







Free-Prompt-Editing (FPE)
补充:关于stable diffusion 中的attention替换思想:Stable Diffusion 中的自注意力替换技术与 Diffusers 实现 - 知乎
补充:Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.
摘要
像Stable Diffusion这样的Deep Text-to-Image Synthesis (TIS) models 模型最近在创造性文本到图像生成方面获得了显着的普及。然而,对于特定领域的场景,无调整的文本引导图像编辑(tuning-free Text-guided Image Editing (TIE) 对应用程序开发人员更为重要。这种方法通过在生成过程中操纵注意力层中的特征组件来修改图像中的对象或对象属性。然而,人们对这些注意力层已经学习的语义知之甚少,注意力图的哪些部分有助于图像编辑的成功。在本文中,我们进行了深入的探测分析,并证明稳定扩散中的crossattention maps通常包含对象属性信息,这可能导致编辑失败。相比之下,self-attention maps在转换到目标图像的过程中,在保留源图像的几何和形状细节方面起着至关重要的作用。我们的分析为理解扩散模型中的交叉和自我注意机制提供了有价值的见解。此外,基于我们的发现,我们提出了一种简化但更稳定、更高效、无调整的过程,该过程仅在去噪过程中修改指定注意力层的自注意力图。实验结果表明,我们的简化方法在多个数据集上始终优于流行方法的性能。
1. Introduction
文本到图像合成(TIS)模型,如稳定扩散[26]、DALL-E 2[25]和Imagen[29],已被证明对文本到图像的生成具有显著的视觉效果,获取学术界和工业界的大量关注[6,20,37,38]。这些TIS模型在大量的图像-文本对上进行训练,如Laion[30,31],并采用尖端技术,包括大规模预训练语言模型[23,24]、变分自编码器[14]和扩散模型[11,32],以实现在生成具有生动细节的真实图像方面的成功。具体来说,稳定扩散作为一种流行且被广泛研究的模型脱颖而出,对开源社区做出了重大贡献。
除了图像生成之外,这些 TIS 模型还具有强大的图像编辑能力,这非常重要,因为它们旨在修改图像,同时确保真实性、自然性和满足人类偏好。文本引导图像编辑 (TIE) 涉及基于描述性提示修改输入图像。现有的 TIE 方法 [1, 2, 5, 10 , 17 , 18, 21 , 22 , 34] 在图像翻译、风格迁移和外观替换方面取得了显着的效果,同时保留输入结构和场景布局。为此,Prompt-to-Prompt (P2P)[10]通过替换源提示中目标编辑词对应的交叉注意映射来修改图像区域。