






文章目录
摘要
本周阅读了一篇基于注意力的LSTM网络在大地震预测中的应用的文章,文章研究了一种基于注意力的LSTM网络,用于预测即将发生的大地震的时间、震级和位置。使用MSE、RMSE、MAE、R-squared和准确度等指标检查结果。与其他经验场景和选定的基线方法相比,提出的模型的性能结果明显更好。多头自注意力能够处理多个关注点的问题,可以较好地处理复杂语义关系,在预测任务中,能够明确结果是根据哪一属性判断得出。而掩码多头自注意力是Transformer中的关键模块,能够在掩码的基础上来实现并行训练。注意力机制可以将一句话整个输入却不考虑序列的顺序,而NLP需要有顺序的输入,因此需要通过位置编码为每一个向量加上位置信息。
Abstract
This week, an article about the application of attention-based LSTM network in earthquake prediction is readed. An attention-based LSTM network is researched in the paper to predict the time, magnitude and location of the upcoming earthquake. MSE, RMSE, MAE, R-squared and accuracy are used to check the results. Compared with other empirical scenarios and selected baseline methods, the performance results of the proposed model are obviously better. Multi-head self-attention can deal with multiple concerns and complex semantic relations, and in the prediction task, it can be clear which attribute the result is based on. Mask multi-head self-attention is the key module in Transformer, which can realize parallel training on the basis of mask. Attention mechanism can input the whole sentence without considering the sequence order, while NLP needs sequential input, so it is necessary to add position information to each vector through position coding.
文献阅读
题目
An attention-based LSTM network for large earthquake prediction
问题
由于地震的复杂性,预测地震的震级、时间和位置是一项具有挑战性的任务,因为地震没有显示出特定的模式,这可能导致预测不准确。但是,使用基于人工智能的模型,他们已经能够提供有希望的结果。然而,对于大地震预测,特别是将其作为回归问题进行研究的成熟研究却很少。
