




组会在即,读论文这事也是逃不掉了啊。
这次的论文题目是《IAF-LG: An Interactive Attention Fusion Network With Local and Global Perspective for Aspect-Based Sentiment Analysis》
解决的问题
1.先前的多数工作只局限于aspect的局部上下文(语义)来进行语义学习,这使得评论结构的解释变得复杂化。
2.先前的多数工作剥夺了模型对全局语义学的兴趣,而全局语义学能有效地揭示整个评论结构中传达的语义概念。
于是作者提出一个新的IAF-LG模型,该模型加强局部语义和全局语义之间的交互和知识融合,能有效地执行ABSA任务。局部和全局语义学习的协同影响有助于获得可信的语义,不仅可以理解评论中每个令牌的实际含义,还可以更好地理解解释评论结构,从而更好地进行基于方面的情感预测。
论文模型
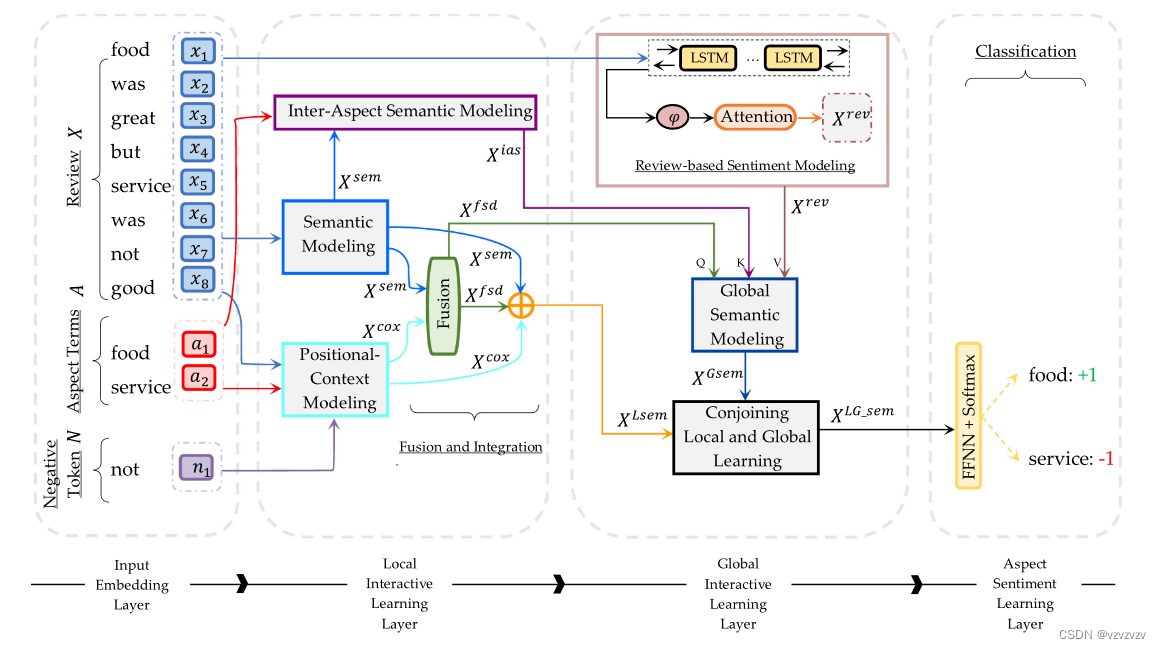 以上就是论文的模型,从左往右开始介绍
以上就是论文的模型,从左往右开始介绍
Input Embedding Layer
这里就是一个BERT的词嵌入没什么好说的
Local Interactive Learning Layer
该层基于方面术语、否定标记和上下文标记的位置信息学习局部语义。此外,该层对aspect间的语义关系进行编码,涉及语义建模、位置上下文建模、融合集成和方面间语义建模四个模块。
Semantic Modeling Module
该模块通过多头注意力网络捕捉token之间的语义依赖关系
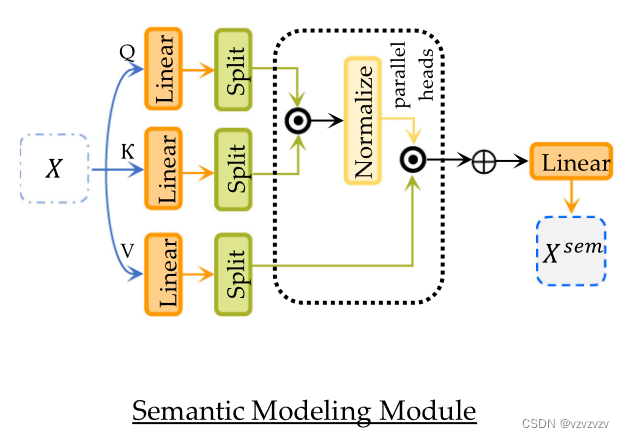
这里的线性层实际上就是对多头注意力的输出乘上了一个权重,最后得到一个语义表征
X
s
e
m
X^{sem}
Xsem
Positional-Context Modeling Module
否定词在整个评论中有着相当重要的作用,因为它可以让情感极性反转,因此我们需要得到它在整个评论中的正确影响
该模块侧重于根据否定token N和aspect A的位置信息来建模token之间的上下文依赖关系。本文使用位置编码,来获得否定token
n
j
n_j
nj和其他token的相对距离。
p
i
=
{
∣
i
−
j
s
∣
,
i
<
j
s
0
,
j
s
≤
i
≤
j
f
∣
i
−
j
f
∣
,
i
>
j
f
p_i=\begin {cases} |i-j_s|, &i<j_s \\ 0, & j_s \le i \le j_f\\ |i-j_f|,&i>j_f \end {cases}
pi=⎩
⎨
⎧∣i−js∣,0,∣i−jf∣,i<jsjs≤i≤jfi>jf
其中
j
s
j_s
js和
j
f
j_f
jf分别表示
n
j
n_j
nj的开始和结束指标。
p
i
p_i
pi则是否定token
n
j
n_j
nj和其他token的相对距离。
然后将所有的位置信息
p
i
p_i
pi拼接进原本的输入X中。
X
n
e
g
=
(
p
1
⊕
.
.
.
⊕
p
e
)
⊕
X
X^{neg}=(p_1\oplus...\oplus p_e)\oplus X