即插即用(PnP)[34]首先提取空间特征以及注意层中原始图像的自我注意,然后将它们注入到目标图像生成过程中。在这些方法中,注意层在控制图像布局和生成图像与输入提示之间的关系方面起着至关重要的作用。然而,对注意力层的不当修改可能会产生不同的编辑结果,甚至会导致编辑失败。例如,如图 1 所示,在交叉注意力层上编辑真实图像可能会导致编辑失败;将人转换为机器人或将汽车的颜色更改为红色失败。此外,上述方法中的一些操作可以修改和优化。

在本文中,我们探索了注意力图修改,以使用基于扩散的模型深入了解 TIE 的潜在机制。具体来说,我们专注于 TIE 的属性并提出基本问题:注意力层的修改如何有助于基于扩散的 TIE。为了回答这个问题,我们仔细构建了新的数据集,并仔细研究了修改注意力图对结果图像的影响。这是通过探针分析 [3, 16] 和对扩散模型中不同块的注意力图修改的系统探索来完成的。我们发现(1)在扩散模型中编辑交叉注意力图对于图像编辑是可选的。替换或细化源图像和目标图像生成过程之间的交叉注意力图是可有可无的,可能导致图像编辑失败。(2) 交叉注意图不仅是生成图像对应位置条件提示的权重度量,还包含条件标记的语义特征。因此,将目标图像的交叉注意图替换为源图像的映射可能会产生意想不到的结果。(3) 自注意力图对 TIE 任务的成功至关重要,因为它们反映了图像特征之间的关联并保留图像的空间信息。基于我们的发现,我们提出了一种简化有效的算法,称为 Free-Prompt-Editing (FPE)。FPE通过在去噪过程中替换特定注意层中的自我注意图来执行图像编辑,而不需要源提示。它对真实的图像编辑场景是有益的。本文的贡献如下::
- 我们对扩散模型中注意力层对图像编辑结果的影响进行了全面分析,并回答了为什么基于跨注意力映射替换的 TIE 方法会导致不稳定结果的问题。
- 我们设计了实验来证明跨注意力映射不仅作为对应 token 在对应像素上的权重,还包含了该 token 的特征信息。相较之下,自注意力在确保编辑后的图像保留原始图像的布局信息和形状细节方面至关重要。
- 基于实验发现,我们简化了当前流行的无需调参的图像编辑方法,并提出了 FPE,使图像编辑过程更简单且更高效。在多个数据集上的实验测试中,FPE 优于目前流行的方法。
2. Related Works
Text-guided Image Editing (TIE)[39]是一项关键任务,涉及修改输入图像,要求用文本表示。这些方法可以大致分为两组:无调整方法和基于微调的方法。
2.1. Tuning-free Methods
