






摘要
本周阅读了一篇关于循环神经网络的论文,论文中提出了一种新的循环神经网络架构,它使得同一层中的神经元彼此独立,并且可以跨层连接。文中的IndRNN可以很容易被调节,以防止梯度爆炸和梯度消失的问题,同时网络可以学习长期依赖性的任务,并且还可以堆叠多个IndRNN,以构建比现有RNN更深的网络。此外,还继续对LSTM进行推导和代码学习。
Abstract
This week, a paper about circular neural network is readed, in which a new circular neural network architecture is proposed, which makes neurons in the same layer independent of each other and can be connected across layers. IndRNN in this paper can be easily adjusted to prevent the problems of gradient explosion and gradient disappearance. At the same time, the network can learn long-term dependent tasks, and multiple IndRNN can be stacked to build a deeper network than the existing RNN. In addition, the derivation and code learning of LSTM are continued.
文献阅读
1. 题目
Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN
2. 传统RNN存在的问题
(1)在传统RNN中,层内按时间展开进行参数共享,出现了梯度消失和梯度爆炸的问题。
(2)在传统RNN中,层内神经元相互联系,导致难以对神经元的行为作出合理解释。
(3)LSTM/GRU中使用sigmoid/tanh饱和激活函数,在解决层内梯度消失/爆炸问题时,梯度仍然会在层间衰减,因此LSTM/GRU难以做成多层网络。
3. 创新点
本文提出了一种新型的RNN,独立递归神经网络(IndRNN),其中同一层中的神经元彼此独立,并且它们跨层连接。IndRNN容易调节,以防止梯度爆炸和消失问题,同时易于学习长期依赖关系。此外,IndRNN可以使用非饱和激活函数,如relu等。可以通过堆叠多个IndRNN来构建比现有RNN更深的网络。实验结果表明,所提出的IndRNN能够处理非常长的序列(超过5000个时间步),可以用于构建非常深的网络(实验中使用了21层)。与传统的RNN和LSTM相比,使用IndRNN在各种任务上取得了更好的性能。
4. RNN与IndRNN的对比
4.1 隐含层状态更新公式
RNN隐含层状态更新公式:

IndRNN隐含层状态更新公式:
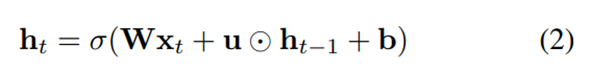
两者对比:
(1)RNN的计算公式为上一时刻的隐含层状态ht-1和权重矩阵相乘
(2)IndRNN计算公式为上一时刻的隐含层状态ht-1和权重向量点乘,点乘操作使
RNN层内神经元解耦,使它们相互独立,提高神经元的可解释性。
4.2 结构示意图


4.3 IndRNN的优势
(1)IndRNN将层内神经元解耦,使它们相互独立,提高神经元的可解释性。
(2)IndRNN能够使用Relu等非饱和激活函数,除了解决层内和层间梯度消失/爆炸问题外,模型还具有鲁棒性,可以构建更深的网络。
(3)IndRNN相比于LSTM,能处理更长(n>5000)的序列信息。
5. IndRNN的实现
5.1 RNN
RNN隐含层状态更新公式:

RNN反向传播:
设T时刻的目标函数为J,则反向传播到t时刻的梯度计算公式为:
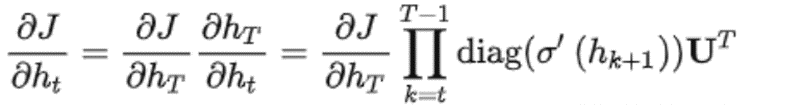
存在的问题:
(1)如果使用sigmoid或tanh激活函数,其导数的取值会小于1,与循环权重相乘构成的对角矩阵元素也会小于1,连积操作会导致梯度呈指数下降,造成梯度消失问题。
(2)如果使用relu激活函数,当x>0时,relu的导数恒大于1,因此当U中有元素大于1时,则构成的对角矩阵会有大于1的元素,连积操作会导致梯度呈指数增加,造成梯度爆炸问题。
5.2 LSTM
门控单元的作用:将激活函数导数的连乘变成加法
LSTM状态更新公式:
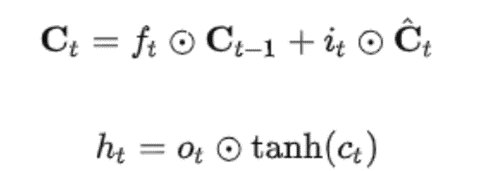
LSTM反向传播:
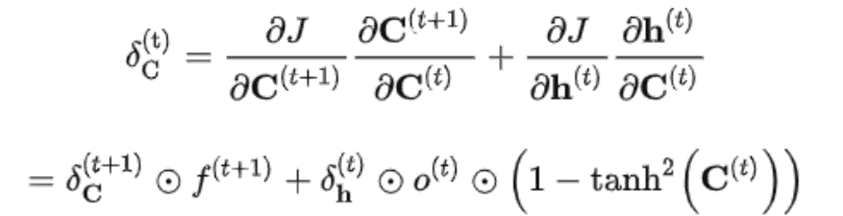
上图中f(t+1)控制梯度衰减的程度:
(1)当f(t+1)=1时,即使后面的项很小,梯度仍然能很好的传到上一时刻。
(2)当f(t+1)=0时,上一时刻信号不受到影响。
存在的问题:
(1)门控单元虽然有效缓解了梯度消失的问题,但是当序列长度过长时,梯度消失的问题仍会出现。
(2)由于门控单元的存在,使计算过程无法并行,增大了计算复杂度。
(3) 因为多层LSTM依旧采用tanh激活函数,层与层之间的梯度消失仍未解决,所以LSTM一般为2到3层。
5.3 IndRNN的初始化
IndRNN使用ReLU作为激活函数,将权重矩阵初始化为单位矩阵,将偏置初始化为0。
5.4 梯度截断
方法:在反向传播中,人为设定传递多少步,即可看作设定对角矩阵连乘几次,强行拉回到正常值,再进行梯度下降。
问题:加入了人为因素,最后得到的值不一定准确。
5.5 IndRNN
IndRNN隐含层状态更新公式:
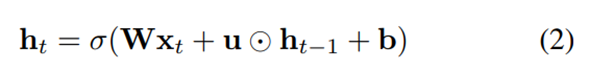
反向传播:
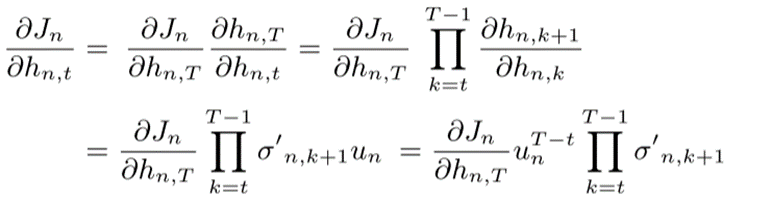
从上图中可以看出,此时的连积操作已经不再是矩阵操作,而是激活函数的导数与循环权重系数独立起来。我们只需要对un约束到合适的范围,就可以避免梯度问题。
神经元之间的相互连接依赖于层间交互来完成。也就是说,下一层的神将元会接受上一层所有神经元的输出作为输入,相当于全连接层。
IndRNN可实现多层堆叠。因为在多层堆叠结构中,层间交互是全连接方式,因此可以进行改进,比如改全连接方式为CNN连接,也可以引入BN、残差连接等。
6.实验结果
实验在三个评估RNN模型的常用任务上进行,以验证IndRNN的长程记忆能力和深层网络训练的可行性,此为验证性实验,然后在骨骼动作识别任务上进行预测,此为实验性实验。
6.1 Adding Problem
实验中输入两个序列,第一个序列是在(0, 1)范围内均匀采样,第二个序列由两个数字组成,分别为1和0。
实验序列长度:100,500和1000
其中:均方误差(MSE)用作目标函数和Adam优化方法用于训练。
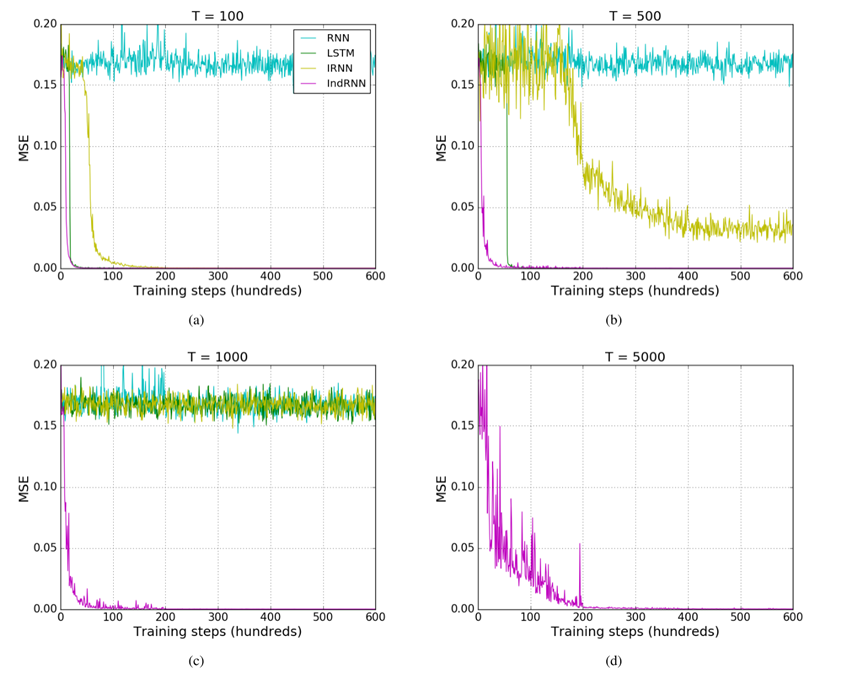
从上图中可以看出,IRNN和LSTM只能处理500步到1000步的序列,而IndRNN可以轻松处理时间跨度为5000步的序列数据。
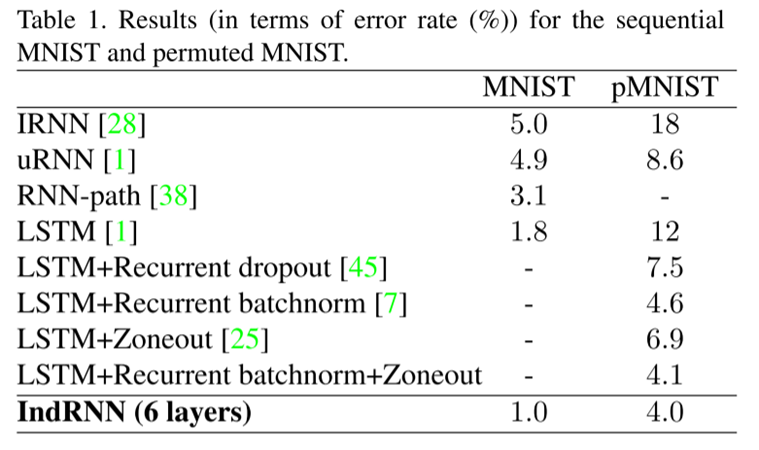
6.2 Sequential MNIST Classification
实验中输入一串MINIST像素点的数据,然后进行分类。pMINIST 是在MINIST任务上增加了难度,对像素点数据进行了置换。
6.3 Language Modeling
实验在字符级别PTB数据集上进行语言模型的评估。在该任务中,为了验证IndRNN可以构造深层网络,论文中给出了21层IndRNN的训练以及结果,对比6层IndRNN的结果,得到加深后的IndRNN表现更好。

