









AI语音克隆软件安装和使用教程
1. 载项目到本地
这个算法是基于比较著名的 Real Time Voice Cloning 实现的。
MockingBird 是最近开源的中文版。去GitHub下载后解压
论文的名字是:
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
简单介绍下:
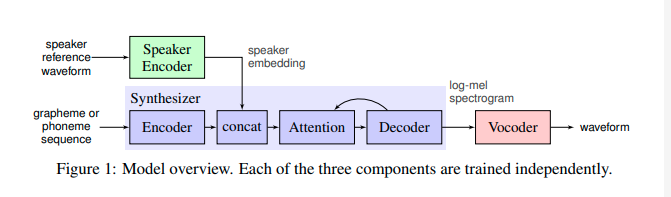
算法分为三个模块:encoder模块、systhesis模块、vocoder模块。
- encoder模块将说话人的声音转换成人声的数字编码(speaker embedding)
- synthesis模块将文本转换成梅尔频谱(mel-spectrogram)
- vocoder模块将梅尔频谱(mel-spectrogram)转换成(波形)waveform
具体的算法原理,大家可以先看论文:
https://arxiv.org/pdf/1806.04558.pdf
2. 下载CUDA
- 打开anaconda,
- 选择environment create新建开发环境rtve
- 打开rtve对应的terminal
会出现如下显示
- 去Pytorch官网: 选择对应电脑的版本
- 复制pip3下载命令
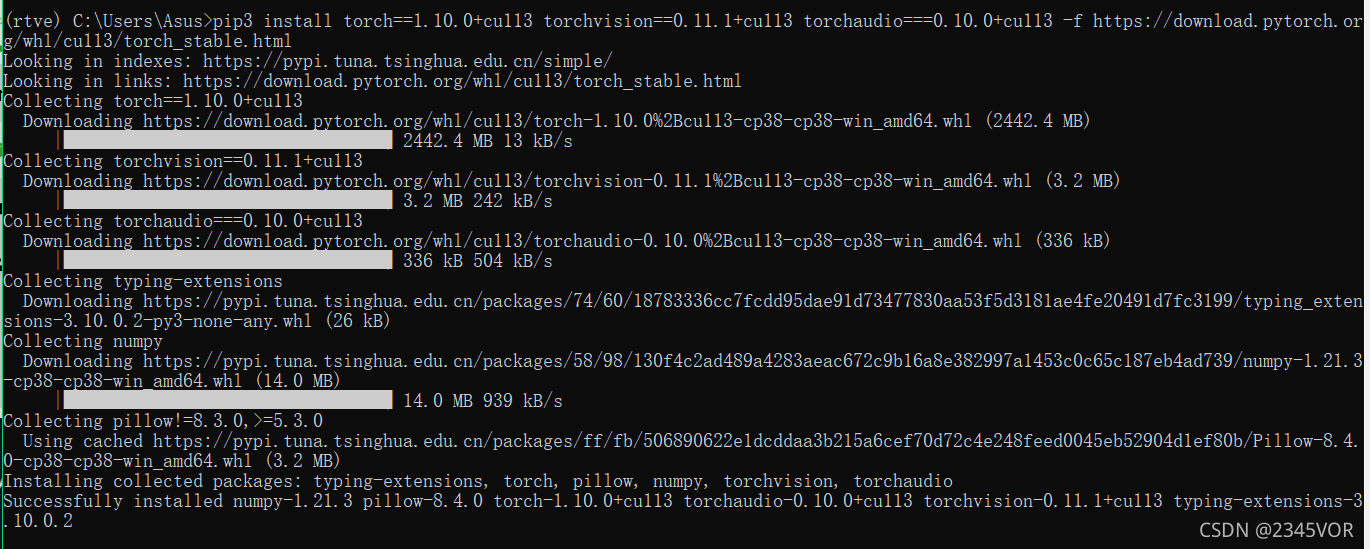