在过去的相关研究中,没有考虑到:
(1)震级预测的效率受限于某些数值范围的问题;
(2)基于位置的地震事件聚类可以保持基于位置的模式不变,因此聚类地震事件可以帮助做出更准确的预测;
(3)由于地震不遵循一定的模式,对于长期地震时间预测,大多数情况下会出现20天到5个月的误差,地震预测可以看作是一个时间序列分析问题。
贡献
1.应用K-Means算法将数据集划分为具有相同地震特征的地理集群,并产生位置相关预测。
2.研究了一种基于注意力的LSTM网络,用于预测即将发生的大地震的时间、震级和位置。其中LSTM用于学习时间关系,注意机制从输入特征中提取重要的模式和信息。
3.在序列数据上准备数据集,以解决时序误差问题,并实现与三个子模型相关联的公共输入层,分别预测震级、时间和位置。
基于注意力的LSTM网络
由于内存有限,在处理长序列的长期依赖关系时,LSTM的性能会迅速下降。深度学习中的注意机制就是为了解决这个问题而开发的,并加强了编码器-解码器架构。将注意力机制应用于LSTM可以使网络更多地关注与输出更相关的输入特征,并减轻无兴趣信息的干扰。
注意机制的主要目的是克服编码器-解码器系统存储较长序列的失败。注意机制选择性地关注一些最具影响力的信息,忽略不必要的信息,增强需要的信息。只使用输入序列中最重要的部分来关注相关信息所在的位置。注意机制的架构如下图所示。

图1:注意机制架构
注意机制的计算首先基于输入序列的编码器创建的隐藏状态。在这项工作中使用的编码器是LSTM算法,因为LSTM应该比RNN更好地捕获长期依赖关系,而RNN在某些情况下(如地震预测)往往会变得健忘。然后通过隐藏状态的加权和计算上下文向量。注意机制是在权重分布的基础上运作的,其中最相关的信息是通过分配更高的权重来确定的。因此,与标准模型相比,它具有很高的优化效果。注意函数的性质可以定义为查询到键值对序列的映射。
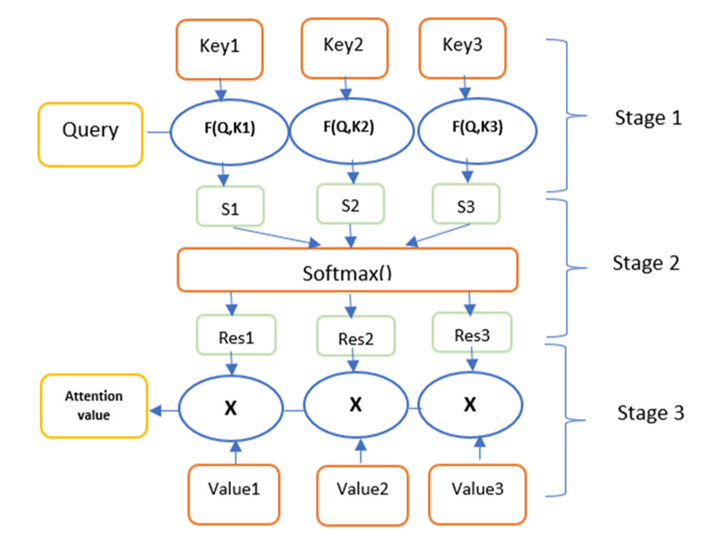
图2:注意机制中的键查询值
共享层是在同一模型中被重用多次的层实例,它们学习层图中多条路径对应的特征。在下图示例中,我们使用连接到三个LSTM顺序层的共享输入层。第一个预测震级,第二个预测时间,最后一个预测聚类位置。这三个模型连接到相同的输入层,这意味着它们都是用相同的地震数据值进行训练和测试的。
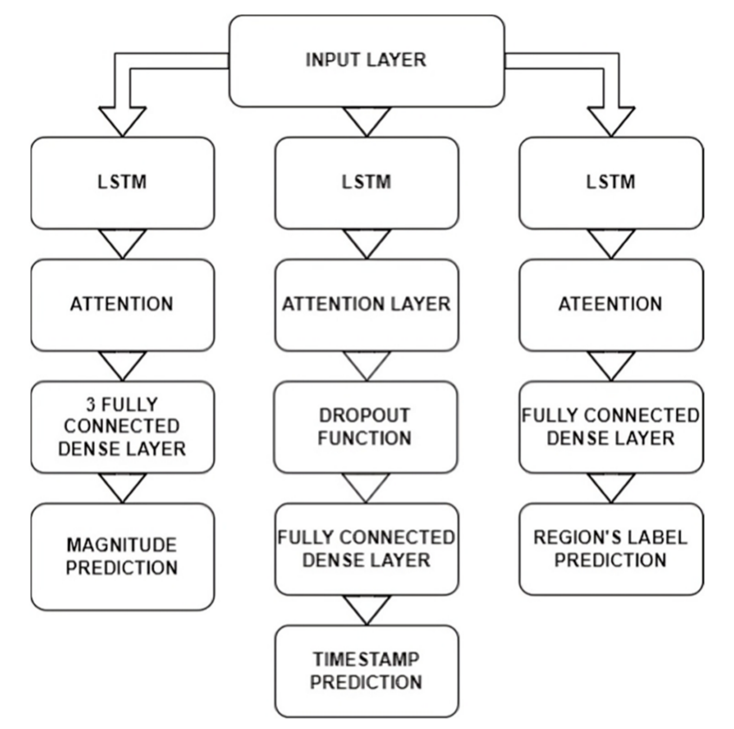
图3:基于注意力的模型图及其层结构
这种类型的实现帮助我们的模型分别独立地关注每个输出。例如,时间戳预测比幅度预测更容易处理,而时间戳预测具有非线性和复杂的行为。因此,如果我们在同一序列层中处理这两个结果,并使用具有多层LSTM的鲁棒模型,则时间戳预测将面临过拟合问题,相反,如果我们使用简单的LSTM模型,则幅度预测将面临欠拟合问题。如果单独对待每一个结果,顺序LSTM层可以根据结果的类型进行参数化,最优预测只会受到期望结果的影响。然后对每个结果的结果进行改进和优化。对于时间戳预测,采用一个包含基于注意力的LSTM层和dropout函数的模型,以避免过拟合。对于位置预测,提出了一个分类模型,该模型使用两个具有reLu激活函数的LSTM层进行热编码输出和一个具有softmax激活功能的全连接层。然而,震级预测将是最糟糕的,因为它们需要一个强大的模型来克服欠拟合,不像时间戳预测,它需要一个软模型和一个dropout函数。
实验
实验目的