6.4 Skeleton Based Action Recognition
实验使用了NTU RGB+D数据库,是当时为止最大的基于骨骼的动作识别数据库。

深度学习
LSTM公式推导
前向传播

反向传播
反向传播需要定义c, h的反向传播误差量,t代表第t个时间步,h是隐藏层,c是LSTM存储长期记忆信息的路径。

接下来计算每一时间步中h的反向传播误差值:

同理,可以用每一个时间步中h的反向传播值计算出c中每一个时间步的反向传播值:
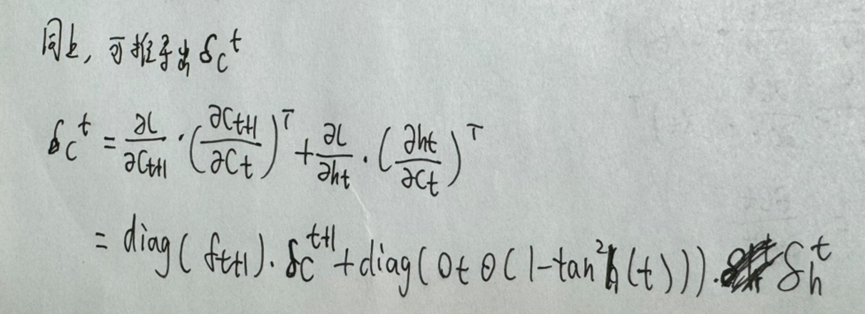
更新遗忘门、输入门、输出门各个时间步的权重值和偏差值:

