






文章目录
摘要
本周阅读了一篇基于FAM—LSTM模型的日光温室温湿度多步超前预测的文章,该研究中构建了一个FAM-LSTM模型,用于日光温室温度和湿度的多步预测。实验证明,与其他模型相比,FAM-LSTM模型因其高精度而脱颖而出。模型在4个预报层的温度预报误差分别基本在[-0.5,0.9]、[-2.1,1.7]、[-0.9,2.7]和[-1.8,2.9] ℃以内。模型在4个预报层的湿度预报误差主要分别在[-1.9,1.8]、[-4.4,3.6]、[-6.9,2.4]和[-5.8,4.4] %以内。该研究为日光温室的精确环境调控和危害预警提供了一种有效的温湿度预测方法。
Abstract
This week, an article on multi-step advanced prediction of temperature and humidity in solar greenhouse based on FAM-LSTM model is readed. In this study, a FAM-LSTM model is constructed for multi-step prediction of temperature and humidity in solar greenhouse. Experiments show that FAM-LSTM model stands out from other models because of its high accuracy. The temperature prediction errors of the model in the four prediction layers are basically within [-0.5, 0.9], [-2.1, 1.7], [-0.9, 2.7] and [-1.8, 2.9]℃ respectively. The humidity forecast errors of the model in the four forecast layers are mainly within [-1.9, 1.8], [-4.4, 3.6], [-6.9, 2.4] and [-5.8, 4.4]% respectively. This study provides an effective temperature and humidity prediction method for precise environmental regulation and hazard early warning of solar greenhouse.
