这个线性变换模块的输出可以用来做一个二分类问题,就是yes或者no,代表这两个句子是不是应该拼在一起
具体如下图:

以上两种BERT的应用场景,看起来似乎都是填空题或者判断题,实际上它还可以用来解决我们感兴趣的下游任务。更有趣的是,它只需要将刚才训练(Pre-train)完成的可以处理填空题任务的简单BERT进行微调(Fine-tune)就可以用来高效地解决一些下游、复杂的任务。也就是说BERT只需要先用简单的任务来进行Pre-train,然后再进行微调就可以用于我们感兴趣的下游复杂任务。
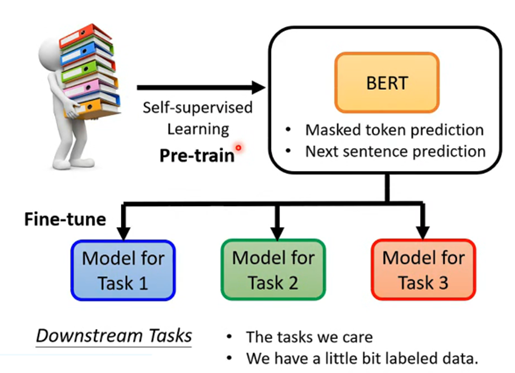
补充:
因为BERT这类模型可以进行微调来解决各种下游任务,因此有一个任务集为GLUE,里面包好了9种自然语言处理的任务,一般评判BERT这种模型就是将BERT分为微调来处理这9个任务然后对正确率等进行平均。9个任务如下:

How to uses BERT
Case 1
Case 1 是接受一个向量,输出一个分类,例如做句子的情感分析,对一个句子判断它是积极的还是消极的。那么如何用BERT来解决这个问题呢,具体的流程如下:
• 在句子对应的一排向量之前再加上CLS这个特殊字符所对应的向量,然后将这一整排向量放入BERT之中
• 我们只关注CLS对应的输出向量,将该向量经过一个线性变换(乘上一个矩阵)后再经过一个softmax,输出一个向量来表示分类的结果,表示是积极的还是消极的
而重要的地方在于线性变换模块的参数是随机初始化的,而BERT中的参数是之前就pre-train的参数,这样会比随机初始化的BERT更加高效。而这也代表我们需要很多句子情感分析的样本和标签来让我们可以通过梯度下降来训练线性变换模块和BERT的参数。如下图:
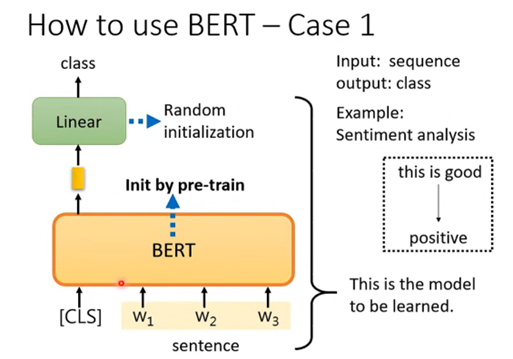
一般我们是将BERT和线型变换模块一起称为Sentiment analysis。
Case 2
这个任务是输入一排向量,输出是和输入相同数目的向量,例如词性标注问题。那么具体的方法也是很类似的,BERT的参数也是经过pre-train得到的,而线性变化的参数是随机初始化的,然后就通过一些有标注的样本进行学习,如下图:
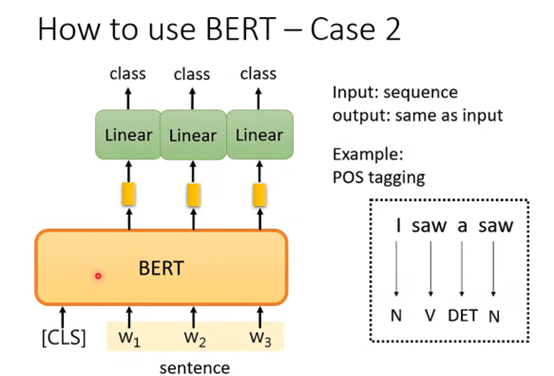
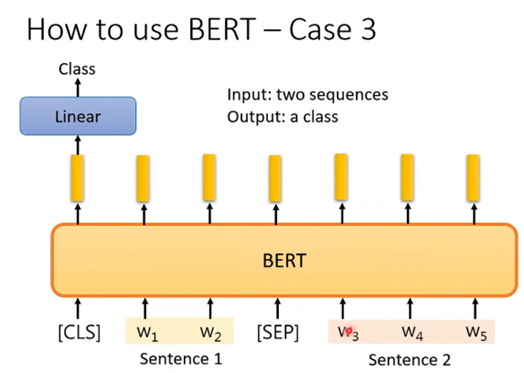
Case 3
在该任务中,输入是两个句子,输出是一个分类,例如自然语言推断问题,输入是一个假设和一个推论,而输出就是这个假设和推论之间是否是冲突的,或者是相关的,或者是没有关系的:
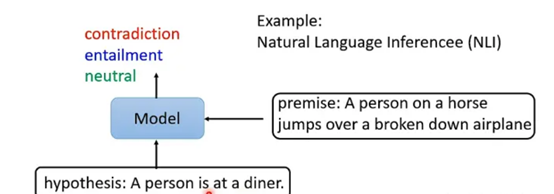
那么BERT对这类任务的做法也是类似的,因为要输出两个句子,因此在两个句子之间应该有一个SEP的特殊字符对应的向量,然后在开头也有CLS特殊字符对应的向量,并且由于输出是单纯一个分类,那关注的也是CLS对应的输出向量,将其放入线性变换模块再经过softmax就得到分类结果了。参数的设置跟之前都是一样的。如下图:
Case 4
BERT还可以用来做问答模型!但是对这个问答模型具有一定的限制,即需要提供给它一篇文章和一系列问题,并且要保证这些问题的答案都在文章之间出现过,那么经过BERT处理之后将会对一个问题输出两个正整数,这两个正整数就代表问题的答案在文章中的第几个单词到第几个单词这样截出来的句子,即下图的s和e就能够截取出正确答案。

那么我们要训练的就是随机初始化的两个向量和已经pre-train的BERT。
如何设计辅助任务?
在设计自监督辅助任务时,以下三点需要考虑:
1、Shotcuts: 根据自己的数据和任务特点设计辅助任务,常常有事半功倍的效果。比如对于镜头检测任务来说,获取成像色差、镜头畸变以及暗角等信息来构造辅助任务是比较有效的。
2、辅助任务的复杂度选择: 之前人们的实验结果表明,辅助任务并不是越复杂越有效,比如图像重组任务中,最优的patch数为9,patch太多会导致每个patch特征过少,并且相邻patch间的差异性不大,导致模型的学习效果并不好。
3、模糊性: 模糊性是指设计的辅助任务的标签必须是唯一确定的,不然会给网络学习引入噪声,影响模型性能。比如在动作预测中,这个半蹲的动作就具有二义性,因为其下个状态有可能是蹲下,也有可能是正在站起,标签不具有唯一性。
总结
找到合适的辅助任务(pretext)对于自监督学习是最需要解决的问题。与数据特点相比,辅助任务难一些有助于性能提升。数据和资源越多,自监督预训练的效果会更好(Bert)。















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









