







 本文介绍了网易云音乐高级音频算法工程师高月洁在LiveVideoStackCon 2021的分享,内容涉及歌唱评价体系、K歌综合评分系统、歌手能力图谱以及应用实例。高月洁详细讲解了如何利用算法对音准、节奏、气息、颤音等多维度进行评价,并展示了这些技术在音街APP中的应用,如综合评分、声音社交和作品推荐。
本文介绍了网易云音乐高级音频算法工程师高月洁在LiveVideoStackCon 2021的分享,内容涉及歌唱评价体系、K歌综合评分系统、歌手能力图谱以及应用实例。高月洁详细讲解了如何利用算法对音准、节奏、气息、颤音等多维度进行评价,并展示了这些技术在音街APP中的应用,如综合评分、声音社交和作品推荐。
点击上方“LiveVideoStack”关注我们
作为国内首创的综合评分功能,音街的综合评分系统可对用户的音准、节奏、气息、颤音、滑音、情感等维度进行综合评价,这些多维度评分在增加演唱趣味性的同时,也可为作品分发提供可用的标签等等。本次LiveVideoStackCon 2021北京线下峰会我们邀请到了网易云音乐高级音频算法工程师高月洁老师,本次分享将围绕歌唱与嗓音分析,介绍相关的体系与算法实现。
文 | 高月洁
整理 | LiveVideoStack

我是高月洁,来自网易云音乐,是K歌综合评分系统的项目负责人,同时也负责包括音乐业务、直播业务与嗓音分析相关的内容。

我来自于云音乐的音视频实验室,实验室主要支持K歌、音乐、直播等业务,衍生出诸多业务驱动应用场景,音频方向重点建设的是音乐理解、音乐处理、音乐生产三个方面。音乐理解包括旋律提取、歌曲打标等来分析音乐内容特质;音乐处理方面包括智能音效、修音美化等通过音乐处理增强音乐消费感知;音乐生产包括智能编曲、旋律生成等,用于降低音乐的创作门槛。

提到传统的歌唱评价,大家印象中应该是左上图的一个功能,有标准音高线,用户演唱音准只要与音高线对到一起,就可以得到高分。与此同时还存在着仿佛是平行世界的一套评价体系,就是声乐老师或是乐评人的评价,歌唱的评价标准包含多个方面,需要气沉丹田、需要头腔共振、需要节奏把握准确等。当中的次元壁我们用算法来打破。

本次的演讲主要分为以下几个方面:歌唱评价概述(人类专家如何评价一段音乐、机器如何理解这些指标)、K歌综合评分(怎样将一个K歌作品打上多样的作品标签)、歌手能力图谱(如何评价歌手歌唱能力)、作品标签和歌手标签的应用实例、规划展望以及Q&A。
1. 歌唱评价概述

歌唱评价概述需要解决的是上文中提到的两个问题:人类专家怎样评价一段歌声;这些指标怎样让机器理解。我们在整理人类专家对于歌唱评价标准时发现整个体系包括所有研究都有明显分水岭,这个分水岭是麦克风的普及,在麦克风普及之前人类专家研究的所有歌唱都是关于美声唱法的。美声唱法有一个共振峰是在3000hz附近,这可以使歌手的声音在交响乐队中脱颖而出,有了这个共振峰就是一个好的歌声。当麦克风普及后,这一套标准完全翻天覆地。本次分享的是在麦克风普及后对歌声评价标准。
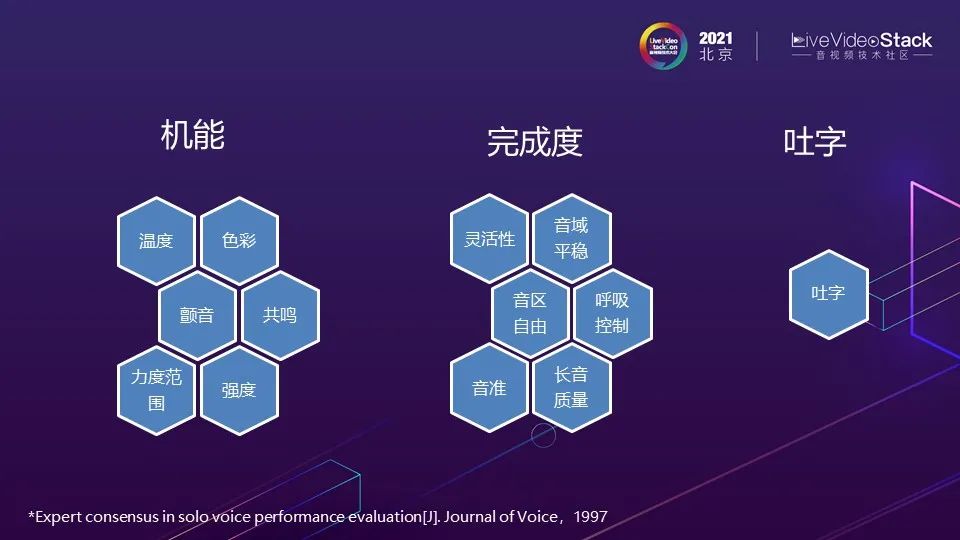
在最近的一篇广为引用文章中,把歌唱标准评价方法分为三类:机能、完成度、吐字。机能包括歌手演唱声音的温度、色彩、颤音、共鸣、力度范围、强度。完成度包括演唱时声音的灵活性、音域平稳性、音区自由度、呼吸控制、音准、长音质量。不同学派对这三类有不同的侧重点,有些会认为机能最重要,有些会认为完成度更重要,吐字一般认为在比较次要的位置。