文献阅读
题目
Multistep ahead prediction of temperature and humidity in solar greenhouse based on FAM-LSTM model
创新点
通过物联网技术获取实验数据。
下图说明了通过物联网技术获取实验数据的流程。首先,传感器采集的数据通过ZigBee技术发送到网关,并通过GPRS技术传输到基站。随后,服务器与基站进行通信,并将获取的数据保存到数据库中。最后,用户可以从应用平台或移动应用程序下载数据。

该论文将LSTM与FAM相结合,提出了一种基于FAM-LSTM模型的温室温湿度时间序列预测模型
首先,利用LSTM模型来处理多元时间序列数据特征。随后,将FAM用于描述未来时间步长与每个时间步长的历史数据之间的关系。然后,通过向每个时间步长输入不同权重并加权求和来提取主要影响。
具体而言,本研究贡献如下:
1) 本研究的目的是实现精确的多变量时间序列预测,采用FAM在不同的时间步长为输入特征生成不同的注意力权重,以预测温室温度和湿度。
2) 利用皮尔逊相关系数(PCC)来识别影响温室内温度和湿度变化的主要因素。建立了一个数据集,并将FAM与各种深度学习模型集成,以实现对日光温室温度和湿度在不同水平的多步预测。
3) 将前馈注意机制—长短期记忆(FAM—LSTM)模型的准确性和误差与RNN、LSTM、GRU、FAM—RNN和FAM—GRU模型进行了对比。结果表明,FAM—LSTM模型能够实现温室温湿度的多步精确预测。
方法
网络架构
向量组首先经过lstm与dropout处理,然后输入注意力机制,随后输入全连接层后输出。
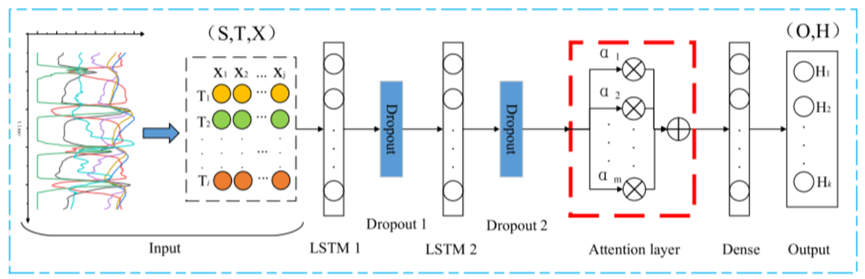
输入层:模型的输入是多维时间序列特征。输入层将输入数据转换为适合LSTM模型结构的三维数组形状(输入样本、时间步长、特征)(S,T,X),其中,S为输入样本的数量, (i为输入序列的时间步,Ti表示第i个时间步)
(i为输入序列的时间步,Ti表示第i个时间步)
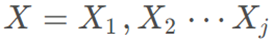 (j为输入序列的特征维度,X j表示表示第j维特征)
(j为输入序列的特征维度,X j表示表示第j维特征)
输出层:输出层用于实现预测结果的输出,输出维度为(输出样本,时间步)(O,H)。其中,O是输入样本的数量,  (k是当前时间的向后预测时间步,Hk表示当前时间之后第k个时间步的预测温度)