pip3 install torch==1.10.0+cu113 torchvision==0.11.1+cu113 torchaudio===0.10.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
每个人下载命令不一样相同,请按照流程操作

然后输入到terminal,如果下载很慢,建议下载IDM(选择普通下载就直接按照教程安装记得打开IDM插件),安装完成如下
3. 安装依赖包
依赖包的名称是requirements.txt
我直接把Github代码解压放到E盘了
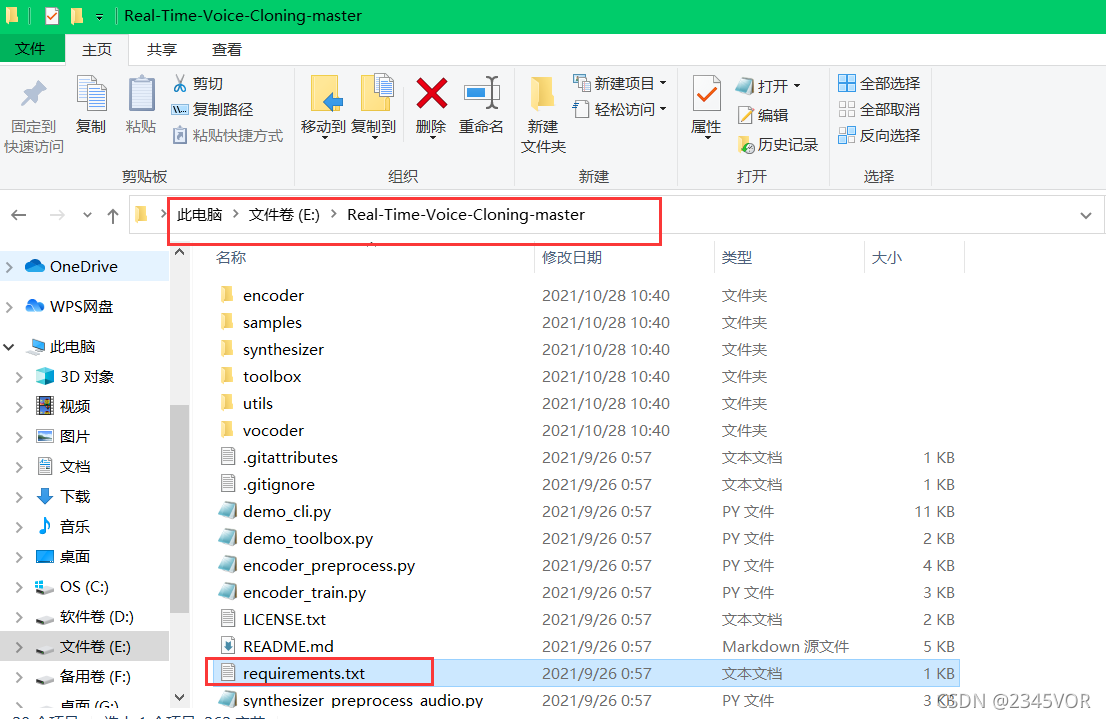
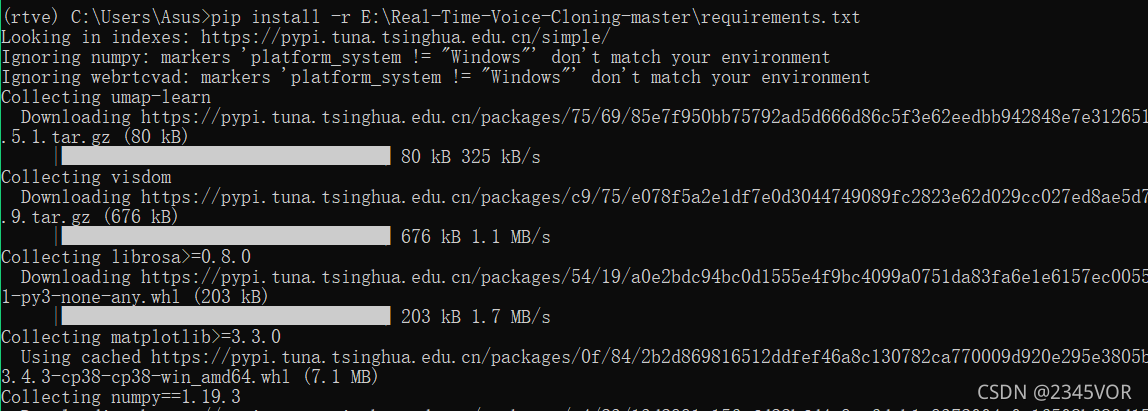