使用性能指标检查我们提出的基于注意力的LSTM模型在日本地震数据集上的性能。然后,将结果与基线方法和两种经验情景进行比较,即(i)忽略注意力机制和(ii)使用多输出模型实现。
数据集
实验使用的地震数据集属于日本地区,日本以地震活动频繁而闻名,因为整个国家都位于地震高发区。此外,这个国家的特别之处在于它有能力通过世界上最密集的地震网络记录地震。使用的数据集来自美国地质调查局(USGS)的目录,地理参数为北纬45.614°和北经30.259°,东经146.074°和东经129.111°,包含1900年至2021年10月的历史地震事件。我们只选择震级>5的大地震,一共5546行数据。
评估指标
使用MSE、RMSE、MAE、r平方和准确性等指标检查结果。
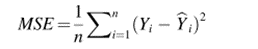

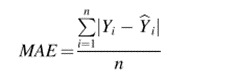

数据预处理和特征提取
USGS数据集包含几个特征。我们根据Pearson方法选择最重要和最相关的特征:地震事件的地理特征、经纬度、地震的深度(以公里为单位)、事件发生的年、月、日、时、分和秒、地震大小。
从初始特征出发,将时间和位置变量转化为更简单、更一致的特征。将日期和时间参数转换为一个代表性的特征,我们称之为时间戳。我们以秒为单位表示时间戳,以捕获简单信息中的时间模式,而不是日期(年、月、日)和时间(时、分、秒)等复杂信息。对于位置创建一个新变量,表示与每个地震事件相关联的位置集群。使用K-means算法根据地理特征(经纬度)选择位置聚类。因此获得了四个输入特征:位置集群、深度、震级和时间戳,并给出了三个输出:位置集群、深度和下一次地震事件的震级。
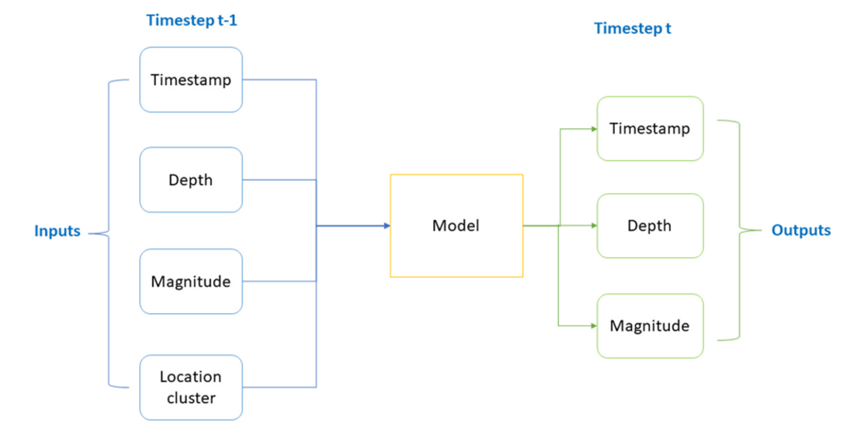
图4:预测模型的输入和输出的架构
选择重要特征后,使用最小-最大标量对数据集进行归一化。这个缩放器通过将每个特征缩放到0到1之间的范围来变换特征,原始分布的形状也可得以保留,原始数据中包含的信息不会被改变。然后,创建由时间步长t-1的输入和时间步长t的输出组成的监督数据集。将数据集分成80%的训练集和20%的测试集。
结果讨论
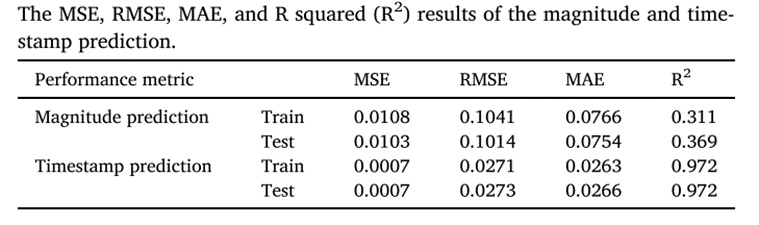
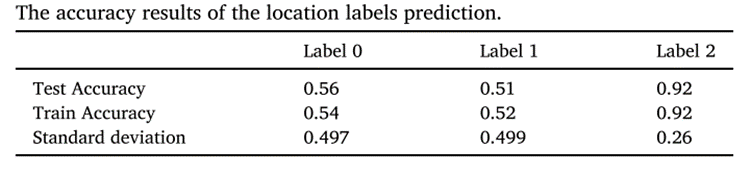
对于地震大小和时间戳预测的MSE、RMSE和MAE如下表所示。对于训练集和测试集,结果都很好。R平方是可用于评估模型性能的另一个性能指标,它描述了模型的拟合程度。时间戳预测由于其线性和简单性,可以达到较高的R2值。下表2为位置预测的结果。可以注意到,与其他区域相比,标记为标签2的区域的预测效果较好,这可能是由于该区域的数据分散程度较低,标准差较低。
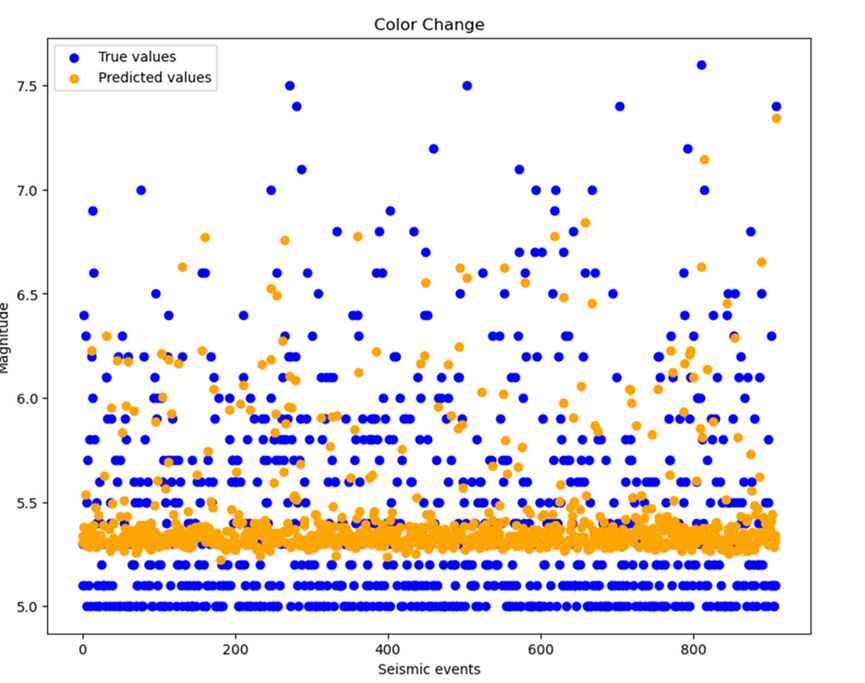
下图分别为实际和预测的震级和时间戳值的曲线,其中蓝色的点为真实值,黄色的点为预测值。在震级曲线显示中,预计将发生5.2到7级的地震。然而,由于其罕见性,高达7级的地震无法准确预测。在时间戳曲线显示中,预测结果与实际值的趋势一致,证实了时间戳预测的高效率。预测曲线的趋势与实际曲线大致相同,这证实了模型即使对于小地震数据集也是有效的。

深度学习
Masked Self-Attention(掩码自注意力)
自注意力机制将句子中的一个单词与句子中的所有单词联系起来,从而提取每个词的更多信息。自注意力机制可以明确的知道,给它的这句话有多少个单词,因此可以一次性得到这个句子的全部注意力值,即计算全部单词之间的注意力值。