无调优的TIE方法旨在控制去噪过程中生成的图像。为了实现这一目标,SDEdit [17] 使用给定的引导图像作为去噪步骤中的初始噪声,这导致了令人印象深刻的结果。其他方法在扩散模型的特征空间中运行,以实现成功的编辑结果。一个值得注意的例子是 P2P [10],它发现操纵交叉注意力层允许控制图像的空间布局和文本中的每个单词之间的关系。Nulltext反演[18]进一步采用优化方法重建制导图像,利用P2P进行真实图像编辑。DiffEdit [5] 通过比较不同的文本提示自动生成掩码,以帮助指导需要编辑的图像区域。PnP[34]专注于空间特征和自我亲和力来控制生成的图像的结构,而不限制与文本的交互。此外,MasaCtrl [2] 将扩散模型中的自注意力转换为相互和掩码引导的自注意力策略,从而实现姿势转换。在本文中,我们旨在深入了解扩散模型的注意力层,并进一步提出一种更精简的无调整 TIE 方法。
2.2. Fine-tuning Based Methods
基于微调的 TIE 方法的核心思想是通过对特定领域数据的知识进行微调 [8, 12, 13 , 27] 或引入额外的引导信息 [1, 19 , 40] 来合成理想的新图像。DreamBooth [27] 在保持文本转换器冻结并利用生成的图像作为正则化数据集的同时微调扩散模型中的所有参数。文本反转 [8] 为每个概念优化一个新的词嵌入标记。Imagic[13]通过调整学习输入图像的近似文本嵌入,然后通过插值近似文本嵌入和目标文本嵌入来编辑图像中物体的姿态。ControlNet[40]和T2I-Adapter[19]允许用户指导,通过调整额外的网络模块,通过输入图像生成的图像。Instructpix2pix [1] 通过以指令的形式构建图像-文本-图像三元组来完全微调扩散模型,使用户能够使用指令提示编辑真实图像,例如“把男人变成cyborg”。与这些工作相比,我们的方法专注于无需微调过程即可调整技术。
看一下Unet中的self-attention和cross-attention的代码:
![]()
# class BasicTransformerBlock(nn.Module) 类中
# 1. Self-Attn
self.attn1 = CrossAttention(
query_dim=dim,
heads=num_attention_heads,
dim_head=attention_head_dim,
dropout=dropout,
bias=attention_bias,
cross_attention_dim=cross_attention_dim if only_cross_attention else None,
upcast_attention=upcast_attention,
)
self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn, final_dropout=final_dropout)