然后在rtve 环境继续安装依赖包
pip install -r E:\Real-Time-Voice-Cloning-master\requirements.txt
输入到terminal中,下图正在安装
安装完成如图

4. 安装FFMPEC
4.1 方法一:
FFMPEG官网:
选择window
点击“Windows builds from gyan.dev”
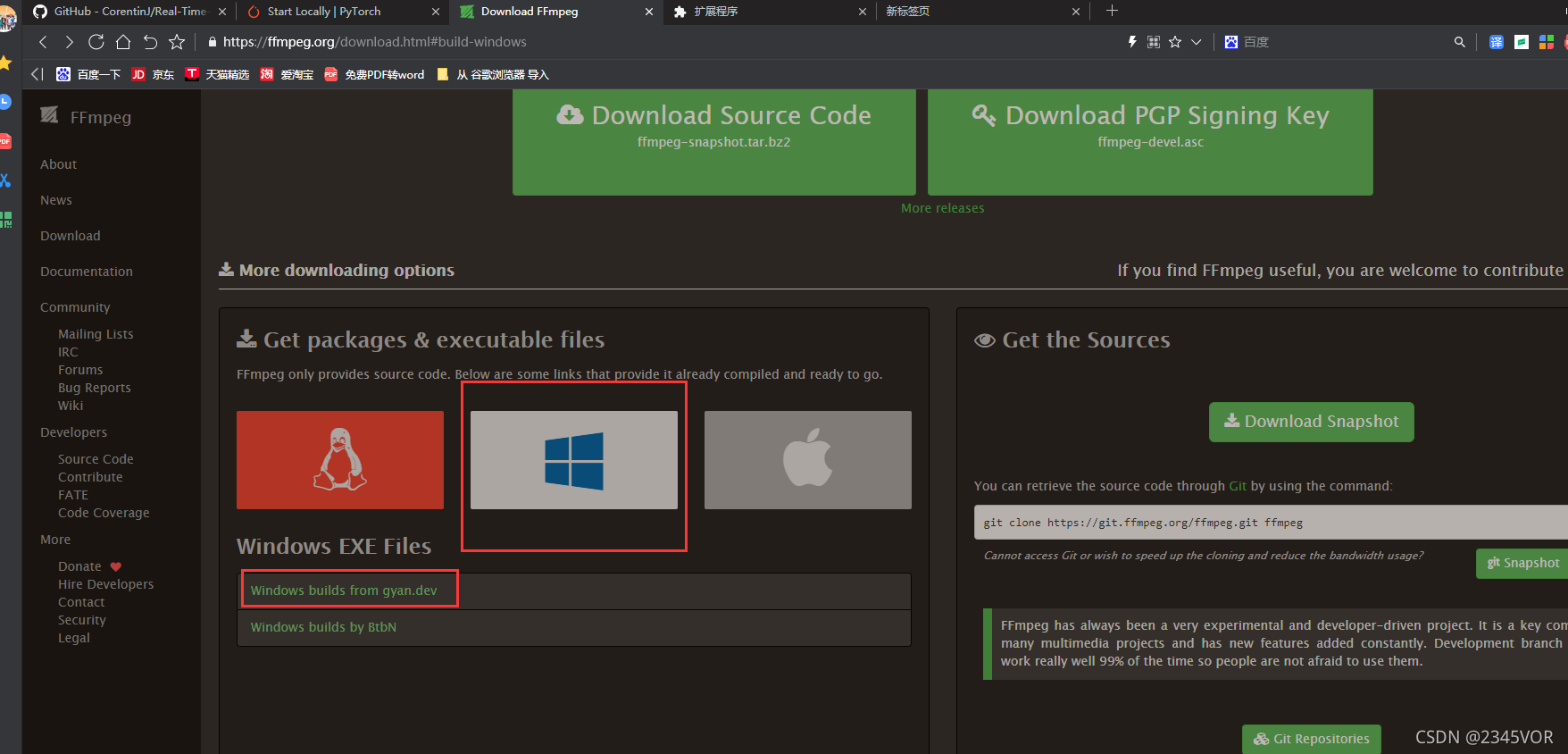
选择所需要版本,我选最新“ version: 2021-10-24-git-9df3f147f5”
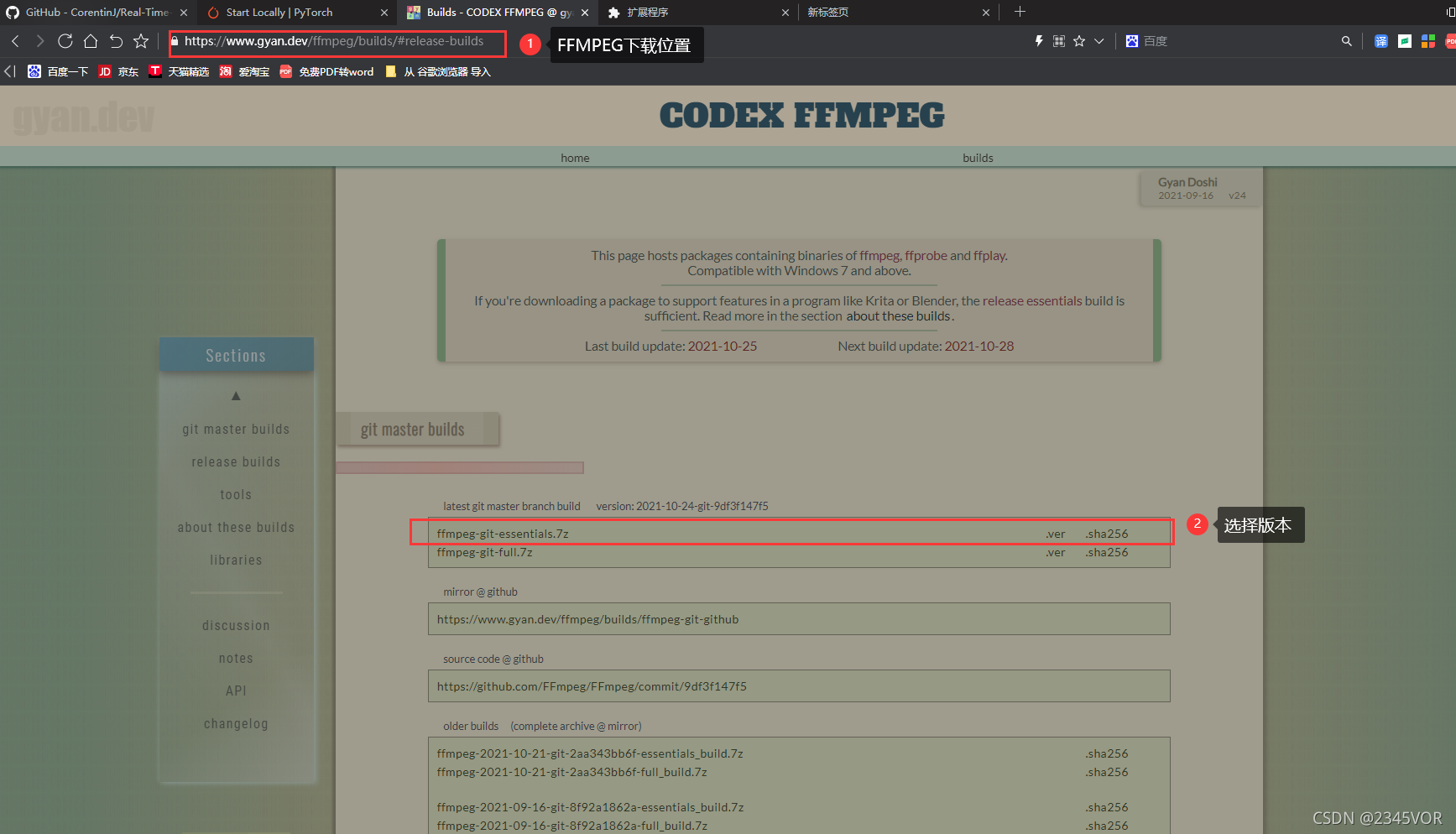
