







最大熵模型中的数学推导
0 引言
写完SVM之后,一直想继续写机器学习的系列,无奈一直时间不稳定且对各个模型算法的理解尚不够,所以导致迟迟未动笔。无独有偶,重写KMP得益于今年4月个人组织的算法班,而动笔继续写这个机器学习系列,正得益于今年10月组织的机器学习班。
10月26日机器学习班第6次课,邹讲最大熵模型,从熵的概念,讲到为何要最大熵、最大熵的推导,以及求解参数的IIS方法,整个过程讲得非常流畅,特别是其中的数学推导。晚上我把上课PPT 在微博上公开分享了出来,但对于没有上过课的朋友直接看PPT 会感到非常跳跃,因此我打算针对机器学习班的某些次课写一系列博客,刚好也算继续博客中未完的机器学习系列。
综上,本文结合10月机器学习班最大熵模型的PPT和其它相关资料写就,可以看成是课程笔记或学习心得,着重推导。有何建议或意见,欢迎随时于本文评论下指出,thanks。
1 预备知识
- 大写字母X表示随机变量,小写字母x表示随机变量X的某个具体的取值;
- P(X)表示随机变量X的概率分布,P(X,Y)表示随机变量X、Y的联合概率分布,P(Y|X)表示已知随机变量X的情况下随机变量Y的条件概率分布;
- p(X = x)表示随机变量X取某个具体值的概率,简记为p(x);
- p(X = x, Y = y) 表示联合概率,简记为p(x,y),p(Y = y|X = x)表示条件概率,简记为p(y|x),且有:p(x,y) = p(x) * p(y|x)。
- 如果函数y=f(x)在[a, b]上连续,且其在(a,b)上可导,如果其导数f’(x) >0,则代表函数f(x)在[a,b]上单调递增,否则单调递减;如果函数的二阶导f''(x) > 0,则函数在[a,b]上是凹的,反之,如果二阶导f''(x) < 0,则函数在[a,b]上是凸的。
- 设函数f(x)在x0处可导,且在x处取得极值,则函数的导数F’(x0) = 0。
- 以二元函数z = f(x,y)为例,固定其中的y,把x看做唯一的自变量,此时,函数对x的导数称为二元函数z=f(x,y)对x的偏导数。
- 为了把原带约束的极值问题转换为无约束的极值问题,一般引入拉格朗日乘子,建立拉格朗日函数,然后对拉格朗日函数求导,令求导结果等于0,得到极值。
更多请查看《高等数学上下册》、《概率论与数理统计》等教科书,或参考本博客中的:数据挖掘中所需的概率论与数理统计知识。
2 何谓熵?
从名字上来看,熵给人一种很玄乎,不知道是啥的感觉。其实,熵的定义很简单,即用来表示随机变量的不确定性。之所以给人玄乎的感觉,大概是因为为何要取这样的名字,以及怎么用。
熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度。在信息论里面,熵是对不确定性的测量。
2.1 熵的引入
事实上,熵的英文原文为entropy,最初由德国物理学家鲁道夫·克劳修斯提出,其表达式为:
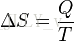
它表示一个系系统在不受外部干扰时,其内部最稳定的状态。后来一中国学者翻译entropy时,考虑到entropy是能量Q跟温度T的商,且跟火有关,便把entropy形象的翻译成“熵”。
我们知道,任何粒子的常态都是随机运动,也就是"无序运动",如果让粒子呈现"有序化",必须耗费能量。所以,温度(热能)可以被看作"有序化"的一种度量,而"熵"可以看作是"无序化"的度量。
如果没有外部能量输入,封闭系统趋向越来越混乱(熵越来越大)。比如,如果房间无人打扫,不可能越来越干净(有序化),只可能越来越乱(无序化)。而要让一个系统变得更有序,必须有外部能量的输入。
若无特别指出,下文中所有提到的熵均为信息熵。
2.2 熵的定义
把最前面的负号放到最后,便成了:
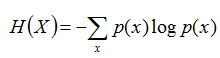
上面两个熵的公式,无论用哪个都行,而且两者等价,一个意思(这两个公式在下文中都会用到)。
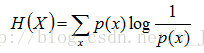
联合熵:两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用H(X,Y)表示。
条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。
且有此式子成立:H(Y|X) = H(X,Y) – H(X),整个式子表示(X,Y)发生所包含的熵减去X单独发生包含的熵。至于怎么得来的请看推导:
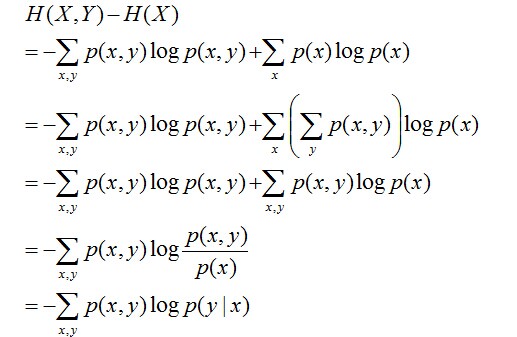
简单解释下上面的推导过程。整个式子共6行,其中
- 第二行推到第三行的依据是边缘分布p(x)等于联合分布p(x,y)的和;
- 第三行推到第四行的依据是把公因子logp(x)乘进去,然后把x,y写在一起;
- 第四行推到第五行的依据是:因为两个sigma都有p(x,y),故提取公因子p(x,y)放到外边,然后把里边的-(log p(x,y) - log p(x))写成- log (p(x,y)/p(x) ) ;
- 第五行推到第六行的依据是:p(x,y) = p(x) * p(y|x),故p(x,y) / p(x) = p(y|x)。
相对熵:又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:
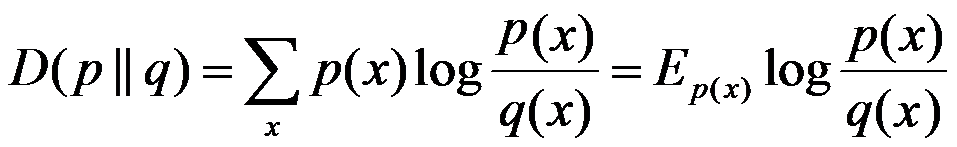
在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。
互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示:
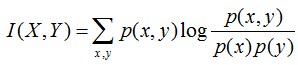
