






 本文详细解释了自注意力机制中如何运用掩码技术,包括paddingmask处理输入序列对齐和填充部分,以及sequencemask防止解码器看到未来信息。通过window_partition和softmax操作,确保模型专注于有效信息并避免不必要的干扰。
本文详细解释了自注意力机制中如何运用掩码技术,包括paddingmask处理输入序列对齐和填充部分,以及sequencemask防止解码器看到未来信息。通过window_partition和softmax操作,确保模型专注于有效信息并避免不必要的干扰。
在自注意力机制中,掩码是一种用来控制模型在处理序列数据时忽略无效部分的技术。具体来说,掩码是一个与输入序列的长度相同的、由0和1组成的矩阵。其中,0表示对应位置是无效的,1表示对应位置是有效的。
在自注意力机制中,掩码被用来屏蔽(即将其值置为一个很小的负无穷)无效的位置。这样,在进行自注意力计算时,无效位置的权重就会变得非常小(接近于0),从而将其对最终结果的影响降到最小。
掩码的作用是确保模型不会关注到输入序列中的填充部分(即长度不足的部分),这在处理变长序列时非常重要。通过使用掩码,模型能够更好地捕捉到序列中的有效信息。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
Padding Mask
padding mask:因为每个批次输入序列长度是不一样,需要对输入序列进行对齐。给较短的序列后面填充 0,对于输入太长的序列,截取左边的内容,把多余的直接舍弃。这些填充的位置,没什么意义,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
Sequence mask
sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
具体做法:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上。
对于 decoder 的 self-attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
其他情况,attn_mask 一律等于 padding mask。
编码器处理输入序列,最终输出为一组注意向量k和v。每个解码器将在其“encoder-decoder attention”层中使用k,v注意向量,这有助于解码器将注意力集中在输入序列中的适当位置。
掩码的生成具体实现如下:、
-
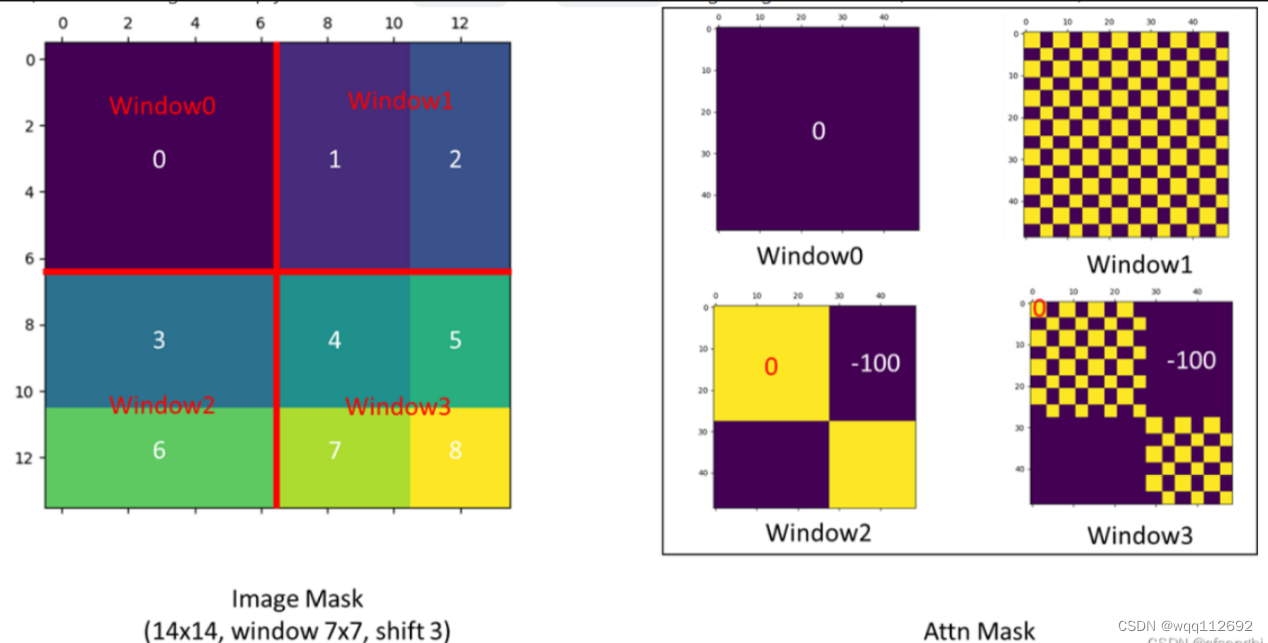
def calculate_mask(self, x_size): # calculate attention mask for SW-MSA H, W = x_size img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1,初始化推向掩码 h_slices = (slice(0, -self.window_size), # slice 函数来生成用于切片操作的索引,从位置0开始到位置-self.window_size结束的切片操作 slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None)) # 高度的大小 w_slices = (slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None)) # 从位置-self.shift_size开始到最后位置结束的切片操作 cnt = 0 for h in h_slices: for w in w_slices: img_mask[:, h, w, :] = cnt cnt += 1 # 掩码的设置,需要的地方设置为1,不需要的地方设置为0 mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1,掩码的窗口划分 mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # 维度调整 attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # 创建注意力机制中的掩码张量,以便在自注意力或其他形式的掩码注意力中屏蔽掉不需要的位置 attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0)) # masked_fill 函数的作用是将输入张量中满足掩码条件的元素替换为指定的值 return attn_mask

















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









