




大家好,我是汤师爷,AI智能体架构师,致力于帮助100W人用智能体创富~
选题对内容创作至关重要,但面对海量信息,找到有价值的爆款选题并不容易。
对标账号监控是内容创作者制定策略的有效工具。
通过跟踪和分析行业内优秀创作者的内容,我们能获得市场洞察和创作灵感,避免从零摸索。
这个方法尤其适合新手创作者,帮助他们快速了解哪类内容最受欢迎。
1. 为什么要做对标账号监控
1、帮助发现行业趋势
通过观察头部创作者的内容变化,我们能及时把握行业热点和用户兴趣的转变。
例如,当多个知名美妆博主同时开始测评某款新产品时,这很可能意味着该产品正成为市场热点。
及时跟进这类话题,可以帮我们搭上流量红利的顺风车。
2、提供内容创作参考框架
通过分析成功账号的视频标题、封面设计、内容结构和互动策略,我们可以提取有效的内容模式。
这些模式不是用来简单复制,而是帮助我们理解哪些元素能引起用户共鸣,从而优化自己的创作。
3、提升创作效率
在内容创作的海洋中,没有明确方向很容易迷失和浪费资源。借鉴成功账号的经验,可以帮我们避开许多不必要的弯路,将有限的精力集中在已被验证有效的内容策略上。
2. 智能体的搭建流程
智能体的搭建流程主要分为两个步骤:梳理工作流和设置智能体。
1、梳理工作流
将对标账号监控的场景流程转化为可自动化运行的工作流节点。下面是具体步骤:
- 根据短视频链接,获取用户的基础信息
- 根据用户ID,批量获取视频列表
- 筛选出对标账号每天发布的视频
- 将数据添加到飞书表格中
2、设置智能体
- 设置人设与逻辑:配置对标账号监控智能体的特征、回复风格和决策逻辑
- 绑定工作流:将工作流与智能体关联,赋予其执行具体任务的能力
- 测试并发布:进行全面的功能测试,确认正常后将智能体正式发布到生产环境
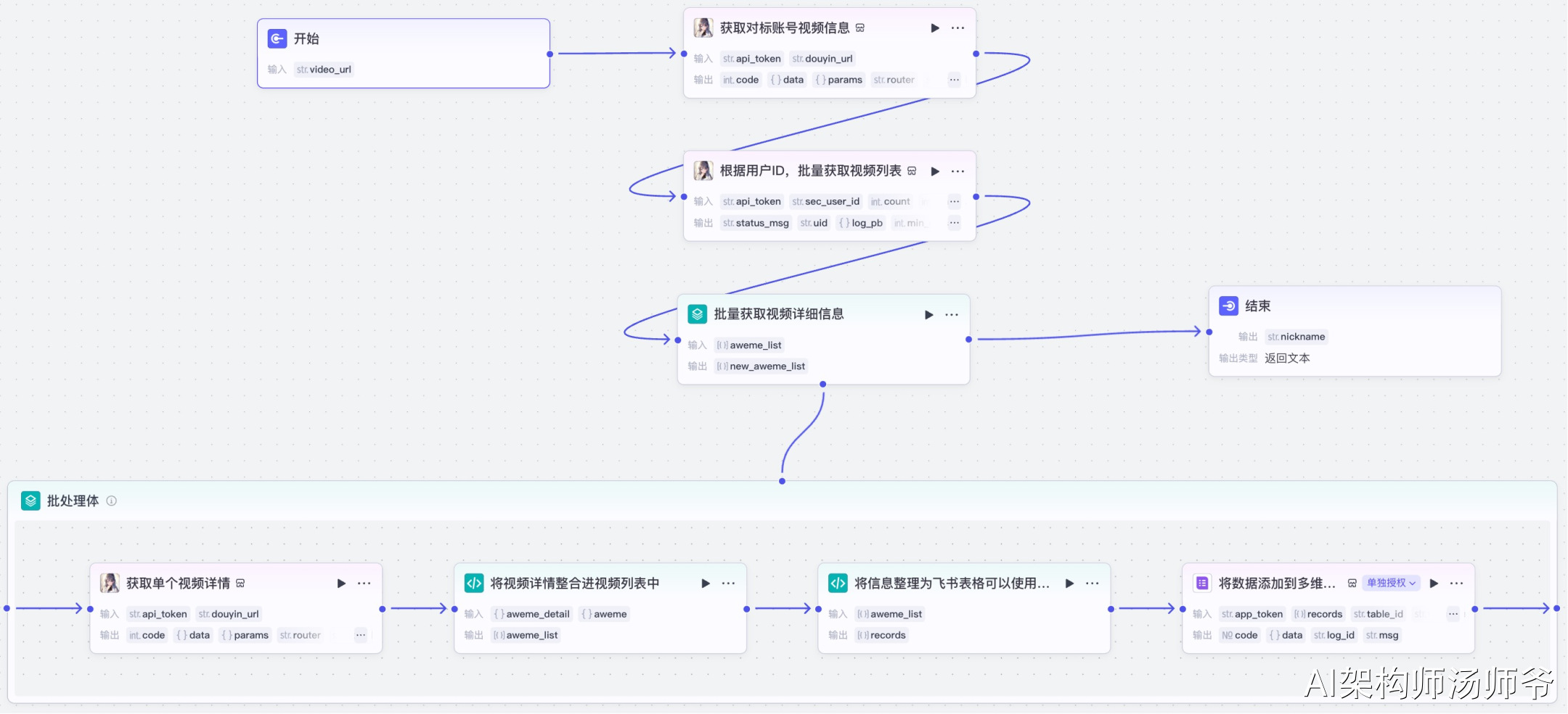
3. 抖音对标账号监控工作流
登录Coze官网,在“资源库-工作流”里新建一个空白工作流,取名“fetch_douyin_user_videos”。
工作流整体预览。
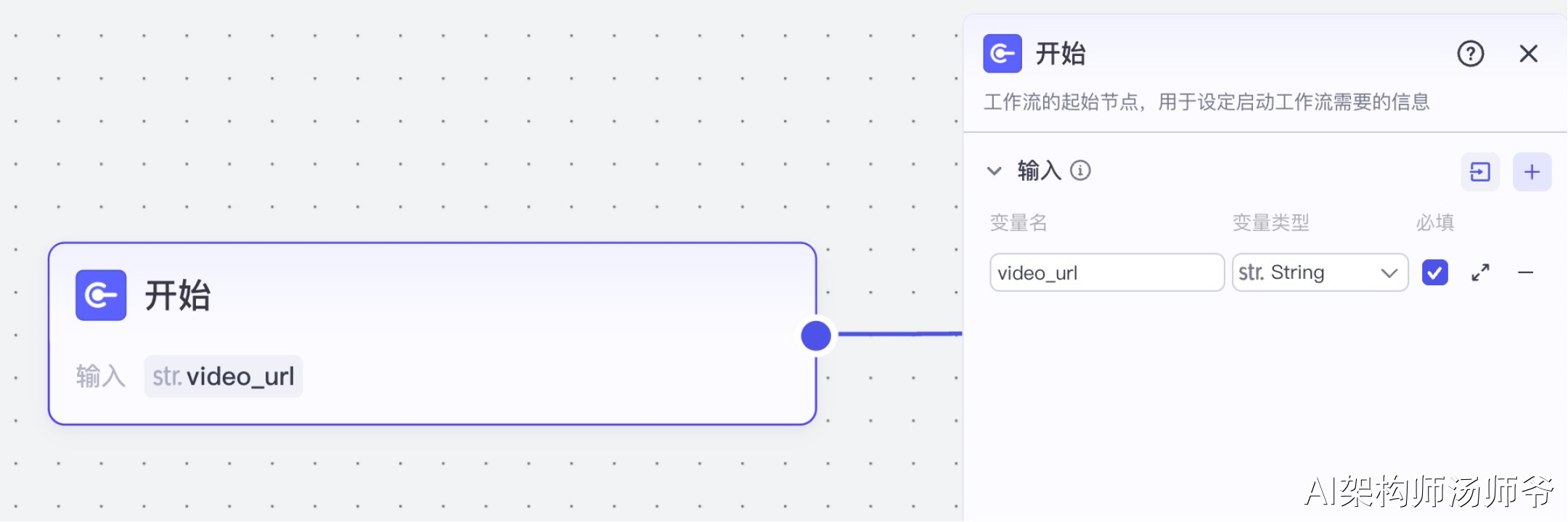
1、开始节点