# 2. Cross-Attn
if cross_attention_dim is not None:
self.attn2 = CrossAttention(
query_dim=dim,
cross_attention_dim=cross_attention_dim,
heads=num_attention_heads,
dim_head=attention_head_dim,
dropout=dropout,
bias=attention_bias,
upcast_attention=upcast_attention,
) # is self-attn if encoder_hidden_states is none
else:
self.attn2 = None补充:关于attention补充部分也可以参考:Cross Attention在Stable diffusion里的源码解析笔记 - 知乎
3. Analysis on Cross and Self-Attention
在本节中,我们分析了Stable Diffusion中的cross and self-attention maps如何有助于 TIE 的有效性。
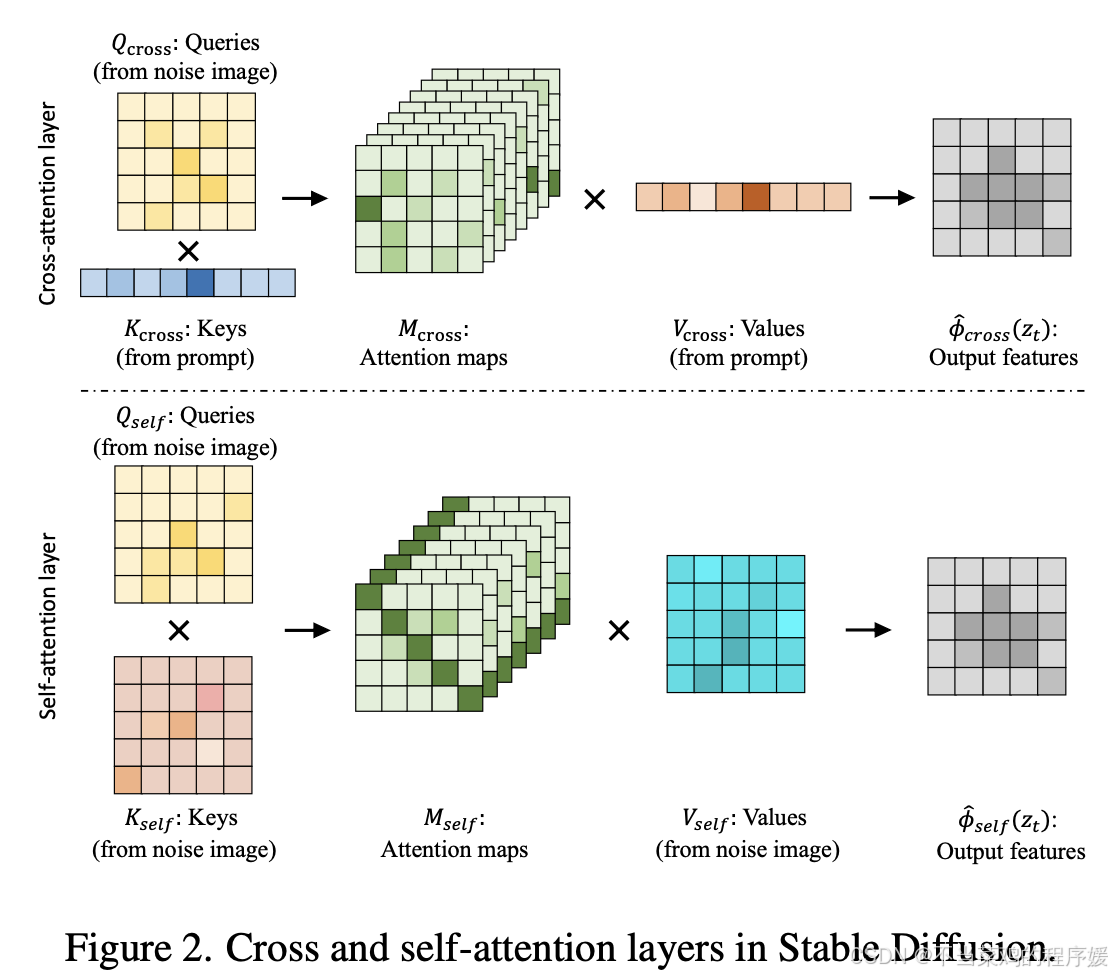
3.1. Cross-Attention in Stable Diffusion


3.2. Self-Attention in Stable Diffusion

3.3. Probing Analysis
然而,交叉和自注意力图的语义仍不清楚。这些注意力图是否仅仅是权重矩阵,或者它们是否包含图像的特征信息。为了回答这些问题,我们旨在探索扩散模型中注意力图的含义。受 NLP 领域的探测分析方法 [3, 16] 的启发,我们提出了构建数据集和训练分类网络来探索注意力图的属性。我们的基本思想是,如果经过训练的分类器能够准确地对不同类别的注意力图进行分类,那么注意力图包含类别信息的有意义的特征表示。因此,我们在扩散模型的交叉注意力和自注意力层之上引入了一个特定于任务的分类器。这个分类器是一个两层 MLP,旨在预测注意力图的特定语义属性。为了更直观地展示分析结果,我们利用颜色形容词和动物名词来形成提示数据集,每个数据集包含十个类别。对于颜色形容词,有两种提示格式:a < color> car and a < color > < object>。动物名词的提示格式是 a/an < animal > standing in the park.。在生成提示后,我们使用探测方法来提取与单词 < color> and < animal>; 对应的交叉注意力图,以及注意力层中的自注意力图。最后,通过训练和评估分类器的性能,我们深入了解注意力图捕获的语义知识。