下载解压到D盘
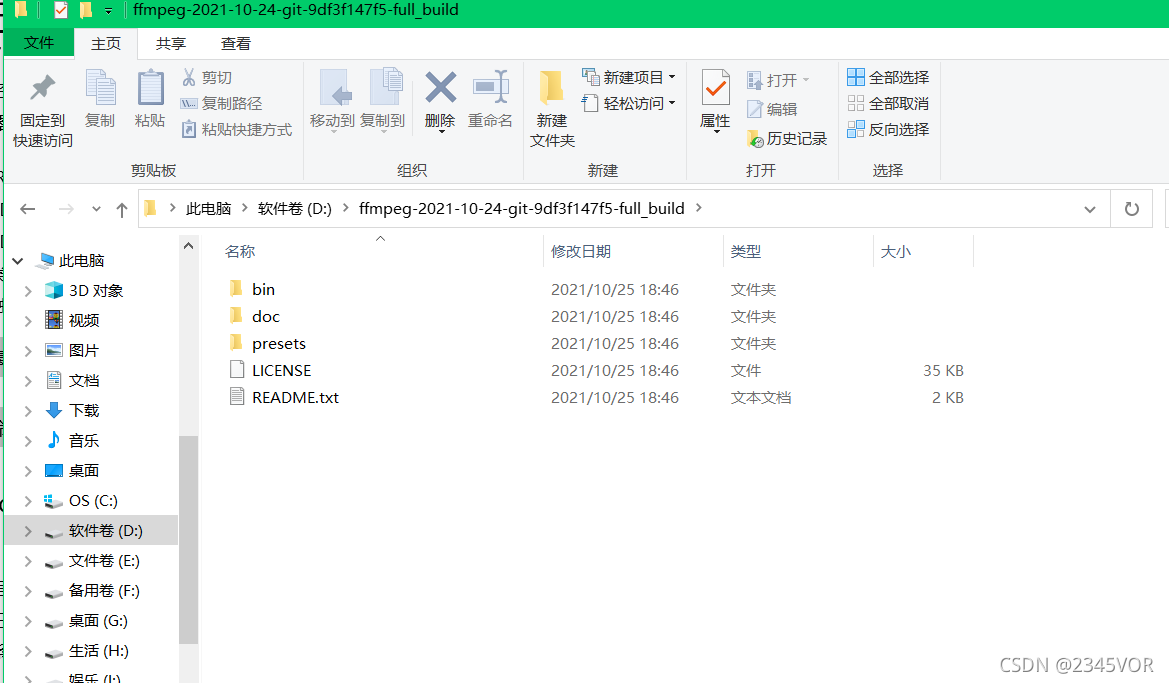
设置环境变量,复制此路径
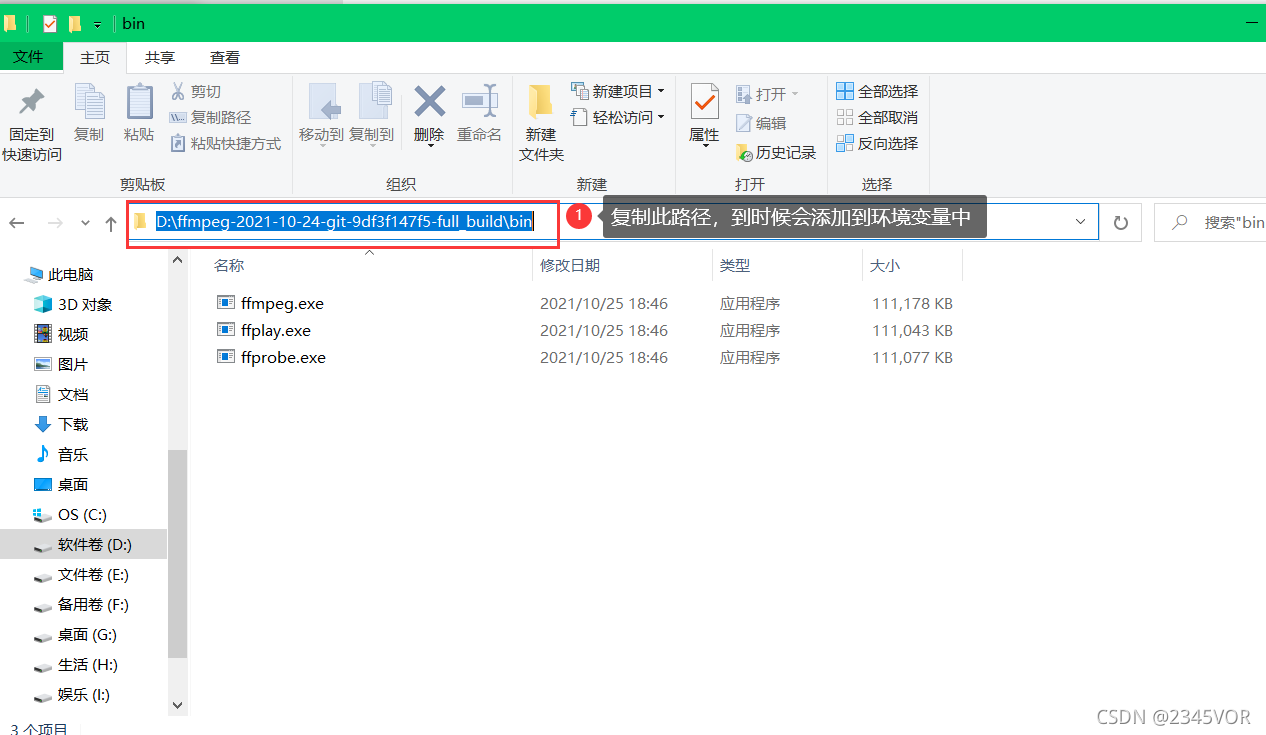
- 右键此电脑属性
- 点击高级的环境变量
- 双击系统变量的Path
- 然后新建刚刚复制的路径,最后点击确定
然后在搜索栏输入cmd(启动命令提示符),输入
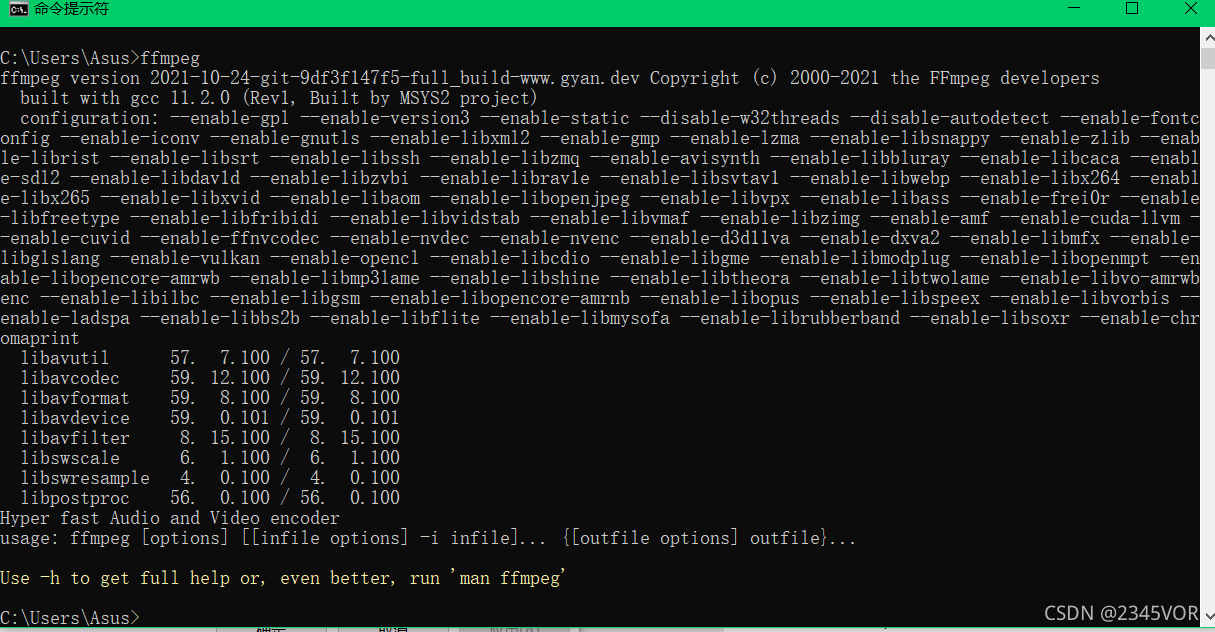
ffmpeg
出现以下情况安装成功
4.2 方法二:(推荐方法二本人成功点亮)
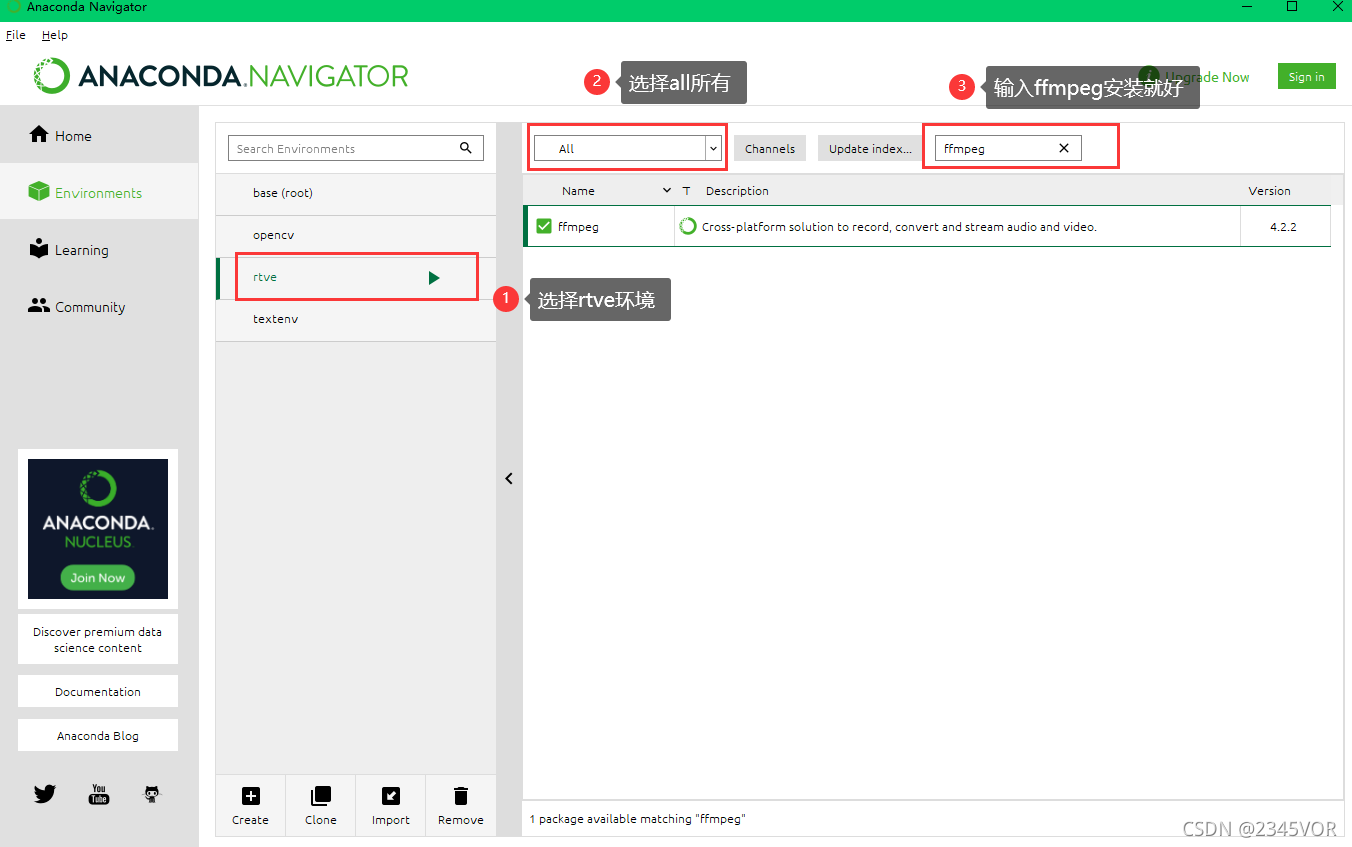