(k是当前时间的向后预测时间步,Hk表示当前时间之后第k个时间步的预测温度)
LSTM

LSTM神经网络在t时刻的工作原理如下:

feed-forward attention mechanism
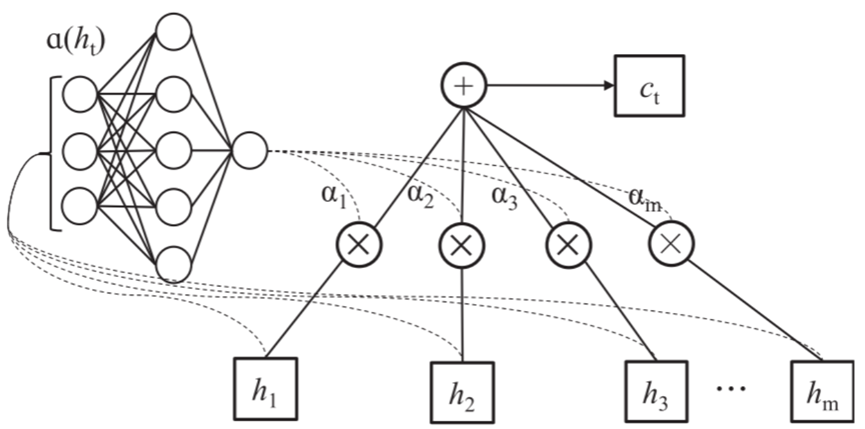
计算每个输入序列的重要性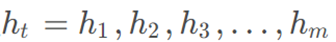 (其中m表示t时刻的输入序列的数量,hm表示第m个输入序列),如式(9)所示。注意力计算过程生成输入ht在各个时间步的概率向量
(其中m表示t时刻的输入序列的数量,hm表示第m个输入序列),如式(9)所示。注意力计算过程生成输入ht在各个时间步的概率向量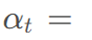
 ,如式(10)。此时的输出向量ct是由式(11)中定义的。αt为权重对输入进行自适应加权平均得到的。
,如式(10)。此时的输出向量ct是由式(11)中定义的。αt为权重对输入进行自适应加权平均得到的。
FAM神经网络在t时刻的工作原理如下:
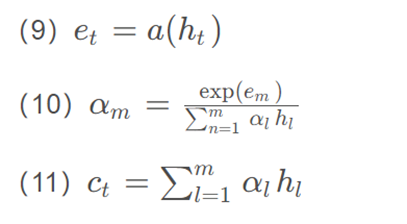
其中,a是可学习的函数; m是t时刻输入序列的数量; αm为t时刻第m个输入序列的概率向量;ct是t时刻输入序列的加权平均值。
实验过程
Data acquisition
试验于2021年11月1日至2022年1月31日在中国陕西省西北农林科技大学泾阳蔬菜试验示范站温室(N108°48′,E34°36′)进行,获得环境有关日光温室生产过程的数据。为了在线获取温室内外的环境参数,实验采用了实验室开发的农业物联网监测平台(https://ems.nwsuaf.edu.cn)。
Data preprocessing
Missing values为了降低传感器采集或传输问题引起的数据丢失和异常对模型性能的影响,采用箱线图来检查数据的整体分布情况并剔除异常数据,以保证数据集的连续性和准确性。低于和高于第 25 个和第 75 个百分位数减去或加上 1.5 倍四分位数范围的数据(Ritter, 2023)将被试作异常值并删除。对于缺失数量低于5的,使用线性插值填充;填充数据为最接近缺失值且具有相同天气条件的数据。
Selection of input variables为了增强模型的有效性,使用PCC计算IAT、IAH和其他环境因素之间的相关系数,计算公式如下:

Normalization采用线性归一化方法使数据保持同一维数,计算公式如下:
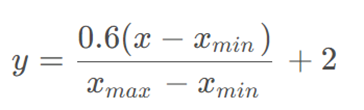
Data preparation使用滑动窗口技术对归一化数据进行划分。

Algorithm parameter settings
参数设置如下:学习率为0.01,优化器为Adam,batch size为32,epoch设置为200。输入窗口为48。模型在 t+24(12h)、t+48(24h)、t+72(36h)和t+96(48h)的不同预测窗口进行训练。将原始数据集分为训练集和测试集,划分比例分别为6:4、7:3和8:2。输入和输出窗口在整个时间序列中同时滑动,步长为30 min。
Models evaluation
平均绝对误差 (MAE) 和均方根误差 (RMSE)
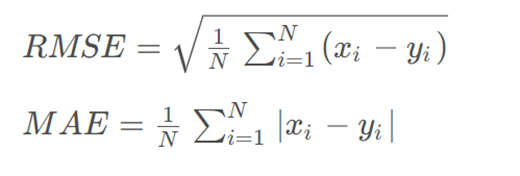

Correlation analysis of impact factors
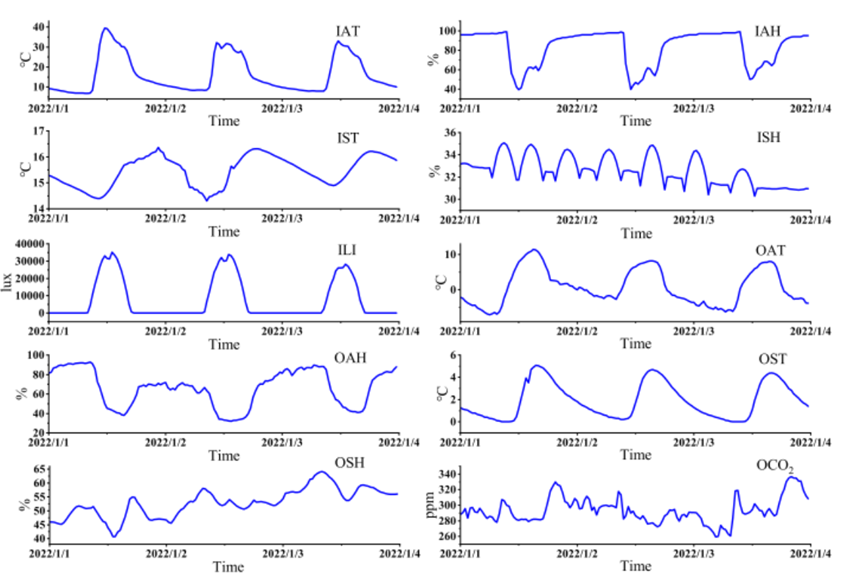
利用重采样功能对原始数据进行下采样,以减少数据冗余并满足建模要求。将时间频率转换为30分钟并与平均值聚合。下图展示了各种环境因素随时间变化的趋势和周期性。
实验结果
在相同的原始数据集上进行,并与RNN、LSTM、GRU、FAM-RNN和FAM-GRU模型进行对比,以验证FAM-LSTM模型的性能。下表显示了6个模型在输出标准t+24、t+48、t+72和t+96时温室IAT预测的性能。
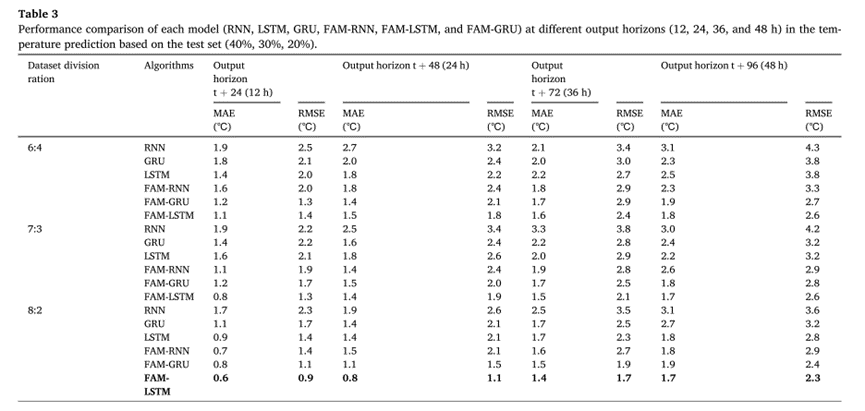
由表可知,对于6:4、7:3和8:2的不同数据集划分比例LSTM 和 GRU 模型比 RNN 模型表现出更高的预测精度。
添加FAM后,FAM-RNN、FAM-LSTM和FAM-GRU模型的预测精度优于RNN、LSTM和GRU模型。
当数据集划分比例为8:2时,FAM-LSTM模型的MAE和RMSE最低。
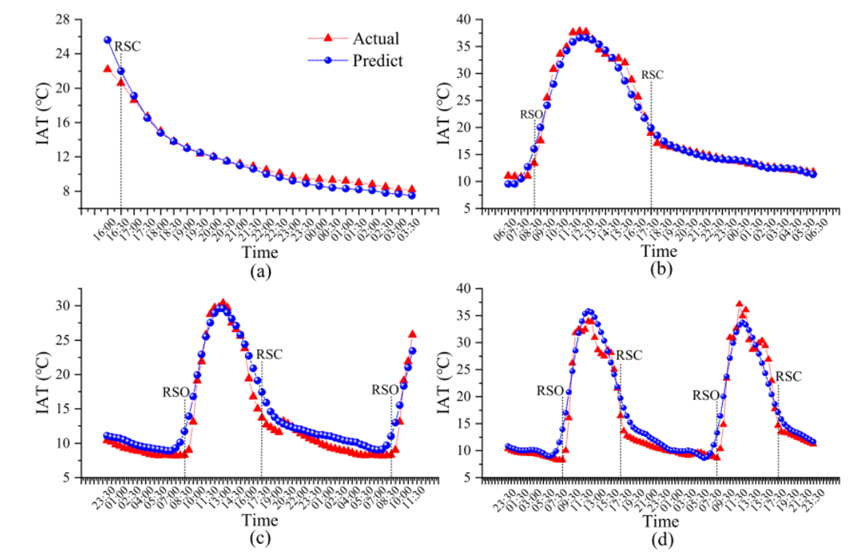
FAM-LSTM 模型在不同的预测范围内独立训练。12、24、36、48h不同预测层位下的实际值与预测值的比较结果如图 8所示。FAM-LSTM模型预测在不同预测层位下均准确地拟合了真实数据,但由于卷帘的影响,在8:30和17:00的预测误差相对较高,未来可引入光强度以改进模型。
Performances of different models in indoor air humidity prediction