3.4. Probing Results on Cross-Attention Maps
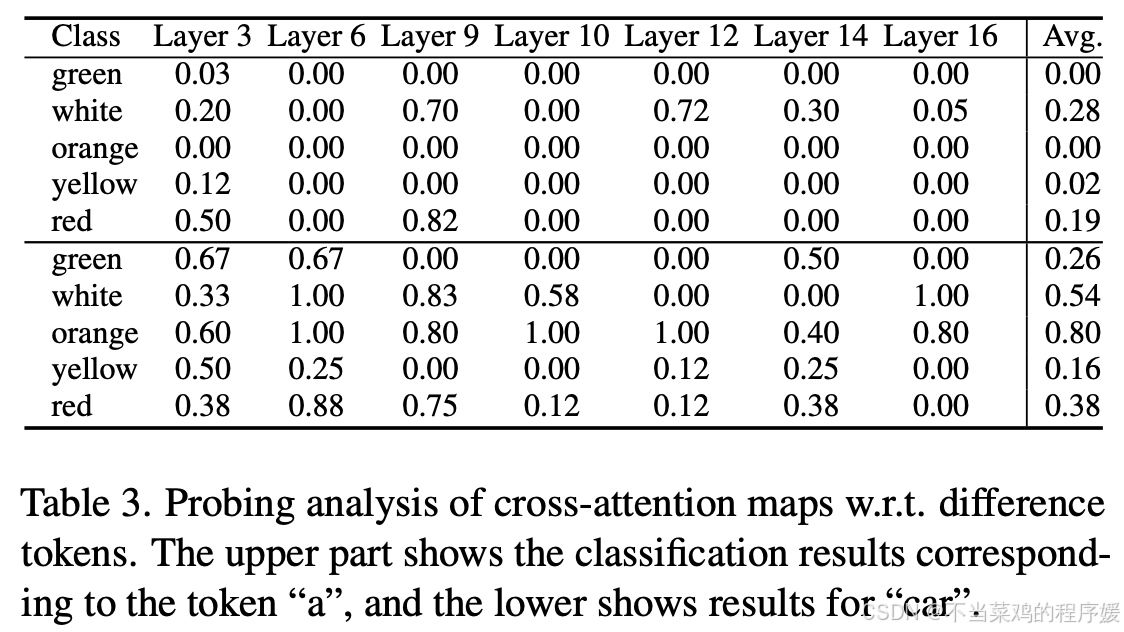
交叉注意力图学习什么。我们直接可视化注意力图,如图 3 所示。提示中的每个单词都有一个与图像相关的相应注意力图,表明与单词相关的信息存在于图像的特定区域。然而,这些信息是这些区域独有的。参考等式 2,我们观察到 M cross 来自 K cross 和 Q cross ,表明 M cross 携带来自两者的信息。为了验证这一假设,我们对 M cross 进行了探测实验,结果如表 1 所示。由于篇幅限制,我们只展示了来自下、中、上、上块最后一层的五个颜色和五个动物的探测结果。如表 1 所示,经过训练的分类器在颜色和动物分类任务中都实现了高精度。例如,分类“sheep”的平均准确率达到 98%,而“橙色”的平均准确率达到 93%。这些结果表明,交叉注意力图充当可靠的类别表示,表明它不仅反映了权重信息,还包含与类别相关的特征。这解释了使用交叉注意图替换进行图像编辑失败。图 4 的上半部分说明了通过在不同的交叉注意力层替换相应单词(“兔子”和“珊瑚”)的交叉注意力图获得的编辑结果。很明显,当所有层都被替换时,编辑结果最令人满意。狗无法完全转化为兔子,黑色汽车不能变成珊瑚汽车。相反,当交叉注意力图保持不变时,可以实现正确的编辑结果。补充材料中提供了完整和更多额外的实验结果。
3.5. Probing Results on Self-Attention Maps
自注意力图的学习方式是什么。表 2 显示了探测实验的结果。结果表明,经过训练的分类器难以对由包含颜色提示的图像生成的自我注意图。对于动物,结果更好,尽管不如使用交叉注意力图的结果精确。这种差异可能归因于对应于颜色提示的自注意力图中存在的不规则空间结构。相反,动物提示对应的自我注意图包含不同动物的结构信息,通过识别结构或轮廓特征来学习类别信息。如图 3 的下半部分所示,马自注意力图的第一个组件清楚地表达了马的轮廓信息。图 4 的下半部分展示了我们在跨不同注意力层的自注意力图上运行的实验结果。当源图像中所有层的自注意力图在目标图像的生成过程中被替换时,得到的目标图像保留。 来自原始图像的所有结构信息,但阻碍了成功的编辑。相反,如果我们不替换自注意力图,我们获得了与直接使用目标提示生成的图像相同的图像。作为折衷方案,将第 4 层到第 14 层的自注意力图替换允许最大程度地保留原始图像的结构信息,同时确保成功的编辑。这个实验结果进一步支持了第 4 层到第 14 层的自注意力图不能作为可靠的类别表示,而是包含图像有价值的空间结构信息的想法。