掩码自注意力就是在自注意力的基础上进行改进, 因为对于生成模型来说,当生成单词的时候,它是一个一个生成的,如果采用自注意力机制对生成的单词做注意力计算的话,每次都是只能对当前已经生成的单词做计算。
例如给一句l have a dream,生成模型分四次生成:
第一次:l (第一次计算注意力只要计算l)
第二次:l have (第二次计算l和have)
第三次:l have a
第四次:l have a dream
即当前词只与前面的值jisuanattention,与后面的不计算。模型的注意力机制应该只与该词之前的单词有关,而不是其后的单词,因此可以通过掩盖后边所有还没有被模型预测的词实现。也就是为了防止泄露信息,避免模型在生成某个单词之前就见过该单词了,以免失去了生成的意义了。
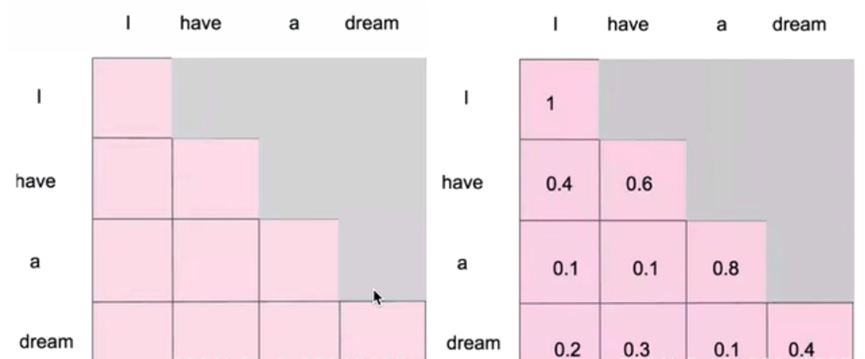
自注意力机制在训练的时候能够让它看到完整的句子,但是在预测或生成的时候,不能让模型看到整个句子,所以需要将后面的掩盖起来。
Muti-Head Self-Attention(多头自注意力)
self-attention中,给定一个X,通过自注意力模型得到一个Z(注意力值),这个Z就是对X的新的表征,Z这个词向量相比较X拥有了句法特征和语义特征,Z相较于X有了提升。自注意力机制的缺陷就是:模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置。而通过Muti-Head Self-Attention得到的Z’相较于Z又有了进一步提升。
多头注意力机制与使用单独的一个注意力池化不同,我们可以独立学习得到h组不同的线性投影(Linear)来变换查询、键和值。然后,这 h组变换后的查询、键和值将并行地进行注意力池化。最后,将这 h个注意力池化的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,以产生最终输出,其中 h个注意力池化输出中的每一个输出都被称作一个头。下图展示了使用全连接层来实现可以学习的线性变换的多头注意力。

捕捉不同子空间内的信息,子空间就可以看成一件事物的多个属性。那就是每个数据代表一个事物,而多头则代表了每个事物不同的属性方面,在求相似度时,由原来的单纯的事物相似 更加细致地演进到 属性相似,所以会更精准。比如人,张三跟李四相似,通常会体现很多方面,身高,体重,胖廋,血型,性格。多头注意力会告诉你张三之所以跟李四相似,是来源于身高,或者血型这些很具体的属性方面。因此多头注意力的优点是能够处理多个关注点的问题,可以较好地处理复杂语义关系。



Q:为什么head越多越好呢?
A:在做self-attention的时候,就是用 去找相关的k,但是相关这件事情有不同的形式、不同的定义,因此需要更多的q负责不同种类的相关性。
多头注意力机制的流程可以总结为以下几步:
- 将输入的序列数据分成多个头;
- 对每个头进行独立的查询、键、值线性变换;
- 对每个头进行自注意力计算,得到该头的输出;
- 将所有头的输出拼接在一起,并进行输出线性变换。
实现多头注意力机制层
import math
import torch
from torch import nn
from d2l import torch as d2l