下表显示了RNN、LSTM、GRU、FAM-LSTM、FAM-RNN和FAM-GRU模型在12、24、36、48h输出范围内预测IAH的性能。
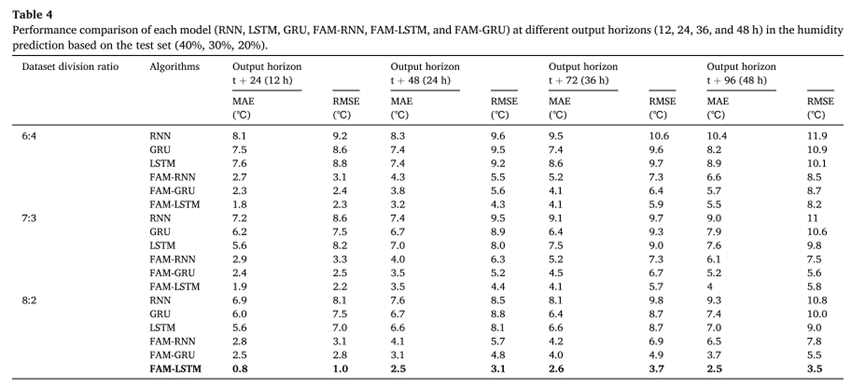
添加FAM后效果相对于原模型均有一定程度的提升,且在实验的模型中FAM-LSTM模型具有最好的预测性能。
下图显示了FAM-LSTM模型在不同预测范围内的实际湿度和预测湿度之间的比较结果。基于FAM-LSTM模型,预测湿度与实际湿度非常吻合。
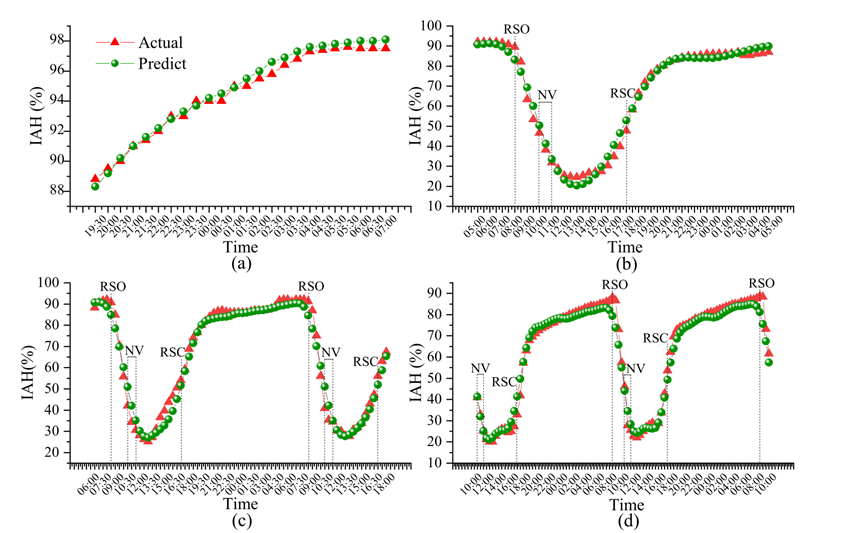
当光强度变化时,有一定程度误差,未来可引入光强度以改进模型。
自然通风(NV)会降低实际空气湿度(Hou et al., 2021)。该操作会增加预测湿度和测量湿度之间的差异。上图(d)显示了从NV开始的48h湿度预测结果。
考虑了通风后环境因素的变化,得到了比NV期间其他预测结果更准确的预测结果(上图(b),©)。
深度学习
ARIMA
一、ARIMA模型的基本思想
ARIMA模型全称为自回归差分移动平均模型(Autoregressive Integrated Moving Average Model)。ARIMA模型主要由三部分构成,分别为自回归模型(AR)、差分过程(I)和移动平均模型(MA)。
ARIMA模型的基本思想是利用数据本身的历史信息来预测未来。一个时间点上的标签值既受过去一段时间内的标签值影响,也受过去一段时间内的偶然事件的影响,这就是说,ARIMA模型假设:标签值是围绕着时间的大趋势而波动的,其中趋势是受历史标签影响构成的,波动是受一段时间内的偶然事件影响构成的,且大趋势本身不一定是稳定的。
简而言之,ARIMA模型就是试图通过数据的自相关性和差分的方式,提取出隐藏在数据背后的时间序列模式,然后用这些模式来预测未来的数据。
其中:
1、AR部分用于处理时间序列的自回归部分,它考虑了过去若干时期的观测值对当前值的影响。
2、I部分用于使非平稳时间序列达到平稳,通过一阶或者二阶等差分处理,消除了时间序列中的趋势和季节性因素。
3、MA部分用于处理时间序列的移动平均部分,它考虑了过去的预测误差对当前值的影响。
结合这三部分,ARIMA模型既可以捕捉到数据的趋势变化,又可以处理那些有临时、突发的变化或者噪声较大的数据。所以,ARIMA模型在很多时间序列预测问题中都有很好的表现。
二、ARIMA模型的数学表达式

这个公式基本上是将AR模型和MA模型的公式组合在一起:
1、AR部分表示当前值 eq?Y_%7Bt%7D与它过去的值有关,这个部分的形式与AR模型的公式一致。
