






前言
本文是对Fully Convolutional Networks for Semantic Segmentation这篇论文所总结的学习笔记,接下来会以通俗的语言来介绍FCN是如何进行语义分割的,希望能帮助大家更加深刻地理解该论文,如有不足之处,还请大家指正。
语义分割

首先计算机视觉领域中的语义分割通俗来讲是指将图像中不同的物体用不同颜色标注出来达到分割不同物体的目的。那么我们为什么需要语义分割呢,其中一个原因是因为当计算机视觉领域落地到实际应用中,仅仅知道图片中的大致位置并不能满足产品的功能,例如自动跟随的无人机一个重要的功能是自动避障,这样的功能需要清楚的知道周围物体的边缘位置。因此语义分割在这样的应用起到举足轻重的作用。
原论文的Abstract

卷积网络是一种用于产生特征层次结构的强大视觉模型,我们证明端到端、像素到像素训练的卷积网络本身超过了最先进的语义分割。我们的核心思想是建立一个通过有效的推理和学习能够接受任意大小输入并产生相应大小输出的“完全卷积”网络。我们定义和详细描述了完全卷积网络的空间,解释了它们在空间密集预测任务中的应用,并与先前的模型建立了联系。我们将当代分类网络(AlexNet [19],the VGG net [31], and GoogLeNet [32])改编成完全卷积网络,并通过微调[4]将其学习到的表示转移到分割任务中。然后,我们定义了一种新的体系结构,它将深层、粗层的语义信息与浅层、细层的外观信息结合起来,以产生精确和详细的分割。我们的完全卷积网络实现了PASCAL VOC最先进的分割(20% relative improvement to 62.2% mean IU on 2012)NYUDv2,SIFT Flow,与此同时,对于一副典型图像的推理只需要不到五分之一秒的时间。
FCN实现语义分割
从上文的概括中我们可以知道该论文作者的核心思想是建立一个通过有效的推理和学习能够接受任意大小输入并产生相应大小输出的“完全卷积”网络。方法分为两步,首先,作者将当代分类网络(AlexNet ,the VGG net , and GoogLeNet )改编成完全卷积网络,并通过微调将其学习到的表示转移到分割任务中。然后,他们定义了一种新的体系结构,它将深层、粗层的语义信息与浅层、细层的外观信息结合起来,以产生精确和详细的分割。
局部信息与全局信息融合

从上图我们可以看出局部信息是从浅层网络中提取出来的,因为对应的感受野较小,所以有利于分割尺寸较小的目标,也有利于提高分割的精确程度;而全局信息是从浅层网络中提取出来的,因为对应的感受野较大,所以有利于分割尺寸较大的目标,也有利于提高辨识出一个物体的完整程度。
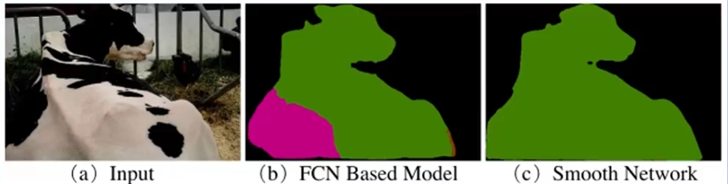
过多地以局部信息或者以全局信息进行语义分割是不可取的。如上图所示,过多的以局部信息(b图)进行语义分割可能会产生将一个完整物体分割成两个不同物体的错误,而过多的以全局信息(c图)进行语义分割会使结果精确度下降。为了解决这个问题,FCN采用将局部信息与全局信息融合的方式进行语义分割。

上图是FCN的结构,他的原理如下:首先输入一张原始图片,经过卷积池化后图片尺寸不断缩小,pool1-5分别为原图尺寸的二分之一、四分之一、八分之一、十六分之一和三十二分之一。作者最后输出三种不同的语义分割图,这三种语义分割图分别由三十二分之一的特征图、十六分之一与三十二分之一融合的特征图、八分之一与十六分之一和三十二分之一融合后特征图进行融合的特征图经过反卷积所得到的。那这三种语义分割得到的结果如下图所示,我们可以看到,经过高度融合的特征图进行语义分割表现出来的物体整体识别度和物体分割精确度更高。
















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









