









在训练神经网络过程中,网络训练速度是比较引人关注的一个问题。我们希望在训练过程中网络代价函数会快速收敛,准确率会快速提升,下面来说说一些常见的方法。
1.代价函数更换
1.1. quadratic-cost function
J(w,b)=12n∑i=1n(yi−h(w,b)(xi))2+R(w)
上式中, R(w) 是正则项,对于第一个代价函数,我们由第二节的知识可知,最后一层w更新公式为
w(L)=w(L)−α⋅∂J(w,b)w(L)=w(L)−α⋅δ(L+1)⋅a(L)
其中
δ(L+1)=−(y−a(L+1))f′(z(L))
而 f′(z(L)) 是激活函数的导数,之前的实验中我们选取的激活函数为sigmod函数,其对应的函数曲线为
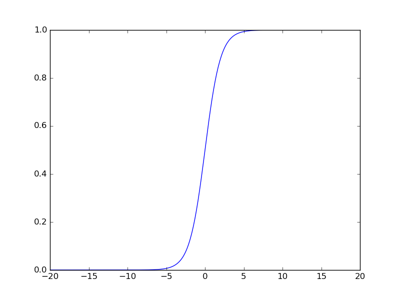
从上图中可以看出,在曲线的两端,sigmod函数导数几乎为0,也就是 δ(L+1) 中的 f′(z(L)) 几乎为0,所以导致权重更新得到的值很小,导致网络学习很慢。
1.2. cross-entropy cost function
对于上面提到的问题,如果能让
δ(L+1)
中的
f′(⋅)
消失,那么
w和b
的更新程度将会增大,网络学习速度就会提示。而cross-entropy函数正好可以实现这样的期盼。