且有I(X,Y)=D(P(X,Y) || P(X)P(Y))。下面,咱们来计算下H(Y)-I(X,Y)的结果,如下:
通过上面的计算过程,我们发现竟然有H(Y)-I(X,Y) = H(Y|X)。故通过条件熵的定义,有:H(Y|X) = H(X,Y) - H(X),而根据互信息定义展开得到H(Y|X) = H(Y) - I(X,Y),把前者跟后者结合起来,便有I(X,Y)= H(X) + H(Y) - H(X,Y),此结论被多数文献作为互信息的定义。
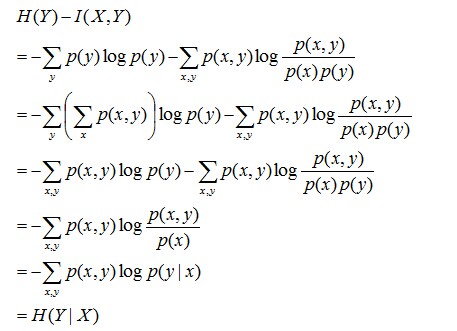
3 最大熵
3.1 无偏原则
- 令x1表示“学习”被标为名词, x2表示“学习”被标为动词。
- 令y1表示“学习”被标为主语, y2表示被标为谓语, y3表示宾语, y4表示定语。
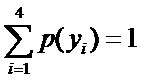 , 则根据无偏原则,认为这个分布中取各个值的概率是相等的,故得到:
, 则根据无偏原则,认为这个分布中取各个值的概率是相等的,故得到:
因为没有任何的先验知识,所以这种判断是合理的。如果有了一定的先验知识呢?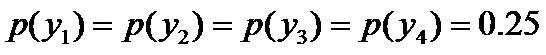
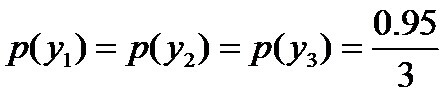
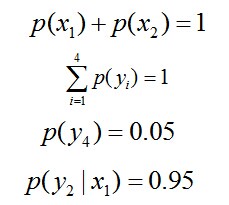
因此,也就引出了最大熵模型的本质,它要解决的问题就是已知X,计算Y的概率,且尽可能让Y的概率最大(实践中,X可能是某单词的上下文信息,Y是该单词翻译成me,I,us、we的各自概率),从而根据已有信息,尽可能最准确的推测未知信息,这就是最大熵模型所要解决的问题。
相当于已知X,计算Y的最大可能的概率,转换成公式,便是要最大化下述式子H(Y|X):
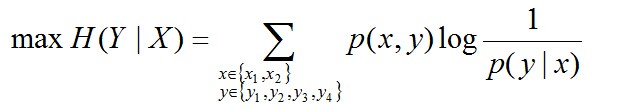
且满足以下4个约束条件:
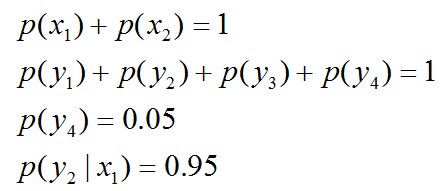
3.2 最大熵模型的表示
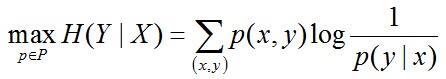
- y:这个特征中需要确定的信息
- x:这个特征中的上下文信息

特征函数关于经验分布
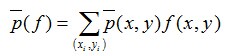
换言之,如果能够获取训练数据中的信息,那么上述这两个期望值相等,即: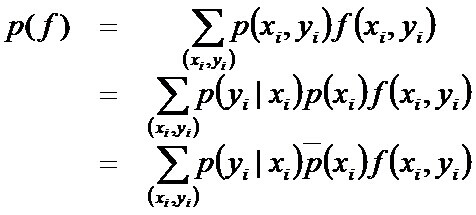
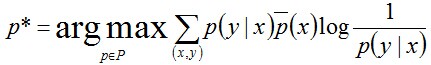
其约束条件为:
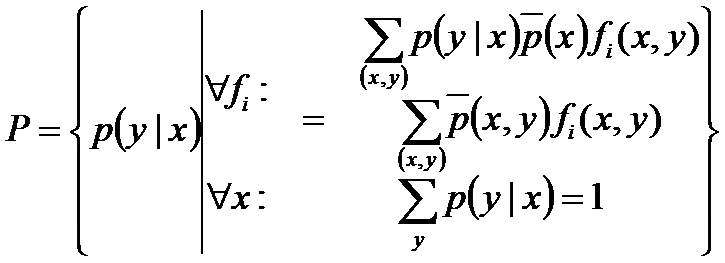