LSTM代码示例
在输入一串连续质数时预估下一个质数:
#lstm在输入一串连续质数时预估下一个质数
import random
import numpy as np
import math
def sigmoid(x):
return 1. / (1 + np.exp(-x))
# createst uniform random array w/ values in [a,b) and shape args
def rand_arr(a, b, *args):
np.random.seed(0)
return np.random.rand(*args) * (b - a) + a
class LstmParam:
def __init__(self, mem_cell_ct, x_dim):
self.mem_cell_ct = mem_cell_ct
self.x_dim = x_dim
concat_len = x_dim + mem_cell_ct
# weight matrices
self.wg = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
self.wi = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
self.wf = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
self.wo = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
# bias terms
self.bg = rand_arr(-0.1, 0.1, mem_cell_ct)
self.bi = rand_arr(-0.1, 0.1, mem_cell_ct)
self.bf = rand_arr(-0.1, 0.1, mem_cell_ct)
self.bo = rand_arr(-0.1, 0.1, mem_cell_ct)
# diffs (derivative of loss function w.r.t. all parameters)
self.wg_diff = np.zeros((mem_cell_ct, concat_len))
self.wi_diff = np.zeros((mem_cell_ct, concat_len))
self.wf_diff = np.zeros((mem_cell_ct, concat_len))
self.wo_diff = np.zeros((mem_cell_ct, concat_len))
self.bg_diff = np.zeros(mem_cell_ct)
self.bi_diff = np.zeros(mem_cell_ct)
self.bf_diff = np.zeros(mem_cell_ct)
self.bo_diff = np.zeros(mem_cell_ct)
def apply_diff(self, lr = 1):
self.wg -= lr * self.wg_diff
self.wi -= lr * self.wi_diff
self.wf -= lr * self.wf_diff
self.wo -= lr * self.wo_diff
self.bg -= lr * self.bg_diff
self.bi -= lr * self.bi_diff
self.bf -= lr * self.bf_diff
self.bo -= lr * self.bo_diff
# reset diffs to zero
self.wg_diff = np.zeros_like(self.wg)
self.wi_diff = np.zeros_like(self.wi)
self.wf_diff = np.zeros_like(self.wf)
self.wo_diff = np.zeros_like(self.wo)
self.bg_diff = np.zeros_like(self.bg)
self.bi_diff = np.zeros_like(self.bi)
self.bf_diff = np.zeros_like(self.bf)
self.bo_diff = np.zeros_like(self.bo)
class LstmState:
def __init__(self, mem_cell_ct, x_dim):
self.g = np.zeros(mem_cell_ct)
self.i = np.zeros(mem_cell_ct)
self.f = np.zeros(mem_cell_ct)
self.o = np.zeros(mem_cell_ct)
self.s = np.zeros(mem_cell_ct)
self.h = np.zeros(mem_cell_ct)
self.bottom_diff_h = np.zeros_like(self.h)
self.bottom_diff_s = np.zeros_like(self.s)
self.bottom_diff_x = np.zeros(x_dim)
class LstmNode:
def __init__(self, lstm_param, lstm_state):
# store reference to parameters and to activations
self.state = lstm_state
self.param = lstm_param
# non-recurrent input to node
self.x = None
# non-recurrent input concatenated with recurrent input
self.xc = None
def bottom_data_is(self, x, s_prev = None, h_prev = None):
# if this is the first lstm node in the network
if s_prev == None: s_prev = np.zeros_like(self.state.s)
if h_prev == None: h_prev = np.zeros_like(self.state.h)
# save data for use in backprop
self.s_prev = s_prev
self.h_prev = h_prev
# concatenate x(t) and h(t-1)
xc = np.hstack((x, h_prev))
self.state.g = np.tanh(np.dot(self.param.wg, xc) + self.param.bg)
self.state.i = sigmoid(np.dot(self.param.wi, xc) + self.param.bi)
self.state.f = sigmoid(np.dot(self.param.wf, xc) + self.param.bf)
self.state.o = sigmoid(np.dot(self.param.wo, xc) + self.param.bo)
self.state.s = self.state.g * self.state.i + s_prev * self.state.f
self.state.h = self.state.s * self.state.o
self.x = x
self.xc = xc
def top_diff_is(self, top_diff_h, top_diff_s):
# notice that top_diff_s is carried along the constant error carousel
ds = self.state.o * top_diff_h + top_diff_s
do = self.state.s * top_diff_h
di = self.state.g * ds
dg = self.state.i * ds
df = self.s_prev * ds
# diffs w.r.t. vector inside sigma / tanh function
di_input = (1. - self.state.i) * self.state.i * di
df_input = (1. - self.state.f) * self.state.f * df
do_input = (1. - self.state.o) * self.state.o * do
dg_input = (1. - self.state.g ** 2) * dg
# diffs w.r.t. inputs
self.param.wi_diff += np.outer(di_input, self.xc)