J(w,b)=−1n∑i=1n[yi⋅ln(h(w,b)(x))+(1−yi)⋅ln(1−h(w,b)(x))]
此时,对于cross-entropy代价函数,有
∂J∂w(L)=∂J∂h⋅∂h∂z(L)⋅∂z(L)w(L)
其中 ∂J∂h=−(yh−1−y1−h)=−(y−hh(1−h)) ,我们根据第二接的定义可知,对于最后一层输出 h=a(L+1) ,而 ∂h∂z(L)=f′(z(L)) ,当 f 为sigmod函数时,
∂J∂w(L)=−(y−a(L+1))⋅a(L)
可以看到,由于没有了 f′(⋅) 项, w 和
然而对于非最后一层的 w 和
δ(l)=δ(l+1)⋅w(l)⋅f′(z(l−1))
也会随着bp算法向前传播而迅速趋近于0,导致底层参数更新慢。下图是基于quadratic cost和cross-entropy cost函数在mnist上运行后得到的结果比较。
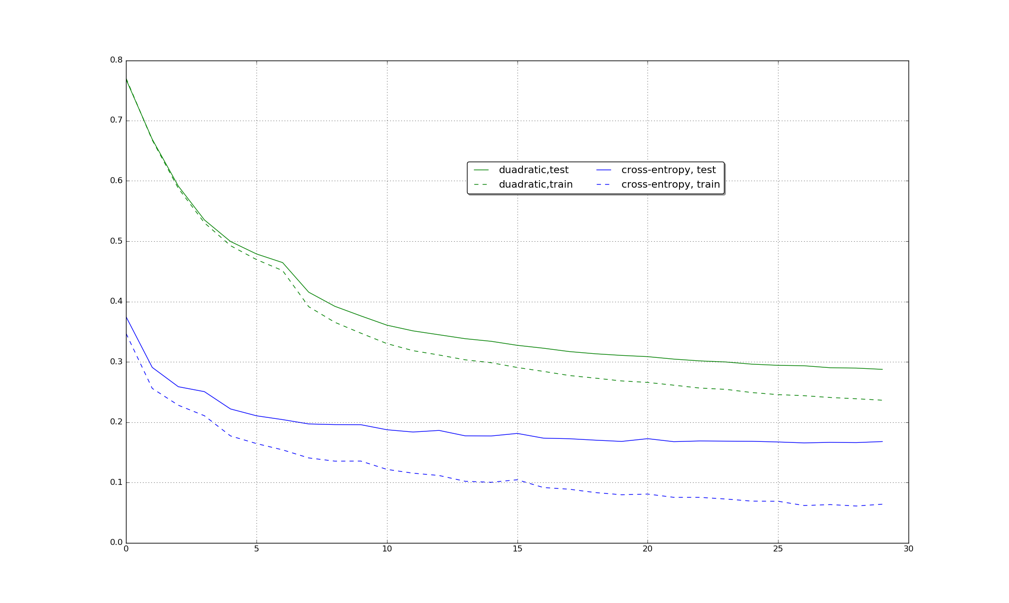
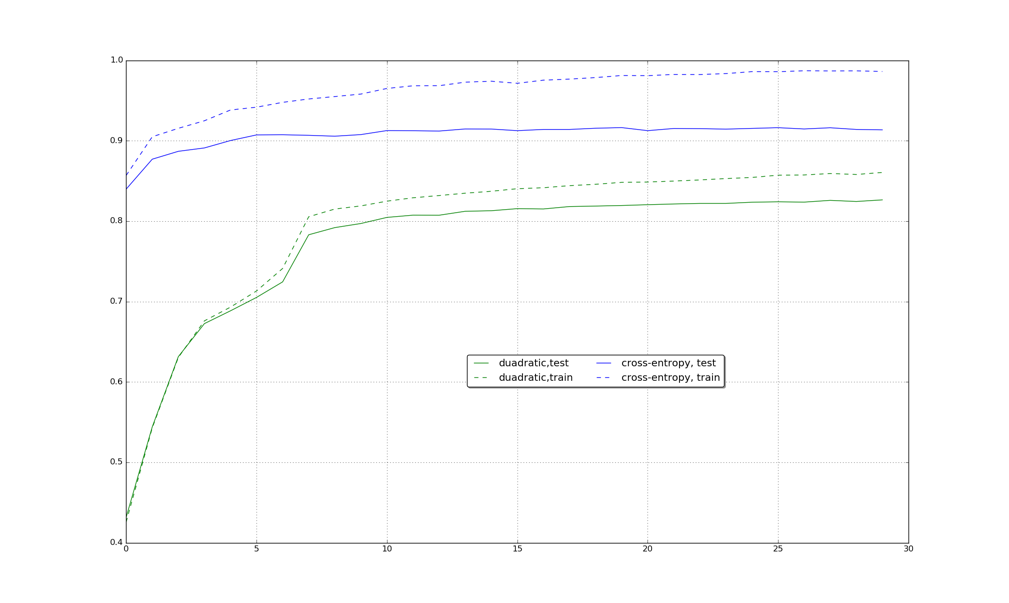
可以看出,cross-entropy函数收敛速度快于quadratic cost函数。
2.参数初始化
对于初始的
w
和