Xneg=(p1⊕...⊕pe)⊕X众所周知,self-attention是不带有位置信息的,序列中任意两个位置的距离在self-attention都是相等的,经过这一步处理后就能让attention注意到否定词的位置信息。

然后利用masking attention model将输入中的aspect遮住(即置为负无穷),让注意力模型不去看aspect从而去学习未被掩盖的token的上下文知识。学习完成后利用cloze把aspect再填回去,最后通过一个带ReLU门控的前馈网络生成上下文表征
X
c
o
x
X^{cox}
Xcox
Fusion and Integration Module
该模块目的是通过融合和集成不同的学习表征,创建一个统一的局部语义表征
X
L
s
e
m
X^{Lsem}
XLsem。通过语义表征和上下文表征之间的映射来完全理解每个token的上下文意义
X
f
s
d
=
S
(
X
s
e
m
,
X
c
o
x
)
=
R
e
L
U
(
X
s
e
m
W
X
s
e
m
)
T
D
R
e
L
U
(
X
c
o
x
W
X
c
o
x
)
X^{fsd}=S(X^{sem},X^{cox})\\=ReLU(X^{sem}W_{X^{sem}})^TDReLU(X^{cox}W_{X^{cox}})
Xfsd=S(Xsem,Xcox)=ReLU(XsemWXsem)TDReLU(XcoxWXcox)这里的S(x,y)是一个叫做对称融合的函数D是一个对角矩阵,我看了一下相关的文献说是通过这种方法能够保留两个矩阵中原本关注的部分,也能提供更多不同部分间的交互。
最终把这几个局部表征拼接起来得到局部语义表征
X
L
s
e
m
X^{Lsem}
XLsem:
X
L
s
e
m
=
X
s
e
m
⊕
X
c
o
x
⊕
X
f
s
d
X^{Lsem}=X^{sem}\oplus X^{cox} \oplus X^{fsd}
XLsem=Xsem⊕Xcox⊕Xfsd
至此,IAF - LG就包含基于A(aspect)、N(否定词)和上下文token的位置的可信局部语义。
Inter-Aspect Semantic Modeling Module
该模块利用语义表征
X
s
e
m
X^{sem}
Xsem对aspect间的关系进行建模,将
X
s
e
m
X^{sem}
Xsem拼接到各个aspect中,然后通过基于距离的语义相似度,向
A
m
e
m
A^{mem}
Amem传递目标aspect项
a
t
a_t
at的信息创建加权方面记忆
A
w
_
s
e
m
A^{w\_sem}
Aw_sem:
w
i
=
1
−
d
i
s
t
(
a
i
−
a
t
)
v
a
l
u
e
w_i=1-\frac{dist(a_i-a_t)}{value}
wi=1−valuedist(ai−at)
X
a
i
w
_
s
e
m
=
w
i
∗
(
X
a
i
s
e
m
,
X
a
t
s
e
m
)
X_{a_i}^{w\_sem}=w_i*(X_{a_i}^{sem},X_{a_t}^{sem})
Xaiw_sem=wi∗(Xaisem,Xatsem)
A
w
_
s
e
m
=
{
X
a
1
w
_
s
e
m
,
X
a
2
w
_
s
e
m
.
