






引言
今天看了一篇关于智能算法的个体更新策略
Guided learning strategy: A novel update mechanism for metaheuristic
algorithms design and improvement
内容
元启发式算法(Meta-heuristic algorithms, MH)中有两个关键的阶段,探索与开发。探索是指大范围的离散搜索,用于避免陷入局部最优;开发是指小范围的集中搜索,用于提高算法精度。如何平衡探索和利用是提高算法性能和问题适应性的关键。文中提出一种全新的策略——导向性学习策略(GLS)来解决上述问题。GLS通过计算个体最近几代历史位置的标准差来获得种群的分散程度,并推断出算法当前需要什么样的指导。当算法偏向于探索时,它会引导算法进行挖掘。否则将引导算法进行探索。正是因为这种策略能够识别算法当前的需求并提供帮助,才能够提高大多数算法的性能。作者给出的了基于海洋掠食者算法(MPA)进行了改进的源代码。
代码
文章中的GLS (GLS_MPA)的源代码可以通过
https://github.com/luchenghao2022/Guide d-Learning-Strategy
公式
Vo = std(St) ∗ B
B = 200/(ub - lb)
B = 200/(ub - lb)
St为学习经验,std为标准差,ub,lb分别为变量的上下界
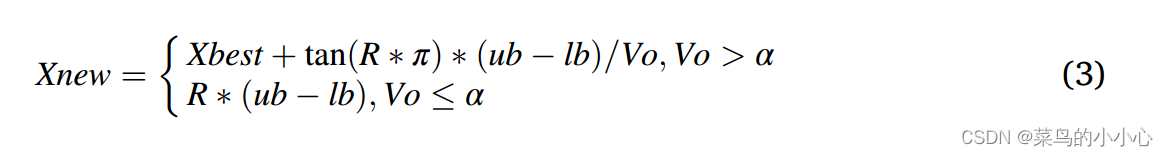
Xbest为历史最优位置,R=rand
论文的分析中介绍时,当个体相对分散时,使用第一个公式来更新,有利于开发
相对的,当个体相对聚集时,使用第二个公式来更新有利于探索。
但是在源代码中,在tan函数那里减了个0.5,想不通。
总结
该策略的在MPA改进的源代码中参数过于复杂,包括文章中的其余两种算法改进的参数,都是通过实验得到的参数,就是说,对不同的算法有不同的针对性。从测试函数运行来看,该策略适用于在算法的最后阶段,比如SBOA算法的第三阶段,适用于摆脱局部最优(猜测)。但注意到该策略的收敛速度有待加强。
若有侵权,请留言联系删除。














 2495
2495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