这里用于定义工作流启动时所需的输入参数。
- 输入:
- video_url:抖音视频分享链接
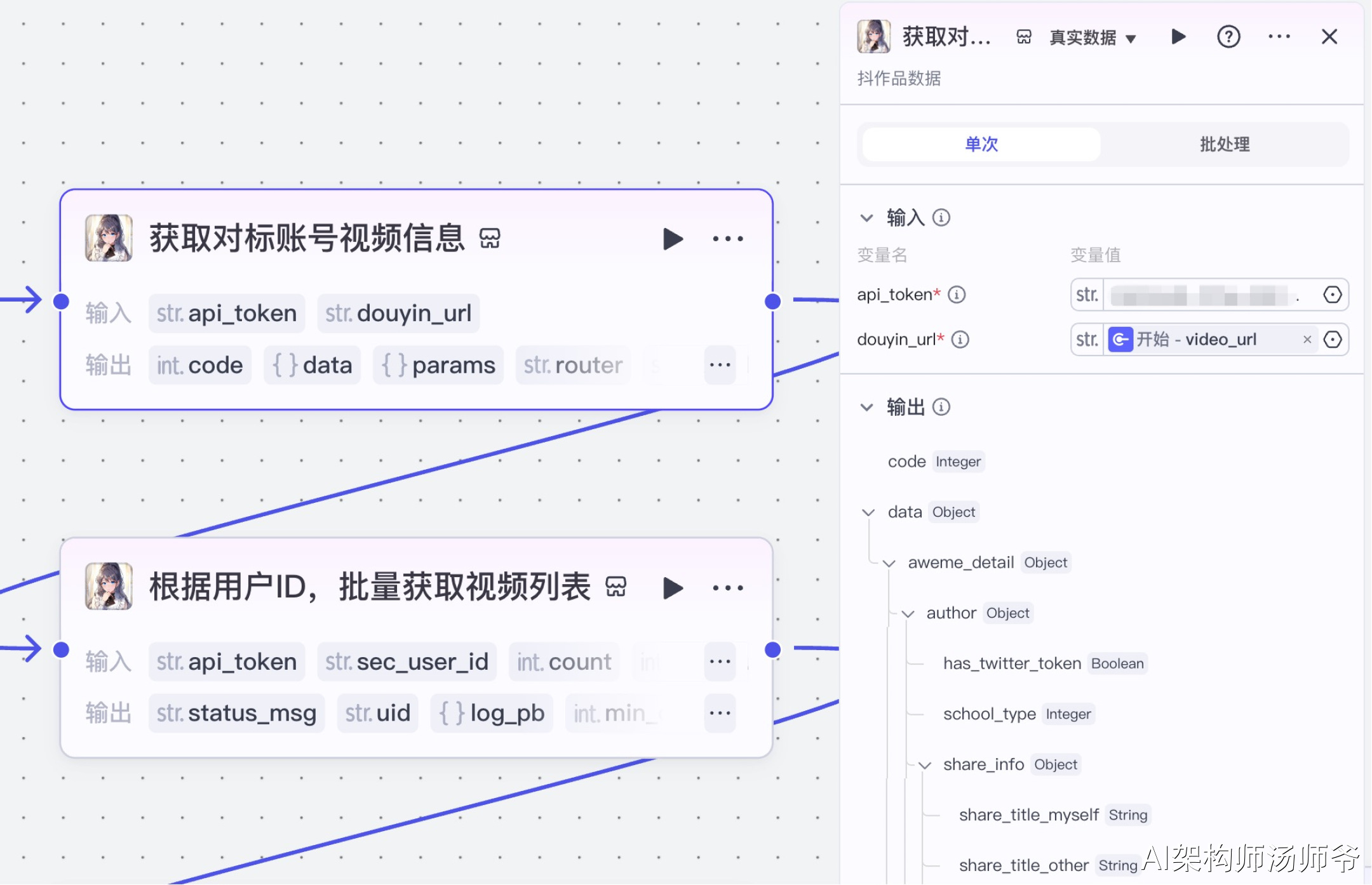
2、插件节点:获取对标账号视频信息
我们将使用“视频搜索”插件的douyin_data工具。通过这个功能,我们可以根据短视频链接,获取用户的ID信息。
- 输入:
- douyin_url:开始节点的video_url
- api_token:API秘钥
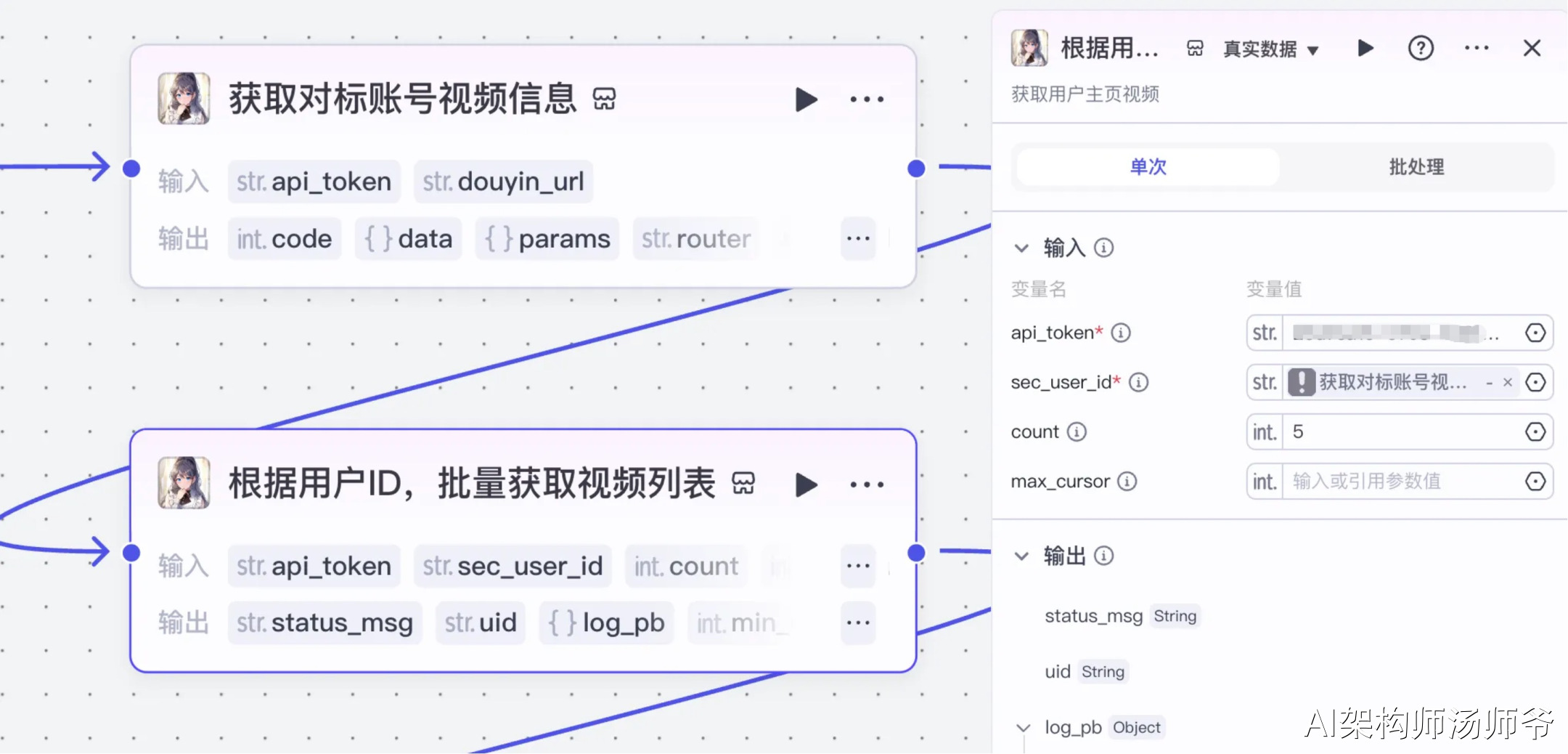
3、插件节点:根据用户ID,批量获取视频列表
我们继续使用“视频搜索”插件,使用其中的工具get_user_video_list。根据用户ID,批量获取视频列表。
- 输入:
- api_token:API秘钥
- sec_uid:在"获取对标账号视频信息"节点的输出变量中,选择用户ID(sec_uid)
- count:设置需要获取的短视频数量,建议设为5个
4、批处理节点:批量获取视频详细信息
这一步将为我们从对标账号的视频列表中提取每个视频的关键数据。通过批处理功能,我们可以同时处理多个视频链接,大大提高数据采集效率。
- 输入:
- aweme_list:从“根据用户ID,批量获取视频列表”节点的输出中,选择 aweme_list
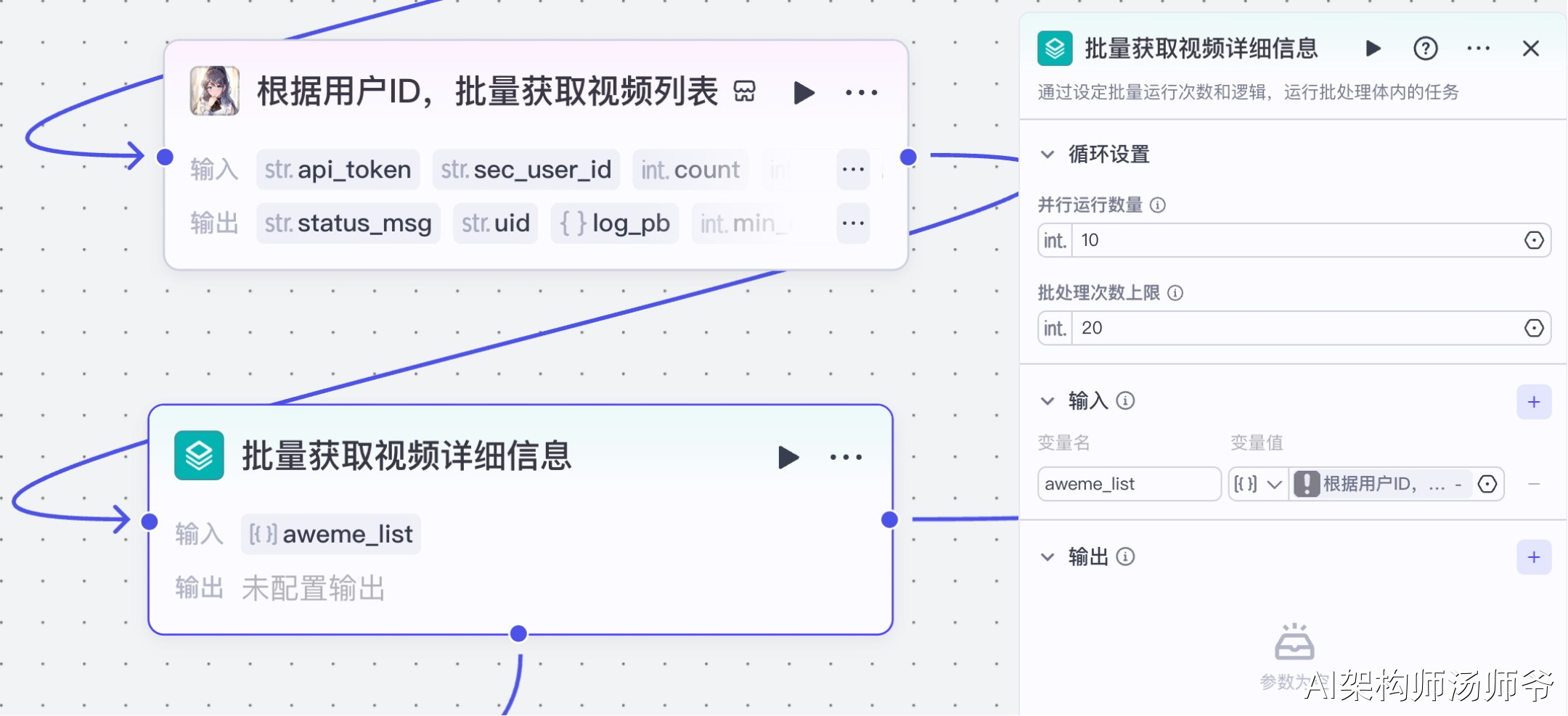
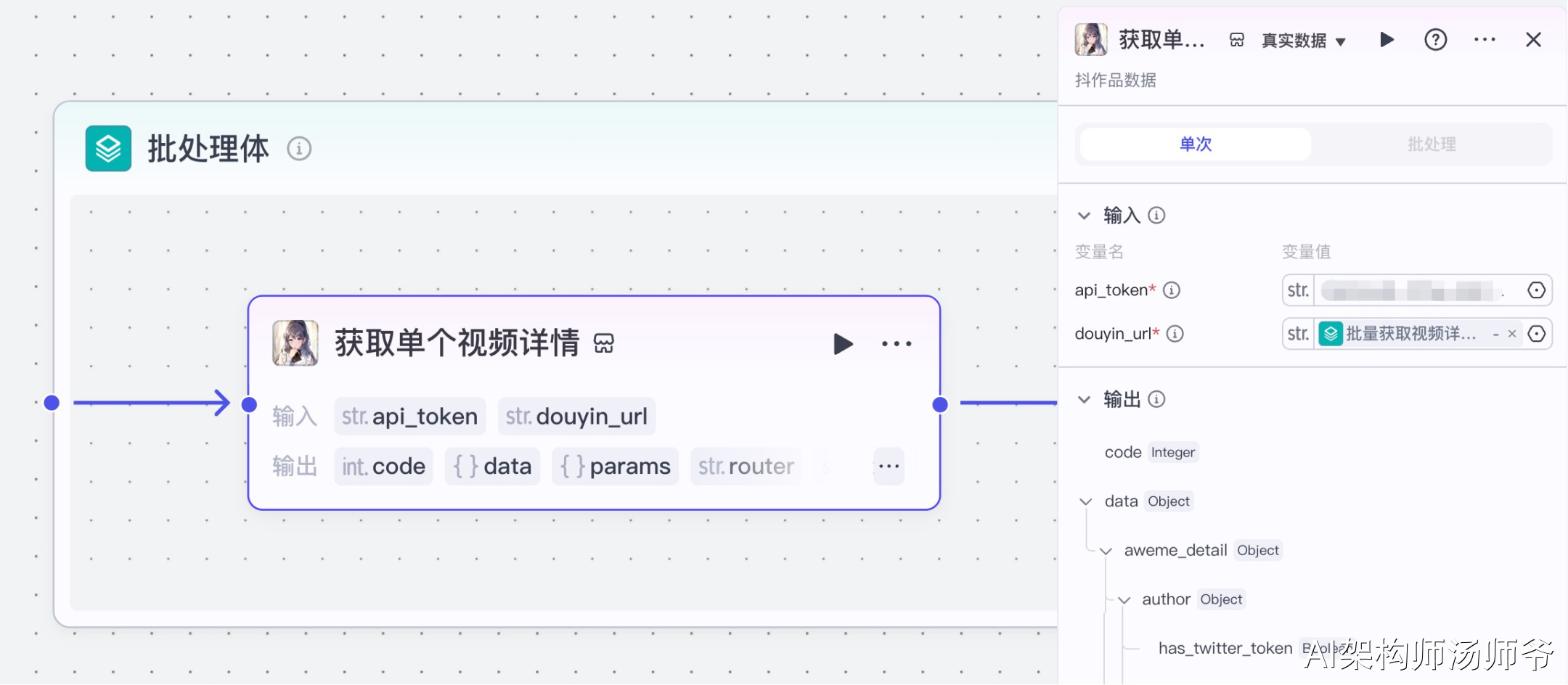
5、批处理体内插件节点:获取单个视频详情
我们将使用“视频搜索”插件的douyin_data工具。通过这个功能,我们可以根据抖音视频链接,获取视频详情信息。
- 输入:
- api_token:API秘钥
- douyin_url:从“批量获取视频详细信息”节点的输出中,选择share_url
6、批处理体内代码节点:将视频详情整合进视频列表中
这一步将从抖音API获取的详细视频信息与我们之前收集的视频列表数据合并。通过这个过程,我们能确保掌握每个视频的完整信息,包括互动数据(点赞、评论、收藏数)、创作者信息和内容详情,为后续分析提供全面的数据基础。