假设输入 a(l+1)i 都为1,那么由于 n(l) 个 w(l+1)k,i 服从标准正态分布,因此 z(l+1)k∼N(0,n(l)) 的正态分布,其分布如下:
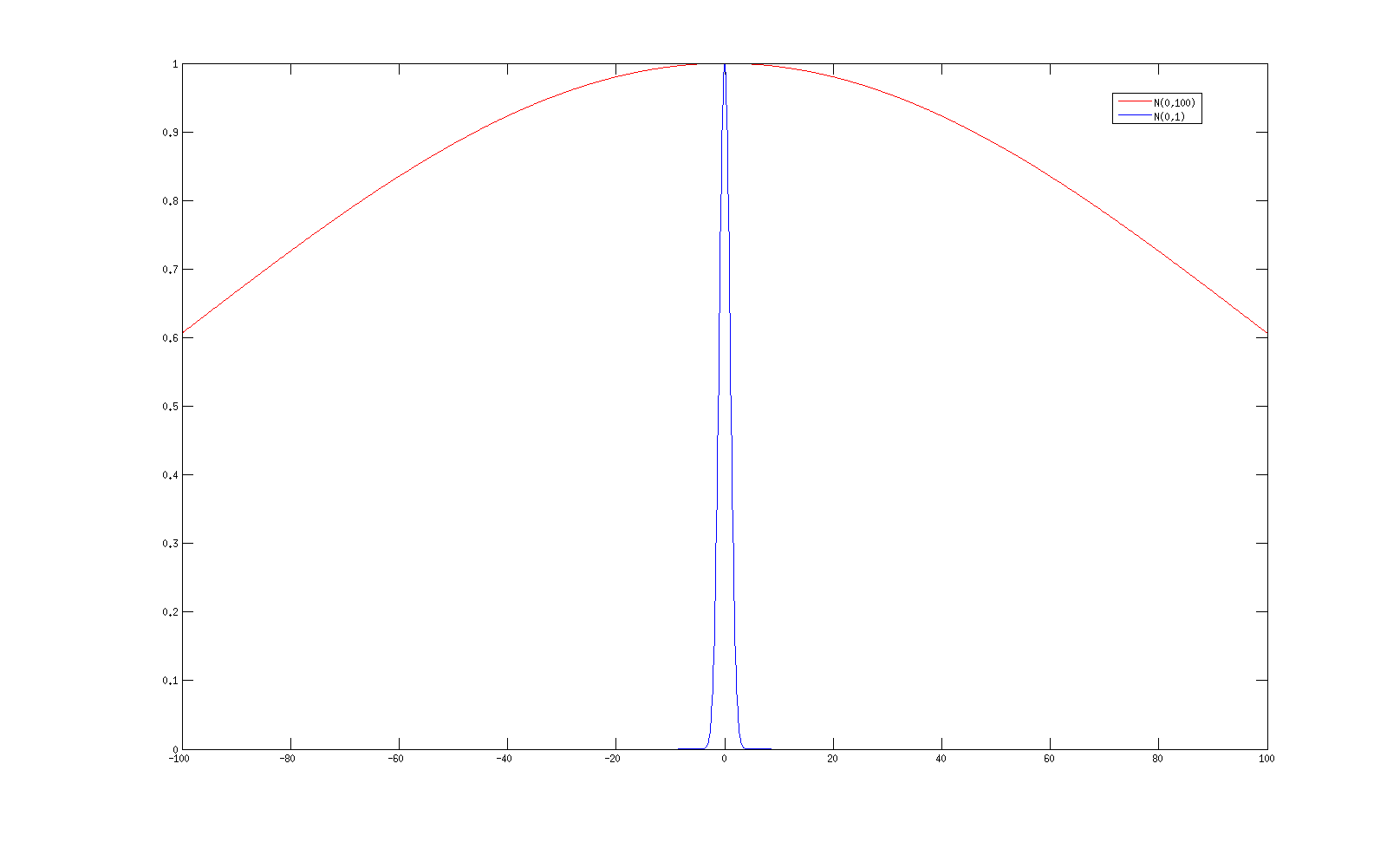
其中蓝色是标准正态分布,红色是N(0,100)的正态分布,可以看到,当 n(l)=100 时, z(l+1) 有很大概率落到值很大的地方,对于到之前的sigmod函数就可看到落在了梯度很小几乎为0的地方概率很大。而我们常用的网络 n(l) 远远大于100,那么 f′(z) 等于0的概率就更大,因此我们要对 w 的初始化做一些限制,使得z服从标准正态分布。我们在产生
下图是利用随机初始化和服从 N(0,1n(l)√) 产生的结果对比
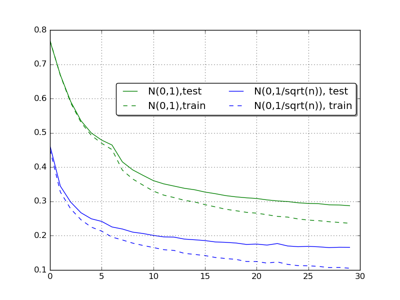
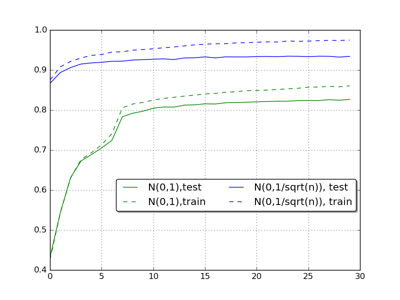
可以看出,改善权重更新后,网络更新速度得以提升,结果也更好。
3.ReLU激活函数
因为之前的激活函数在函数两端梯度几乎为0,所以如果能换其他函数使得其在输入很大的情况下梯度不会非常小,那么网络收敛速度就不会受太大影响。ReLU激活函数就具备这样的性质,ReLU函数为
z=max(0,z)
下图是三种激活函数的对比
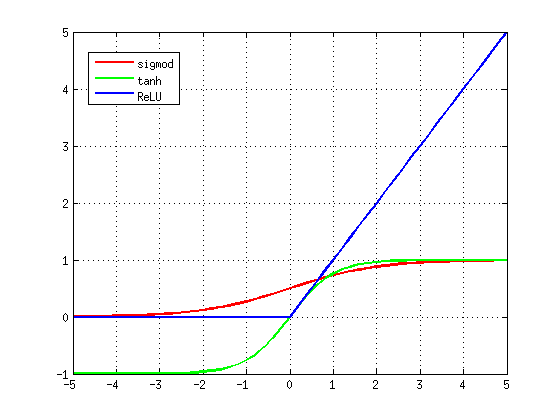