- 直接在anaconda环境安装
- 选择你的rtve环境
- 选all所有程序拓展
- 输入ffmeg点击安装即可
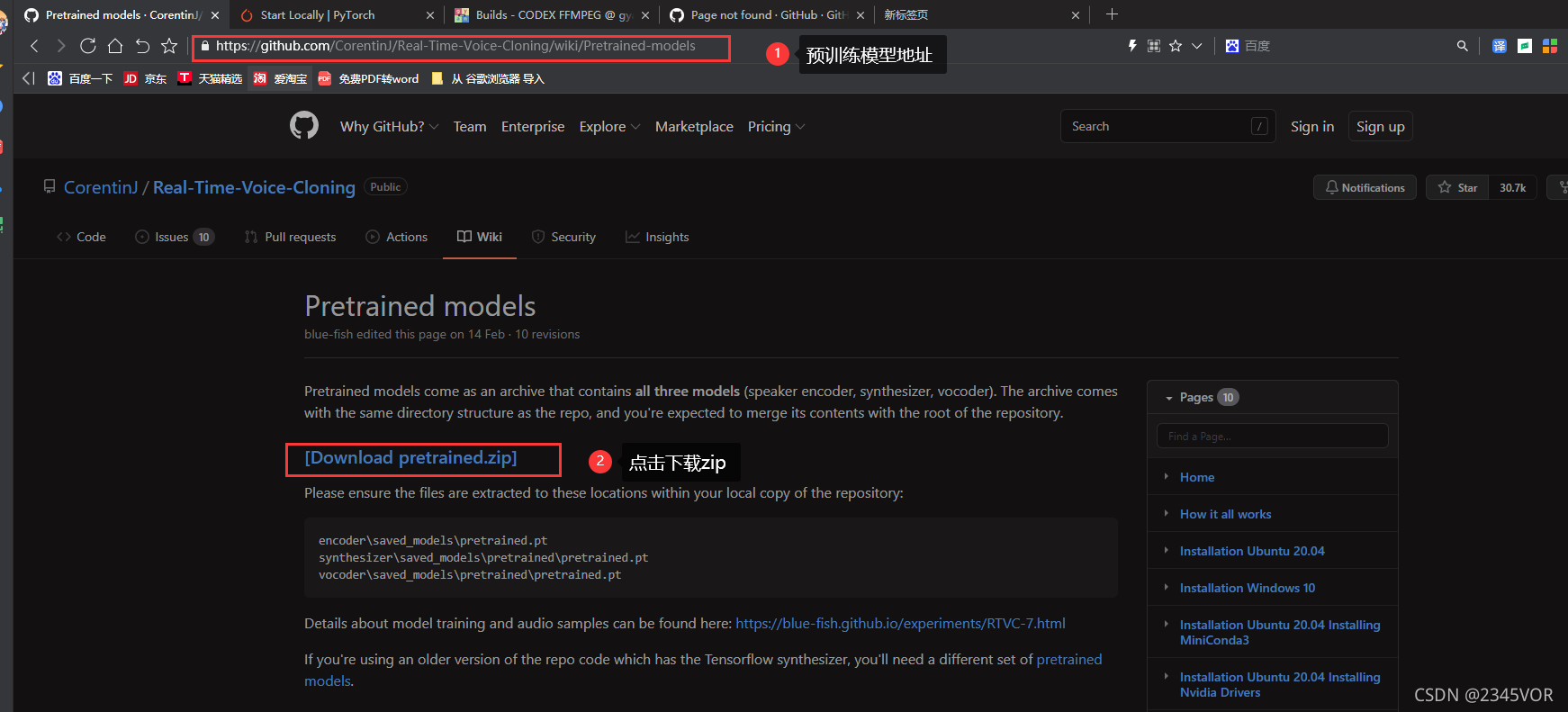
5. 下载预训练模型
预训练模型地址
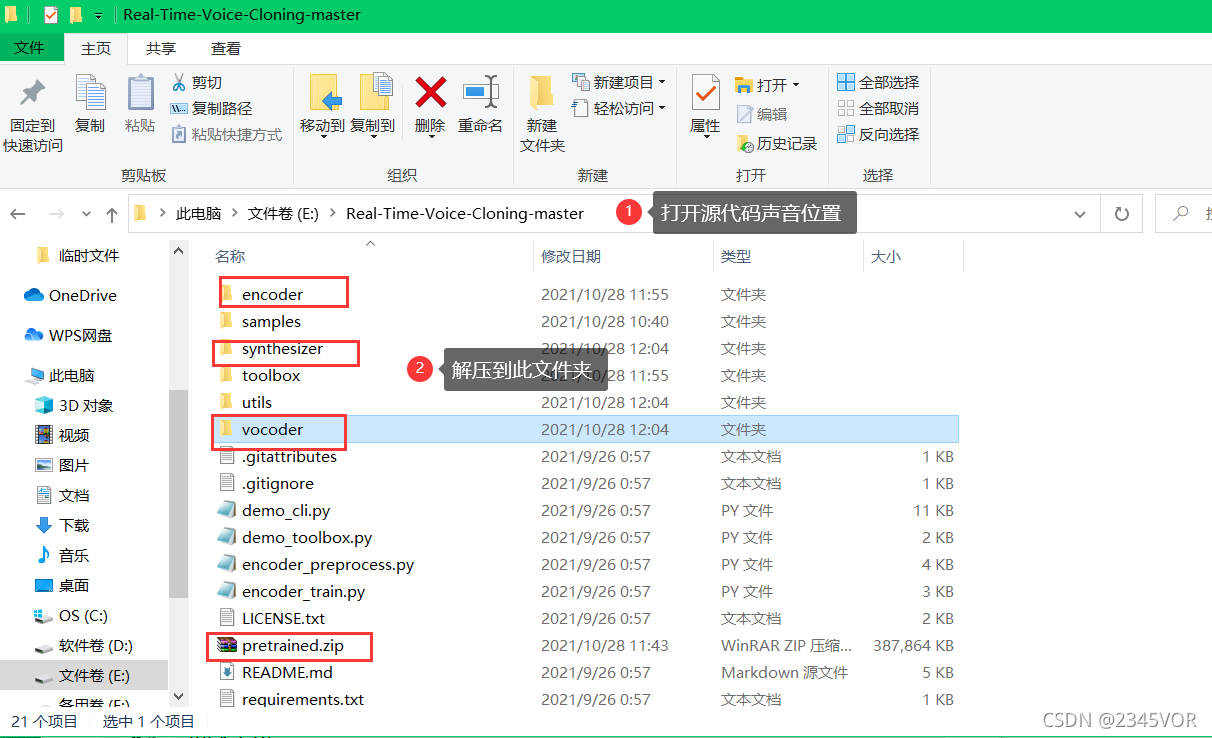
下载解压之后放在声音源代码文件(有三个文件)
E:\Real-Time-Voice-Cloning-master
所有需要安装的步骤都已完成
6. 开始训练和演示
打开之前的环境rtve 的terminal
依此输入回车
e:
cd E:\Real-Time-Voice-Cloning-master