针对未受训练的歌手,有论文研究了非常多指标,根据重要程度排名,第一是音高的准确性;第二是节奏的一致性,需要节奏稳定卡上点;第三是音色亮度,研究发现这与高频能量有关;第四是声音清晰度,与HNR有很强相关性;第五是颤音;第六是音域,即能够自由地唱歌的音高范围,而不会在声音质量或其他方面发生不适当的变化。
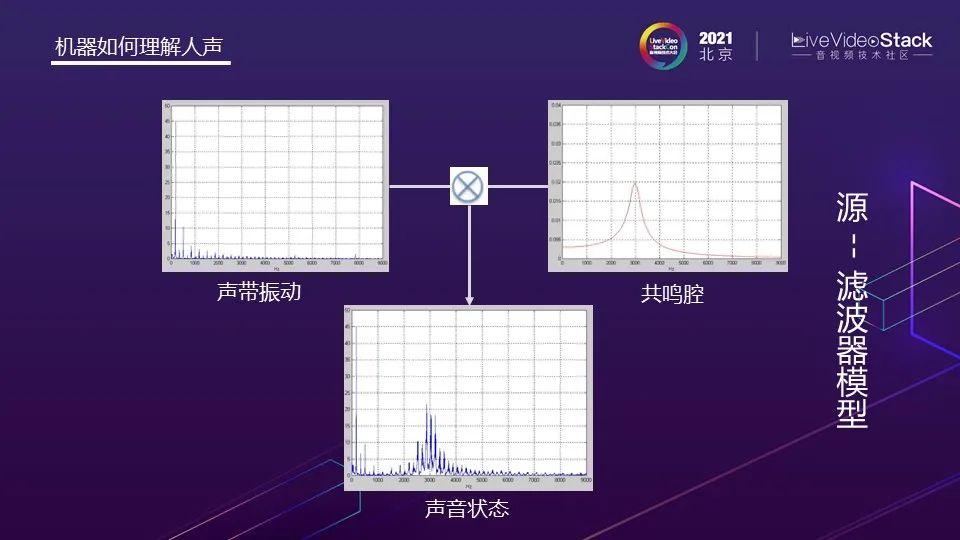
接下来要解决的问题是,机器是如何理解人声的。大家应该都了解源-滤波器模型。其中,可以把声带震动认为是震动源,它的震动会产生一系列谐波。共鸣腔是由声道,包括口腔的形状、牙齿、嘴唇的位置等组成,声道形状可以决定共鸣腔波峰系数。声带震动与共鸣腔进行卷积就可以确定声音状态。在歌唱时,声带相关的,比如真声假声混声,都影响着声带震动的部分;头腔共鸣、喉位影响共振腔形状,最终决定声音状态。声音状态随着时间变化,就形成了歌声。
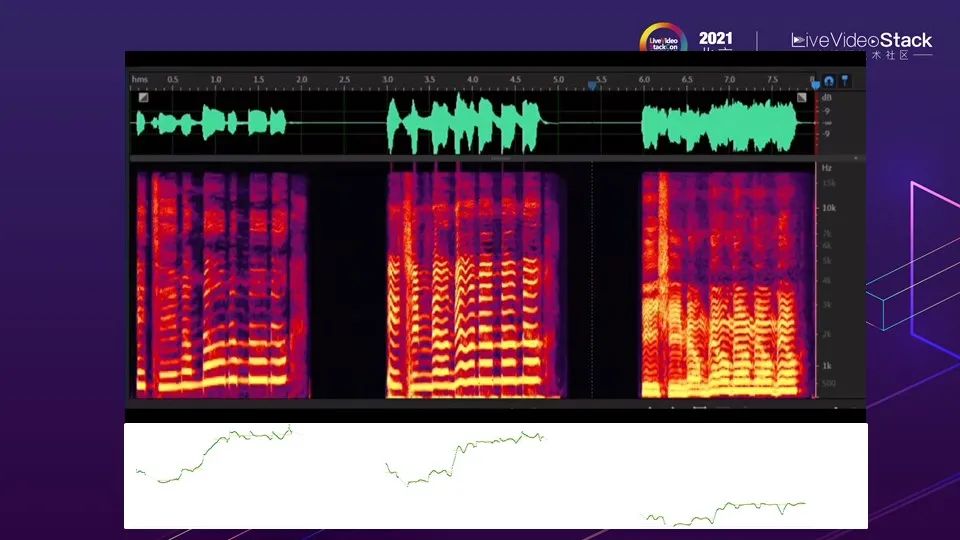
演示的是三个人演唱同一段学猫叫的声音。三个人演唱音区音色有很大区别,可以在频谱上看出他们的不同。频谱中的信息更加细化可以将其分为三个类型。第一类是音高,上图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2078
2078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