.
.
X
a
l
w
_
s
e
m
}
A^{w\_sem}=\{X_{a_1}^{w\_sem},X_{a_2}^{w\_sem}...X_{a_l}^{w\_sem}\}
Aw_sem={Xa1w_sem,Xa2w_sem...Xalw_sem}
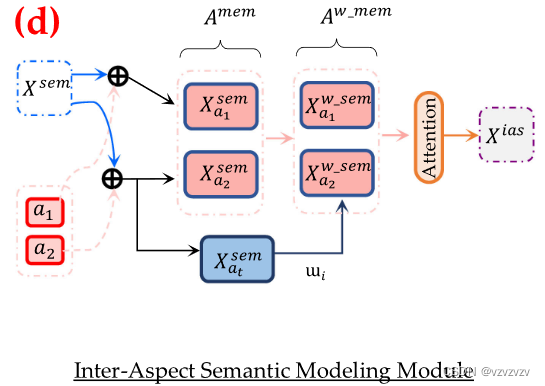
这里我看了文献也看不明白这个
w
i
w_i
wi是怎么来的,当成未解之谜吧
Global Interactive Learning Layer
该层通过注意力机制耦合局部语义和全局语义来编码可信语义。其中,全局语义通过融合上下文语义、方面间语义和基于评论的情感学习之间通过自注意力的协同交互来实现。
Review-Based Sentiment Modeling Task
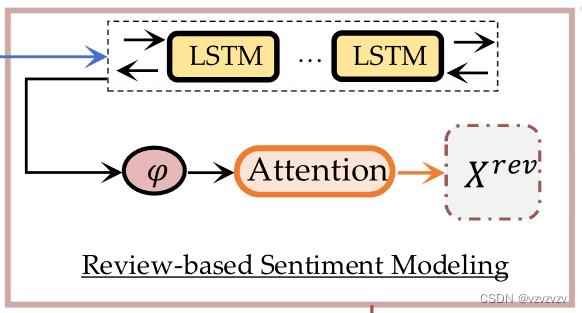
主要就是一个双向的LSTM将过程中的各个隐藏状态
h
i
h_i
hi丢进高斯里面,如果高于均值
μ
\mu
μ就认为该token为积极的低于就是消极的:
φ
(
h
i
)
=
1
2
π
e
−
1
2
(
h
i
−
μ
)
2
\varphi(h_i)=\frac{1}{\sqrt{2\pi}}e^{-\frac{1}{2}(h_i-\mu)^2}
φ(hi)=2π1e−21(hi−μ)2最后透过一个注意力过程得到基于评论的语义表征
X
r
e
v
X^{rev}
Xrev:
δ
i
=
s
o
f
t
m
a
x
(
W
h
i
φ
h
i
φ
+
b
)
\delta_i=softmax(W_{h_i^\varphi}h_i^\varphi+b)
δi=softmax(Whiφhiφ+b)
x
i
r
e
v
=
δ
i
∗
h
i
φ
x_i^{rev}=\delta_i*h_i^\varphi