self.param.wf_diff += np.outer(df_input, self.xc)
self.param.wo_diff += np.outer(do_input, self.xc)
self.param.wg_diff += np.outer(dg_input, self.xc)
self.param.bi_diff += di_input
self.param.bf_diff += df_input
self.param.bo_diff += do_input
self.param.bg_diff += dg_input
# compute bottom diff
dxc = np.zeros_like(self.xc)
dxc += np.dot(self.param.wi.T, di_input)
dxc += np.dot(self.param.wf.T, df_input)
dxc += np.dot(self.param.wo.T, do_input)
dxc += np.dot(self.param.wg.T, dg_input)
# save bottom diffs
self.state.bottom_diff_s = ds * self.state.f
self.state.bottom_diff_x = dxc[:self.param.x_dim]
self.state.bottom_diff_h = dxc[self.param.x_dim:]
class LstmNetwork():
def __init__(self, lstm_param):
self.lstm_param = lstm_param
self.lstm_node_list = []
# input sequence
self.x_list = []
def y_list_is(self, y_list, loss_layer):
"""
Updates diffs by setting target sequence
with corresponding loss layer.
Will *NOT* update parameters. To update parameters,
call self.lstm_param.apply_diff()
"""
assert len(y_list) == len(self.x_list)
idx = len(self.x_list) - 1
# first node only gets diffs from label ...
loss = loss_layer.loss(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h = loss_layer.bottom_diff(self.lstm_node_list[idx].state.h, y_list[idx])
# here s is not affecting loss due to h(t+1), hence we set equal to zero
diff_s = np.zeros(self.lstm_param.mem_cell_ct)
self.lstm_node_list[idx].top_diff_is(diff_h, diff_s)
idx -= 1
### ... following nodes also get diffs from next nodes, hence we add diffs to diff_h
### we also propagate error along constant error carousel using diff_s
while idx >= 0:
loss += loss_layer.loss(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h = loss_layer.bottom_diff(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h += self.lstm_node_list[idx + 1].state.bottom_diff_h
diff_s = self.lstm_node_list[idx + 1].state.bottom_diff_s
self.lstm_node_list[idx].top_diff_is(diff_h, diff_s)
idx -= 1
return loss
def x_list_clear(self):
self.x_list = []
def x_list_add(self, x):
self.x_list.append(x)
if len(self.x_list) > len(self.lstm_node_list):
# need to add new lstm node, create new state mem
lstm_state = LstmState(self.lstm_param.mem_cell_ct, self.lstm_param.x_dim)
self.lstm_node_list.append(LstmNode(self.lstm_param, lstm_state))
# get index of most recent x input
idx = len(self.x_list) - 1
if idx == 0:
# no recurrent inputs yet
self.lstm_node_list[idx].bottom_data_is(x)
else:
s_prev = self.lstm_node_list[idx - 1].state.s
h_prev = self.lstm_node_list[idx - 1].state.h
self.lstm_node_list[idx].bottom_data_is(x, s_prev, h_prev)
测试代码
import numpy as np
from lstm import LstmParam, LstmNetwork
class ToyLossLayer:
"""
Computes square loss with first element of hidden layer array.
"""
@classmethod
def loss(self, pred, label):
return (pred[0] - label) ** 2
@classmethod
def bottom_diff(self, pred, label):
diff = np.zeros_like(pred)
diff[0] = 2 * (pred[0] - label)
return diff
def example_0():
# learns to repeat simple sequence from random inputs
np.random.seed(0)
# parameters for input data dimension and lstm cell count
mem_cell_ct = 100
x_dim = 50
concat_len = x_dim + mem_cell_ct
lstm_param = LstmParam(mem_cell_ct, x_dim)
lstm_net = LstmNetwork(lstm_param)
y_list = [-0.5,0.2,0.1, -0.5]
input_val_arr = [np.random.random(x_dim) for _ in y_list]
for cur_iter in range(100):
print "cur iter: ", cur_iter
for ind in range(len(y_list)):
lstm_net.x_list_add(input_val_arr[ind])
print "y_pred[%d] : %f" % (ind, lstm_net.lstm_node_list[ind].state.h[0])
loss = lstm_net.y_list_is(y_list, ToyLossLayer)
print "loss: ", loss
lstm_param.apply_diff(lr=0.1)
lstm_net.x_list_clear()
if __name__ == "__main__":
example_0()
总结
本周对RNN及LSTM等知识进行复习和进一步的学习,下周将对时序模型的文章作进一步的阅读。















 3502
3502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