可以看出,在横轴大于5时,sigmod和tanh函数梯度几乎为零,但是ReLU函数梯度不变一直为1.
4.Momentum-based gradient descent(动量梯度下降)
该方法出发点为,既然梯度每次都会下降,拿我们对其在其下降方向上对下降程度进行累加,如果每次下降方向相同,那么下降速度会越来越快。有
w=w+v
v=μ⋅v−α⋅∂J∂w
这样,每次下降都会考虑到上次下降的程度(由 μ 控制),这样梯度会沿着下降最快的方向行进。下图是利用动量梯度下降和原始梯度下降的对比效果。
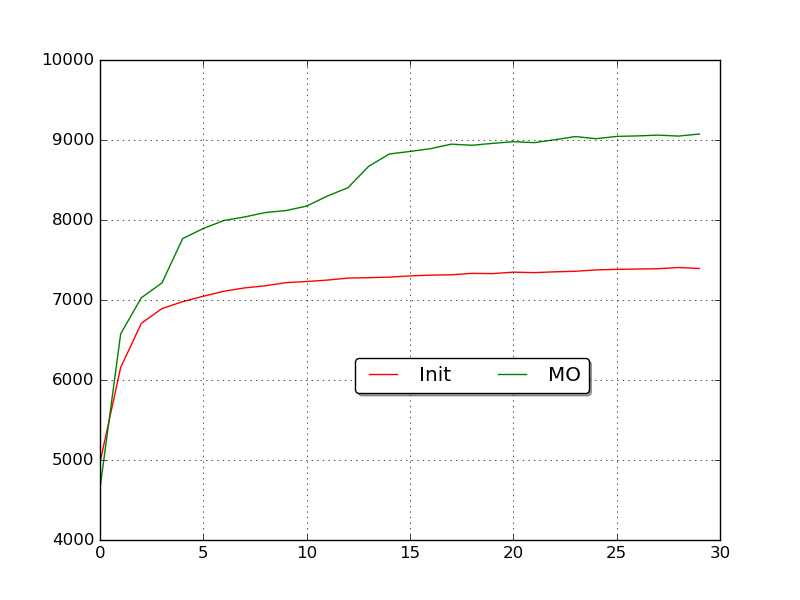
| 功能 | 函数 |
|---|---|
| 随机初始化函数 | reset_qinit() |
| cross-entropy代价函数 | backppg_cs() |
| momentum-based gradient decent | 在调用TrainNet()时添加第二个参数”MO”以及最后一行输入”-p x”设置活跃神经元的比例 |
参考
[1] Michael Nielsen















 2498
2498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