xirev=δi∗hiφ
Global Semantic Modeling Module
在该模块中,全局语义被表示为局部语义和外部知识信息的组合,即基于评论的情感建模。
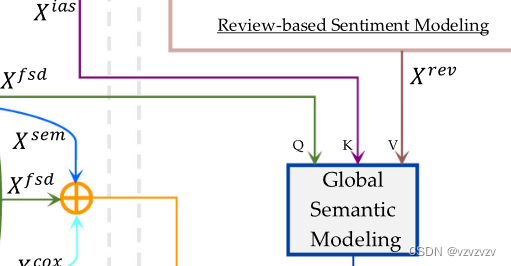
这里依然是一个注意力机制,但是它的Q,K,V分别是
X
f
s
d
X^{fsd}
Xfsd,
X
i
a
s
X^{ias}
Xias,
X
r
e
v
X^{rev}
Xrev,作者将两个局部表征互相匹配,将相应的评论情感传递给注意力生成全局语义表示
X
G
s
e
m
X^{Gsem}
XGsem。
Conjoining Local and Global Learning Module
混合全局和局部信息,获得可信的情感表征:
A
=
W
X
L
s
e
m
X
L
s
e
m
f
(
W
X
G
s
e
m
X
G
s
e
m
)
A=W_{X^{Lsem}}X^{Lsem}f(W_{X^{Gsem}}X^{Gsem})
A=WXLsemXLsemf(WXGsemXGsem)
X
L
G
_
s
e
m
=
A
∗
X
G
s
e
m
X^{LG\_sem}=A*X^{Gsem}
XLG_sem=A∗XGsem
其中f是一个激活函数
Aspect Sentiment Learning Layer
全连接+softmax多分类,没什么好讲的
实验结果
使用的数据集是eval2014的两个经典数据集,以及一个自制数据集
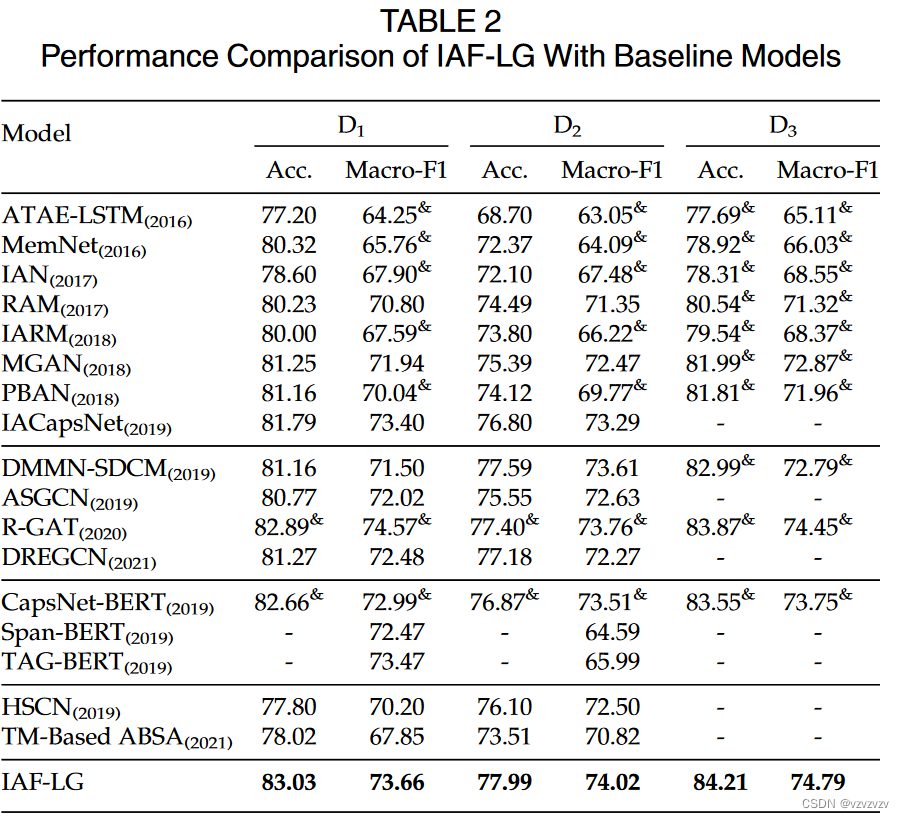
后面就是论文的惯常套路了,不细说了。

















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