2、MA部分表示当前值eq?Y_%7Bt%7D与它过去的误差项有关,这个部分的形式与MA模型的公式一致。
值得注意的是,MA模型中代表长期趋势的均值μ并不存在于ARIMA模型的公式当中,因为ARIMA模型中“预测长期趋势”这部分功能由AR模型来执行,因此AR模型替代了原本的μ。在ARIMA模型中,c可以为0。
另外,这个公式的基础是假设我们正在处理的时间序列是平稳的,这样我们可以直接应用AR和MA模型。如果时间序列是非平稳的,那么我们就需要考虑ARIMA模型中的I部分,也就是进行差分处理。
上述模型被称之为ARIMA(p,d,q)模型,其中p和q的含义与原始MA、AR模型中完全一致,且p和q可以被设置为不同的数值,而d是ARIMA模型需要的差分的阶数。
三、差分过程
1、什么是差分
差分是一种数学操作,用于计算一组数值序列中相邻数据点的差值。在时间序列分析中,差分常用于将非平稳序列转化为平稳序列,也就是减小或消除时间序列的趋势和季节性变化。
当我们对一个序列进行差分运算,就意味着我们会计算该序列中的不同观测值之间的差异。
简单地说,如果我们有一个时间序列Yt,那么该序列的一阶差分就可以定义为:
这样,我们得到一个新的时间序列,其每一个值都是原时间序列中相邻两个值的差。
让我们以一个简单的例子来具体理解理解差分操作:
假设我们有以下一组时间序列数据:Y=4,8,6,5,3,4
我们可以看到,这个序列的长度是6。现在,我们希望对这个序列进行一阶差分。
第一步,我们计算第二个数据点和第一个数据点的差,也就是8-4=4。
第二步,我们计算第三个数据点和第二个数据点的差,也就是6-8=-2。
依次类推,我们计算出所有相邻数据点之间的差值,得到一个新的序列:
△y=4,-2,-1,-2,1
我们可以看到,差分后的序列比原序列短了一位,因为差分操作实际上计算的是原序列中的相邻数据点之间的差值。同时,差分后的序列相比于原序列,其趋势和季节性变化都得到了一定程度的消除。通常进行一次差分运算,原始的序列会变短1个单位。
在实际进行差分运算时,我们可以改变差分运算的两个相关因子来执行不同的差分:一个是差分的阶数(order),另一个是差分的滞后(lag)。
2、差分的阶数
在上一节,我们介绍了一阶差分。然而,实际上,差分的阶数可以是任何正整数。差分的阶数就是我们需要进行多少次差分操作才能得到一个平稳序列。
具体地说,二阶差分就是对一阶差分后的序列再次进行差分。如果我们有一个时间序列 Y t {Y_t} Yt,那么该序列的二阶差分就可以定义为:
这样,我们得到一个新的时间序列,其每一个值都是原时间序列中相邻两个值的差的差。
3、什么是滞后?