def transpose_qkv(X,num_heads):
# 输入X的形状: (batch_size, 查询或者“键-值”对的个数, num_hiddens).
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状: (batch_size, 查询或者“键-值”对的个数, num_heads,num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X,num_heads):
#逆转 `transpose_qkv` 函数的操作
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
#定义多头自注意力模型
class MultiHeadAttention(nn.Module):
def __init__(self,key_size,query_size,value_size,num_hiddens,
num_heads,dropout,bias=False,**kwargs):
super(MultiHeadAttention,self).__init__(**kwargs)
self.num_heads = num_heads
#将Attention设置为Dot-Product Attention
self.attention = d2l.DotProductAttention(dropout)
# 将输入映射为(batch_size,query_size/k-v size,num_hidden)大小的输出
self.W_q = nn.Linear(query_size,num_hiddens,bias=bias)
self.W_k = nn.Linear(key_size,num_hiddens,bias=bias)
self.W_v = nn.Linear(value_size,num_hiddens,bias=bias)
self.W_o = nn.Linear(num_hiddens,num_hiddens,bias=bias)
def forward(self,queries,keys,values,valid_lens):
# `queries`, `keys`, or `values` 的形状:
# (`batch_size`, 查询或者“键-值”对的个数, `num_hiddens`)
# `valid_lens` 的形状:
# (`batch_size`,) or (`batch_size`, 查询的个数)
# 经过变换后,输出的 `queries`, `keys`, or `values` 的形状:
# (`batch_size` * `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
# 将多个头的数据堆叠在一起,然后进行计算,从而不用多次计算
if valid_lens is not None:
valid_lens = torch.repeat_interleave(valid_lens,
repeats=self.num_heads,
dim=0)
output = self.attention(queries,keys,values,valid_lens)
# output->(10,4,20)
return output
output_concat = transpose_output(output,self.num_heads)