- 输入:
- aweme_detail:从 “获取单个视频详细信息”节点的输出中,选择aweme_detail
- aweme:从“批量获取视频详细信息”节点的输出中,选择item
- 输出:
- aweme_list:变量类型设置为 Array 对象数组,表示处理后的单条视频
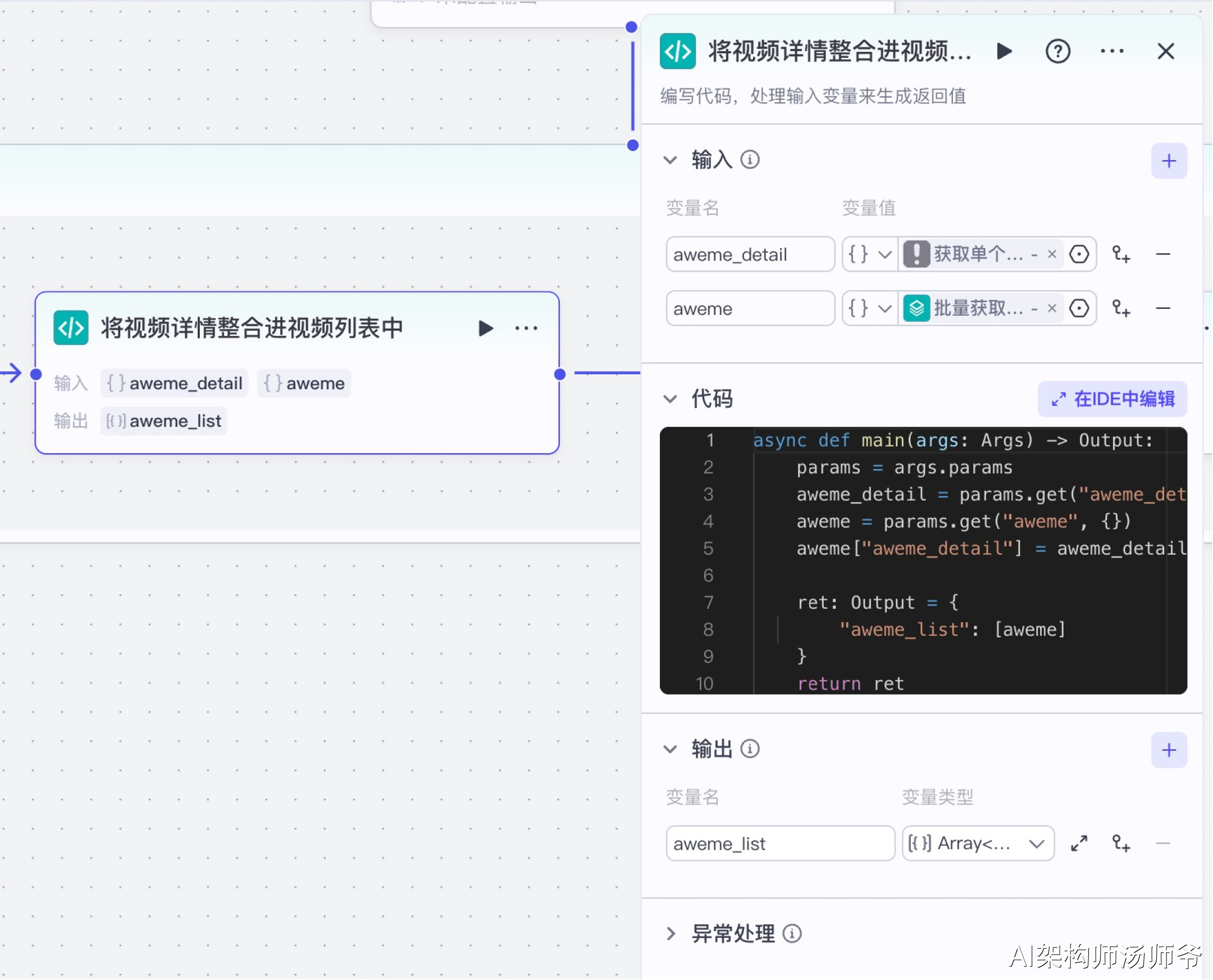
下面是处理数据的Python代码,它会将视频信息转换成我们需要的格式。
async def main(args: Args) -> Output:
params = args.params
aweme_detail = params.get("aweme_detail", {})
aweme = params.get("aweme", {})
aweme["aweme_detail"] = aweme_detail
ret: Output = {
"aweme_list": [aweme]
}
return ret
7、批处理体内代码节点:将信息整理为飞书表格可以使用的数据
在这个环节中,我们会提取视频的核心信息(如标题、点赞数、评论数等),并将它们转换成飞书表格能够直接识别和处理的格式。
- 输入:
- aweme_list:从"将视频详情整合进视频列表中"节点的输出中,选择aweme_list
- 输出:
- records:处理后的表格数据,选择Array类型
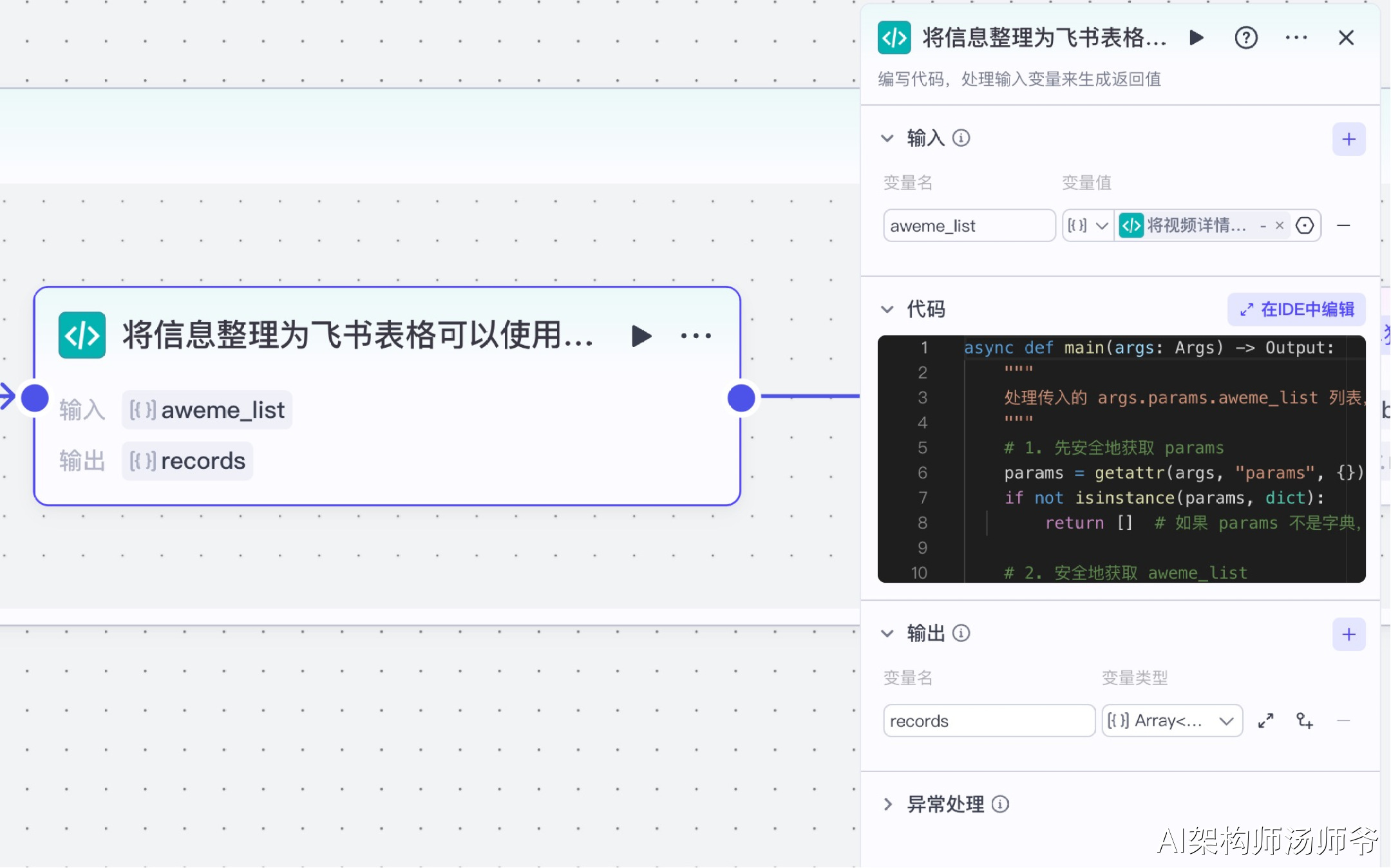
下面是Python代码,用于处理数据转换。这段代码至关重要,它将抖音API返回的原始数据转换为结构化的表格格式。
async def main(args: Args) -> Output:
params = args.params
aweme_list = params.get("aweme_list", [])
result = []
# 遍历 aweme_list,依次处理
for aweme in aweme_list:
# 获取 aweme_detail 并判空
aweme_detail = aweme.get("aweme_detail") or {}