3.6. Probing Results for Other Tokens
与非编辑词对应的交叉注意力图是否包含类别信息。此外,我们探索了与非编辑词相关的注意力图。这是相关的,因为在文本序列中,每个单词的文本嵌入保留了句子的上下文信息,特别是当使用了基于转换器的文本编码器 [7 , 23] 时。我们使用格式为 < color> car 的提示数据进行探测实验。实验结果如表3所示。结果表明,文章“a”不包含任何颜色类别信息。相比之下,由颜色形容词修改时名词“car”确实包含颜色类别信息。因此,如果我们将非编辑词对应的交叉注意力图替换为目标图像的交叉注意力图,可能会引入颜色信息,最终导致编辑失败。这一观察结果从图 5 中的实验结果中也很明显,其中替换非编辑单词的交叉注意力图同样会导致编辑失败。
4. Our Approach
基于我们对注意力层的探索,我们提出了一种更简单但更稳定和更有效的方法,称为 Free-Prompt-Editing (FPE)。设是要编辑的图像。我们的目标是基于目标提示
合成一个新的期望图像
,同时保留原始图像
的内容和结构。
当前的编辑P2P[10]等方法取代了源图像和目标图像生成过程中的交叉注意映射。这需要修改原始提示以找到相应的注意力图进行替换。然而,这种限制阻止了 P2P 直接应用于编辑真实图像,因为它们没有原始提示。
基于我们对注意力层的探索,我们的核心思想是将的布局和内容与目标提示
合成的语义信息相结合,合成保留原始图像
的结构和内容信息的所需图像
。为此,在源图像和目标图像之间的去噪过程中,对于在扩散模型的注意层4到14, 我们采用自我注意劫持机制。对于生成的图像编辑,我们在扩散去噪过程中将目标图像的自我注意图替换为源图像的自我注意图。在处理实际图像时,我们首先使用反演操作[33]获得重建真实图像的必要潜在值。随后,在编辑过程中,我们在目标图像的生成过程中替换了真实图像的自注意力图。我们可以根据以下原因完成TIE任务:1)交叉注意机制[26,35]促进了合成图像和目标提示的融合,允许目标提示和图像自动对齐,即使不引入源提示的交叉注意图;2)自注意图包含源图像的空间布局和形状细节,自注意机制[35]允许将原始图像的结构信息注入到生成的目标图像中。算法 1 和 2 分别展示了我们应用于生成图像和真实图像的简化方法的伪代码。FPE还可以与零文本反演相结合,用于真实图像编辑(请参阅补充材料中的第10节)。

5. Experiments
5.1. Experimental Settings
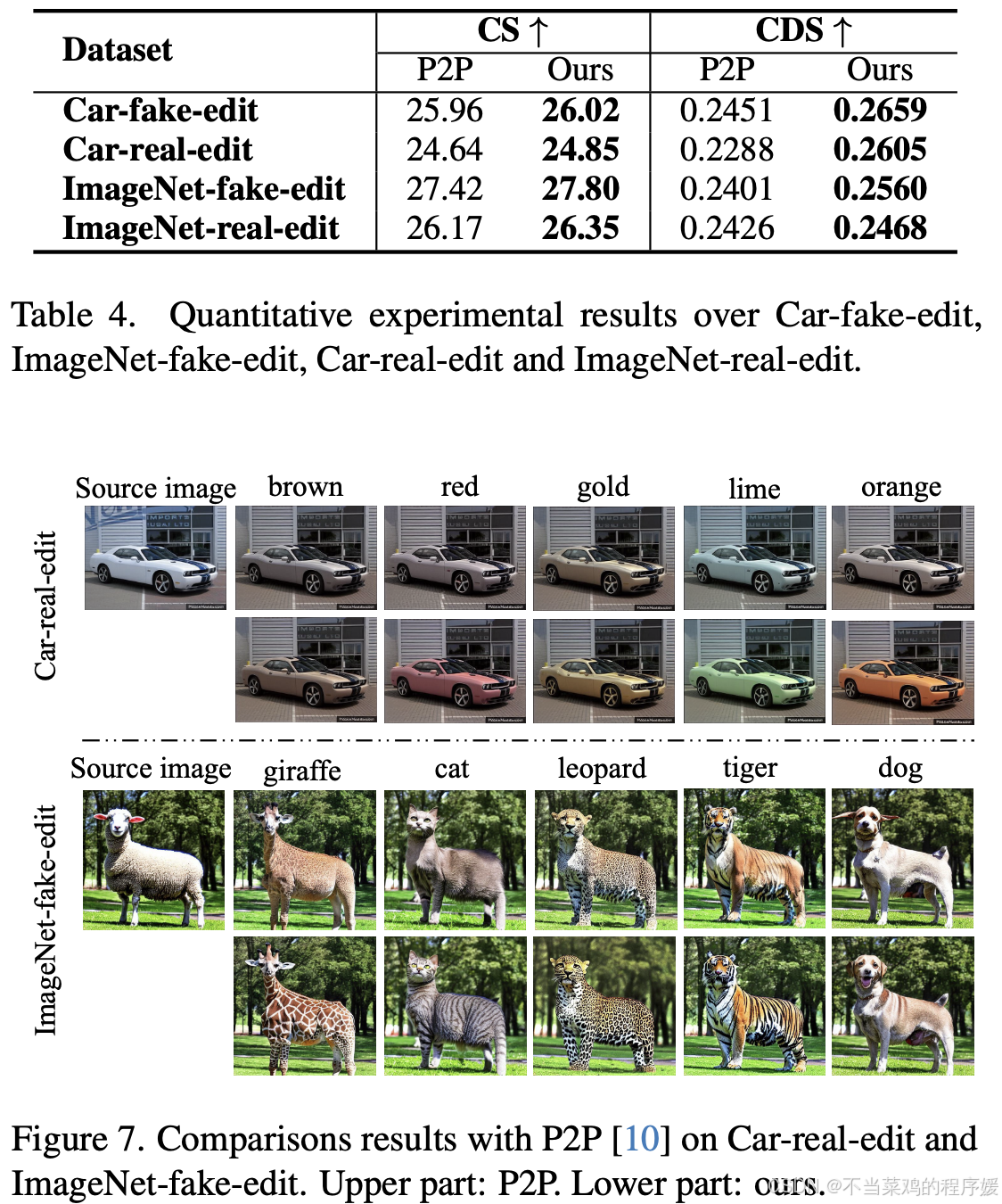
5.2. Image Editing Results

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