# output_concat -> (2,4,100)
return self.W_o(output_concat)
#使用键和值相同的小例子来测试我们编写的 MultiHeadAttention 类
#多头注意力输出的形状是(batch_size、num_queries、num_hiddens)
# 线性变换的输出为100个,5个头
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,num_hiddens, num_heads, 0.5)
attention.eval()
MultiHeadAttention(
(attention): DotProductAttention(
(dropout): Dropout(p=0.5, inplace=False)
)
(W_q): Linear(in_features=100, out_features=100, bias=False)
(W_k): Linear(in_features=100, out_features=100, bias=False)
(W_v): Linear(in_features=100, out_features=100, bias=False)
(W_o): Linear(in_features=100, out_features=100, bias=False)
)
# 2个batch,4个query,6个键值对
batch_size, num_queries, num_kvpairs, valid_lens = 2, 4, 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens)) # query(2,4,100)
Y = torch.ones((batch_size, num_kvpairs, num_hiddens)) # key和value (2,6,100)
output = attention(X, Y, Y, valid_lens) # 输出大小与输入的query的大小相同
output.shape
#输出:torch.Size([2, 4, 100])
Masked Multi-head Self-Attention(掩码多头自注意力)
在需要进行掩码的基础上来实现并行(并行计算注意力值)训练
掩码多头自注意力被提出作为标准Transformer体系结构的关键模块,用于捕捉任何历史序列中的重要特征而不考虑距离。多头结构通过将多个自注意模块与不同状态子空间的特征学习相结合,可以显著提高长期依赖的学习性能。从本质上讲,掩码多头自注意力通过每个头部的相互作用可以获得更好的预测性能,而单头部结构只强调了某些阶段的重要特征而忽略了其他阶段。此外,为了解决时间序列预测问题,在掩码多头自注意力中引入了一个额外的掩码机制,以防止将未来的值添加到计算中。
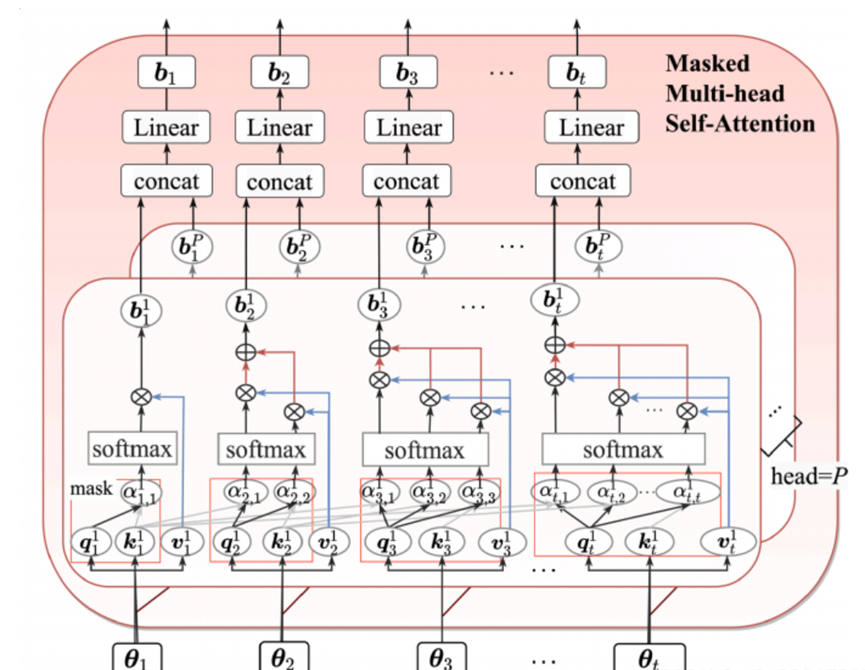
掩蔽多头自注意模块

总结
多头注意力融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。基于适当的张量操作,可以实现多头注意力的并行计算。















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