title = aweme_detail.get("desc") or ""
link = aweme_detail.get("share_url") or ""
# 安全获取 statistics
statistics = aweme_detail.get("statistics") or {}
# 提取各字段信息,并在取值时加默认值
video_id = statistics.get("aweme_id") or ""
digg_count = statistics.get("digg_count") or 0
comment_count = statistics.get("comment_count") or 0
collect_count = statistics.get("collect_count") or 0
share_count = statistics.get("share_count") or 0
# 获取作者信息
author_info = aweme_detail.get("author") or {}
author_name = author_info.get("nickname") or ""
signature = author_info.get("signature") or ""
sec_uid = author_info.get("sec_uid") or ""
raw_create_time = aweme_detail.get("create_time", 0)
# 如果不是 int,就尝试转换,失败则为 0
try:
create_time = int(raw_create_time)
except (TypeError, ValueError):
create_time = 0
# 创建时间以毫秒计,避免 None 或非法值导致报错
create_time_ms = create_time * 1000
raw_duration = aweme_detail.get("duration", 0)
# 如果不是数字,尝试转换为 float,失败则为 0
try:
duration = float(raw_duration)
except (TypeError, ValueError):
duration = 0.0
duration_sec = duration / 1000
# 组装返回数据
item_dict = {
"fields": {
"视频ID": video_id,
"标题": title.strip(),
"链接": {
"text": "查看视频",
"link": link.strip(),
},
"点赞数": digg_count,
"评论数": comment_count,
"收藏数": collect_count,
"分享数": share_count,
"作者": author_name,
"用户简介": signature,
"用户ID": sec_uid,
"发布日期": create_time_ms, # 毫秒级时间戳
"时长": duration_sec # 秒
}
}
result.append(item_dict)
return result
8、批处理体内插件节点:将数据添加到多维表格
首先,我们需要创建一个多维表格,设置好表头字段。

选择“飞书表格”插件节点的add_records工具,将数据添加到多维表格。
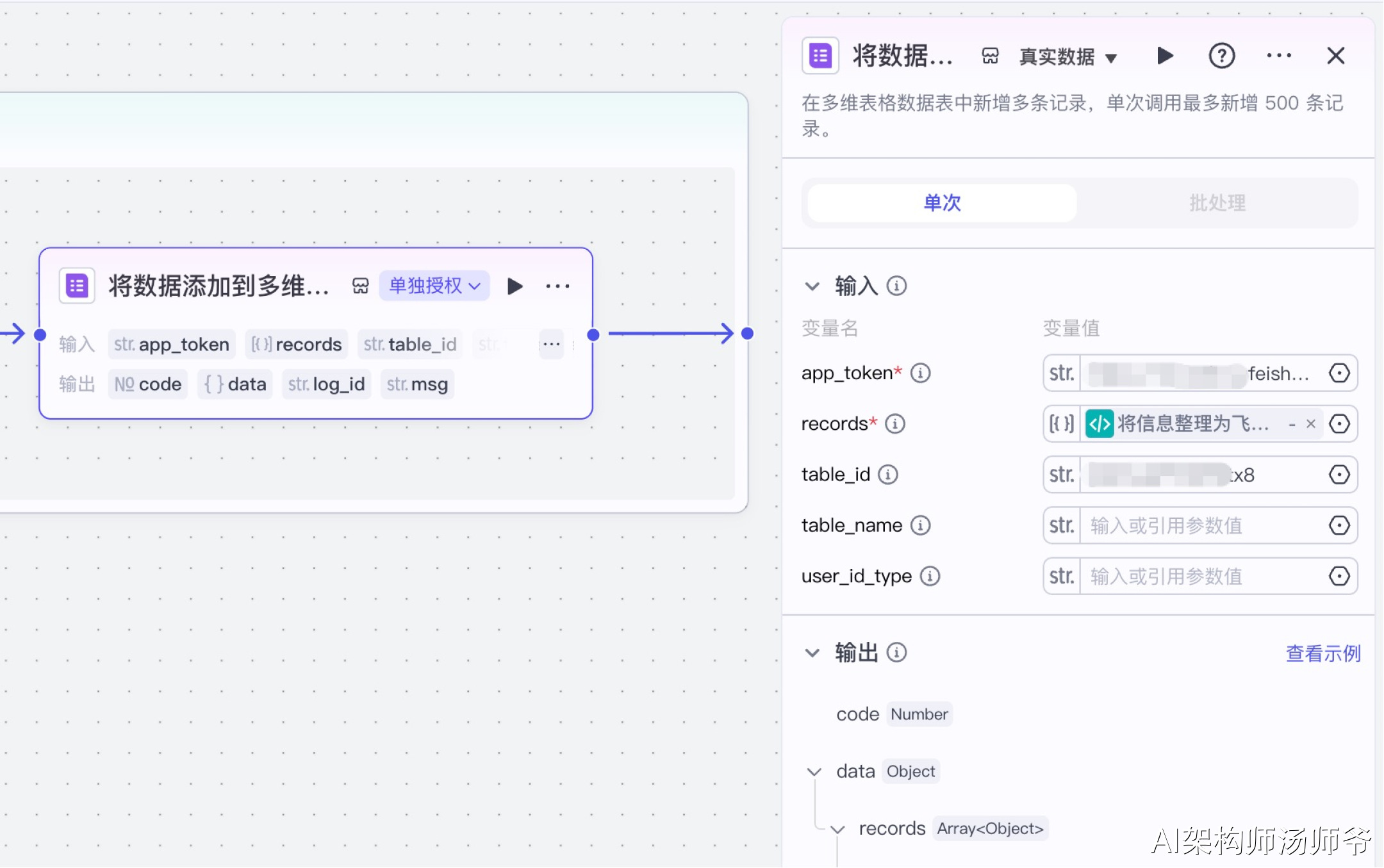
- 输入:
- app_token:提前创建一个多维表格,将多维表格的链接复制进去。
- records:从"将信息整理为飞书表格可以使用的数据"的输出变量中,选择records。
- table_id:多维表格数据表的唯一标识符
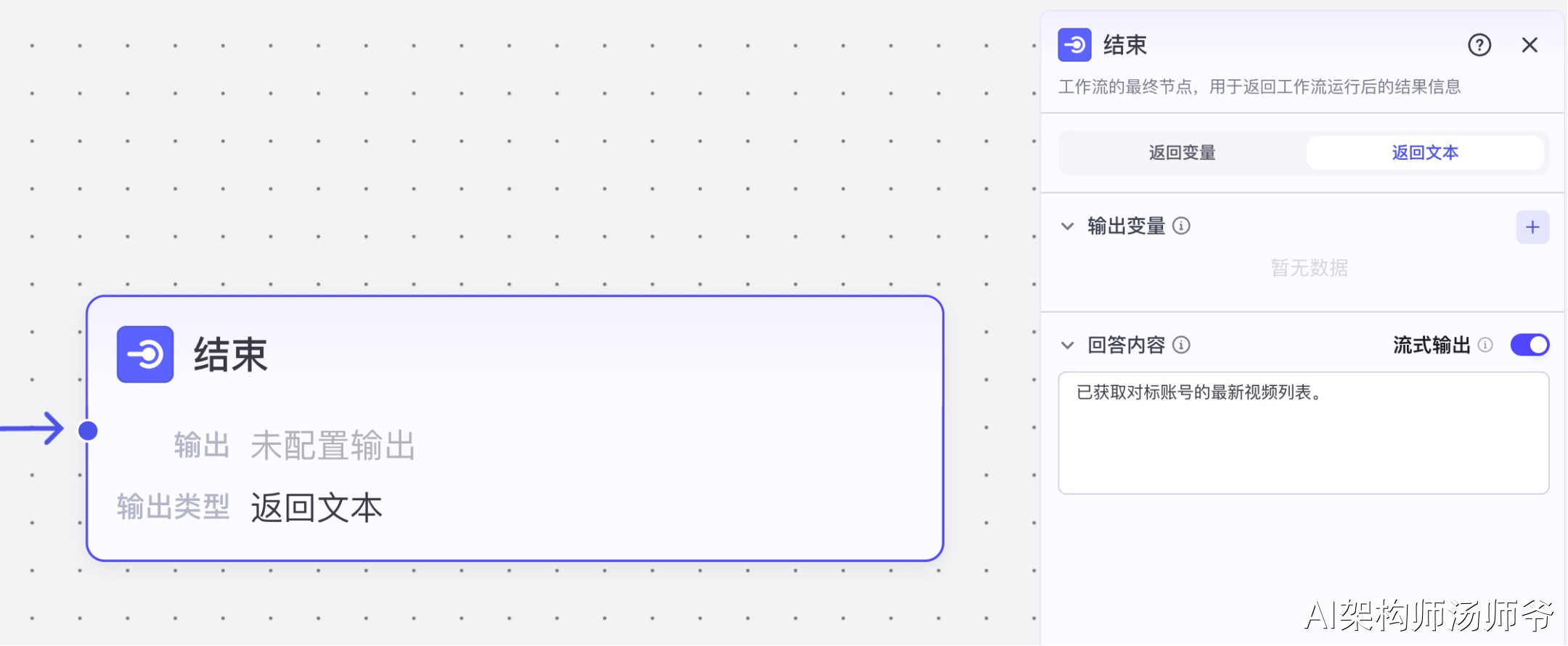
9、结束节点
选择"返回文本",将回答内容设置为:已获取对标账号的最新视频列表。
4.小红书对标账号监控工作流
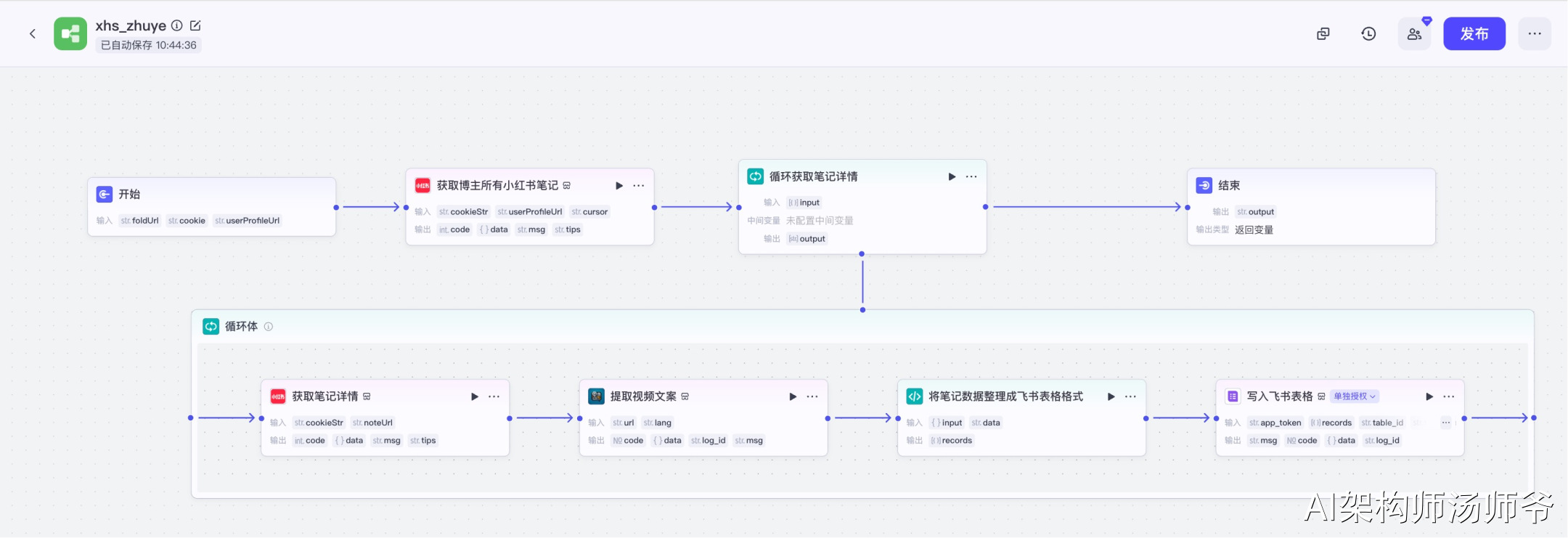
登录Coze官网,在"资源库-工作流"中新建一个空白工作流,命名为"xhs_zhuye"。
工作流整体预览。
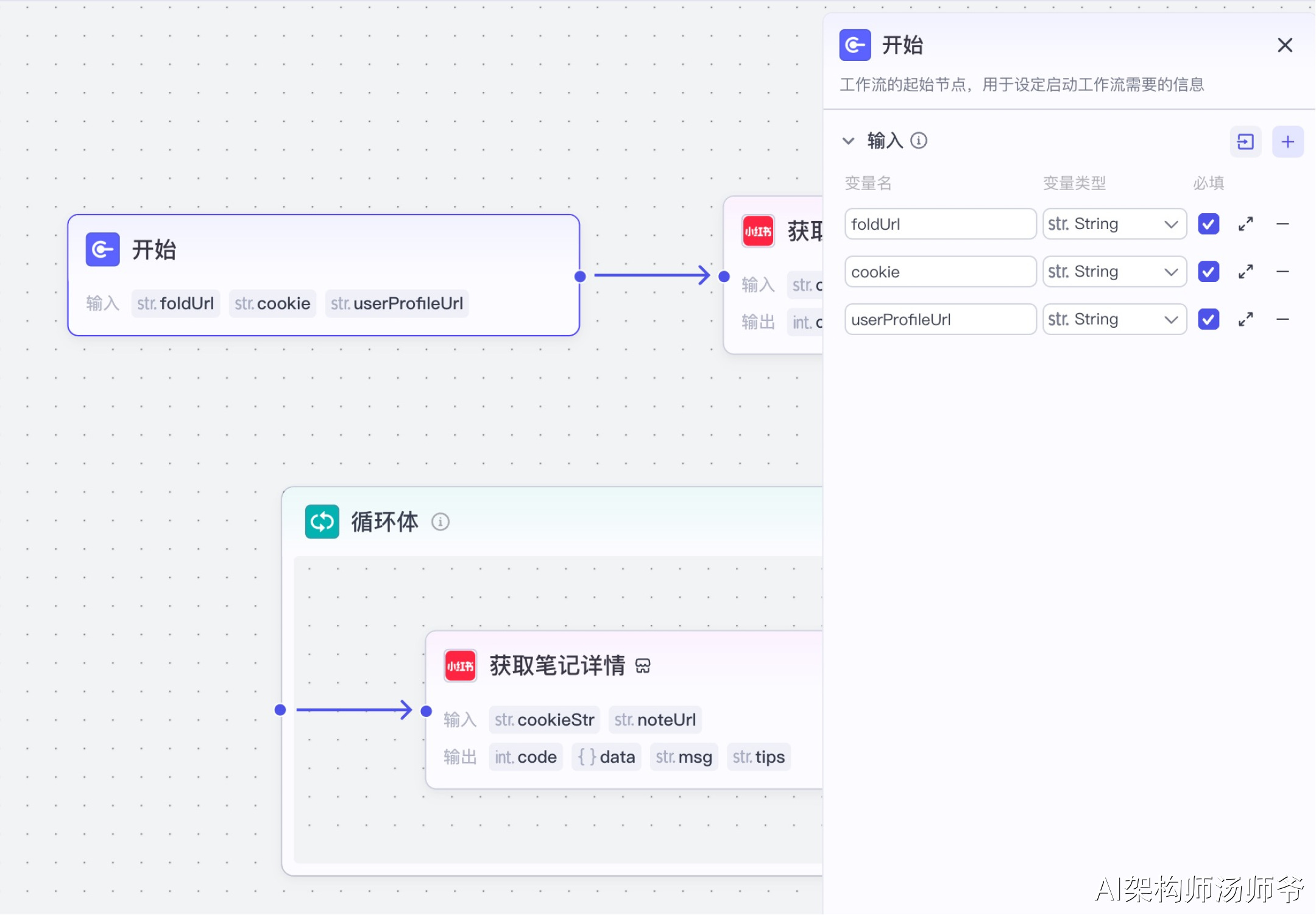
1、开始节点