该问题已知若干条件,要求若干变量的值使到目标函数(熵)最大,其数学本质是最优化问题(Optimization Problem),其约束条件是线性的等式,而目标函数是非线性的,所以该问题属于非线性规划(线性约束)(non-linear programming with linear constraints)问题,故可通过引入Lagrange函数将原带约束的最优化问题转换为无约束的最优化的对偶问题。
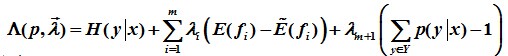
3.3 凸优化中的对偶问题
考虑到机器学习里,不少问题都在围绕着一个“最优化”打转,而最优化中凸优化最为常见,所以为了过渡自然,这里简单阐述下凸优化中的对偶问题。
一般优化问题可以表示为下述式子:
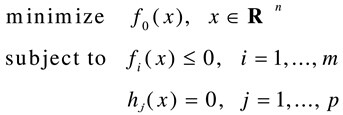
其中,subject to导出的是约束条件,f(x)表示不等式约束,h(x)表示等式约束。
然后可通过引入拉格朗日乘子λ和v,建立拉格朗日函数,如下:
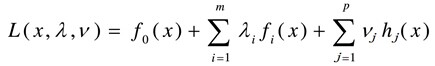
对固定的x,Lagrange函数L(x,λ,v)为关于λ和v的仿射函数。
3.4 对偶问题极大化的指数解
针对原问题,首先引入拉格朗日乘子λ0,λ1,λ2, ..., λi,定义拉格朗日函数,转换为对偶问题求其极大化:
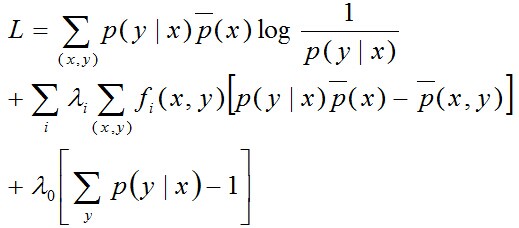
然后求偏导,:
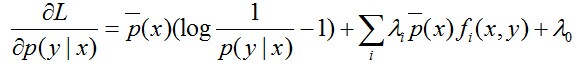
注:上面这里是对P(y|x)求偏导,即只把P(y|x)当做未知数,其他都是常数。因此,求偏导时,只有跟P(y0|x0)相等的那个"(x0,y0)"才会起作用,其他的(x,y)都不是关于P(y0|x0)的系数,是常数项,而常数项一律被“偏导掉”了。
令上述的偏导结果等于0,解得:
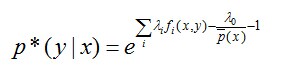
进一步转换:
其中,Z(x)称为规范化因子。
根据之前的约束条件之一: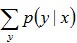
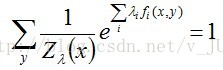
从而有
现将求得的最优解P*(y|x)带回之前建立的拉格朗日函数L
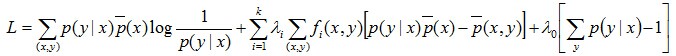
得到关于λ的式子:
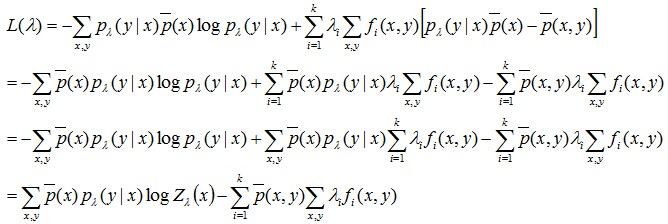
注:最后一步的推导中,把之前得到的结果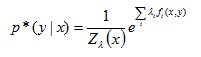
接下来,再回过头来看这个式子:
可知,最大熵模型模型属于对数线性模型,因为其包含指数函数,所以几乎不可能有解析解。换言之,即便有了解析解,仍然需要数值解。那么,能不能找到另一种逼近?构造函数f(λ),求其最大/最小值?
