






关键词:施密特正交化 (Gram-Schmidt Orthogonalization),对称正交化/勒夫丁正交化(Symmetric Orthogonalization/ Per-Olov Löwdin Orthogonalization)
一、符号用语
在下文中,我们以加粗的大写字母来表示一个矩阵,如 “”;以加粗斜体的小写字母辅以下标表示一个向量,如 “
”。另外,我们默认需要正交化的向量组为矩阵
的列。
表示向量内积。
二、施密特正交化
施密特正交化其实很简单,套公式就行。
配合下图更好理解。
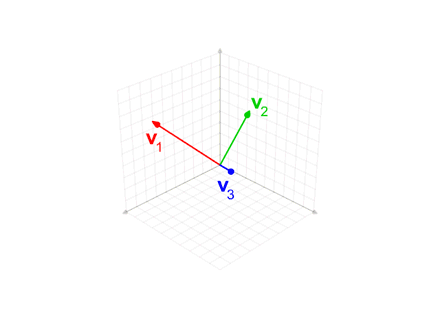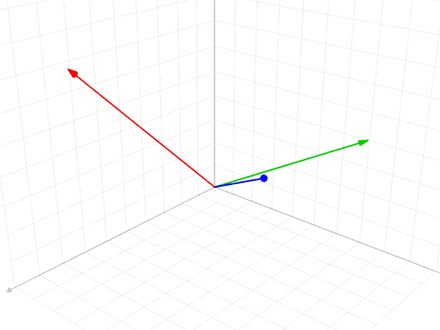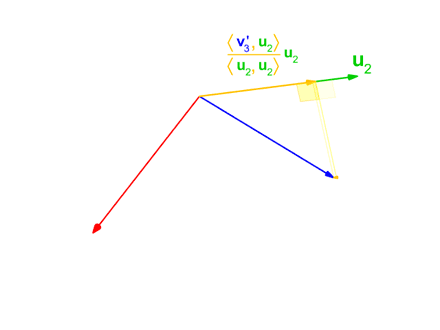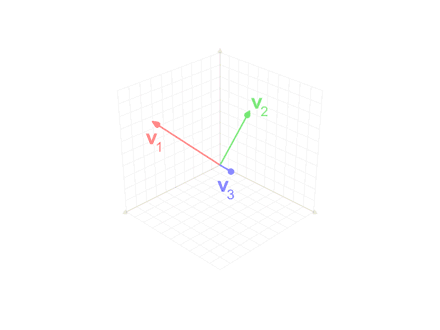
W[:, 0] = W[:, 0] / torch.norm(W[:, 0], 2) // 单位化
for v in range(W.size(1)):
for u in range(v):
W[:, v] = W[:, v] - proj(W[:, v], W[:, u])
W[:, v] = W[:, v] / torch.norm(W[:, v], 2) // 单位化
//torch.norm(u) 就是向量u的二范数(模长)
def proj(v, u):
coeff = torch.matmul(v, u) / torch.matmul(u, u) // 或者直接 v @ u
return coeff * u
// torch.matmul(v, u) 表示矩阵乘法这里就不再细说了,如果有问题可以留言。
三、对称正交化/勒夫丁正交化
这部分我在网上没有找到比较详细的资料,最早提出应该是在 Löwdin P O. On the nonorthogonality problem[M]//Advances in quantum chemistry. Academic Press, 1970, 5: 185-199. 但是很遗憾,这篇论文我没有找到原文,于是整合了我能找到的一些资料,以下部分翻译改编自书籍 Piela L. Ideas of quantum chemistry[M]. Elsevier, 2006. 的附录 J。
设想一组单位化的非正交基 组成的矩阵
,通过对
进行适当的线性组合,我们可以得到正交的
(这里还是和施密特正交化的思想一致)。但是与施密特正交化不同,对称正交化均等地对待所有
(插一句嘴,书中对这句话有部分解释:对于两个向量的施密特正交化过程来说,我们总是从一个向量上减去另一个向量投影的一定倍数,就此而言两个向量并没有被同等对待。再换句话说,和特征值有关,建议大伙用到再深究)。
公式如下:
如果我们进行验证不难发现,
接着是 -1/2 次幂的计算过程,先展示书上给出的过程:
1. 对 做特征分解,使得
,此时的
是包含全部特征值的对角矩阵
2. 计算 ,显然
3. 根据相似理论,
实操的时候 torch.eig 会产生复数,开根号可能会出问题,所以这里介绍一种更简便的方法:
1. 对 做奇异值分解,使得
,此时的
是包含全部奇异值的对角矩阵。显然,这里的
和前面的
一模一样(误差除外),且
2. 于是
def symmetric_orthogonalization(W):
W = W.float()
U, S, _ = torch.linalg.svd(W)
r = torch.matrix_rank(W)
S = torch.inverse(torch.diag(S))
U = U[:, 0:r]
res = U @ S @ U.t() @ W
return res实际运用中,在速度上,奇异值分解>>特征值分解>施密特正交化。
最后给出一个测试用例:
import torch
def symmetric_orthogonalization(W):
W = W.float()
U, S, _ = torch.linalg.svd(W)
r = torch.matrix_rank(W)
S = torch.inverse(torch.diag(S))
U = U[:, 0:r]
res = U @ S @ U.t() @ W
return res
W = torch.tensor([
[1, 2],
[3, 4],
[5, 6]
])
W = symmetric_orthogonalization(W)
print(W.t()@W)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