此节点用于定义工作流启动时所需的输入参数。
- 输入:
- foldUrl:飞书表格链接
- cookie:小红书平台的cookie信息,这是访问小红书数据的身份凭证,获取方法参考6节
- userProfileUrl:要监控的小红书博主主页完整URL地址
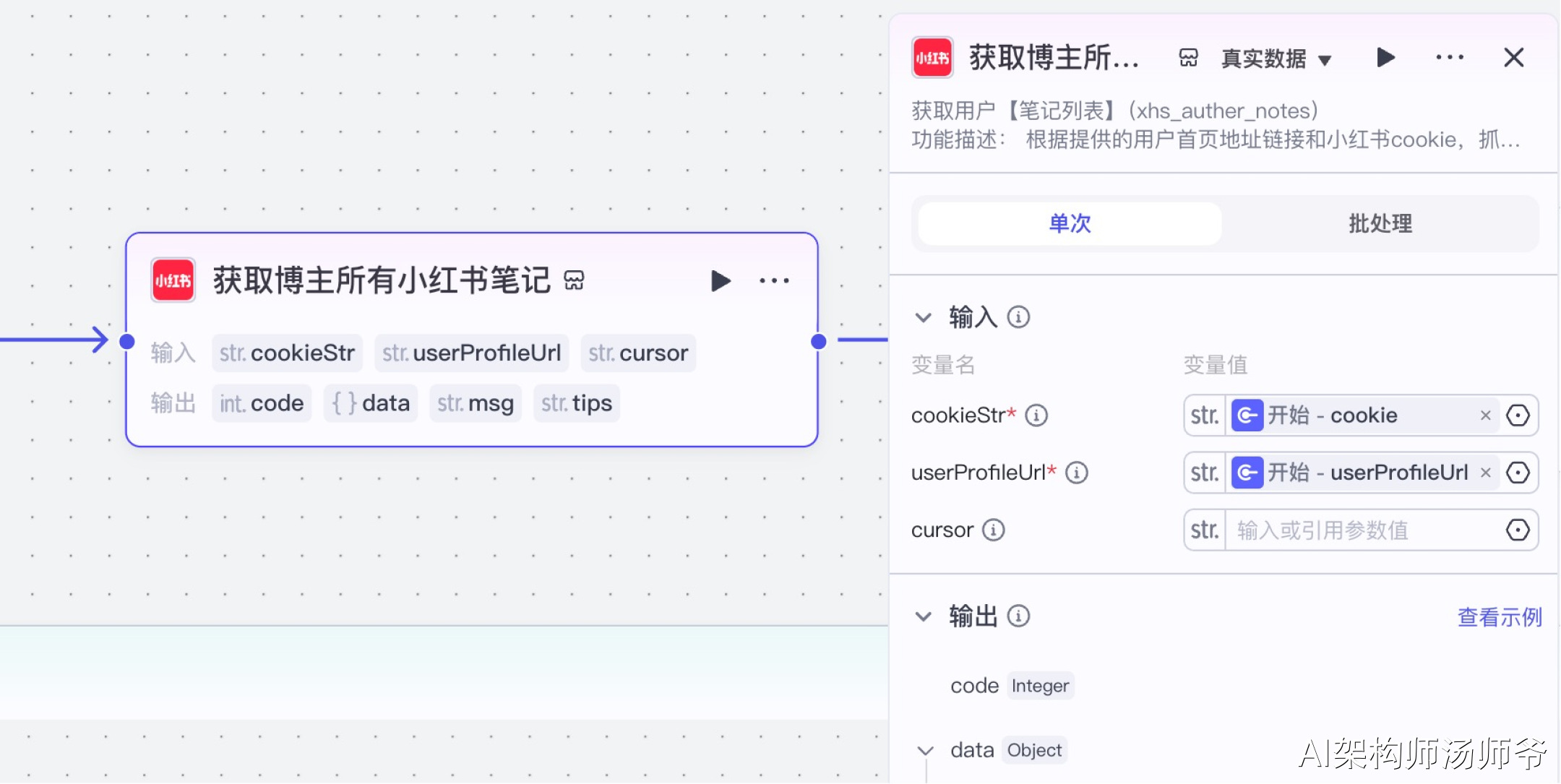
2、插件节点:获取博主所有小红书笔记
我们将使用"小红书"插件的xhs_auther_notes工具。这个工具能帮我们一次性获取博主所有发布的笔记内容。
- 输入:
- cookieStr:开始节点的 cookie
- userProfileUrl:开始节点的 userProfileUrl
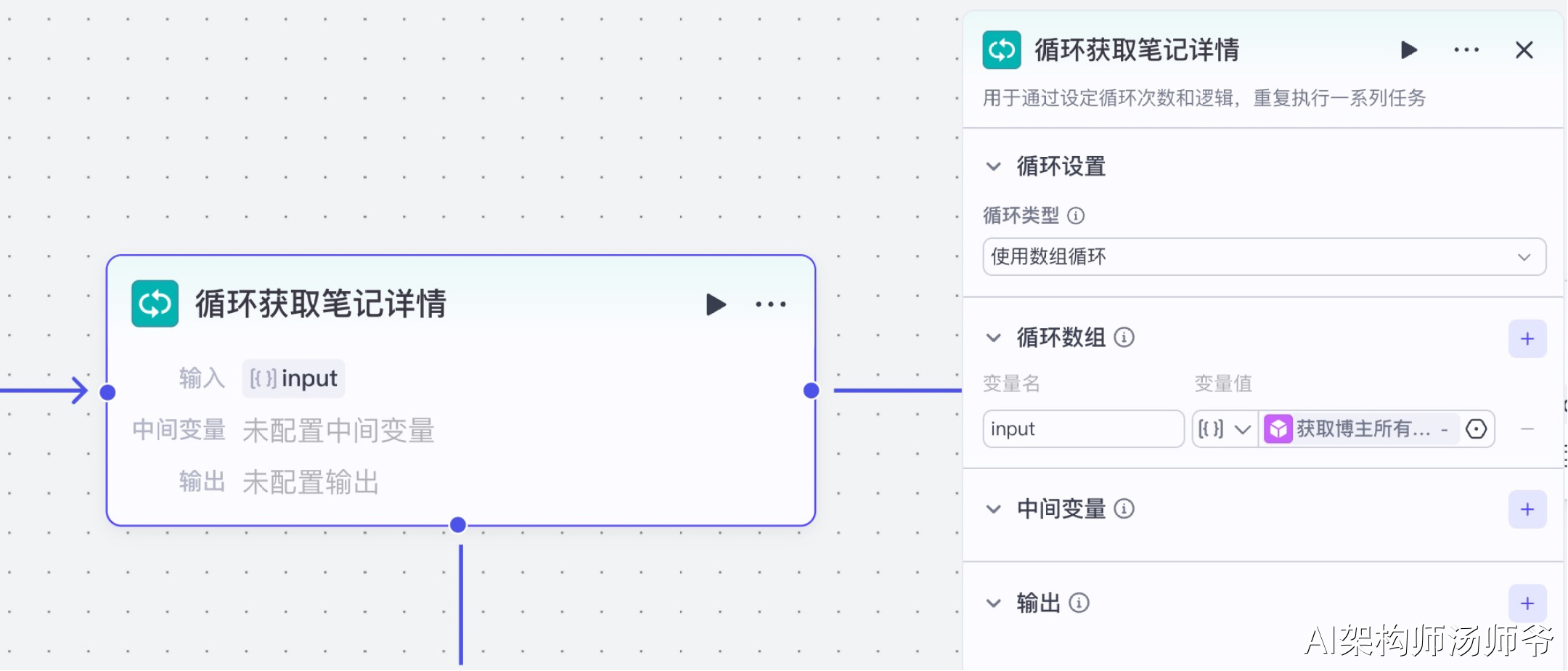
3、循环节点:循环获取笔记详情
循环获取笔记详情是工作流中的一个关键步骤,它会遍历博主所有的笔记,逐一获取详细信息,收集每篇笔记的数据,包括标题、内容、互动数据等。
- 输入
- input:从 “获取博主所有小红书笔记”节点 的输出中,选择 notes
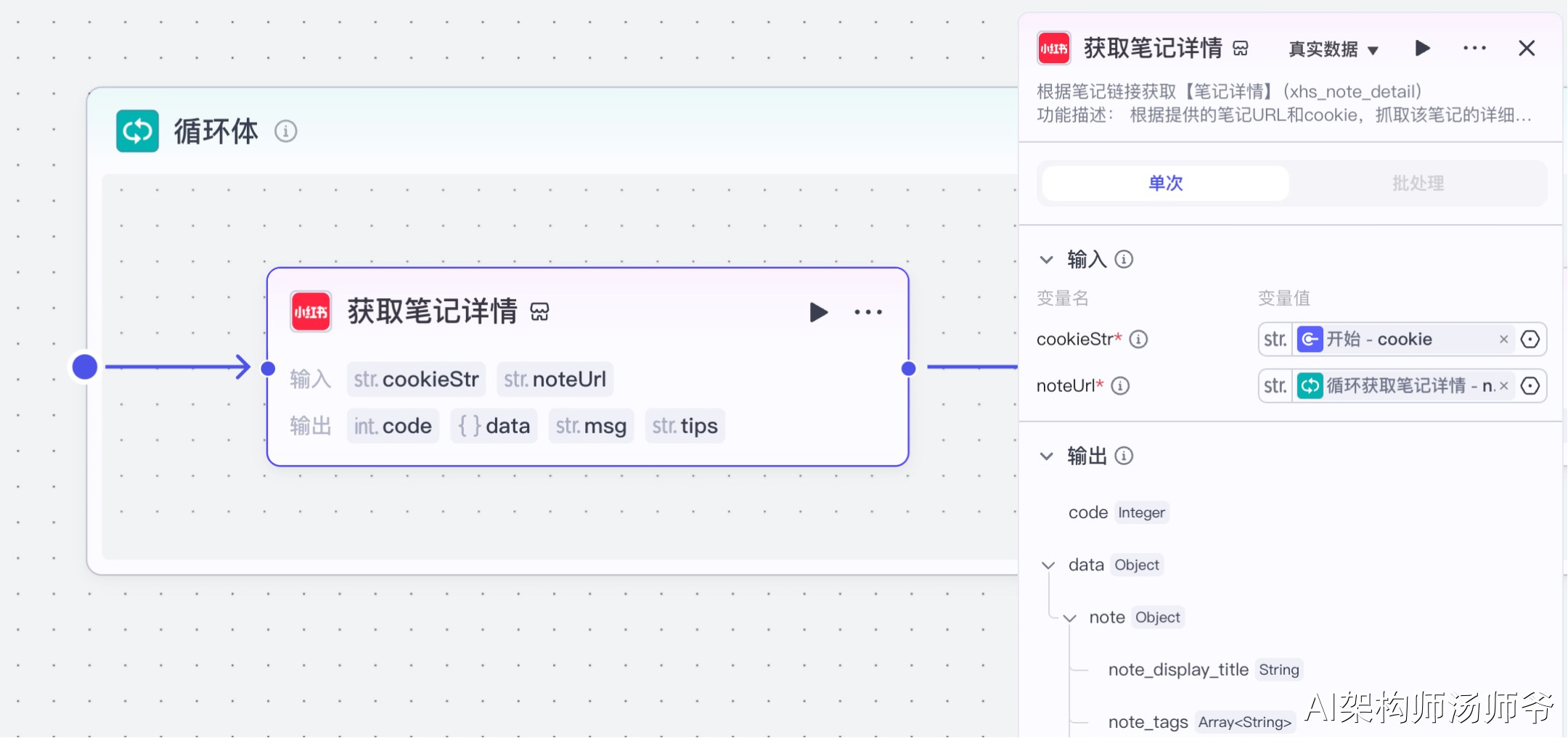
4、循环体内插件节点:获取笔记详情
我们将使用"小红书"插件的xhs_note_detail工具。这个工具能够帮助我们获取每篇笔记的详细信息,包括笔记内容、互动数据、图片和视频资源链接等。
- 输入
- cookieStr:开始节点的 cookie
- noteUrl:从 “循环笔记详情” 节点的输出中,选择 noteUrl
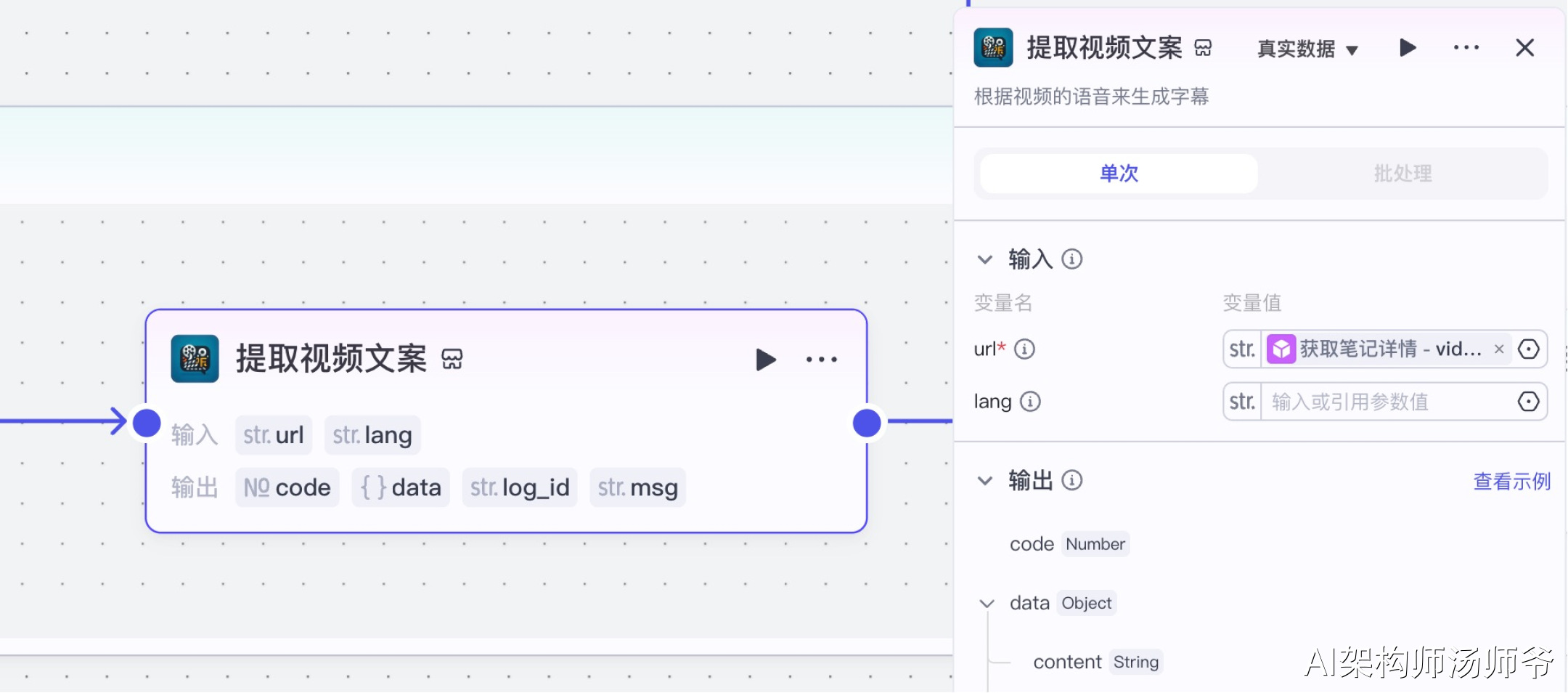
5、循环体内插件节点:提取视频文案
我们将使用"字幕获取"插件的generate_video_captions_sync工具。这个工具可以自动提取视频中的语音内容并转换为文字,非常适合批量处理视频素材和内容分析。
- 输入:
- url:从"获取笔记详情"节点的输出中,选择 video_h264_url,表示H264标准编码格式视频链接
- lang:视频语言,如汉语、英语等,不填时默认为汉语