python E:\Real-Time-Voice-Cloning-master\demo_toolbox.py
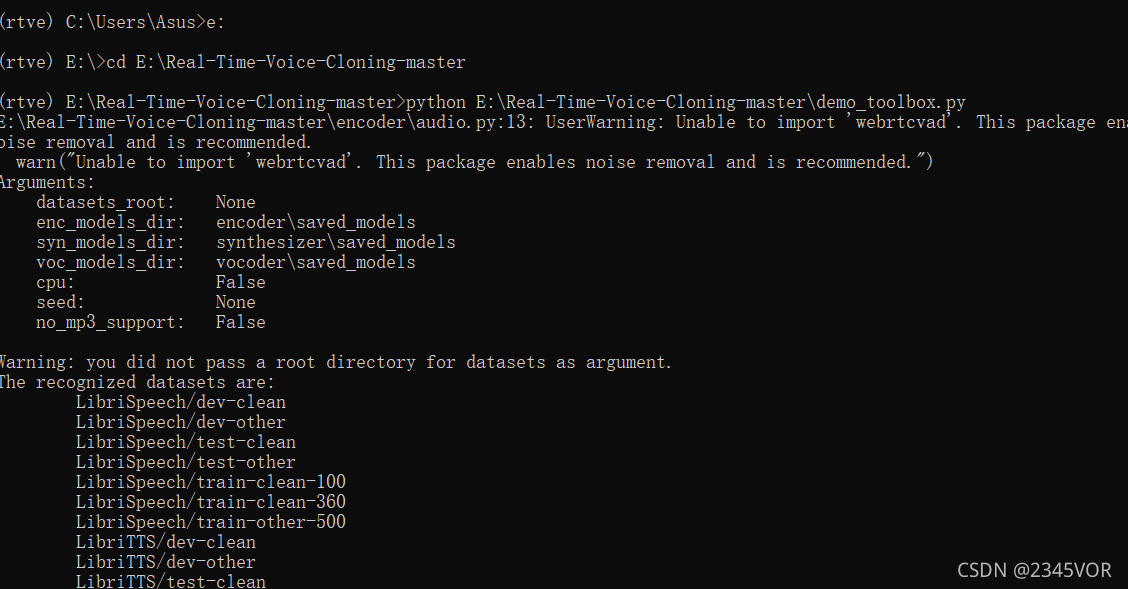
得到操作平台
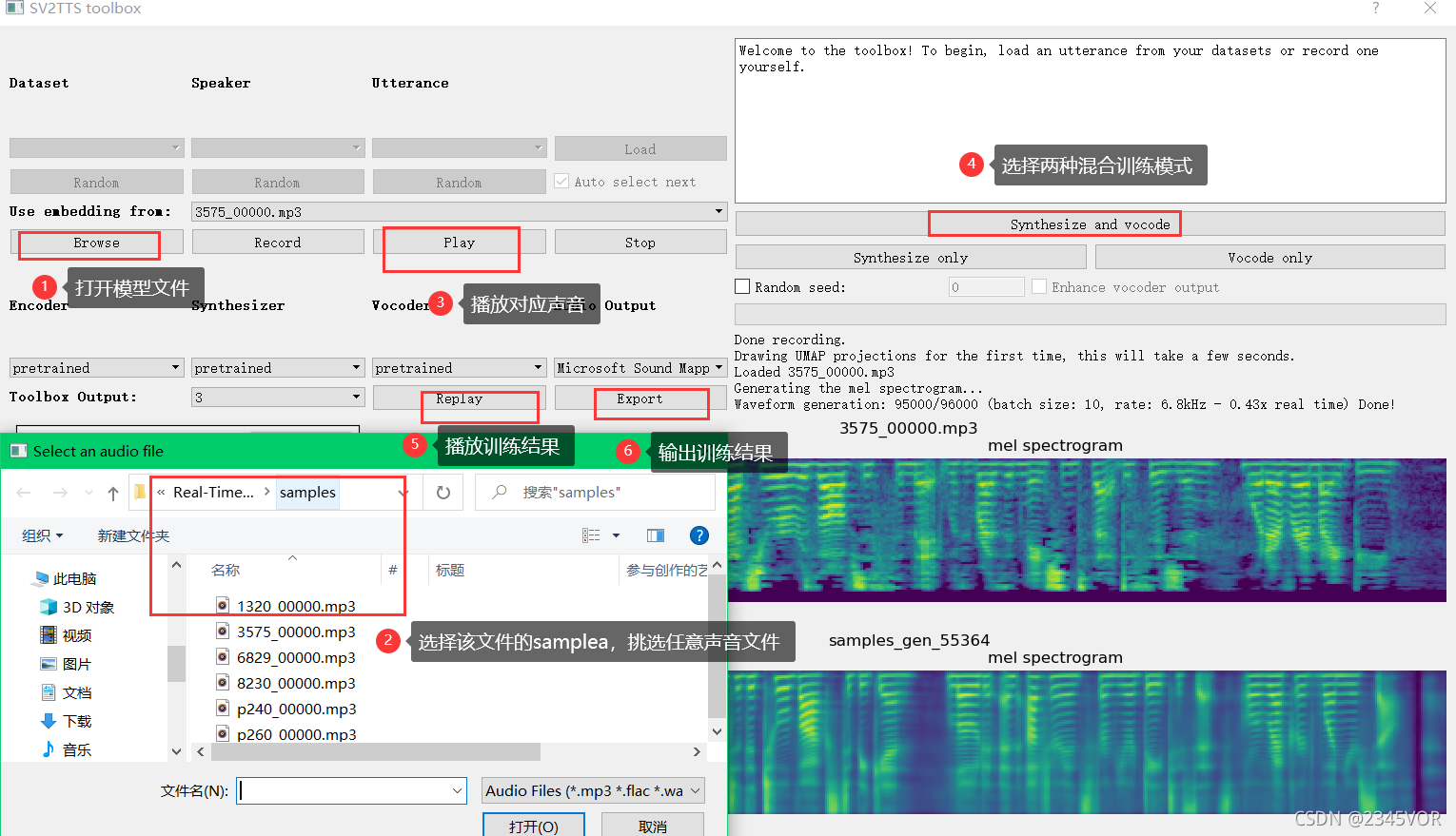
首先打开训练文件,播放对应文件,选择训练方式,播放训练结果,对比训练结果与源文件的差异,训练好后输出对应文件,不可以做违法乱纪的事情,预防电信诈骗的诡诈!👮♂️👮♀️
7. 中文训练
e:
cd E:\MockingBird-main
python pre.py D:\data\ -d aidatatang_200zh -n 10#进行音频和梅尔频谱图预处理
python synthesizer_train.py mandarin D:\data\/SV2TTS/synthesizer #训练合成器:
python demo_toolbox.py -d D:\data\
中文报错实现不了
8. 总结
-
本文介绍做了一期有关语音克隆的教程,时间有点长,但是都会有各种各样的bug,慢慢解决就好,与此同时此方法绝不可以做违法乱纪的事情👮♂️👮♀️,预防电信诈骗的诡诈!很高兴能和大家分享!🤣🤣🤣希望你能有所收获。
-
参考链接:


















 4687
4687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