相当于问题转换成了寻找与样本的分布最接近的概率分布模型,如何寻找呢?你可能想到了极大似然估计。
3.5 最大熵模型的极大似然估计
记得13年1月份在微博上说过:所谓最大似然,即最大可能,在“模型已定,参数θ未知”的情况下,通过观测数据估计参数θ的一种思想或方法,换言之,解决的是取怎样的参数θ使得产生已得观测数据的概率最大的问题。
举个例子,假设我们要统计全国人口的身高,首先假设这个身高服从服从正态分布,但是该分布的均值与方差未知。由于没有足够的人力和物力去统计全国每个人的身高,但是可以通过采样(所有的采样要求都是独立同分布的),获取部分人的身高,然后通过最大似然估计来获取上述假设中的正态分布的均值与方差。
极大似然估计MLE的一般形式表示为:
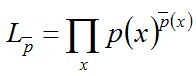
其中,是对模型进行估计的概率分布,
是实验结果得到的概率分布。
进一步转换,可得:
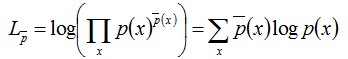
对上式两边取对数可得:
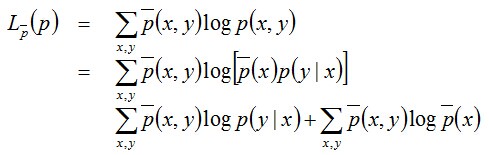
因上述式子最后结果的第二项是常数项(因为第二项是关于样本的联合概率和样本自变量的式子,都是定值),所以最终结果为:
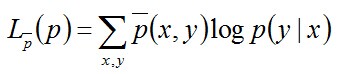
至此,我们发现极大似然估计和条件熵的定义式具有极大的相似性,故可以大胆猜测它们极有可能殊途同归,使得它们建立的目标函数也是相同的。 我们来推导下,验证下这个猜测。
将之前得到的最大熵的解带入MLE,计算得到(右边在左边的基础上往下再多推导了几步):
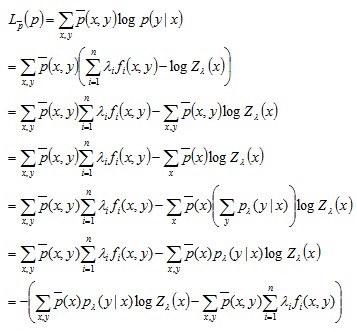
注:其中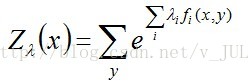
然后拿这个通过极大似然估计得到的结果
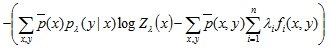
跟之前得到的对偶问题的极大化解
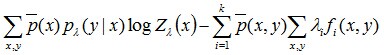
只差一个“-”号,所以只要把原对偶问题的极大化解也加个负号,等价转换为对偶问题的极小化解:
则与极大似然估计的结果具有完全相同的目标函数。
换言之,之前最大熵模型的对偶问题的极小化等价于最大熵模型的极大似然估计。
且根据MLE的正确性,可以断定:最大熵的解(无偏的对待不确定性)同时是最符合样本数据分布的解,进一步证明了最大熵模型的合理性。两相对比,熵是表示不确定性的度量,似然表示的是与知识的吻合程度,进一步,最大熵模型是对不确定度的无偏分配,最大似然估计则是对知识的无偏理解。
4 参数求解法:IIS
回顾下之前最大熵模型的解:
其中
对数似然函数为:
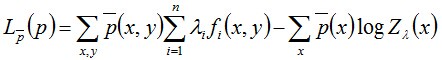
相当于现在的问题转换成:通过极大似然函数求解最大熵模型的参数,即求上述对数似然函数参数λ 的极大值。此时,通常通过迭代算法求解,比如改进的迭代尺度法IIS、梯度下降法、牛顿法或拟牛顿法。这里主要介绍下其中的改进的迭代尺度法IIS。
改进的迭代尺度法IIS的核心思想是:假设最大熵模型当前的参数向量是λ,希望找到一个新的参数向量λ+δ,使得当前模型的对数似然函数值L增加。重复这一过程,直至找到对数似然函数的最大值。
下面,咱们来计算下参数λ 变到λ+δ的过程中,对数似然函数的增加量,用L(λ+δ)-L(λ)表示,同时利用不等式:-lnx ≥1-x , x>0,可得到对数似然函数增加量的下界,如下:
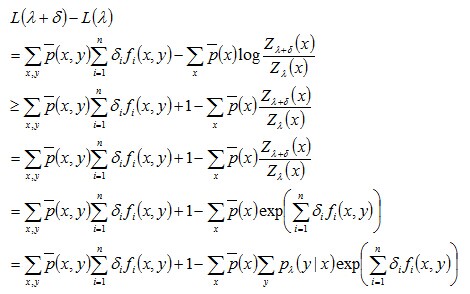
将上述求得的下界结果记为A(δ | λ),为了进一步降低这个下界,即缩小A(δ | λ)的值,引入一个变量:
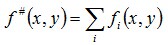
其中,f 是一个二值函数,故f#(x, y)表示的是所有特征(x, y)出现的次数,然后利用Jason不等式,可得:
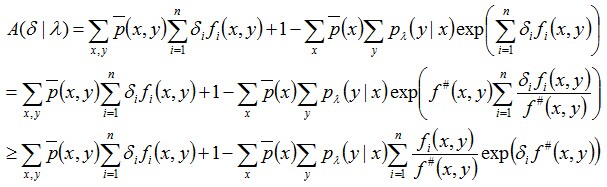
我们把上述式子求得的A(δ | λ)的下界记为B(δ | λ):
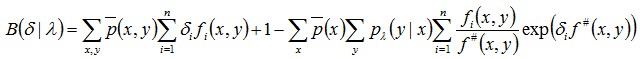
相当于B(δ | λ)是对数似然函数增加量的一个新的下界,可记作:L(λ+δ)-L(λ) >= B(δ | λ)。
接下来,对B(δ | λ)求偏导,得:
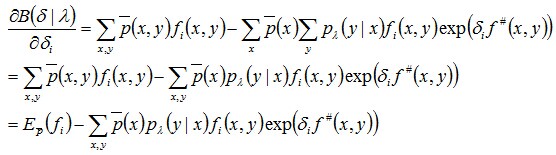
此时得到的偏导结果只含δ,除δ之外不再含其它变量,令其为0,可得:
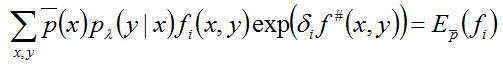
从而求得δ,问题得解。
值得一提的是,在求解δ的过程中,如果若f#(x,y)=M为常数,则
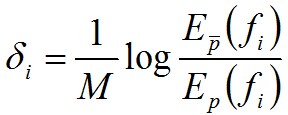
否则,用牛顿法解决:
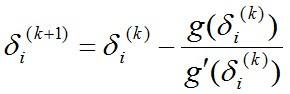
求得了δ,便相当于求得权值λ,最终将λ 回代到下式中:
即得到最大熵模型的最优估计。
5 参考文献
- 一堆wikipedia,热力学熵:http://zh.wikipedia.org/zh-mo/%E7%86%B5,信息熵:http://zh.wikipedia.org/wiki/%E7%86%B5_(%E4%BF%A1%E6%81%AF%E8%AE%BA),百度百科:http://baike.baidu.com/view/401605.htm;
- 熵的社会学意义:http://www.ruanyifeng.com/blog/2013/04/entropy.html;
- 北京10月机器学习班之邹博的最大熵模型PPT:http://pan.baidu.com/s/1qWLSehI;
- 北京10月机器学习班之邹博的凸优化PPT:http://pan.baidu.com/s/1sjHMj2d;
- 《统计学习方法 李航著》;
- 最大熵学习笔记:http://blog.csdn.net/itplus/article/details/26549871;
- 2013年在微博上关于极大似然估计的讨论:http://weibo.com/1580904460/zfUsAgCl2?type=comment#_rnd1414644053228;
- 极大似然估计:http://www.cnblogs.com/liliu/archive/2010/11/22/1883702.html;
- 数据挖掘中所需的概率论与数理统计知识:http://blog.csdn.net/v_july_v/article/details/8308762。
- 数学之美系列十六--谈谈最大熵模型:http://www.cnblogs.com/kevinyang/archive/2009/02/01/1381798.html。
















 3089
3089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