6、循环体内代码节点:将笔记数据整理成飞书表格格式
这一步是将我们获取到的原始数据转换成标准化、结构化的格式,以便后续导入飞书表格。
- 输入
- input:从“获取笔记详情”节点的输出中,选择note
- data:从“提取视频文案”节点的 输出中,选择 content
- 输出
- records:变量类型设置为 Array 对象数组,表示处理后的单条视频
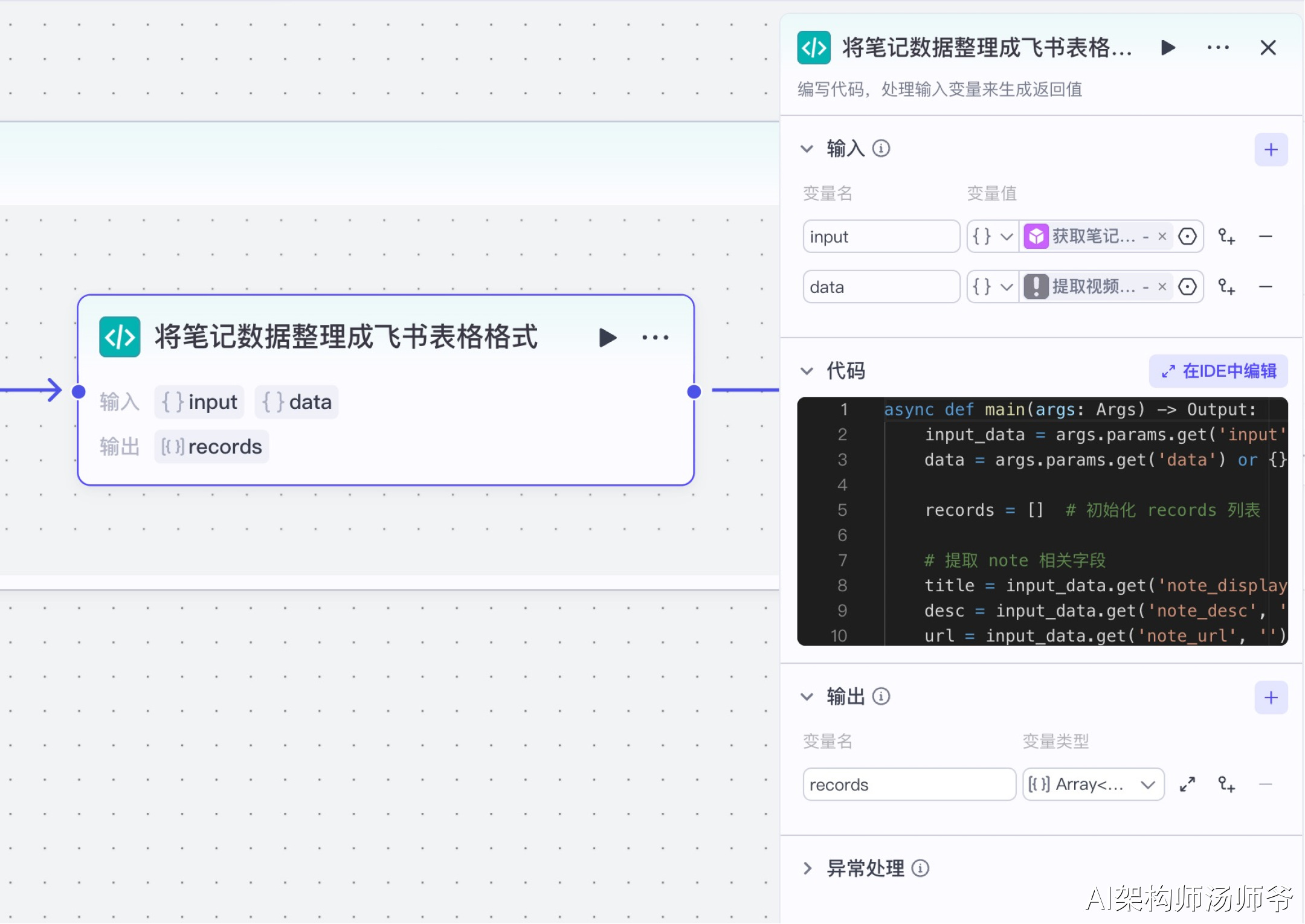
下面是处理数据的Python代码:
async def main(args: Args) -> Output:
input_data = args.params.get('input') or {}
data = args.params.get('data') or {}
records = [] # 初始化 records 列表
# 提取 note 相关字段
title = input_data.get('note_display_title', '') # 标题
desc = input_data.get('note_desc', '') # 描述
url = input_data.get('note_url', '') # 链接
nickname = input_data.get('auther_nick_name', '') # 作者昵称
likedCount = input_data.get('note_liked_count', '0') # 点赞数
videoUrl = input_data.get('video_h264_url', '') # 视频地址
collectedCount = input_data.get('collected_count', '0') # 收藏数
imageList = input_data.get('note_image_list', []) # 图片列表
# 构建记录对象
record = {
"fields": {
"笔记链接": url,
"标题": title,
"内容": desc,
"作者": nickname,
"点赞数": likedCount,
"链接": {