在时间序列分析中,"滞后"是一个非常重要的概念。滞后实际上是描述了时间序列数据点之间的时间差。举个例子,对于一个月度数据的时间序列, 就代表了Yt-1到Yt这一个月的滞后。
差分的滞后(lag)与差分的阶数完全不同。正常的一阶差分是滞后为1的差分(lag-1 Differences),这代表在差分运算中,我们让相邻的两个观测值相减,即让间隔为(lag-1)的两个观测值相减。因此,当滞后为2时,则代表我们需要让相隔1个值的两个观测值相减。
在ARIMA模型中,我们经常需要计算滞后d期的时间序列数据。这就意味着我们需要查找在t时刻前d个时间单位的数据。
4、滞后差分(多步差分)
滞后差分(Lag Differences)是在进行差分操作时,不是用相邻的观测值进行相减,而是用相隔一定数量(即滞后数量)的观测值进行相减。这种操作通常在时间序列具有周期性的情况下非常有用,例如,当我们处理的数据随季节有规律地波动或者随一周的时间有规律地波动时。
5、使用差分消除数据波动
在时间序列中,标签往往具备一定的周期性:例如,标签可能随季节有规律地波动(比如在夏季标签值高、在冬季标签值较低等),也可能随一周的时间有规律地波动(比如在周末较高、在工作日较低等)。这种波动可以通过滞后差分来消除,我们生成一个人造的不平稳时间序列,并通过差分使其平稳。我们将利用Numpy和Pandas库生成这个序列,然后用同样的步骤进行检验和可视化。代码如下:
# 导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import adfuller
# 创建一个函数来检查数据的平稳性
def test_stationarity(timeseries):
# 执行Dickey-Fuller测试
print('Results of Dickey-Fuller Test:')
dftest = adfuller(timeseries, autolag='AIC')
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic', 'p-value', '#Lags Used', 'Number of Observations Used'])
for key, value in dftest[4].items():
dfoutput['Critical Value (%s)' % key] = value
print(dfoutput)
# 生成不平稳的时间序列
np.random.seed(0)
n = 100
x = np.cumsum(np.random.randn(n))
# 把它转换成Pandas的DataFrame格式
df = pd.DataFrame(x, columns=['value'])
# 检查原始数据的平稳性
test_stationarity(df['value'])
# 进行一阶差分
df['first_difference'] = df['value'] - df['value'].shift(1)
# 检查一阶差分后的数据的平稳性
test_stationarity(df['first_difference'].dropna())
# 进行二阶差分
df['second_difference'] = df['first_difference'] - df['first_difference'].shift(1)
# 检查二阶差分后的数据的平稳性
test_stationarity(df['second_difference'].dropna())
# 可视化原始数据和差分后的数据
plt.figure(figsize=(12, 6))
plt.plot(df['value'], label='Original')
plt.plot(df['first_difference'], label='1st Order Difference')
plt.plot(df['second_difference'], label='2nd Order Difference')
plt.legend(loc='best')
plt.title('Original and Differenced Time Series')
plt.show()
运行结果如下:

这段代码首先创建了一个不平稳的时间序列。然后,它对原始数据、一阶差分数据和二阶差分数据进行了平稳性检验。最后,它画出了原始数据以及一阶和二阶差分数据的图形。
在你运行这段代码之后,你应该会看到,原始数据不平稳,一阶差分后的数据仍然不完全平稳,而二阶差分后的数据就已经变得平稳了。
总结
ARIMA模型的核心思想是利用数据的历史信息来预测未来趋势。对时间序列预测的全面探索让我了解了像CoST这样创新性框架,还为我提供了对传统模型如ARIMA基本原理的深入理解。这些经验的综合使我更全面地理解了时间序列预测,强调了在这一不断发展领域中创新与传统方法的重要性。















 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