"link": url,
"text": title
},
"收藏数": collectedCount,
"图片地址": '\n'.join(imageList), # 将图片列表拼接成字符串
"视频地址": videoUrl,
"视频文案": data.get("content", "")
}
}
records.append(record) # 将记录对象添加到 records 列表中
# 构建输出对象
ret: Output = {
"records": records
}
return ret
7、循环体内插件节点:写入飞书表格
首先,我们需要创建一个多维表格,设置好表头字段。

表头字段包括视频的所有关键信息:笔记链接、标题、内容、作者、点赞数、链接、收藏数、图片地址、视频地址、视频文案。
最后,我们将处理好的数据添加到飞书多维表格中。选择“飞书表格”插件节点的add_records工具,将数据添加到多维表格。
- 输入:
- app_token:开始节点的 foldUrl,也就是飞书多维表格的链接
- records:从“将笔记整理成飞书表格格式”的输出变量中,选择records
- table_id:多维表格数据表的唯一标识符
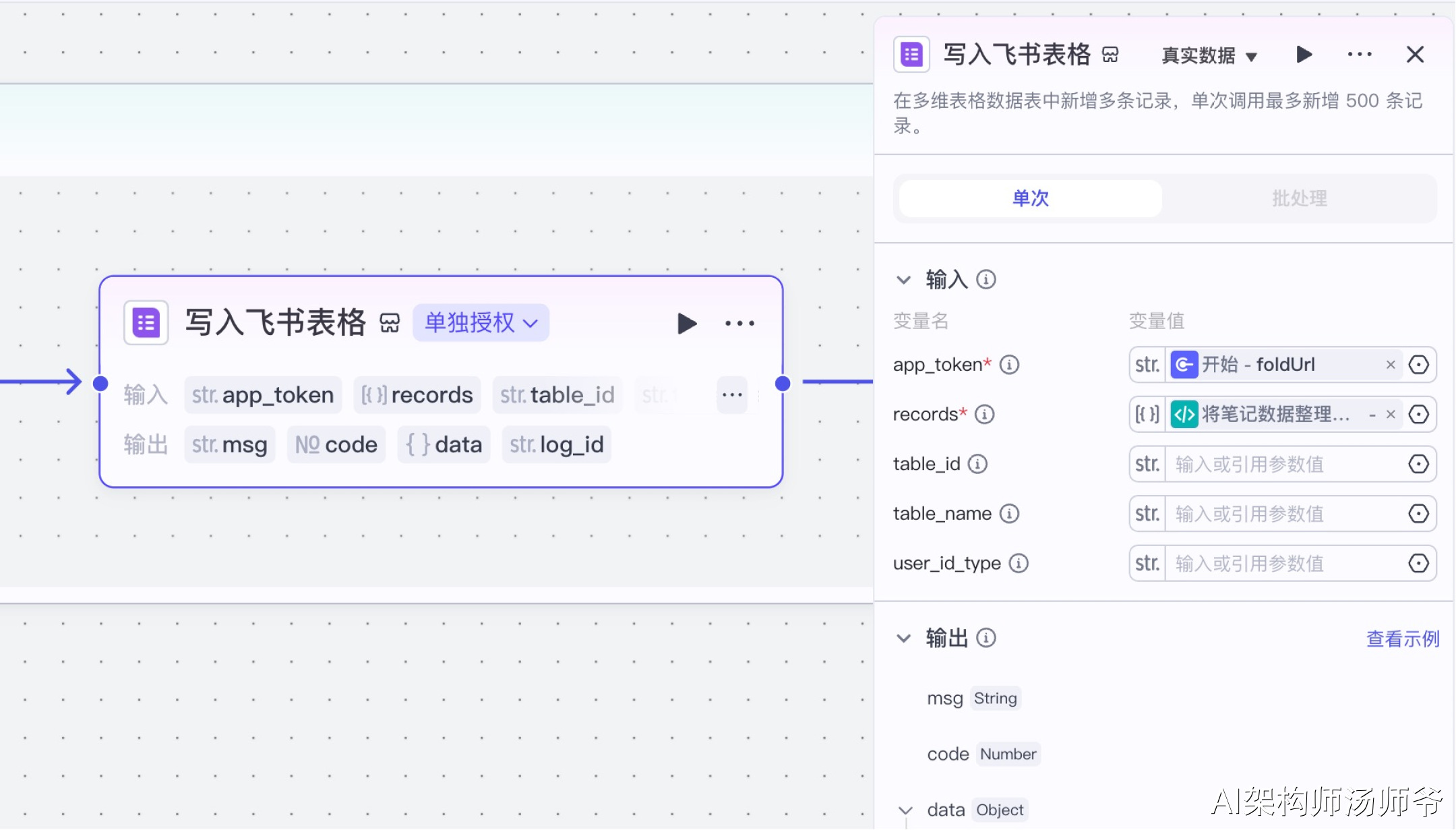
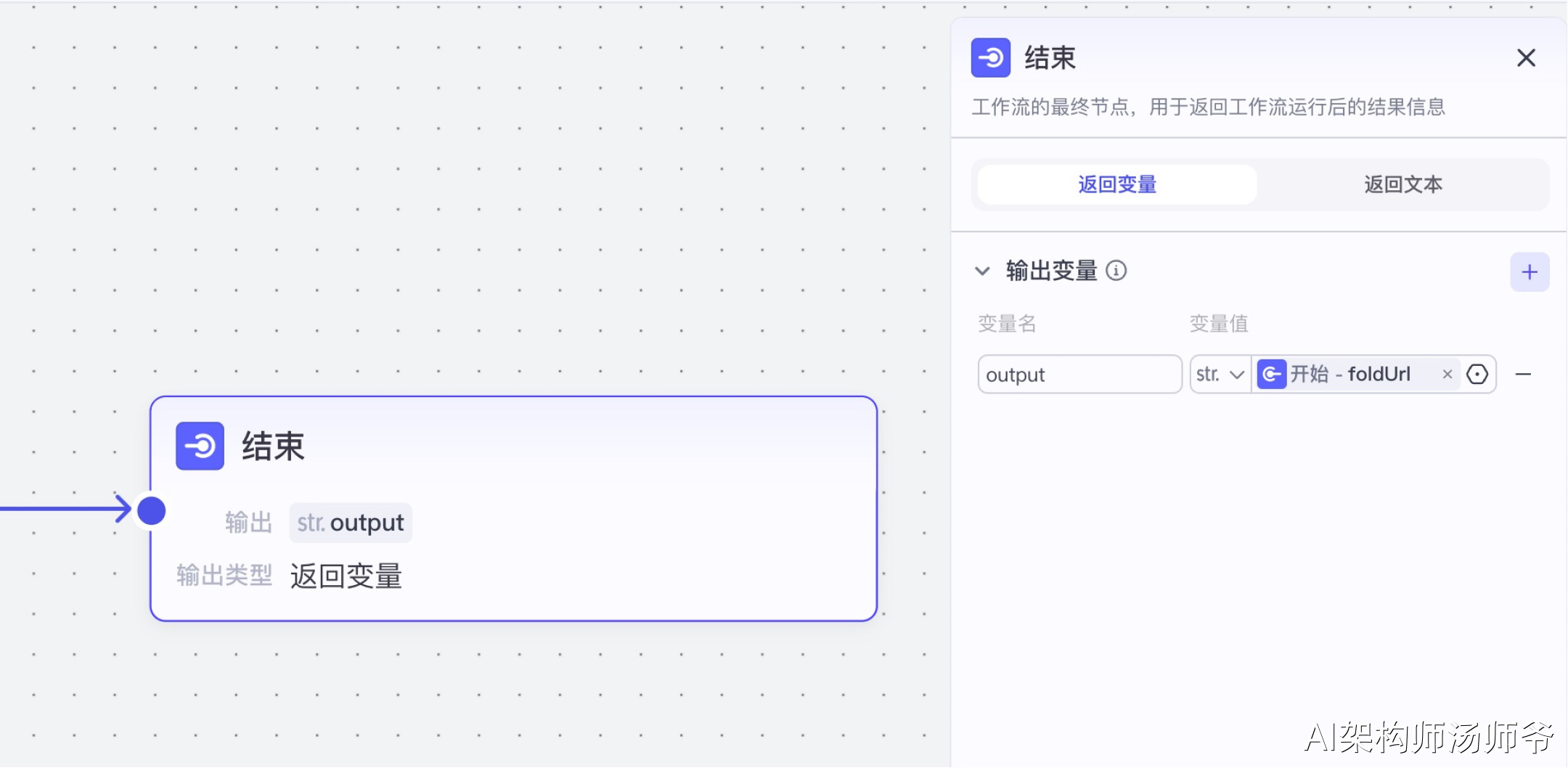
8、结束节点
选择“返回变量”,输出:output 开始节点的foldUrl,也就是飞书多维表格的链接
5. 小结
对标账号监控智能体专注于竞品分析,自动获取优质账号的内容数据。
我们介绍了抖音和小红书平台的监控工作流搭建方法,包括获取视频列表、提取详情、整理数据结构和存储等步骤。
通过这一智能体,创作者可持续学习行业标杆,获取创作灵感和参考。
本文已收录于,我的技术博客:tangshiye.cn 里面有,AI 学习资料,Coze 工作流,n8n 工作流,算法 Leetcode 详解,BAT 面试真题,架构设计,等干货分享。

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









